2019.01.04
NeuralProcessの画像補間への応用
あけおめ、ことよろ、次世代システム研究室のK.Nです。今回は、前回紹介したGarnelo et alらによるNeuralProcessの続きで、画像補間のデモを行いました。画像補間とは、画像内の一部の画素から画像全体の画素を推定を行うというものです。
今回は、いわゆるやってみた的な内容で、前回のブログと比べて特に新しい内容はございません。検証の細かい点について知りたい方は、実装コードを見るのが早いと思いますのでこちらをご参考ください。
前提
NeuralProcessとは、簡単にNeuralNetwork(NN)関数で条件付き分布を表したものと言うことができると思います。
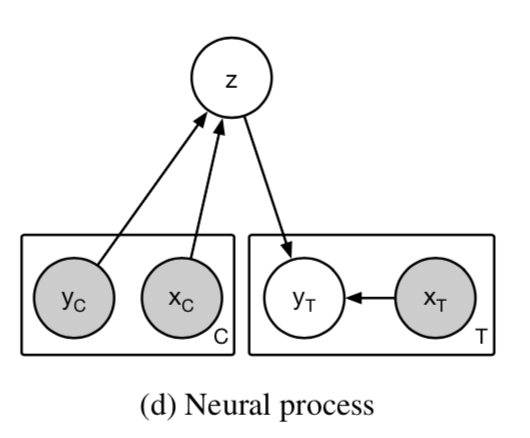
より具体的に言うと、教師ラベル付きの観測データがC={(x,y)}が与えられたとき、ターゲットとなる未観測のxに対するyを予測する確率モデルp(y|x,C)をNN関数で構築することを意味します。また、これは関数空間上の関数f: x -> yに対して確率分布p(f)が定義され、観測データCが与えられたときの条件づき分布p(f|C)に従う関数fに対してy=f(x)を与えるとみなすことができます。
代表的な確率過程の応用であるガウス過程は、p(y|x) = N(m(x), K(x))のようにyはxの関数で与えられる平均と共分散を持つ多次元正規分布に従うと仮定し、未観測のyを条件づき分布p(y|x,C)で計算します。これは、正規分布の性質により解析的に計算できます。
ガウス過程のメリットとして、訓練が必要ない、十分なデータがあれば精度が良い、がありますが、逆にデメリットは、学習データを保持する必要がある、カーネル関数では表現できる関数に制限がある、が挙げられます。特に、ガウス過程ではデータ間の相関関係はカーネル関数と呼ばれるxの座標空間上の距離に依存する関数によって決まり、互いのxの距離が近いほど、yも近い値を取りやすいという性質を示します。このため、画像のように画素間でより複雑な相関関係を持つようなデータに対しては、有効ではありません。カーネル関数のパラメータを最尤推定するという方法もありますが、ベースが正規分布であるので表現力に限界があります。
NeuralProcessでは観測データをNN関数でエンコーディング後、集約した確率変数を通して、関数の条件付けをしています。モデルの学習は必要になりますが、関数に対する分布をデータから学習できるので、うまく学習すれば少ない観測データで関数を推定できる(fewshot-learning)というメリットがあります。NeuralProcessの応用として、前回はsin系の関数形を数点の情報で関数形全体を推定するというデモを行いました。今回は画像への応用ということで、画像中の画素の一部の情報から画像全体の画素の推定を行います。
デモ
NeuralProcessの画像補間のデモを紹介します。DLフレームワークは以前と同じpytorchです。実装はgithubを御覧ください。環境はGCP Google Deep Learning VM, GPUはTesla K80, 2 GPUです。
データ
ここでは、画像データにMNISTとCELEBAを使用します。MNISTは白黒の手書き文字、CELEBAは著名人の顔の切り抜き写真になります。画像サイズはそれぞれ、1x28x28、1x64x64です。CELEBAは予め加工して、そのサイズになるようにしています。画像データはNPに与えられる形に変更する必要があります。元々のフォーマットは[C, H, W] (C: カラーチャンネル、H: 高さ、W: 幅)になってますが、画素一点ごとに対して、その座標を表すベクトルxとその位置に対応する画素yに変換します。xの定義域が[0,1]になるようは、幅と高さは正規化します。画像一枚に対して、(x,y)_n,(n=H*W)というデータ点の集合が対応します。

モデル
NNのモデルの構成は以下のとおりです。
エンコーダー: 128次元の4層の隠れ層。活性化関数は、隠れ層にReluを使用、出力層にはなし。
デコーダー:128次元の第2層の隠れ層、活性化関数は、隠れ層にReluを、出力層はSigmoidを使用
結果
MNIST
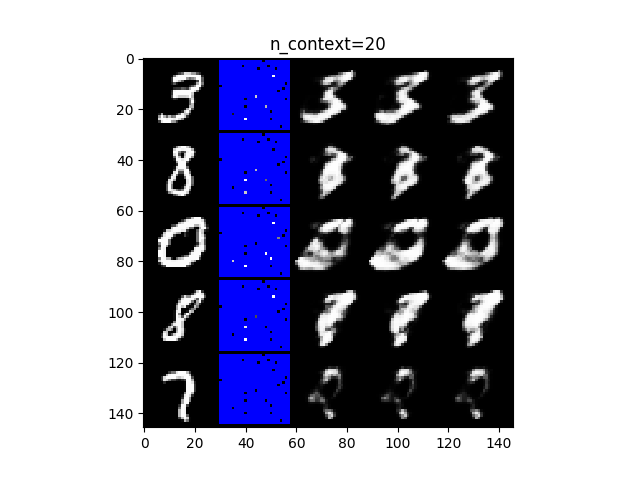
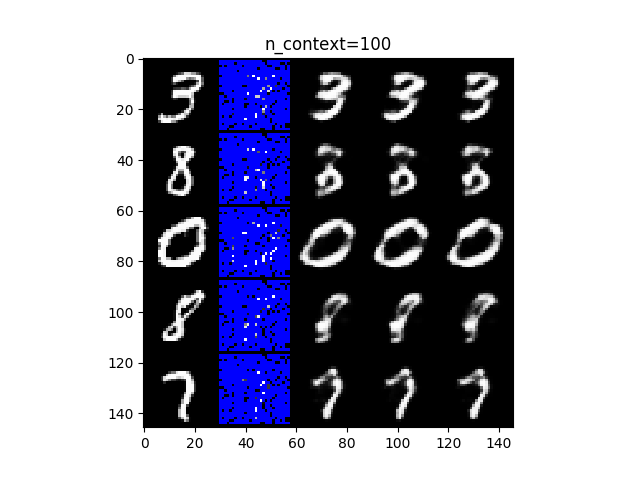
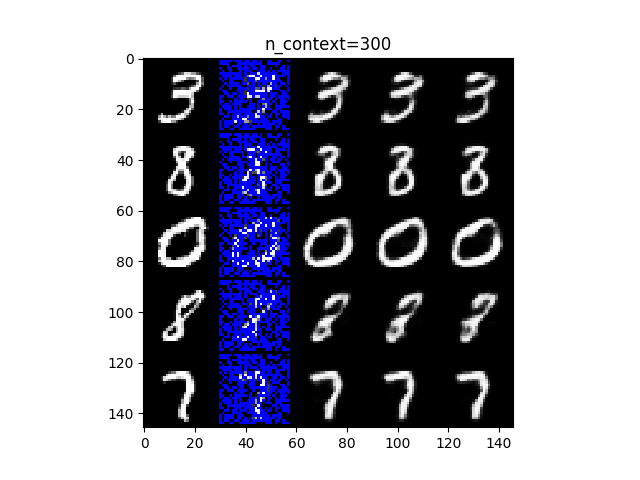
まずは、MNISTの結果です。上図は20点(左)、100点(中)、300点(右)の画素データで条件づけたときの結果になります。図それぞれにおいて、左の列は元のデータ、右隣の列はモデルの予測のために与えられた条件データです。それ以外の箇所は青色でマスクしています。残りの右隣3列は、モデルから得られたサンプルになります。一見して、条件データの数が多いほど、サンプルが明瞭になります。100点以降は、すべてのサンプルにおいて判断できるほど明瞭に再現できていることがわかります。20点では、3と0が(広い心でみれば)判断がつきそうです。条件データだけでは、まったく判断できそうもないことを踏まえると、これは優れた復元性能ではないでしょうか。
CELEBA
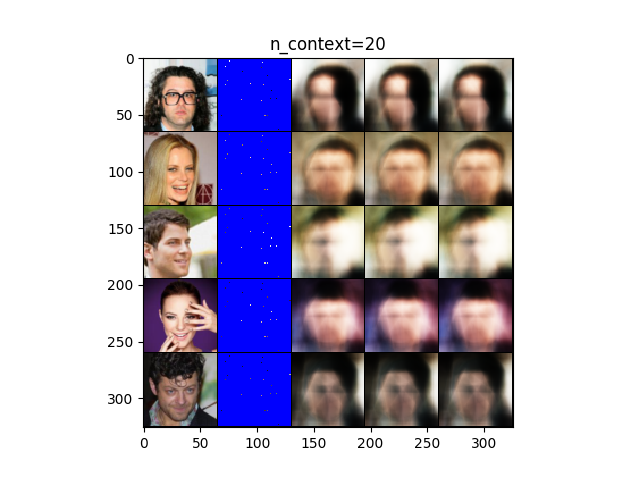
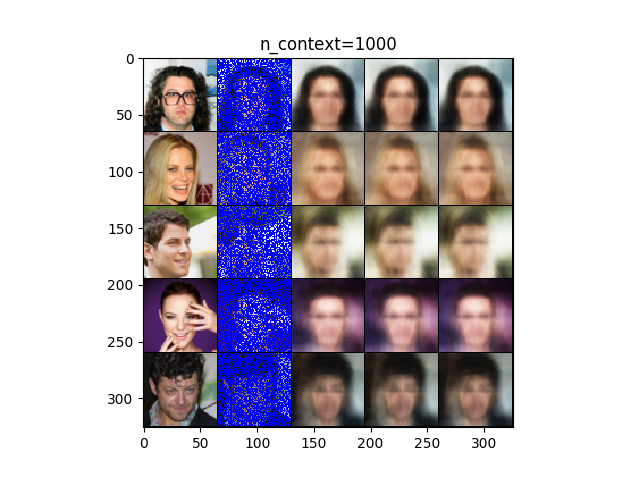
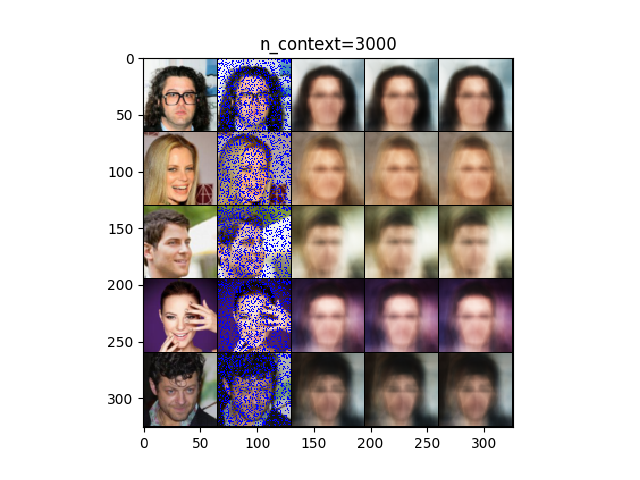
上図はCELEBAの結果(20点(左)、1000点(中)、3000点(右))になります。20点ですでに大体の顔の輪郭を捉えていることがわかります。1000点では大体性別を判定できるほどまでは復元しています。3000点では、多少はっきりしたものの1000点の結果と大差ありません。画像もおぼろげのままになっています。参考にした論文の図はもう少し鮮明な結果だったので、学習の方法が良くなかったかもしれません。ちなみに、訓練中にlossが発散することが何度かあったので、何かしら有効な正規化の方法を取ることで効果があるかもしれません。
以上、ここでは、NeuralProcessの画像補間の例を紹介しました。実は、今回の結果で示したように、画像が不明瞭になるという問題は既に指摘されていて、新たに出た論文では、NeuralProcessにattentionの仕組みを応用して、この問題を克服したという報告がなされています。次回以降は、それの紹介か、また別な深層生成モデルをテーマにしたいと思います。
最後に
次世代システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧からご応募をお願いします。一緒に勉強しながら楽しく働きたい方のご応募をお待ちしております。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD