2018.10.01
メタ学習(meta-learning)の紹介:Regression版で今年の東京の気温を当ててみました~
こんにちは。次世代システム研究室のK.S.(女性、外国人)です。
夏休みはいかがでしたか? 暑い日々がそろそろ終わり、これからは涼しくなって行くでしょう。では、来月の気温はどれくらいになるでしょうか? 気温がよい感じで下がってくれれば、秋には綺麗な紅葉が見られるかな? 紅葉を楽しみにしているので、機械学習の関連技術を利用し、東京の気温を予測してみたいなあと思いました。
最近、International Conference on Learning Representations (ICLR)といった有名な機械学習の学会が去年の3つの最優秀論文を発表しました。その中の一つは メタ学習についての論文 でした。発表結果を聞いて、え、meta-learningってなんですか? なぜ、注目されてきて、ベスト論文になれたのでしょうか? 疑問をお持ちになりませんでしたか? 私は少し気になってきて、この技術を深く勉強したいなあと思いました。
ということで、今回のブログでは、上記の二つ気になったことを合わせて、メタ学習(meta-learning)についての情報を共有し、この技術を使って東京の気温を予測してみたいと思います。このブログの構成は、以下のとおりです。
① メタ学習(meta-learning)とは?
② Model-Agnostic Meta-Learning (MAML)の紹介
③ 東京の気温の予測
④ まとめと考察
まず、メタ学習を簡単に紹介します。次に、Model-Agnostic Meta-Learning (MAML)というメタ学習でよく使われている有名なアルゴリズムを説明させて頂きます。それから、MAMLの実装例として、今年の東京の気温を予測します。最後、まとめと考察になります。
① meta-learning(メタ学習)とは?
メタ学習(meta-learning)は学習方法を学習すること(learning to learn)です。わかりやすくするため、人が学習することを例にします。人が学習するとは人間が繰り返して教科書を読んだり、テストをしたり、することですが、学習プロセスは人間が他の人の勉強する方法(勉強計画、勉強時間、教科書の読み方、暗記方法、など)を学んで適応するような感じになります。同じ教科書を繰り返して読むより、よりよい読み方がわかれば、最も効率的に教科書内容を吸収できると考えられるのです。機械学習は、コンピューターがデータから反復的に学習し、人が気づいていなかったデータの中に隠れた情報やパターンを見つけ出します。そこで、メタ学習は機械の学習能力を高めるのを目的として、学習プロセスを学んでいくということです。
具体的に、メタ学習はどういう感じに行うのかをお話させて頂きます。Thomas Wolfさんのブログ とberkeley大学のブログ の説明がわかりやすかったので、参考にさせて頂きます。
学習プロセス
このセクションでは従来の機械学習の一つであるディープラーニング(深層学習)の学習プロセスのおさらいです。
機械学習はコンピューターにデータを学習させ、答えを導き出します。たくさんデータがあるときに、データの中に人間が気づかない隠れた情報やパターンがあります。そのときに、ディープラーニングといった機械学習を発展させたテクノロジーが役に立ちます。ディープラーニングは人間の神経(ニューロン)を真似て、学習プロセス(ニューラルネットワーク)を作ります。人間の場合、神経細胞(ニューロン)は情報処理と情報伝達に特化します。ニューロンは他のニューロンを繋いで、情報などを通信しながら、情報を理解していきます。ディープラーニングの場合、コンピューターがニューラルネットワークにデータを入力し、そのニューラルネットワーク内で情報を伝達し、学習しながら、隠れた情報を見つけ出します。このディープラーニングの学習プロセスは具体的にどう行われるかについて、下記に説明します。
Thomas Wolfさんのブログの図を借りて、犬と猫の分別ケースを例として説明しようと思います。
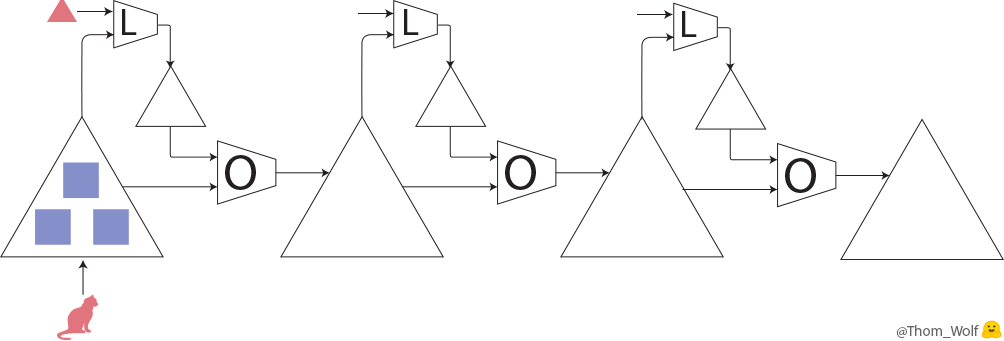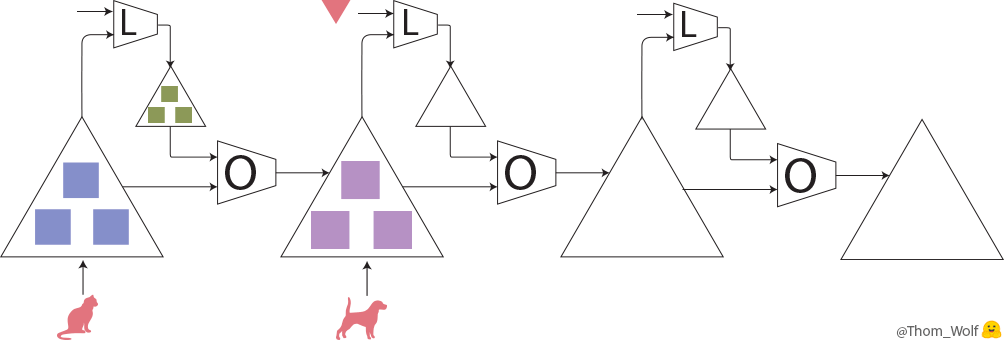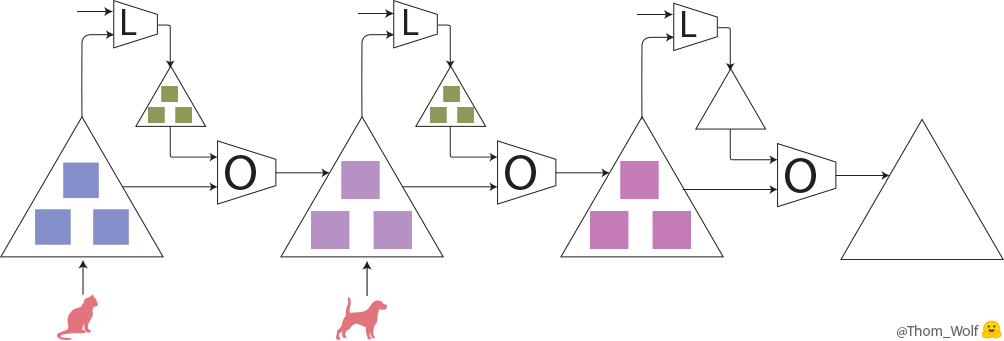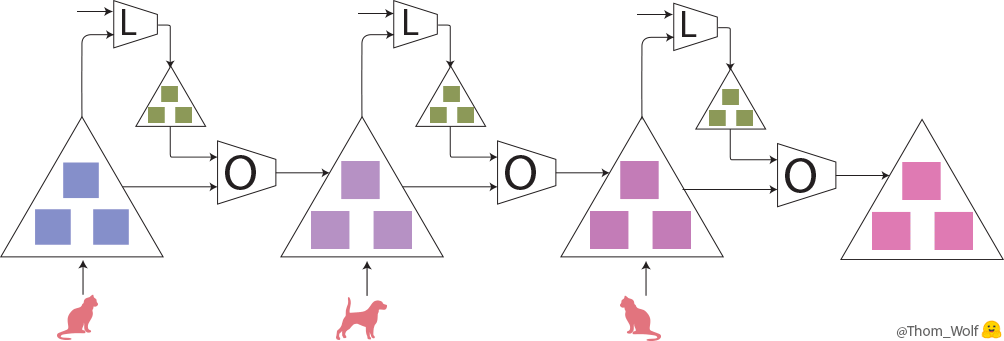
図1は学習プロセスを表します。まず、犬と猫の写真を数字でラベルし、ニューラルネットワーク(大きい△)に入力します。ニューラルネットワークの中に、犬と猫を判別するためのパラメータ(□)が入っています。最初のパラメータ値は初期値として設定されます。パラメータに基づいたニューラルネットワークが犬と猫を予測します。予測したものが正しいかどうかloss関数(L箱)で評価します。Loss関数はパラメータを使って予測したものとラベルされたものを比較します。パラメータ最適化(optimizer、O箱)で、パラメータを調整し、loss値が小さくなるように計算を繰り返していきます。loss値が小さいほど、予測したものがラベルされたものに似ているようになります。パラメータ調整率は学習率(learning rate)です。loss値が小さくなるかどうか、loss値の勾配(gradient)を計算しながら、パラメータをチューニングするための一般的な手法はbackpropagationです。最後に、backpropagationを使ってパラメータをアップデートしていきます。そこで、最もよい答えを出すため、最適化で繰り返して学習を行っていきます。よりよい学習を得るため、ニューラルネットワークのbackpropagationが主なステップになります。
メタ学習
前のセクションでは一般的な学習プロセスをおさらいしましたが、ここではメタ学習を説明します。メタ学習は全ての学習プロセスまるごとを学習します(図2)。
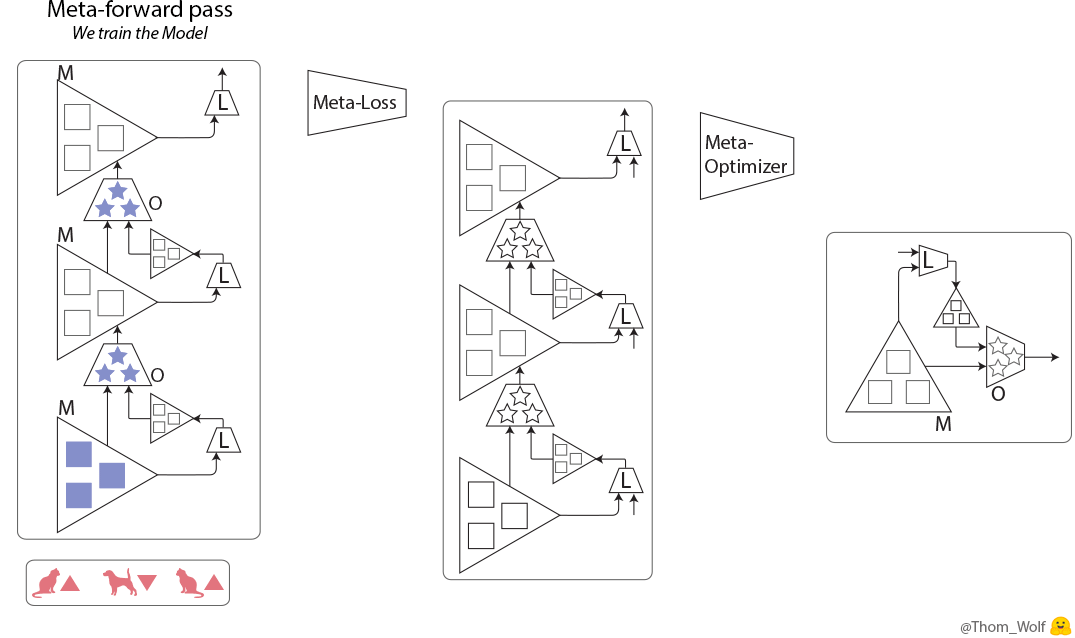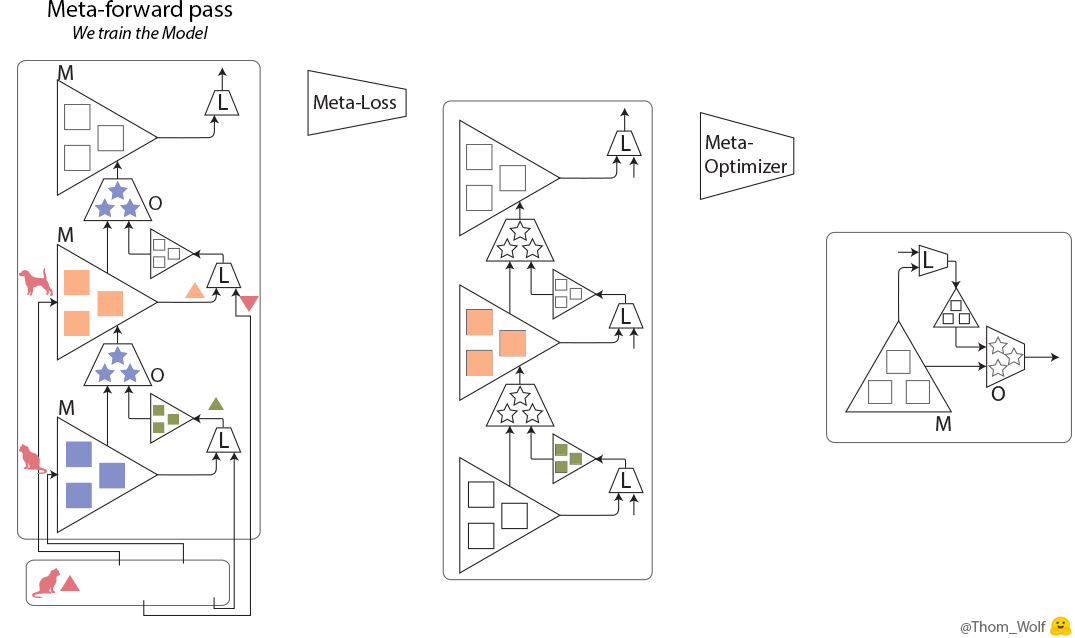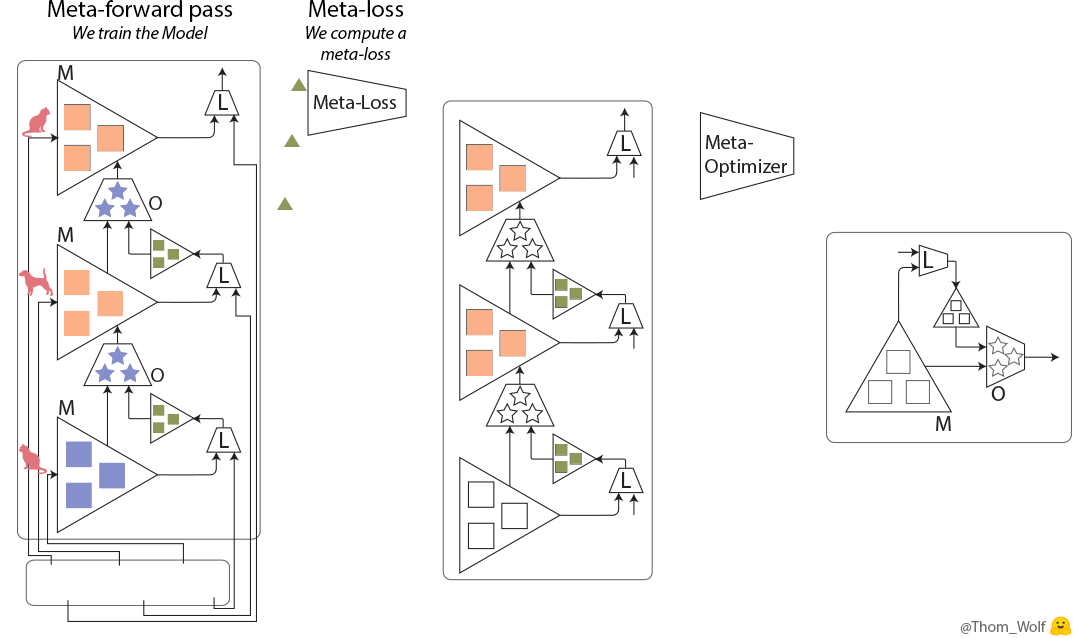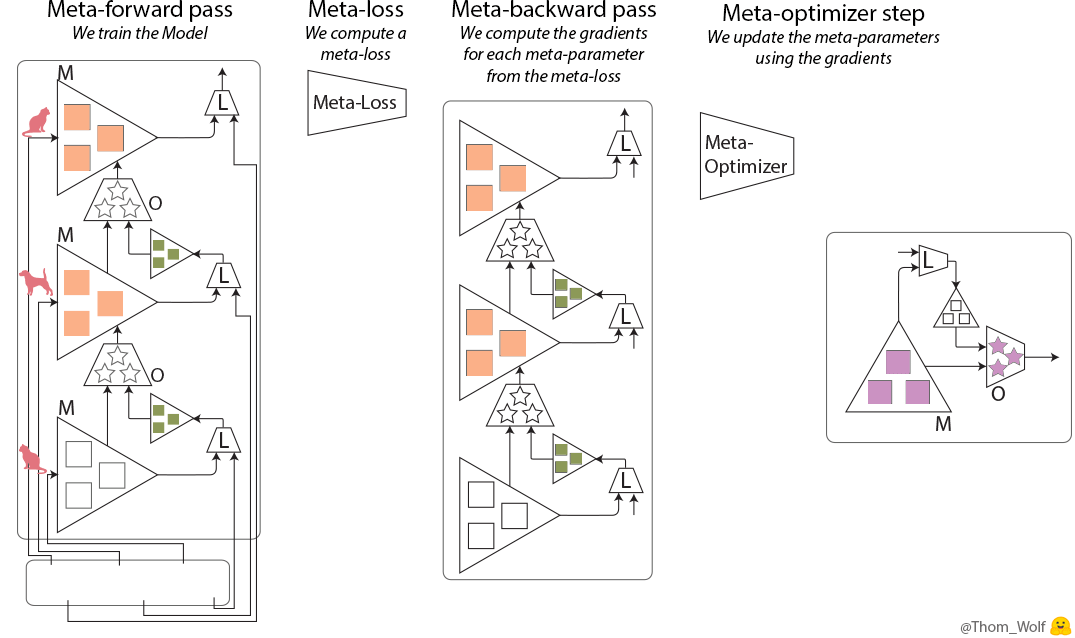
まず、学習プロセス(図1のまるごと)を学習します。ここで全てのプロセスのloss関数(Meta-Loss)を計算します。それから、Meta-loss値から、各meta-parameterのgradientを計算します。最後、meta-optimizerでgradientを利用し、meta-parameterをアップデートします。
ディープラーニングならparameter、loss、optimiserだけで十分ですが、メタ学習はさらにmeta-parameter、meta-loss、meta-optimizerが必要となります。ここで、学習アルゴリズムがより複雑になります。ディープラーニングで学習するためにはたくさんのデータを使うので、コストの高い計算が必要となります。そうすると、メタ学習はディープラーニングよりもっと多くのデータを利用し、よりコストの高い計算が要求されます。これは現実に適応するのに、厳しいです。この大変さを減らすため、多くのメタ学習はfew-shot learningというコンセプトを利用しています。Few-shot learningは少ない学習データから正答できることを目的としています。また、few-shot learningに基づいて、メタ学習の効率を向上させるために、Model-Agnostic Meta-Learning (MAML) という有名なアルゴリズムが開発されたようです。さらに、MAMLアルゴリズムをベースにして開発したものが多いです。例えば、recurrent neural models (meta-reinforcement learningやfew-shot classification and regression)やmetric learningなどにも使われています。そこで、今回はMAMLを読んだり、遊んだりしてみました。MAMLの詳細説明は「②Model-Agnostic Meta-Learning (MAML)の紹介」、実装例は「③東京の気温の予測」を参考にしてください。
② Model-Agnostic Meta-Learning (MAML)の紹介
メタ学習をよりよい学習にするため、Berkeley AI Research LabがModel-Agnostic Meta-Learning (MAML)を開発しました。MAMLは大きくメタ学習を変えたものと言われています。はじめに話した去年のICLRベスト論文もMAMLに基づいて開発されたものです。
さて、MAMLも含んだメタ学習を行うためのハイパーパラメータチューニングはfew-shot learningコンセプトが利用されています。そこで、先にfew-shot learningをおさらいしたいと思います。一般的な機械学習(特に、ディープラーニング)は情報やパターン(アウトプット)を見つけ出すため、大きなデータセット(インプット)を学習しますが、one-shot learningやfew-shot learningはいくつかの情報(アウトプット)を見つけ出すため、一つだけや少ないデータセット(インプット)で学習します。
MAMLはメタ学習の高コストの計算を減らすため、モデルパラメータの初期値を最適化します。上記に説明したように、学習するときに、loss関数を小さくするためのパラメータ調整はloss値の勾配(gradient)が使われています。ここで、よく使われているアルゴリズムはgradient descentです。大きなシステムの答えを導くため、gradient descent計算が大変になります。MAMLは各タスクのgradient descentを改良するため、gradient descentを行うアルゴリズムです(図3)。基本的によりよいモデルパラメータの初期値を設定することでGradientステップを減らし、学習時間が早くなり、少ないデータセットを使ってもoverfitting問題を緩和することも可能です。
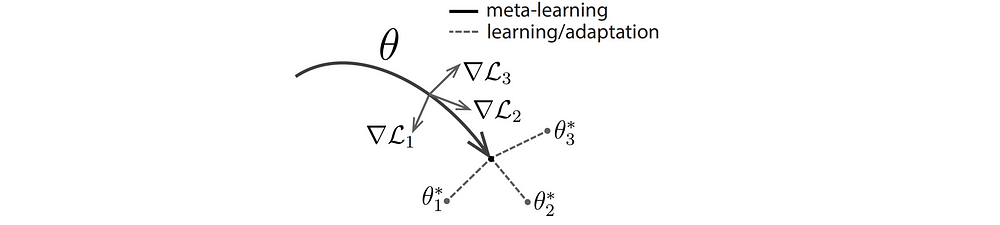
図3で、黒線はメタ学習段階(フェーズ)、θはモデルパラメータ、Lはlossです。ここで一つのlossの最小化を一つのタスクとします。例えば、3つのタスクがあります。全てのタスクは共通のモデル初期値θがあります。グレー線(∇L1, ∇L2, ∇L3への線)はそれぞれのタスクのgradientステップです。パラメータθは3つのタスクの最適なパラメータ値に近くなるように、∇Lを使って評価します。θはそれぞれのタスクに適用可能ですので、ベストパラメータ初期値だと考えられます。結果、パラメータθをそのように設定したら、多くのタスクのloss関数を減らすことできます。
アルゴリズムの詳細は以下の論文を参考にして頂ければと思います。

MAMLの論文では、メタ学習を使って、Regression, Classification, Reinforcement Learning3つの手法に適応した結果がありました。今回の初勉強として、一番簡単でわかりやすいもので、Regression版をやってみたいと思います。
③ 東京の気温の予測
ここでは、MAMLを使ったメタ学習で東京の気温を予測してみたいと思います。論文の発表者が公開したコードを勉強し、今回の実装のベースに使わせて頂きました。
(20200205追加:修正したコードはここから、ダウンロードできます。)
具体的にやりたいことはメタ学習のRegressionを使って、東京の気温のデータを学習します。それから、学習したモデルを使って最新の東京の気温を予測します。また、これだけだとちょっとつまらないので、ついでに最近話題になっている気候変動も少し検討してみたいです。
それでは、これからメタ学習で遊んでみます~
実装環境
-
- ノートパソコン:Panasonic CF-SZ5
-
- プロセッサ:Intel® Core™i5-6300U [email protected]
-
- メモリ(RAM):8GB
-
- OS: Windows 7
-
- 言語:Python 3.5.5 (Anaconda 3.5、Tensorflow 1.8.0、Numpy 1.14.5、Matplotlib 2.2.2)
データ準備
まず、データ取得です。日本の気象庁ホームページからCSVファイルで、東京の気温データをダウンロードしました。ダウンロード条件は下記になります。
-
- 都道府県:東京
-
- データの種類:月別値
-
- 気温:月平均気温
-
- 期間:1918年1月~2018年9月22日(101年分)
- ダウンロード日:2018年9月16日(最後の2018年9月データは半月の平均になります)
次に、データの前処理です。上記に説明したように、気候変動も検討するため、学習データセット(train data)は二つに分けます。一つ目は1918-1967年(100-50年前)、二つ目は1968-2017(去年までの直近50年)。また、今年(2018)のデータは予測(test data)のために使います。普通の機械学習と比較すると、今回のtest dataは少ないかもしれませんが、一応お試しでこのままにしたいと思います。
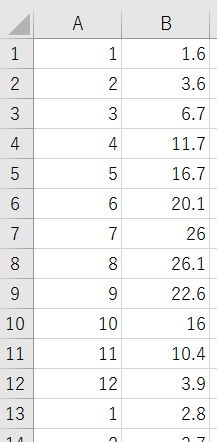
入力データの形式に関しては年の情報を無視し、月(ラベル)と気温だけを使います。そうすると、ラベルは1から12までになります。イメージは下記のように、左は月ラベル、右は月の平均気温になります。
実装
データ入力
まず、CSVファイルから、東京の気温データを読み込みます。データに10% random noiseを付けます。データ処理はdata_generator.pyに下記のfunctionsを追加しました。
def generate_weather_temperature_batch(self, train=True, input_idx=None):
# set up input conditions
# csv_name = "data/tokyo_temp_191801-196712.csv"
csv_name = "data/tokyo_temp_196801-201712.csv"
# load csv file
temp_data = np.genfromtxt(csv_name, delimiter=',')
# randomly select data from csv
selected_data = np.array(random.sample(temp_data.tolist(), self.batch_size*self.num_samples_per_class*self.dim_input))
label_batch, data_batch = np.transpose(selected_data)
# add noise for 10%
noise = np.random.uniform(-0.1, 0.1, self.batch_size*self.num_samples_per_class*self.dim_input)
noisy_data_batch = data_batch + data_batch * noise
# mock conditions
amp = np.random.uniform(self.amp_range[0], self.amp_range[1], [self.batch_size])
phase = np.random.uniform(self.phase_range[0], self.phase_range[1], [self.batch_size])
label_batch1 = np.reshape(label_batch, [self.batch_size, self.num_samples_per_class, self.dim_input])
noisy_data_batch1 = np.reshape(noisy_data_batch, [self.batch_size, self.num_samples_per_class, self.dim_input])
return label_batch1, noisy_data_batch1, amp, phase
def generate_test_weather_temperature_batch(self, train=True, input_idx=None):
# set up input conditions
csv_name = "data/tokyo_temp_2018.csv"
num_samples_per_class = 1
batch_size = 12
# load csv file
temp_data = np.genfromtxt(csv_name, delimiter=',')
# randomly select data from csv
selected_data = np.array(random.sample(temp_data.tolist(), batch_size*num_samples_per_class*self.dim_input))
label_batch, data_batch = np.transpose(selected_data)
# add noise for 10%
noise = np.random.uniform(-0.1, 0.1, batch_size*num_samples_per_class*self.dim_input)
noisy_data_batch = data_batch + data_batch * noise
# mock conditions
amp = np.random.uniform(self.amp_range[0], self.amp_range[1], [self.batch_size])
phase = np.random.uniform(self.phase_range[0], self.phase_range[1], [self.batch_size])
label_batch1 = np.reshape(label_batch, [batch_size, num_samples_per_class, self.dim_input])
noisy_data_batch1 = np.reshape(noisy_data_batch, [batch_size, num_samples_per_class, self.dim_input])
return label_batch1, noisy_data_batch1, amp, phase
学習モデル
一年中の気温変化はMAMLの論文に載っていたsinusiod regression問題と似ているので、sinusiod regressionの学習条件を当てはめてみました。
-
- Pre-train iteration: 0
-
- Meta train iteration: 70000
-
- Meta batch size: 25
-
- Meta learning rate: 0.001
-
- Update batch size: 10
-
- Update learning rate: 0.001
実行コマンド
# train python main.py --datasource=weather --logdir=logs/weather_prev/ --metatrain_iterations=70000 --norm=None --update_batch_size=10 # test python main.py --datasource=weather --train=False --test_set=True --logdir=logs/weather_prev/ --metatrain_iterations=70000 --norm=None --update_batch_size=10
結果
東京の気温の予測結果は二つに分かれています。一つは1918-1967年(100-50年前)、もう一つは1968-2017(最近の50年)です。学習はそれぞれのデータを使い、学習モデルも二つのモデルになります。予測(テスト)はそれぞれのモデルを使って、今年の東京の気温と比較しました。
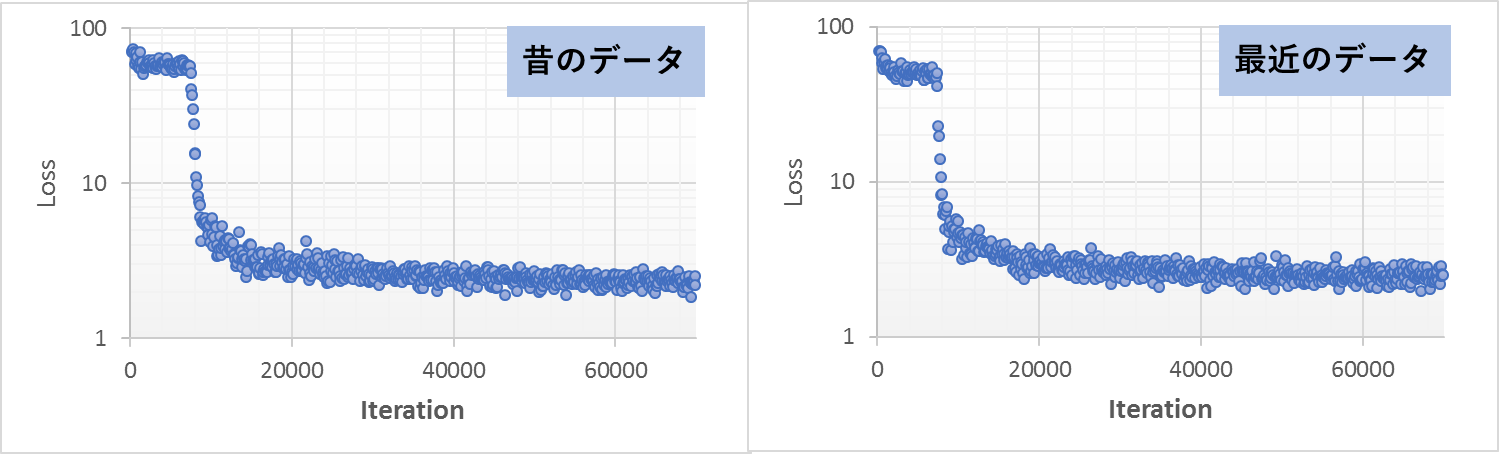
過去の東京の気温の学習
図5は学習結果です。左は100-50年前のデータ、右は最近の50年のデータ、を使って学習したLoss結果です。Lossの変化を見やすくするため、log軸でプロットしました。この結果をみると、どちらのデータからでも簡単に学習できたことが見られました。
具体的に、モデルがどう学習したかイメージするため、学習が行われているときのビデオを作成しました。下記のビデオは学習のmeta iteration 0から15,000回までで、図のアップデータ間隔は500iterationごとです。ビデオを見てみると、最初にモデルが線形のようなデータを作成し、少しずつsinカーブに変わっていくことが見られました。
- 100-50年前のモデル
- 最近の50年のモデル
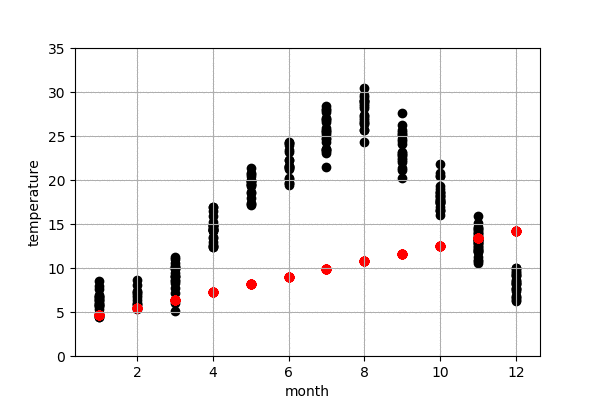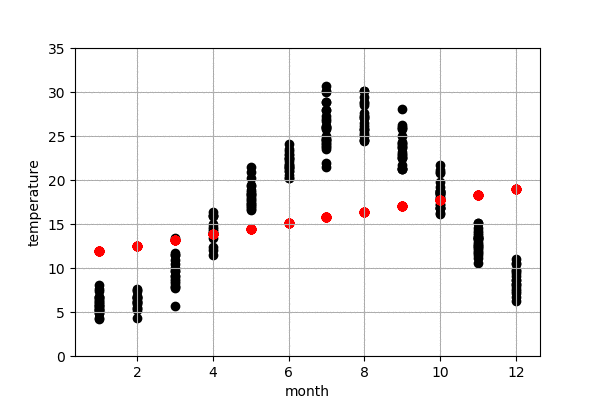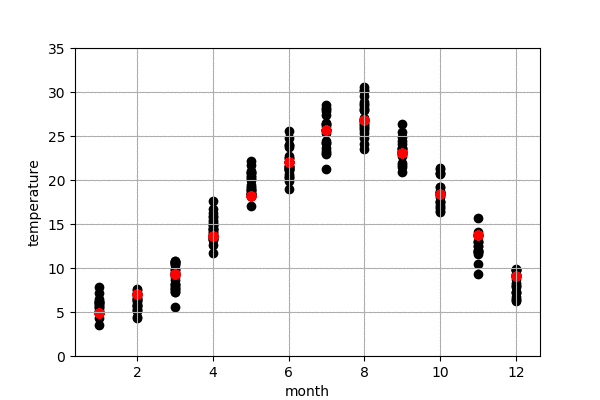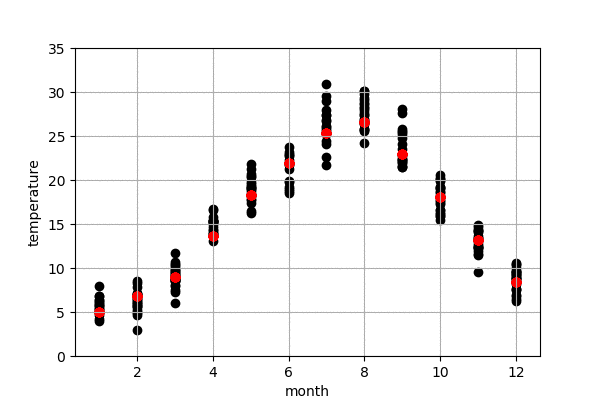
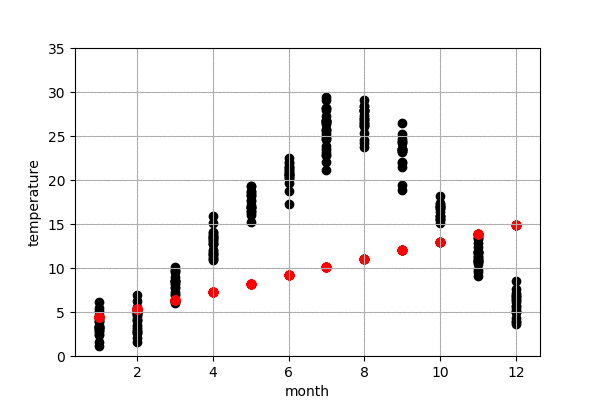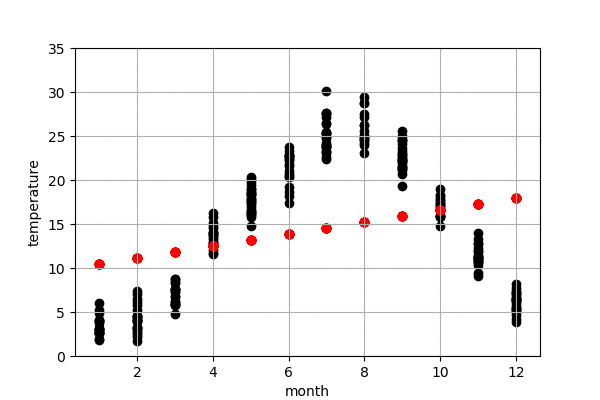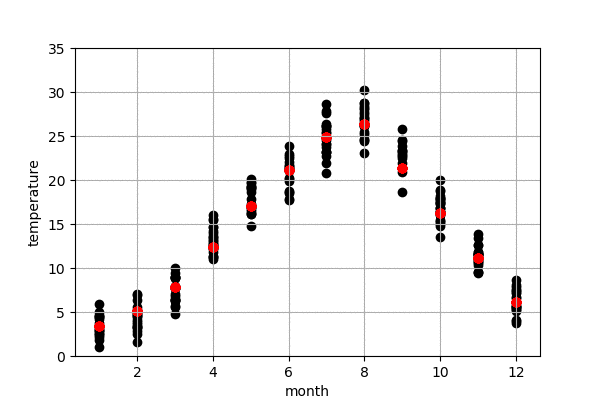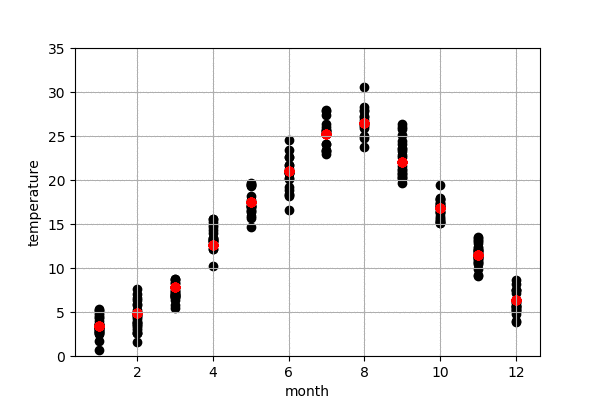
東京の気温の予測
図6は今年の東京の気温予測結果です。左は100-50年前のデータで作成したモデル、右は最近の50年のデータで作成したモデルになります。黒点は実際の気温、赤点はモデルで予測した気温です。今年の10,11,12月の実際の気温はまだわからないので、仮に0度にしておきました。
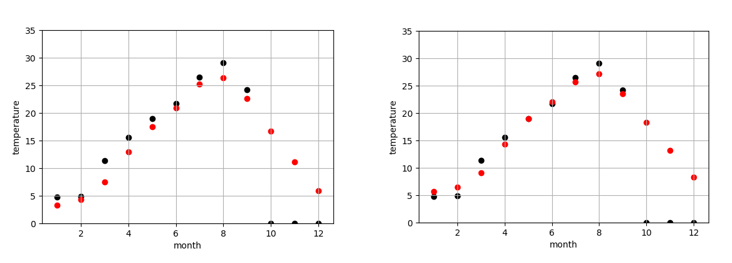
また、予測結果の詳細を見てみると、100-50年前のデータで作成したモデルの予測の方が、最近の50年のものより、予測気温は低いことが見られます。これで、明らかに気象が変動してきたことがわかりました。例えば、100-50年前のデータで作成したモデルによる、来月の予測気温は16.66度でしたが、最近の50年のデータで作成したモデルによる、来月の予測気温は18.32度くらいでした。モデルによる、昔に比較すると、最近の10月平均温度は2度弱上がってきたことがわかりました。昔の方が早く気温が下がり、綺麗な紅葉が早い段階で見られたのでしょう。また、いずれにしても、今年(1-9月)の予測結果による、最近のデータで作成したモデルの予測結果は昔のモデルより、今年の気温に近いことがわかりました。当たり前ですが、最近のデータで作成したモデルのほうが、予測精度が高かったということになります。
④ まとめと考察
今回はメタ学習のコンセプトを紹介し、MAMLといったメタ学習の有名なアルゴリズムに触れてみました。regression問題の実装例として、今年の東京の気温を予測してみました。メタ学習の理論通り、普通の学習より計算は少し速いと感じました。精度はきっちりと比較していませんが、論文のように、悪くない結果だと思います。個人的には、メタ学習の可能性を感じ、この分野の発展を期待しながら、また様々なメタ学習を試してみたいと思います。
最後に
次世代システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧からご応募をお願いします。
一緒に勉強しながら楽しく働きたい方のご応募をお待ちしております。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD