2025.08.12
LangExtract: Gemini駆動でテキストからデータ抽出できるGoogleのPythonライブラリ
TL;DR
- GoogleがLangExtractという非構造化テキストから構造化データを抽出するPythonライブラリを発表しました。GeminiやOpenAI、ローカルLLMを利用し、プロンプトとfew-shotの例示を組み合わせて柔軟で正確なデータ抽出が可能です。
- 大量のテキストデータへの対応や、抽出結果のHTMLでの可視化と検証も容易に行えます。また、LLMの学習した知識を利用し専門分野の情報抽出にも対応しています。
はじめに
こんにちは、グループ研究開発本部のAI研究開発室のT.I.です。データサイエンティストの業務において、まずは、良質なデータは必要不可欠です。しかし必ずしもデータが適切に整理され構造化されているとは限りません。そのような非構造化データ(テキスト文章やWebページなど)から情報を整理して抽出するには、手間のかかる大変に面倒な作業でした。昨今のLLMの性能向上により、文章データからの情報抽出は飛躍的に容易になりましたが、その後の処理やデータの正確性の確認など、まだ人の手が必要なことが多いです。先日、GoogleがLangExtractという非構造化データから構造化sされたデータを抽出するPythonライブラリを発表しました。LangExtractは、GeminiなどのLLMを利用することで人のような柔軟なデータ抽出を実現します。今回のブログでは、LangExtractの概要とその利用方法について解説します。
LangExtractを動かしてみる
GoogleのBlog「Introducing LangExtract: A Gemini-Powered Information Extraction Library」で紹介されているLangExtractの特徴は以下の通りです。
- 正確な情報源の参照: 抽出した情報の元テキストでの位置も取得するため情報の検証が可能
- 構造化された出力: few-shotの例をとスキーマを定義することで構造化されたデータを抽出
- ロングコンテキストへの対応: 文章を分割し並列処理による大規模文章への対応
- インタラクティブな可視化: 結果をHTMLで動的に可視化
- 多様なLLMバックエンドへの対応: GoogleのGeminiだけでなく、OpenAIのAPIやローカルLLMなどにも対応
- 多様な分野に対応可能: few-shotの例をもとに専門分野での情報抽出にも対応
- LLMのworld knowledgeの活用: LLMが持つ広範な知識を活用した情報抽出が可能
具体的なLangExtractの利用のフローは以下の通りです。
- 抽出の指示をするプロンプトを作成
- few-shotの例と構造化データの形式を定義
- LLMのバックエンドを指定して実行
- 結果を取得し、必要に応じて可視化などの検証
では早速、LangExtractを使ってみましょう。GitHubのレポジトリの指示に従って始めてみます(GitHub – google/langextract)。
pip install langextract
GeminiなどのLLMを利用するためには、APIキーが必要ですので、Google AI StudioなどでAPIキーを取得して.envファイルに記述しておきます。
cat >> .env << 'EOF' LANGEXTRACT_API_KEY=your-api-key-here EOF
コードは以下のようになります。まず、必要なライブラリをインポートし、プロンプトを作成します。内容は公開されているRomeo and Julietの台本からの情報抽出を部分的に日本語訳したものです。
import textwrap
import langextract as lx
from dotenv import load_dotenv
load_dotenv()
prompt = textwrap.dedent("""\
与えられたテキストから登場人物、感情、関係性を抽出してください。
文脈と深みを加えるために、すべてのエンティティに意味のある属性を提供してください。
重要:extraction_textには入力からの正確なテキストを使用してください。言い換えはしないでください。
重複するテキストスパンがないよう、出現順にエンティティを抽出してください。
注意:戯曲の台本では、話者名はすべて大文字で表示され、その後にピリオドが続きます。""")
LLMを利用するので柔軟な抽出が可能です。抽出する情報に関して以下のようにfew-shotの例を定義します。
examples = [
lx.data.ExampleData(
text=textwrap.dedent("""\
ROMEO. But soft! What light through yonder window breaks?
It is the east, and Juliet is the sun.
JULIET. O Romeo, Romeo! Wherefore art thou Romeo?"""),
extractions=[
lx.data.Extraction(
extraction_class="登場人物",
extraction_text="ROMEO",
attributes={"感情状態": "驚嘆"}
),
lx.data.Extraction(
extraction_class="感情",
extraction_text="But soft!",
attributes={"感覚": "穏やかな畏敬", "登場人物": "Romeo"}
),
lx.data.Extraction(
extraction_class="関係性",
extraction_text="Juliet is the sun",
attributes={"種類": "隠喩", "登場人物1": "Romeo", "登場人物2": "Juliet"}
),
lx.data.Extraction(
extraction_class="登場人物",
extraction_text="JULIET",
attributes={"感情状態": "憧憬"}
),
lx.data.Extraction(
extraction_class="感情",
extraction_text="Wherefore art thou Romeo?",
attributes={"感覚": "切望する問い", "登場人物": "Juliet"}
),
]
)
]
あとは抽出したい入力文を与えて抽出を実行します。
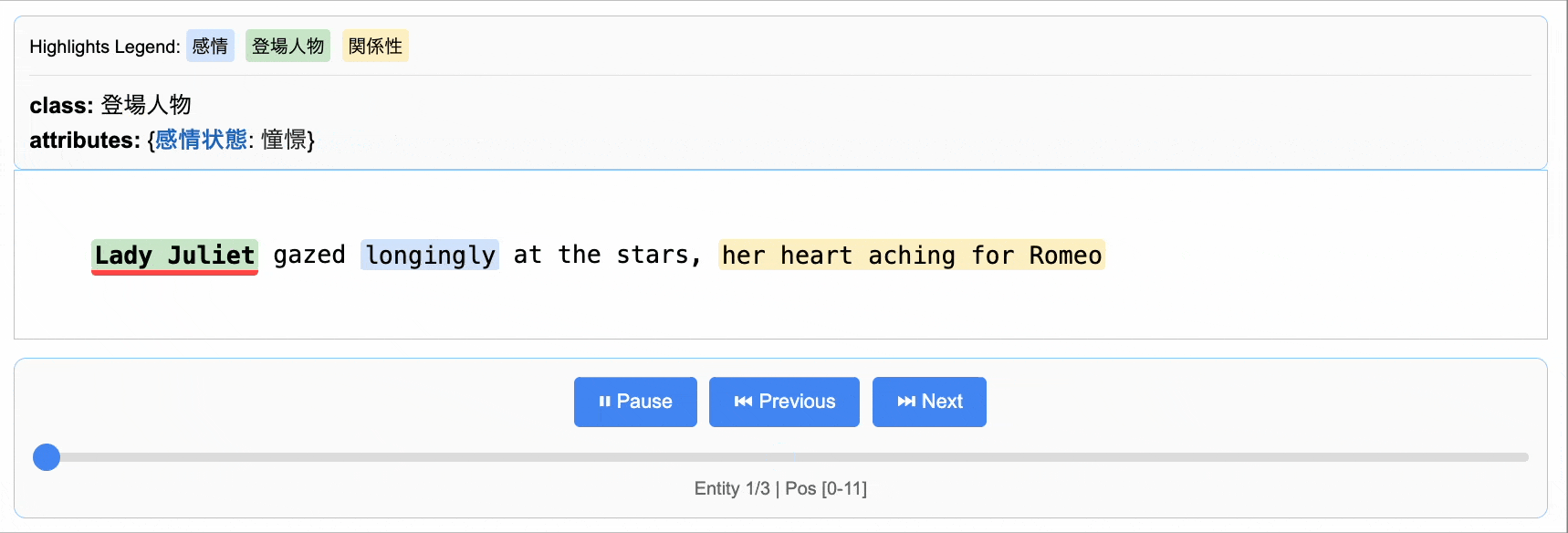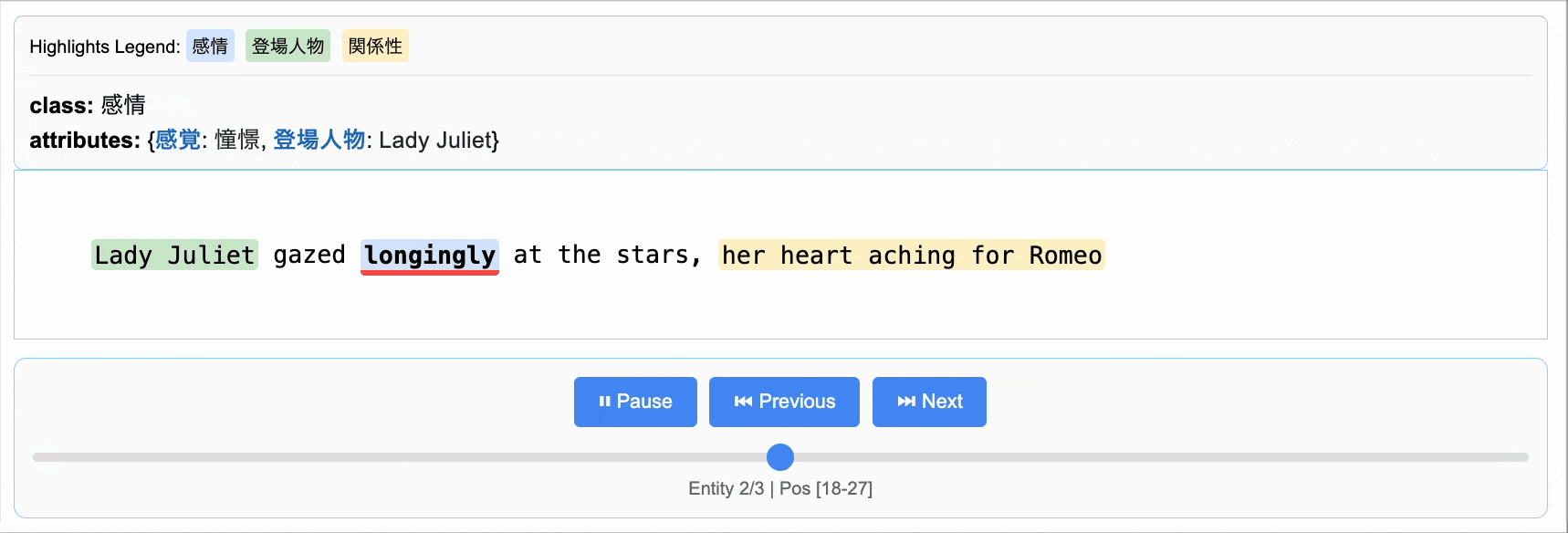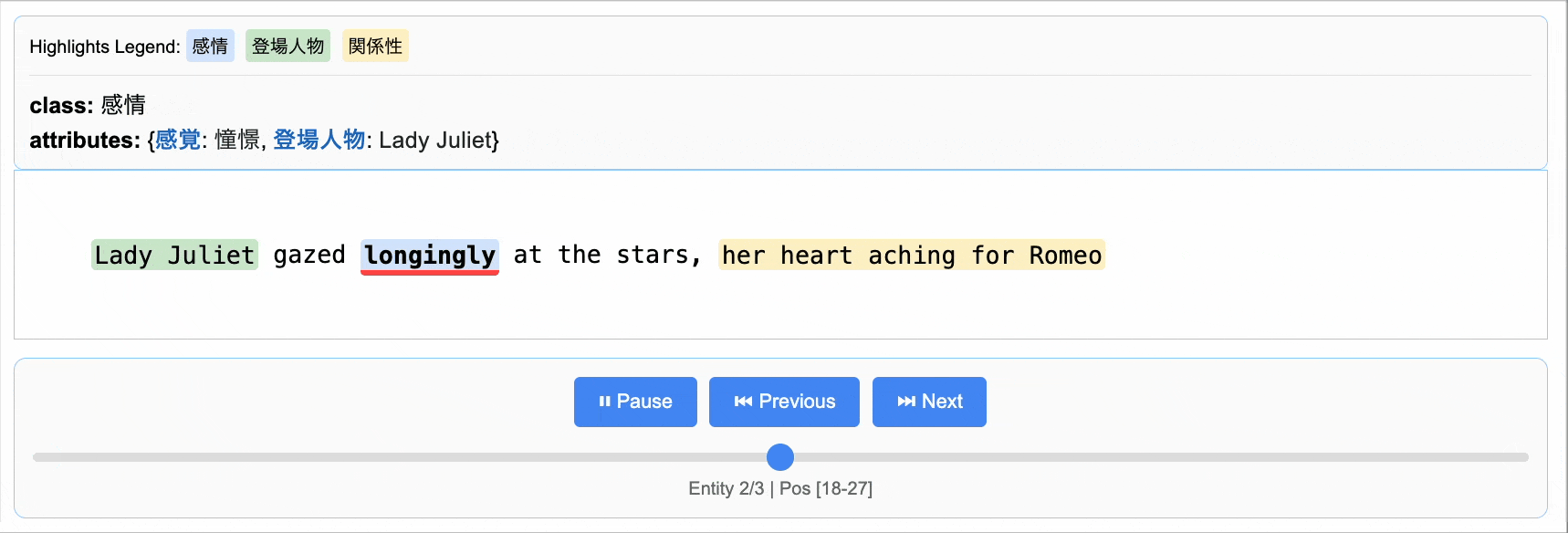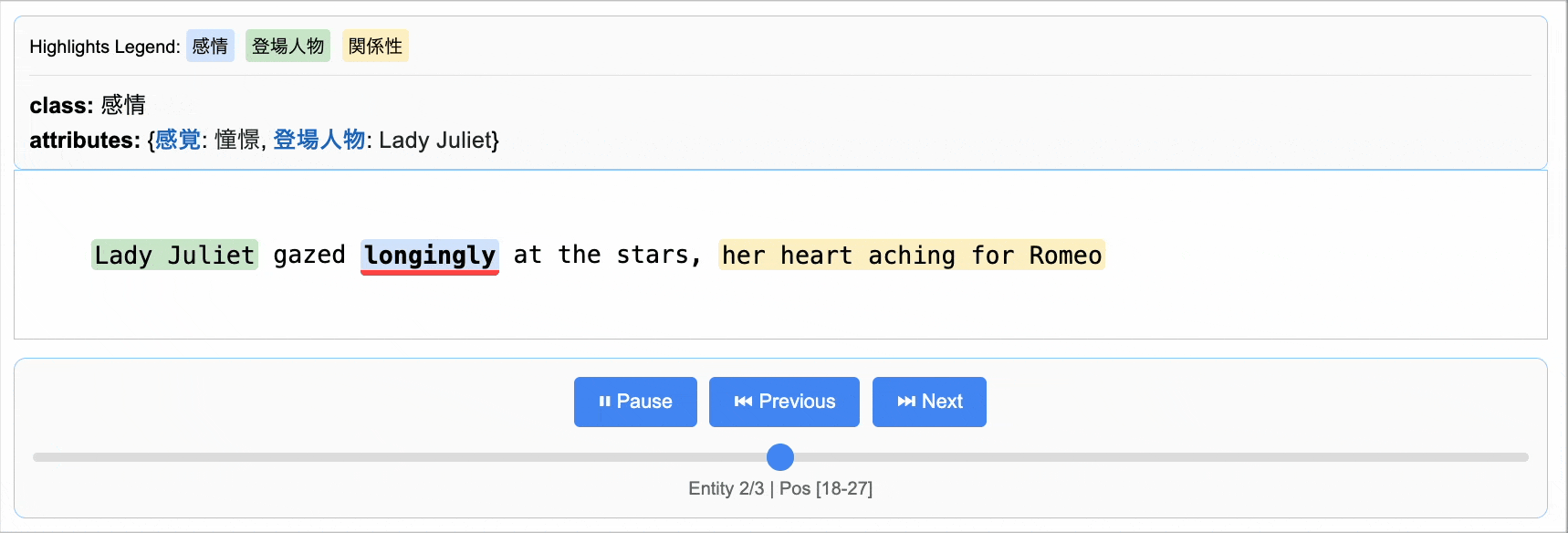
input_text = (
"Lady Juliet gazed longingly at the stars, her heart aching for Romeo"
)
result = lx.extract(
text_or_documents=input_text,
prompt_description=prompt,
examples=examples,
model_id="gemini-2.5-flash",
)
さて、抽出結果ですが以下のように構造化されており、後処理が容易です。
from pprint import pprint pprint(result.extractions)
[Extraction(extraction_class='登場人物',
extraction_text='Lady Juliet',
char_interval=CharInterval(start_pos=0, end_pos=11),
alignment_status=<AlignmentStatus.MATCH_EXACT: 'match_exact'>,
extraction_index=1,
group_index=0,
description=None,
attributes={'感情状態': '憧憬'}),
Extraction(extraction_class='感情',
extraction_text='longingly',
char_interval=CharInterval(start_pos=18, end_pos=27),
alignment_status=<AlignmentStatus.MATCH_EXACT: 'match_exact'>,
extraction_index=2,
group_index=1,
description=None,
attributes={'感覚': '憧憬', '登場人物': 'Lady Juliet'}),
Extraction(extraction_class='関係性',
extraction_text='her heart aching for Romeo',
char_interval=CharInterval(start_pos=42, end_pos=68),
alignment_status=<AlignmentStatus.MATCH_EXACT: 'match_exact'>,
extraction_index=3,
group_index=2,
description=None,
attributes={'登場人物1': 'Lady Juliet', '登場人物2': 'Romeo', '種類': '思慕'})]
また、結果をjsonl形式で保存し、それを元にHTMLで動的に可視化できます。
# Save the results to a JSONL file
lx.io.save_annotated_documents([result], output_name="extraction_results_sample_jp.jsonl", output_dir=".")
# Generate the interactive visualization from the file
html_content = lx.visualize("extraction_results_sample_jp.jsonl")
with open("extract_sample_jp.html", "w") as f:
f.write(html_content.__html__())
抽出した結果はこのように可視化して、元のテキストと照らし合わせながら内容を確認できます。
公開されているデモでは、Project Gutenbergで公開されているRomeo and Julietのテキスト全体を利用した抽出を行っています。5,000行を超えるテキストでおよそ44,000トークンに渡る長大なテキストです。ドキュメントの入力にはurlを指定します。
result = lx.extract(
text_or_documents="https://www.gutenberg.org/files/1513/1513-0.txt",
prompt_description=prompt,
examples=examples,
model_id="gemini-2.5-flash",
extraction_passes=3, # Multiple passes for improved recall
max_workers=20, # Parallel processing for speed
max_char_buffer=1000 # Smaller contexts for better accuracy
)

LangExtractで非構造化データから構造化データを抽出してみる
ニュース記事からの情報抽出
では、実験としてニュース記事を元に情報抽出を行ってみましょう。Yahooファイナンスの経済指標予測の記事を使います(「国内外の注目経済指標:日本の4-6月期GDP成長率はプラス転換か」)。この記事では以下のように発表日時と予測とコメントが記載されています。
■12日(火)午後9時30分発表予定
○(米)7月消費者物価コア指数-予想:前年比+3.0%
参考となる6月実績は前年比+2.9%。財の物価上昇率がやや目立った。7月については関税引き上げの影響が顕在化しはじめていることから、上昇率は6月実績を上回る可能性がある。
この文章から経済指標とその発表日時、予測値などの情報を抽出したいと思います。そのためにプロンプトは以下の様に指定しました。
prompt = textwrap.dedent("""\
与えられたテキストから、経済指標に関する情報を抽出してください。
抽出する情報は以下の通りです:
- 指標名(例:(米)7月消費者物価コア指数)
- 発表日時(例:12日(火)午後9時30分))
- 予測値(例:前年比+3.0%)
- 参考値(例:前年比+2.9%)
- 参考指標(例:6月実績)
注意:日本語の改行や句読点は無視してください。また、抽出する情報は必ずしもすべて含まれているとは限りません。可能な限り多くの情報を抽出してください。
""")
プロンプトに合わせて欲しい情報の構造を以下の様に例示しました。
examples = [
lx.data.ExampleData(
text=textwrap.dedent("""\
■12日(火)午後9時30分発表予定
○(米)7月消費者物価コア指数-予想:前年比+3.0%
参考となる6月実績は前年比+2.9%。財の物価上昇率がやや目立った。7月については関税引き上げの影響が顕在化しはじめていることから、上昇率は6月実績を上回る可能性がある。"""),
extractions=[
lx.data.Extraction(
extraction_class="指標名",
extraction_text="(米)7月消費者物価コア指数",
attributes={"経済指標": "(米)7月消費者物価コア指数"}
),
lx.data.Extraction(
extraction_class="発表日時",
extraction_text="12日(火)午後9時30分",
attributes={"経済指標": "(米)7月消費者物価コア指数"}
),
lx.data.Extraction(
extraction_class="予測値",
extraction_text="前年比+3.0%",
attributes={"経済指標": "(米)7月消費者物価コア指数"}
),
lx.data.Extraction(
extraction_class="参考値",
extraction_text="前年比+2.9%",
attributes={"経済指標": "(米)7月消費者物価コア指数"}
),
lx.data.Extraction(
extraction_class="参考指標",
extraction_text="6月実績",
attributes={"経済指標": "(米)7月消費者物価コア指数"}
),
]
)
]
抽出したい記事の文章は以下の通りです。
■14日(木)午後6時発表予定
○(欧)4-6月期域内総生産改定値-予想:前年比+1.4%。
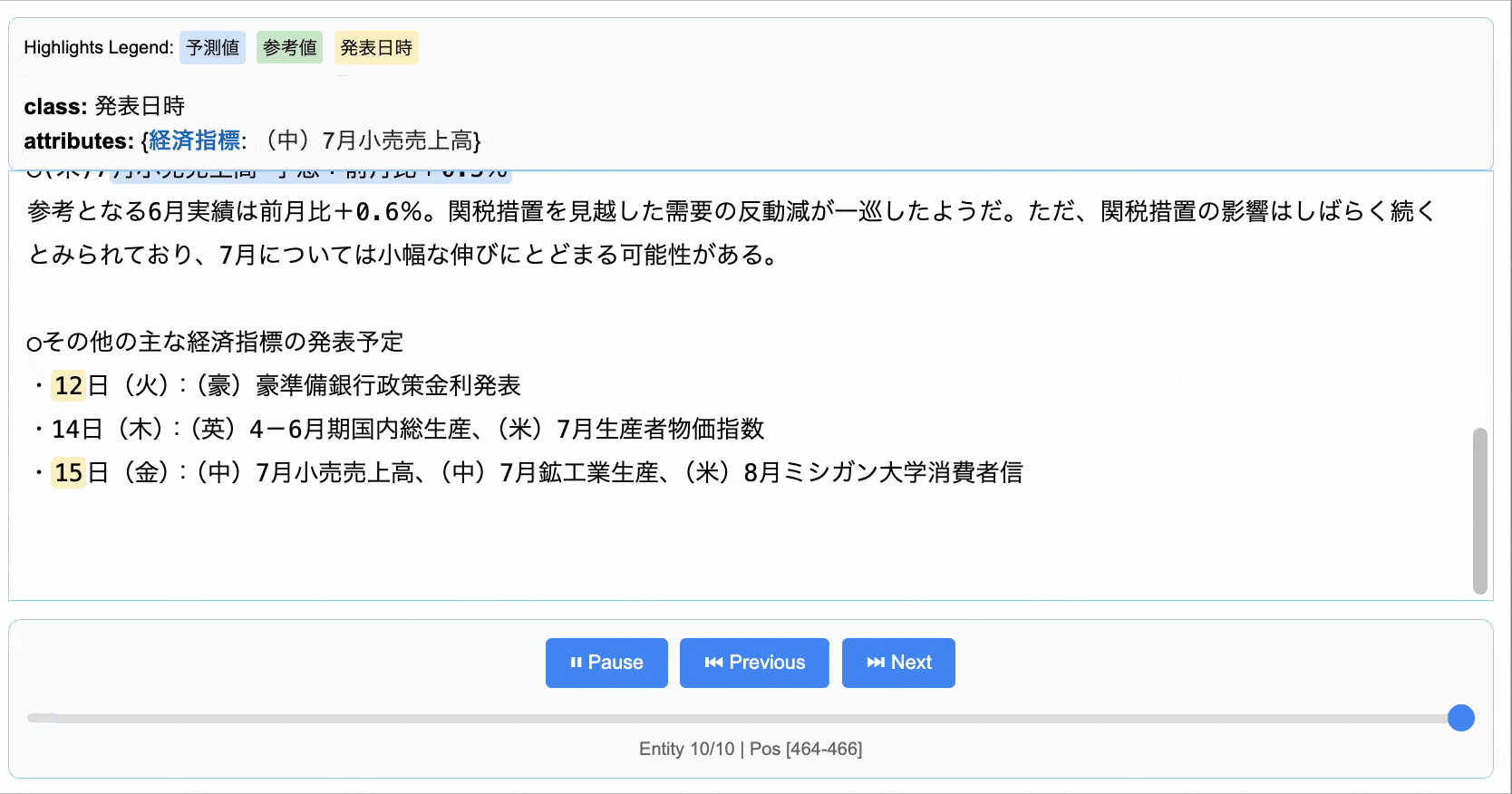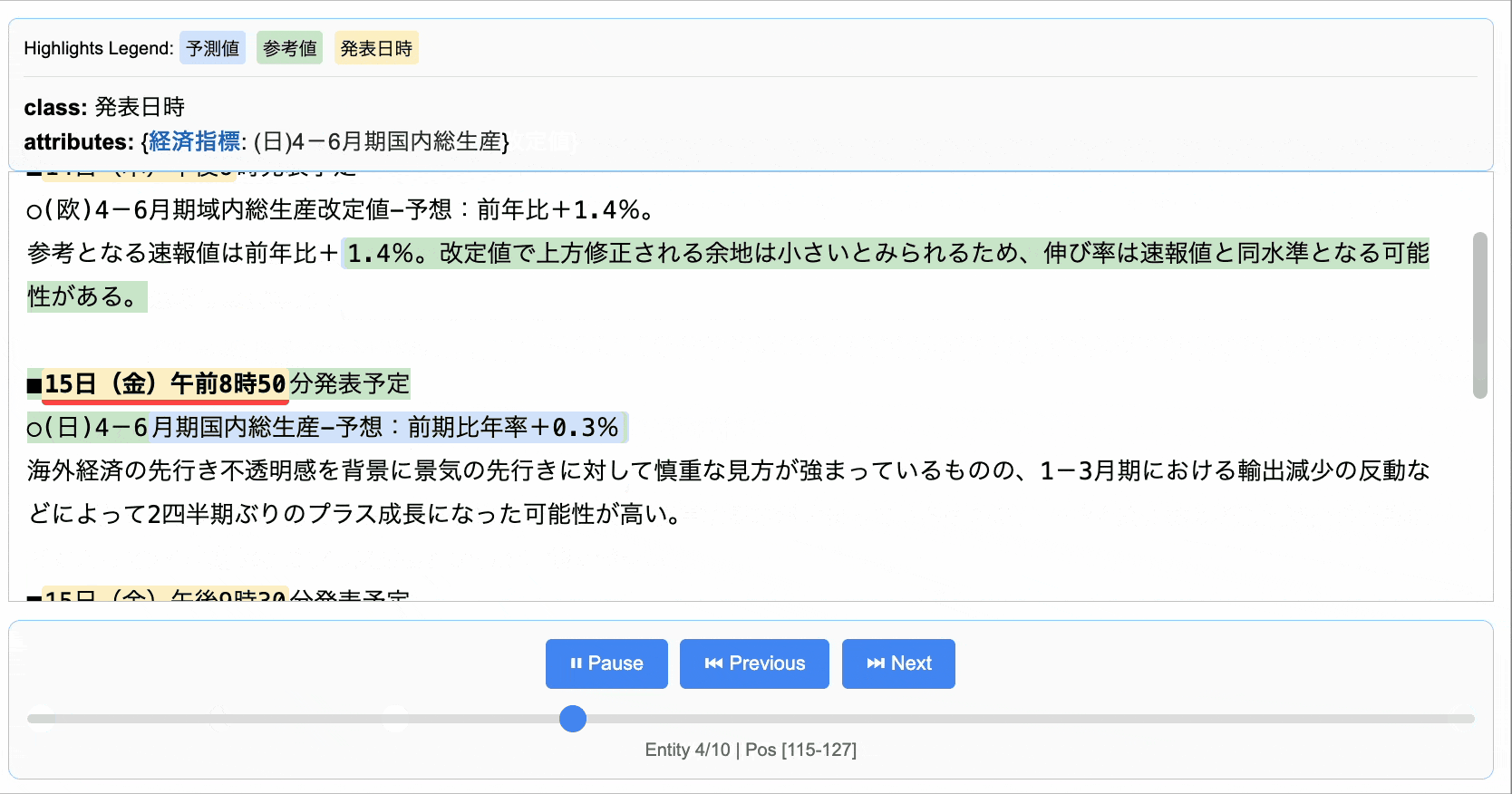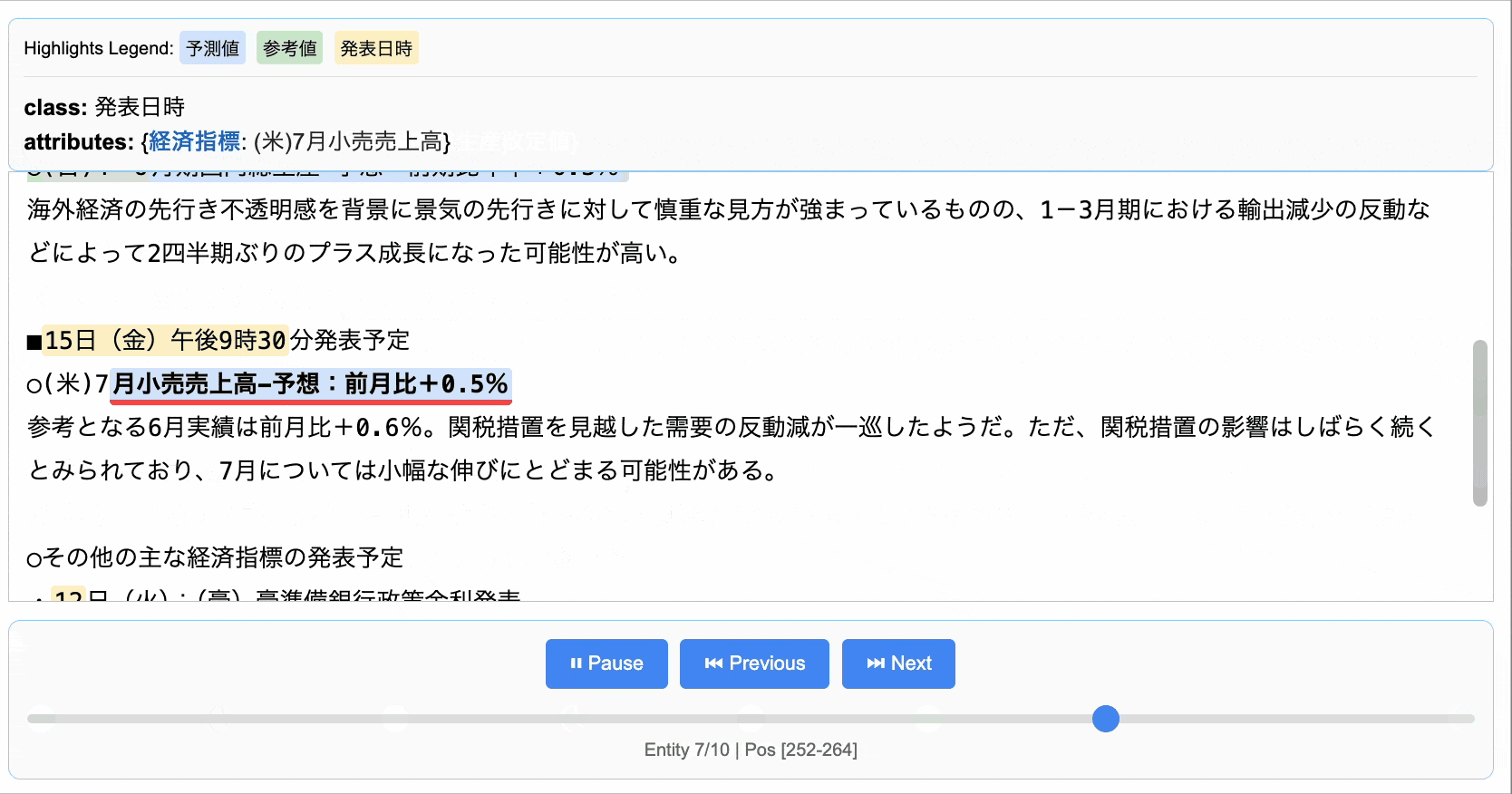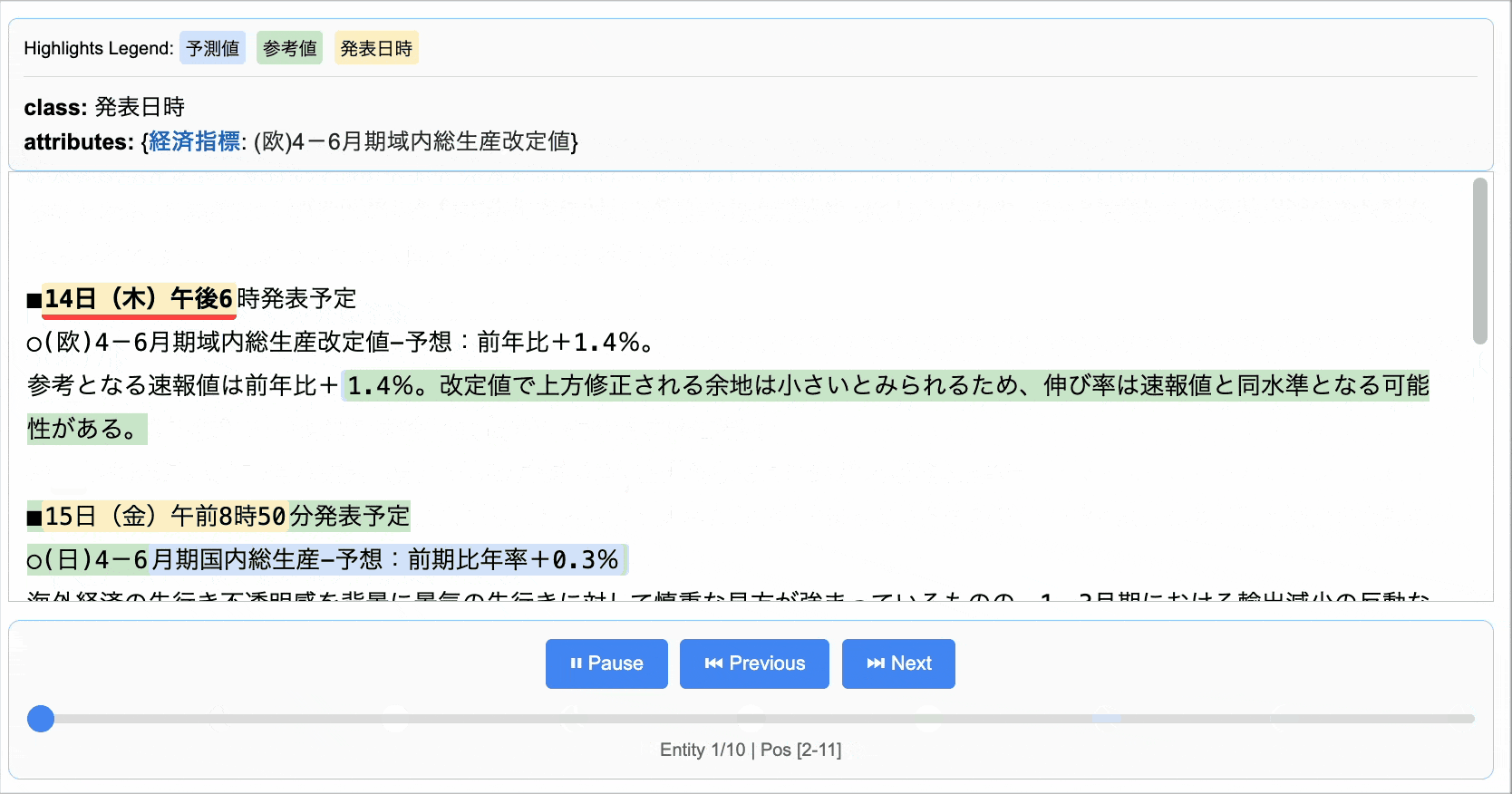
参考となる速報値は前年比+1.4%。改定値で上方修正される余地は小さいとみられるため、伸び率は速報値と同水準となる可能性がある。■15日(金)午前8時50分発表予定
○(日)4-6月期国内総生産-予想:前期比年率+0.3%
海外経済の先行き不透明感を背景に景気の先行きに対して慎重な見方が強まっているものの、1-3月期における輸出減少の反動などによって2四半期ぶりのプラス成長になった可能性が高い。■15日(金)午後9時30分発表予定
○(米)7月小売売上高-予想:前月比+0.5%
参考となる6月実績は前月比+0.6%。関税措置を見越した需要の反動減が一巡したようだ。ただ、関税措置の影響はしばらく続くとみられており、7月については小幅な伸びにとどまる可能性がある。○その他の主な経済指標の発表予定
・12日(火):(豪)豪準備銀行政策金利発表
・14日(木):(英)4-6月期国内総生産、(米)7月生産者物価指数
・15日(金):(中)7月小売売上高、(中)7月鉱工業生産、(米)8月ミシガン大学消費者信
では、抽出を実行してみます。結果は以下の通りとなりました。LLMが学習済みの経済指標に関する知識を利用しているためか、その他の経済指標に関しても問題なく抽出されています。またプロンプトの指示の通り、予測値がない場合でも発表日時までは抽出するなど、柔軟に対応ができています。このような処理は単純な正規表現では不可能ですね。
[Extraction(extraction_class='指標名', extraction_text='(欧)4-6月期域内総生産改定値', char_interval=None, alignment_status=None, extraction_index=1, group_index=0, description=None, attributes={'経済指標': '(欧)4-6月期域内総生産改定値'}),
Extraction(extraction_class='発表日時', extraction_text='14日(木)午後6時', char_interval=CharInterval(start_pos=2, end_pos=11), alignment_status=<AlignmentStatus.MATCH_LESSER: 'match_lesser'>, extraction_index=2, group_index=1, description=None, attributes={'経済指標': '(欧)4-6月期域内総生産改定値'}),
Extraction(extraction_class='予測値', extraction_text='前年比+1.4%', char_interval=CharInterval(start_pos=61, end_pos=161), alignment_status=<AlignmentStatus.MATCH_FUZZY: 'match_fuzzy'>, extraction_index=3, group_index=2, description=None, attributes={'経済指標': '(欧)4-6月期域内総生産改定値'}),
Extraction(extraction_class='参考値', extraction_text='前年比+1.4%', char_interval=CharInterval(start_pos=61, end_pos=161), alignment_status=<AlignmentStatus.MATCH_FUZZY: 'match_fuzzy'>, extraction_index=4, group_index=3, description=None, attributes={'経済指標': '(欧)4-6月期域内総生産改定値'}),
Extraction(extraction_class='参考指標', extraction_text='速報値', char_interval=None, alignment_status=None, extraction_index=5, group_index=4, description=None, attributes={'経済指標': '(欧)4-6月期域内総生産改定値'}),
Extraction(extraction_class='指標名', extraction_text='(日)4-6月期国内総生産', char_interval=None, alignment_status=None, extraction_index=6, group_index=5, description=None, attributes={'経済指標': '(日)4-6月期国内総生産'}),
Extraction(extraction_class='発表日時', extraction_text='15日(金)午前8時50分', char_interval=CharInterval(start_pos=115, end_pos=127), alignment_status=<AlignmentStatus.MATCH_LESSER: 'match_lesser'>, extraction_index=7, group_index=6, description=None, attributes={'経済指標': '(日)4-6月期国内総生産'}),
Extraction(extraction_class='予測値', extraction_text='前期比年率+0.3%', char_interval=CharInterval(start_pos=140, end_pos=161), alignment_status=<AlignmentStatus.MATCH_FUZZY: 'match_fuzzy'>, extraction_index=8, group_index=7, description=None, attributes={'経済指標': '(日)4-6月期国内総生産'}),
Extraction(extraction_class='指標名', extraction_text='(米)7月小売売上高', char_interval=None, alignment_status=None, extraction_index=9, group_index=8, description=None, attributes={'経済指標': '(米)7月小売売上高'}),
Extraction(extraction_class='発表日時', extraction_text='15日(金)午後9時30分', char_interval=CharInterval(start_pos=252, end_pos=264), alignment_status=<AlignmentStatus.MATCH_LESSER: 'match_lesser'>, extraction_index=10, group_index=9, description=None, attributes={'経済指標': '(米)7月小売売上高'}),
Extraction(extraction_class='予測値', extraction_text='前月比+0.5%', char_interval=CharInterval(start_pos=275, end_pos=293), alignment_status=<AlignmentStatus.MATCH_FUZZY: 'match_fuzzy'>, extraction_index=11, group_index=10, description=None, attributes={'経済指標': '(米)7月小売売上高'}),
Extraction(extraction_class='参考値', extraction_text='前月比+0.6%', char_interval=None, alignment_status=None, extraction_index=12, group_index=11, description=None, attributes={'経済指標': '(米)7月小売売上高'}),
Extraction(extraction_class='参考指標', extraction_text='6月実績', char_interval=None, alignment_status=None, extraction_index=13, group_index=12, description=None, attributes={'経済指標': '(米)7月小売売上高'}),
Extraction(extraction_class='指標名', extraction_text='(豪)豪準備銀行政策金利発表', char_interval=None, alignment_status=None, extraction_index=14, group_index=13, description=None, attributes={'経済指標': '(豪)豪準備銀行政策金利発表'}),
Extraction(extraction_class='発表日時', extraction_text='12日(火)', char_interval=CharInterval(start_pos=406, end_pos=408), alignment_status=<AlignmentStatus.MATCH_LESSER: 'match_lesser'>, extraction_index=15, group_index=14, description=None, attributes={'経済指標': '(豪)豪準備銀行政策金利発表'}),
Extraction(extraction_class='指標名', extraction_text='(英)4-6月期国内総生産', char_interval=None, alignment_status=None, extraction_index=16, group_index=15, description=None, attributes={'経済指標': '(英)4-6月期国内総生産'}),
Extraction(extraction_class='発表日時', extraction_text='14日(木)', char_interval=None, alignment_status=None, extraction_index=17, group_index=16, description=None, attributes={'経済指標': '(英)4-6月期国内総生産'}),
Extraction(extraction_class='指標名', extraction_text='(米)7月生産者物価指数', char_interval=None, alignment_status=None, extraction_index=18, group_index=17, description=None, attributes={'経済指標': '(米)7月生産者物価指数'}),
Extraction(extraction_class='発表日時', extraction_text='14日(木)', char_interval=None, alignment_status=None, extraction_index=19, group_index=18, description=None, attributes={'経済指標': '(米)7月生産者物価指数'}),
Extraction(extraction_class='指標名', extraction_text='(中)7月小売売上高', char_interval=None, alignment_status=None, extraction_index=20, group_index=19, description=None, attributes={'経済指標': '(中)7月小売売上高'}),
Extraction(extraction_class='発表日時', extraction_text='15日(金)', char_interval=CharInterval(start_pos=464, end_pos=466), alignment_status=<AlignmentStatus.MATCH_LESSER: 'match_lesser'>, extraction_index=21, group_index=20, description=None, attributes={'経済指標': '(中)7月小売売上高'}),
Extraction(extraction_class='指標名', extraction_text='(中)7月鉱工業生産', char_interval=None, alignment_status=None, extraction_index=22, group_index=21, description=None, attributes={'経済指標': '(中)7月鉱工業生産'}),
Extraction(extraction_class='発表日時', extraction_text='15日(金)', char_interval=None, alignment_status=None, extraction_index=23, group_index=22, description=None, attributes={'経済指標': '(中)7月鉱工業生産'}),
Extraction(extraction_class='指標名', extraction_text='(米)8月ミシガン大学消費者信', char_interval=None, alignment_status=None, extraction_index=24, group_index=23, description=None, attributes={'経済指標': '(米)8月ミシガン大学消費者信'}),
Extraction(extraction_class='発表日時', extraction_text='15日(金)', char_interval=None, alignment_status=None, extraction_index=25, group_index=24, description=None, attributes={'経済指標': '(米)8月ミシガン大学消費者信'})]
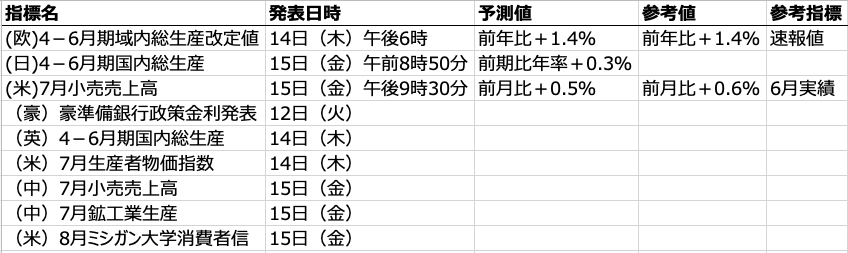
元のニュース記事からちゃんと情報を抽出して構造化できました。なお、HTMLの可視化では以下の通りで日本語の場合、一部の出力が変になっていますが、データの抽出自体は上記の表の通り正しく行われています。
売上報告レポートからの数値の抽出
さて、このようなある製品の月次売上とその考察に関する長大なレポートが来ました。これから月次の売上や増加率を抽出していきます。
FitLife Pro X1は2024年4月に市場投入され、発売初月として1億2,000万円の売上を記録しました。製品発表から実際の販売開始まで約2週間の準備期間を要したため、実質的な販売期間は3週間程度でした。この期間における週平均売上は約4,000万円となり、新製品としては順調なスタートを切ることができました。発売初月の売上を支えたのは、事前予約による初期需要でした。製品発表会での好評価と、主要テクノロジーメディアでの肯定的なレビューにより、健康志向の高いアーリーアダプター層からの強い関心を集めました。特に、従来製品と比較して大幅に改善されたバッテリー持続時間と、日本人の体型に最適化されたフィット感が高く評価され、口コミによる拡散効果も見られました。
5月は前月比54%増となる1億8,500万円の売上を達成し、製品への市場の受容度の高さを証明しました。この大幅な売上増加の背景には、複数の要因が組み合わさって相乗効果を生んだことがあります。最も大きな影響を与えたのは、有名フィットネスインフルエンサーによる製品紹介動画の公開でした。YouTubeとInstagramで合計200万回以上の視聴を記録し、30代から40代の健康意識の高い層への認知度が急激に向上しました。また、ゴールデンウィーク期間中の健康管理への関心の高まりと、新年度開始による新生活準備需要も売上押し上げ要因となりました。販売チャネル別では、オンライン直販が特に好調で、前月比67%増を記録しました。これは製品の詳細情報と使用方法を動画で紹介するコンテンツマーケティングの効果が現れた結果と分析されます。(中略)…
6月は前月比15%増の2億1,200万円となり、安定した成長軌道に入りました。この月は梅雨シーズンにもかかわらず売上が伸長したことで、製品への継続的な需要があることが確認できました。売上成長の主要因は、企業の健康経営推進による法人需要の本格化でした。従業員の健康管理ツールとして複数の企業から大口注文を受注し、B2B市場での存在感を示すことができました。特に製造業とIT企業からの引き合いが強く、従業員福利厚生の一環として導入されるケースが増加しました。また、父の日ギフト需要も6月後半の売上を支えました。健康管理への意識が高まる50代男性をターゲットとした特別パッケージが好評で、ギフト用途での購入が全体の18%を占めました。
7月は前月比22%増の2億5,800万円を達成し、夏季需要の本格化を反映した力強い成長を示しました。この月の売上増加は、季節的要因と戦略的マーケティング施策の両方が効果的に機能した結果でした。夏季休暇シーズンに向けた健康管理への関心の高まりが、売上の大きな押し上げ要因となりました。海やプールでの使用に対応した防水機能と、炎天下でも見やすいディスプレイ性能が市場で高く評価されました。また、夏祭りや花火大会などのイベント会場での着用写真がSNSで拡散され、若年層への認知度向上にも寄与しました。販売促進策として実施した「夏の健康チャレンジキャンペーン」も奏功しました。購入者限定のオンラインフィットネスプログラムと連携したプロモーションにより、製品の付加価値を効果的にアピールできました。
8月は前月比13%増の2億9,100万円となり、夏季需要のピークを迎えました。お盆休み期間を含む長期休暇中の健康管理意識の高まりと、帰省時のギフト需要が売上を支える主要因となりました。特筆すべきは、睡眠分析機能への評価の高まりです。夏季の暑さによる睡眠の質の低下を懸念する消費者が増加し、製品の高精度な睡眠モニタリング機能が注目を集めました。医療従事者からの推奨も増え、健康管理ツールとしての信頼性が市場で認知されました。家電量販店での店頭販売も好調で、実際に製品を手に取って確認したいという消費者ニーズに応えることができました。週末の店頭デモンストレーションでは、体験後の購入率が72%という高い数値を記録しました。
9月は前月比8%増の3億1,500万円となり、初めて月間売上3億円の大台を突破しました。夏季から秋季への季節の変わり目において、健康管理への継続的な関心が維持されたことを示す結果となりました。この月の売上成長を牽引したのは、企業の健康経営推進による大型受注の増加でした。年度後半の予算執行時期と重なり、従業員向けの健康管理ツール導入が本格化しました。特に大手商社と金融機関からの大口受注により、B2B売上が前月比35%増となりました。また、新学期シーズンに合わせた学生・教職員向けの特別価格プログラムも好評でした。大学生協での取り扱い開始により、若年層への市場浸透が進み、将来的な顧客基盤拡大への基礎を築くことができました。
10月は前月比9%増の3億4,200万円を達成し、安定した成長を継続しました。スポーツの秋という季節的要因と、年末商戦に向けた準備需要が重なり、堅調な売上推移を維持しました。マラソンシーズンの本格化により、ランニング愛好家からの需要が急増しました。GPS機能の精度と、長時間使用でも快適なフィット感が評価され、スポーツ用品店での売上が前月比28%増となりました。また、各地のマラソン大会でのスポンサーシップ活動により、ブランド認知度のさらなる向上を実現しました。健康診断シーズンとの連動も売上押し上げ要因となりました。定期健康診断の結果を受けて健康管理を見直す消費者が増加し、日常的な健康モニタリングツールとしての需要が高まりました。
11月は前月比14%増の3億8,900万円となり、年末商戦の前哨戦として力強い成長を示しました。この時期の売上増加は、ホリデーシーズンに向けたギフト需要の本格化と、一年間の健康管理の総仕上げとして製品を求める消費者心理が反映された結果でした。年末年始の贈り物として選ばれるケースが急増し、ギフト包装の依頼が前月比45%増となりました。特に親から成人した子どもへ、また夫婦間での健康を気遣う贈り物としての需要が顕著でした。限定カラーのローズゴールドモデルが特に人気を集め、発売から2週間で完売となりました。企業のボーナス支給時期と重なったことも、個人購入の増加につながりました。自分への投資として健康管理ツールを購入する消費者が増え、高機能モデルの売上比率が向上しました。12月は前月比8%増の4億2,000万円を記録し、年間を通じて最高の月間売上を達成しました。年末商戦の本格化により、ギフト需要と自己購入需要の両方が最高潮に達した結果、過去最高の売上実績を実現することができました。クリスマスプレゼントとしての需要が全体の35%を占め、特に若年カップル間での贈り物として人気を集めました。恋人同士でペアで購入するケースが増加し、カップル向けの特別パッケージが好評を博しました。SNSでのペア写真投稿も話題となり、ブランドの若年層への浸透を促進しました。年末の健康管理意識の高まりも売上を押し上げました。新年からの健康的な生活を目指す消費者が多数製品を購入し、「新年の抱負」関連のマーケティングキャンペーンが大きな効果を発揮しました。また、一年間のボーナス支給により購買力が向上したことも、高額商品への需要増加につながりました。(generated by Claude)
この文章の場合、金額が「1億8,500万円」と記載されており、そのまま文字列を抽出しても不便ですので、指示を工夫して百万円単位で抽出してもらいます。このような融通が効くこともLLMがバックエンドで動いているLangExtractの強みです。
prompt = textwrap.dedent("""\
与えられた売り上げ報告書から以下の情報を抽出してください。
抽出する情報は以下の通りです:
- 月別売上
- 前月比(可能であれば)
注意:日本語の改行や句読点は無視してください。また、抽出する情報は必ずしもすべて含まれているとは限りません。可能な限り多くの情報を抽出してください。
金額は「百万円」単位で数値として抽出してください。
例:1億5,000万円 → 150
""")
examples = [
lx.data.ExampleData(
text=textwrap.dedent("""\
5月は前月比54%増となる1億8,500万円の売上を達成し、製品への市場の受容度の高さを証明しました。この大幅な売上増加の背景には、複数の要因が組み合わさって相乗効果を生んだことがあります。
"""),
extractions=[
lx.data.Extraction(
extraction_class="月別売上",
extraction_text="5月は前月比54%増となる1億8,500万円の売上",
attributes={"月": "5", "売上(百万円)": "185", "前月比[%]": "54"}
),
],
),
]
結果は以下の通りです。期待通り、月別の売り上げの数値が百万円単位で数値として抽出できました。前月比も「+何々パーセント」ではなく、数値のみが抽出できています。
[Extraction(extraction_class='月別売上', extraction_text='FitLife Pro X1は2024年4月に市場投入され、発売初月として1億2,000万円の売上を記録しました。', char_interval=CharInterval(start_pos=1, end_pos=45), alignment_status=<AlignmentStatus.MATCH_LESSER: 'match_lesser'>, extraction_index=1, group_index=0, description=None, attributes={'月': '4', '売上(百万円)': '120'}),
Extraction(extraction_class='月別売上', extraction_text='5月は前月比54%増となる1億8,500万円の売上を達成し、製品への市場の受容度の高さを証明しました。', char_interval=CharInterval(start_pos=334, end_pos=354), alignment_status=<AlignmentStatus.MATCH_LESSER: 'match_lesser'>, extraction_index=2, group_index=1, description=None, attributes={'月': '5', '売上(百万円)': '185', '前月比[%]': '54'}),
Extraction(extraction_class='月別売上', extraction_text='6月は前月比15%増の2億1,200万円', char_interval=CharInterval(start_pos=697, end_pos=715), alignment_status=<AlignmentStatus.MATCH_LESSER: 'match_lesser'>, extraction_index=1, group_index=0, description=None, attributes={'月': '6', '売上(百万円)': '212', '前月比[%]': '15'}),
Extraction(extraction_class='月別売上', extraction_text='7月は前月比22%増の2億5,800万円', char_interval=CharInterval(start_pos=1013, end_pos=1031), alignment_status=<AlignmentStatus.MATCH_LESSER: 'match_lesser'>, extraction_index=2, group_index=1, description=None, attributes={'月': '7', '売上(百万円)': '258', '前月比[%]': '22'}),
Extraction(extraction_class='月別売上', extraction_text='8月は前月比13%増の2億9,100万円', char_interval=CharInterval(start_pos=1359, end_pos=1377), alignment_status=<AlignmentStatus.MATCH_LESSER: 'match_lesser'>, extraction_index=3, group_index=2, description=None, attributes={'月': '8', '売上(百万円)': '291', '前月比[%]': '13'}),
Extraction(extraction_class='月別売上', extraction_text='9月は前月比8%増の3億1,500万円', char_interval=CharInterval(start_pos=1670, end_pos=1687), alignment_status=<AlignmentStatus.MATCH_LESSER: 'match_lesser'>, extraction_index=1, group_index=0, description=None, attributes={'月': '9', '売上(百万円)': '315', '前月比[%]': '8'}),
Extraction(extraction_class='月別売上', extraction_text='10月は前月比9%増の3億4,200万円', char_interval=CharInterval(start_pos=1984, end_pos=2002), alignment_status=<AlignmentStatus.MATCH_LESSER: 'match_lesser'>, extraction_index=2, group_index=1, description=None, attributes={'月': '10', '売上(百万円)': '342', '前月比[%]': '9'}),
Extraction(extraction_class='月別売上', extraction_text='11月は前月比14%増の3億8,900万円', char_interval=CharInterval(start_pos=2303, end_pos=2322), alignment_status=<AlignmentStatus.MATCH_LESSER: 'match_lesser'>, extraction_index=3, group_index=2, description=None, attributes={'月': '11', '売上(百万円)': '389', '前月比[%]': '14'}),
Extraction(extraction_class='月別売上', extraction_text='12月は前月比8%増の4億2,000万円を記録', char_interval=CharInterval(start_pos=2640, end_pos=2658), alignment_status=<AlignmentStatus.MATCH_LESSER: 'match_lesser'>, extraction_index=1, group_index=0, description=None, attributes={'月': '12', '売上(百万円)': '420', '前月比[%]': '8'})]
読みやすく整理すると、この様になります。

まとめ
今回のブログでは、Googleの発表したOpen Sourceの情報抽出ライブラリLangExtractを紹介しました。LangExtractは、GeminiなどのLLMをバックエンドに非構造データから構造化された情報を手軽に抽出できるPythonライブラリです。タスクのプロンプトと抽出したいデータ構造を設定し、few-shotの例を提示することで、意図した情報を抽出できます。また、結果をjsonl形式で出力し、HTML形式でデータの抽出状況を可視化しヒトが確認しやすい形で結果を確認できます。ChatGPTやClaudeなどでのLLMを利用しての文章からの情報抽出は可能ですが、その正確性の確認は手間で、下流の分析やデータの利活用が不便であったことを考えると、LangExtractは非常に便利なツールです。
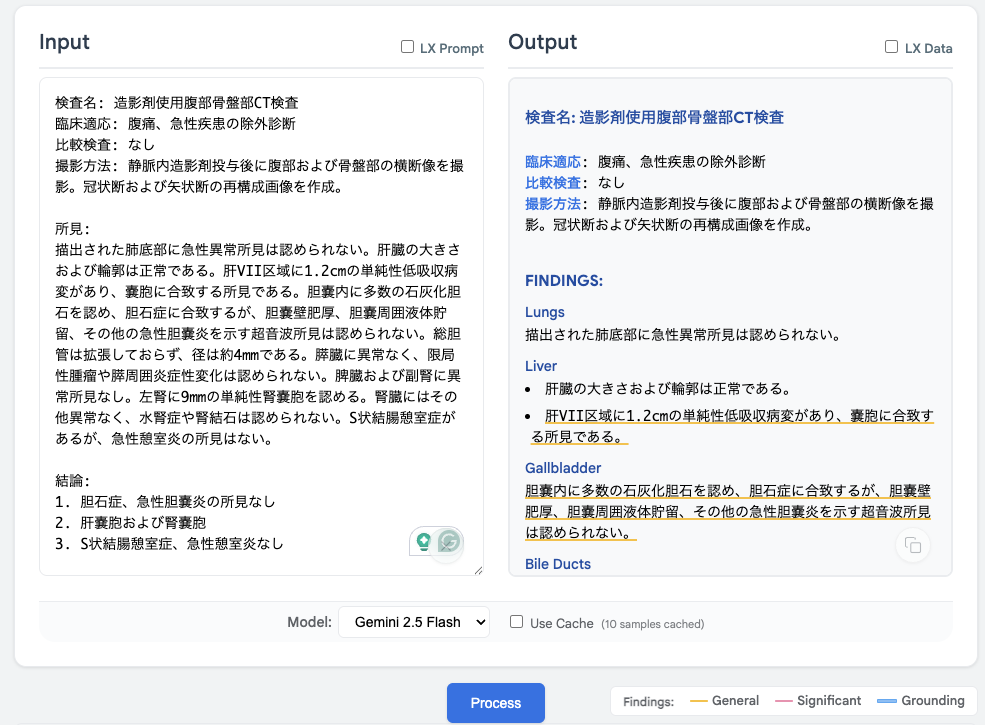
今回の例では単純にデータを抽出するのみでしたが、入力データと下流のタスク次第で様々な応用が考えられます。その例として公式リポジトリでは、画像診断報告書を構造化されたレポート化するアプリケーション(RadExtract)が公開されています。所見に書かれている情報を臓器別にポイントをまとめ直し、わかりやすい形式のレポートへと変換されています。
最後に
グループ研究開発本部 AI研究開発室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務などAI研究開発室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ募集職種一覧からご応募をお願いします。皆さんのご応募をお待ちしています。

参考資料
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD