2021.07.08
簡単に利用できる PDF 文字認識 OCR 比較まとめ ~ AI OCR の頭抜けた実力
D.M.です。今回は RPA にて PDF を OCR で読み取る検証をしたお話です。
TL;DR
・実用性は AI OCR しか勝たん。
・AI OCR は Google vs Microsoft の構図。 両者精度高。
・Google も Microsoft も API に無料枠があり Python などのプログラムで連携できる。
・Microsoft は有料の RPA 連携機能が超絶楽勝なのでコードを書かない前提ならこっちも選択肢。非エンジニアでも楽々自動化できる。
※関連記事
AI OCR でクレカ読み取りをやっています。
スマホNativeアプリでクレジットカード番号の読み取り機能の技術検証結果まとめ
https://recruit.gmo.jp/engineer/jisedai/blog/technical_review_ocr_solutions_on_auto_detect_credit_card_number_for_native_apps/
業務課題(やりたいこと)
RPA での業務改善を進めるMTGにて、社内のある部門から「先方から紙や電子データをPDF化した資料が送られてくるが、業務上それらを手でシステムに入力する業務があり、非常に時間を取られている。」という相談を受けました。
PDF の文字起こしと言えば OCR かと思います。ソリューションは多々ありますが、現段階で簡易的にできそうか、かつ精度が高い結果が出せるかを調査した結果をまとめておきます。
この記事でターゲットにした課題(検証としてやったこと)
先方から受け取る実物の PDF は機密情報を含み記事内での共有が難しいので、ダミーのターゲットとして請求書のサンプルをWebから取得し、それに対して OCR を施します。
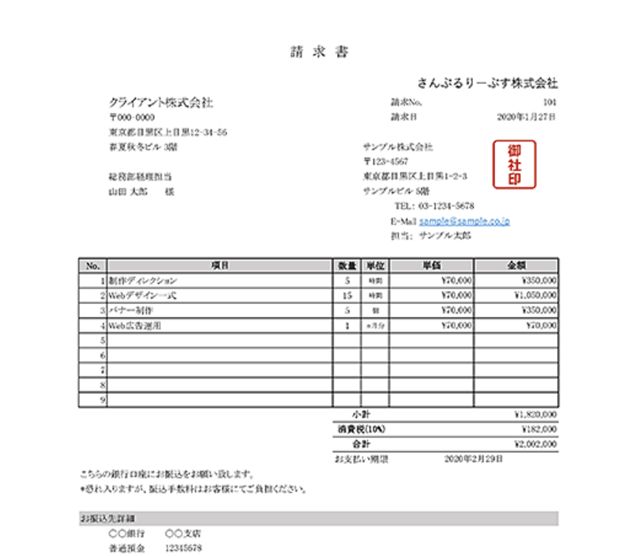
請求書のサンプルはMakeLeapsさんが配布している無料のテンプレートを利用しています。
https://www.makeleaps.jp/%E8%B3%87%E6%96%99/excel-templates-invoice/
そして「なんでボケているんだこの請求書画像は!」と感じたと思うのですが、実は OCR の性能差を見るためにあえて「字が薄い」状態にするというひねりを加えています。
さて OCR はこれをちゃんと読み取ることができるんでしょうか。。?
実際の業務では紙をスキャンした PDF と電子データの Word などを変換した PDF がありますが、今回は簡易的に検証するため電子データ由来の PDF だけを対象にしました。
OCR 選択肢の整理
OCR で検索するとたくさんヒットしますが、無料で試すことができたツールを中心に以下を検討対象としました。
目次
1-1. Tesseract
1-2. Microsoft Windows Runtime API Windows.Media.Ocr
2.クラウド系 OCR
2-1.ストレージ型
2-1-1.Google Drive
2-2.API 型
2-2-1.Google Cloud Vision API
2-2-2.Microsoft Power Automate AI Builder
1.ローカル系 OCR
ローカルPCにインストールするタイプのOCRエンジンです。
1-1. Tesseract
もともと HP 製で Google が引き継いで開発したオープンソース OCR である Tesseract が無料で利用できそうなので試してみます。
Windows 用の Tesseract は以下のサイトからすぐにダウンロード可能です。
https://github.com/UB-Mannheim/tesseract/wiki
Tesseract との連携は多くの情報があり、 Python 等のプログラムから呼ぶこともできるのですが、今回は Microsoft RPA の Power Automate Desktop を用いて呼び出してみます。
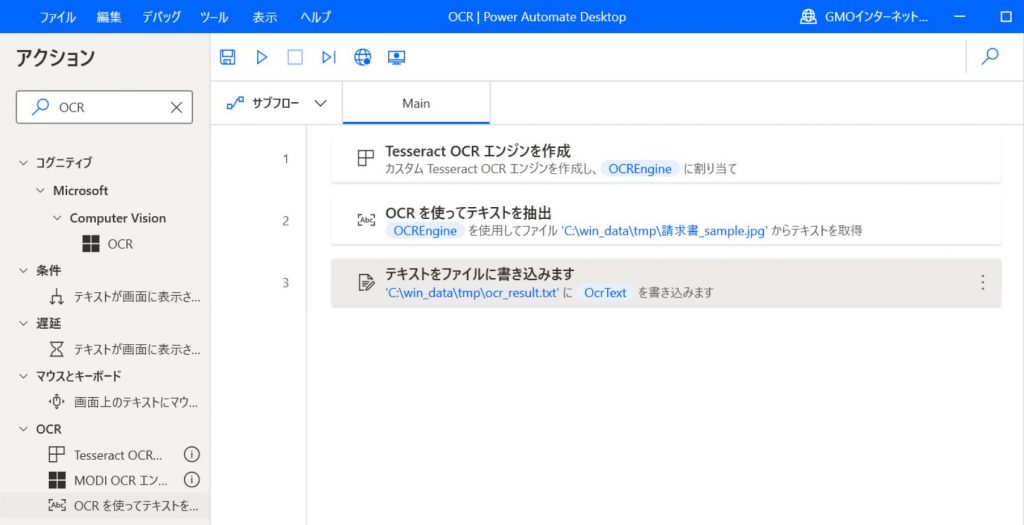
Power Automate Desktop については非常に簡単に組めるため詳細は割愛しますが、今回もわずか5分程度で作るすることができました。
Tesseract の結果
上述の請求書サンプル PDF を OCR で読み込ませた結果です。
きんぶるリーぶす株式会社
クライアント株式会社 滞本we Me
ヒレ ーー Pi
0 soっ
AN ンジTrent
Mei aaoeizwianei20a
サンプル大でRe
kPa ES
のHOを7いします
・6りますお全てごRPCださい
DRComn Oo
生池金 SH679
全く使い物になりません。。
既存のブログ等の情報を参照すると、 Tesseract は文字の輪郭など情報をはっきりさせるチューニングすれば読込精度はあげられるとあります。
https://rightcode.co.jp/blog/information-technology/python-tesseract-image-processing-ocr
今回のユースケースのように薄い字の場合は輪郭を濃くするなどの前処理が必要になりそうです。いったん保留として次のツールに移ります。
1-2. Microsoft OCR
Microsoft OCR (または Windows.Media.Ocr )は、 Windows 10 にデフォルトで備わっている OCR です。もちろん無料。
Windows Runtime API (WinRT) から呼び出すことができ、 Python をはじめとしたプログラミング言語で利用可能です。
今回は Microsoft が公開しているサンプルコードから C# のものをそのまま実行してみます。(この OCR は画像を読み込む仕様のため、 PDF から利用する場合はプログラミングまたはツールを利用してPDF⇒画像変換を行う必要があります)
https://docs.microsoft.com/ja-jp/samples/microsoft/windows-universal-samples/ocr/
Microsoft OCR の結果
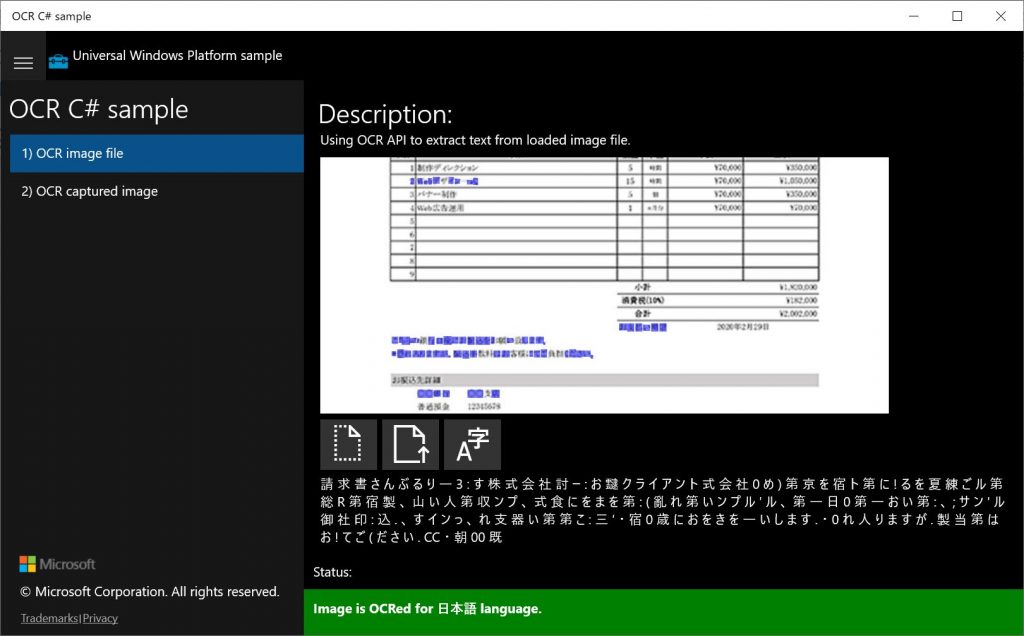
上記画像の右下のあたりに結果が出力されているのですが、いかがでしょうか。
さっきよりは良さげに見えますが、実際は全く役に立たないレベルです。非常に残念。
テスト用にあえて字を薄くしたのは失敗だったのかと若干思いましたが、次のツールにいってみようと思います。
2.クラウド型 OCR
クラウド上にエンジンがある OCR で、その中にさらに以下の2種類があります。
2-1. サイト上で OCR を実行させるタイプ(ストレージサービスなど)
2-2. API で OCR を実行するタイプ
2-1-1. Google Drive
ストレージサービスである Google Drive に PDF をアップロードすると Google ドキュメントへ変換できるメニューがあります。
無料でも使えますが、法人契約をして使っています。
さっそくやってみましょう。
上述の請求書サンプル.pdfをアップロードし、変換メニューを選択してみます。
Google Drive の結果
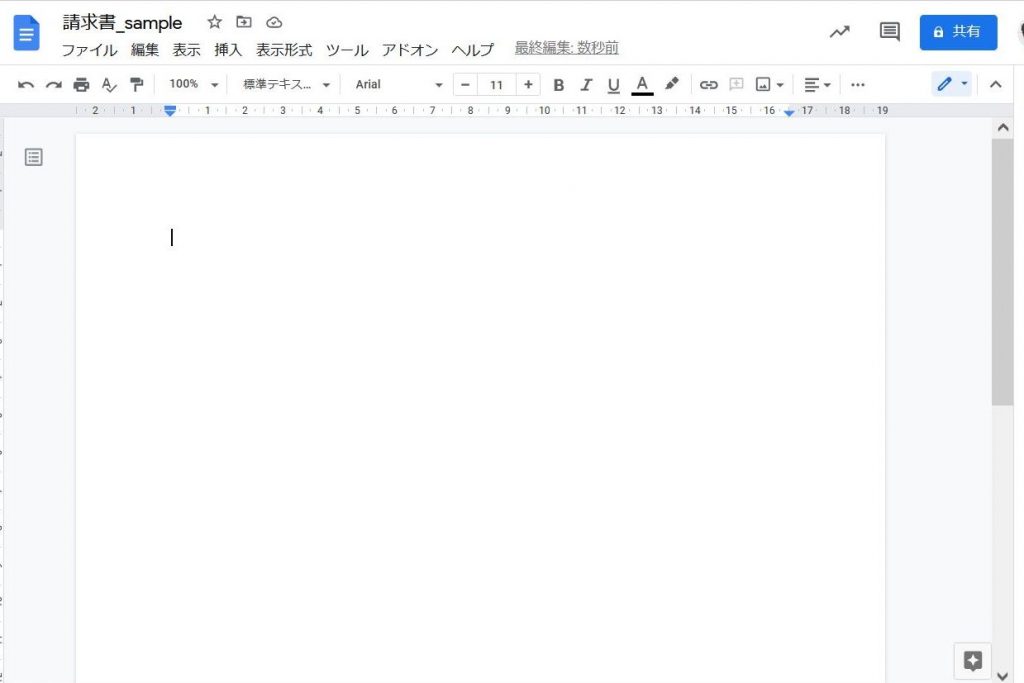
真っ白です(笑)
他の PDF で試したかんじですとここまで全く読まれないことはなく、電子データ由来のPDFでは90点以上は余裕で出せていたのですが、このユースケースでは残念ながら0点に終わりました。
しかし!もう1つ別ツールで Google Photo の機能として自動文字認識 Google Lens があります。こちらは画像のみで PDF では使えないのですが、実際やってみたところ非常に高精度でした。
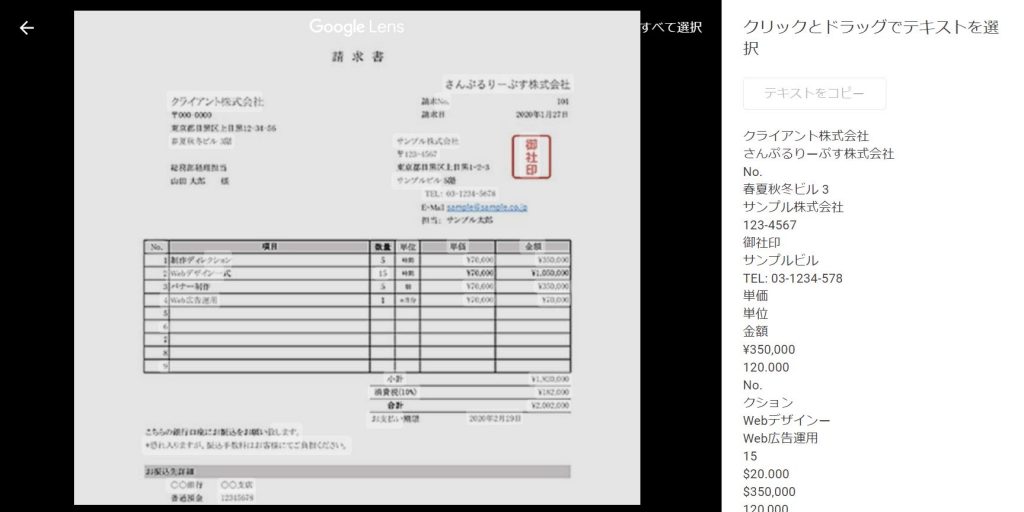
これは使えそうです。PDF⇒画像というひと手間を何かで実装する必要があるものの、8割がた正確に読み込まれており、有力な選択肢となりそうです。
ただ、ダメな点として人名である「山田 太郎」が読み込めておらず無視されてしまいました。(太郎がだいぶつぶれていますが。。)実用化の際には人間の手で補正する必要があるという感じです。
余談ですが、Microsoft Office のツールの1つである OneNote でも PDF アップロードによる OCR ができました。ただ内部的には上記の Tesseract よりも弱い MODI を使っているようで、精度的にも大したレベルには至りませんでした。
ちなみに Microsoft は以前 Office Lens という画像からの OCR 機能を提供していたのですが、現状スマホアプリだけの提供になってしまったので、今回の検証対象からは外しています。画像変換を前提にする場合はかなり有望なツールになると思いますので別の機会で検証したいと思っています。
2-2-1. Google Cloud Vision API
さて、ここから API 型です。
そしていきなり AI OCR です。機械学習を利用して精度を向上させている製品で、期待感が高まります。
こちらは Google Cloud Platform の一部なので基本 API 呼び出しで利用します。
また気になる料金は小規模なら安く 1000 回まで無料で、それ以降も 1000 回あたり$1.50(だいたい150円)のようです。詳細は以下で確認してください。
Google Cloud Vision API 料金表
https://cloud.google.com/vision/pricing?hl=ja
使い方的には Python などプログラムから呼び出したり Power Automate Desktop から呼び出すことができるのですが、 Google 側はすぐに試せるデモ画面を公開しています。
https://cloud.google.com/vision?hl=ja
ここでこれまでの流れのとおり PDF をアップロードする実験をしてみます。
Google Cloud Vision API の結果
こちらがデモ画面で判別してもらった結果です。右の方の +Page 1 の枠がそれになります。
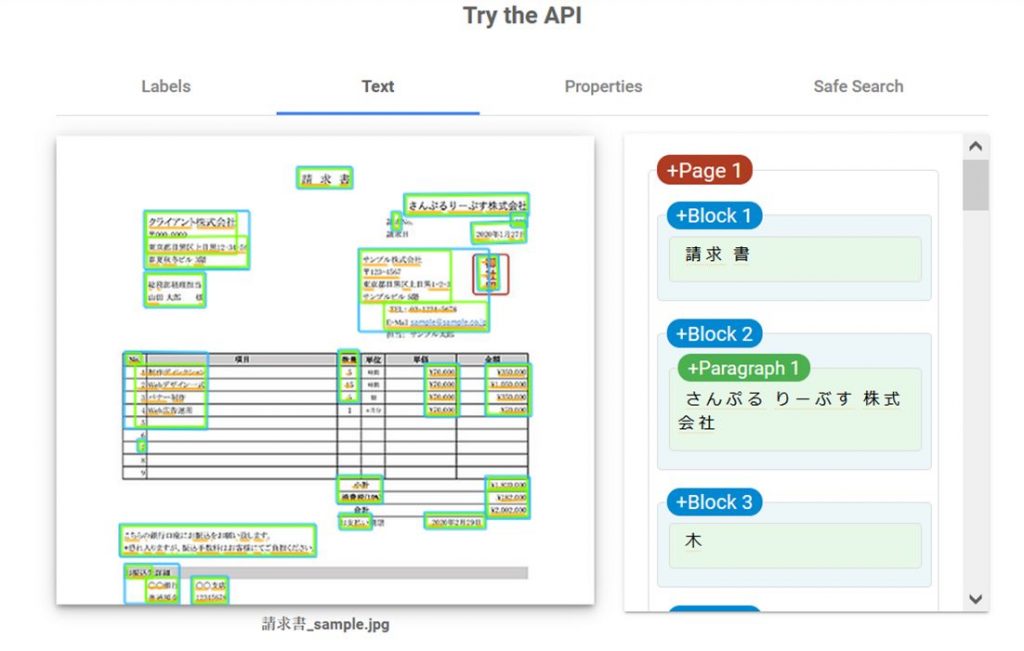
お、文字がちゃんと読める!
画面的に全部をキャプるのが難しかったので、貼りつけます。
請 求 書
さ ん ぷ る り ー ぶ す 株 式 会 社
木
1 0 1
ク ラ イ ア ン ト
株 式 会 社 〒 0 0 0 – 0 0 0 0 東 京 都
目 黒
2 – 3 4 – 3 5 春 夏 秋 冬 ビ ル 1 0 0
2 0 0 9
年 1 月 2 7 日
御 社 印
2 枚 山 口 大 株
サ ン プ ル
株 式 会 社 〒 1 2 3 – 4 5 6 東 京 都 以 上 1 2 – 3 サ ン ブ ル ビ ル 5 階
T E L
: 0 3 – 1 2 3 4 – 5 6 7 8
E – M 1 1 0 m o l e s s a n g l e . c o . i d
N o .
制 作
デ ィ レ ク シ ョ ン [ 2 w e b デ ザ イ ン ー バ バ ナ ー 制 作 ( W e b 広 告
5
数 量 S I S S
7 7 0 . 0 0 0 1 7 0 . 0 0 0 1 2 0 . 0 0 0 Y 2 0 . 0 0 0
W 3 5 0 . 0 0 0 V 1 . 0 5 0 . 0 0 0
1 3 5 0 . 0 0 0 ¥ 2 0 . 0 0
小 計 A R R O A
V 1 . 2 0 , 0 0 0
¥ 1 8 2 , 0 0 0 1 2 . 0 0 2 . 0 0 0
お 支 じ い
2 0 1 0
年 2 月 2 9 日
こ ち ら
の 商 品 を い 出 し ま す 。 き れ 入 り ま す が 、 込 手 数 料 は お 客 様 に て ご 負 い く だ さ い 。
お 振 込 先
C O M 普 通 預 金
○ ○ 支 店 1 2 3 4 5 6 7 8
細かいところ見るとあれれっとなりますが、少し手で修正するレベルで使えるのではと思っています。
そしてやっぱりダメな点としては「山田 太郎」が読み込めておらず、「山 口 大 株」になっています。誰なんだという感じです。ただこはテストデータのように字が薄い場合でなければ結果を出せる可能性はあるのではないでしょうか。追加の検証が必要になりそうです。
2-2-2. Microsoft Power Automate AI Builder
今回の最後に Microsoft の RPA である Power Automate の AI 機能を使ってみます。
Power Automate は自動化された一連の処理をサーバサイドで実行できるものです。(前述した Power Automate Desktop はデスクトップ用で別物。両者が連携できるハイブリッドフローについてはこちらの記事参照 https://developers.gmo.jp/8233/ )
AI Builder は Power Automate から Azure の AI 系 API を呼び出せる機能になっていて、おそらく内部で Azure Cognitive Service の Computer Vision API を呼んで OCR を実現しています。
※現在弊社では Microsoft 365 のライセンスと Power Automate のサーバライセンスを購入しています。また今回の検証では AI Builder は試用期間で利用しています。(ここが実は曲者。後述)
早速使ってみます。
Power Automate のテンプレートにて AI Builder で検索します。
「AI Builder のテキスト認識を使用し、画像またはPDFからテキストを抽出する」を選択します。
こんな画面で概要説明が出ますが、続行で進みます。
このテンプレートがデフォルトで OCR のフローを生成してくれるので、画面に PDF をアップロードすると OCR を実施しテキストを抽出する機能がすでに出来上がっているかたちになりました。
このテンプレートには最後に Outlook で送信する部分がありますが、今回の検証では不要なので一旦削除して、単にExcelファイルに書き出すように変更しました。
Microsoft Power Automate AI Builder の結果
請求書 さんぶるリーぶす株式会社 クライアント株式会社 7000-0000 請求日 2020年1月27日 東京都目黒区上目黒12-31-56 春夏秋冬ビル 3ぷ サンプル株式会社 御社印 Y 123-4367 総務部経理担当 東京都目黒区上日第1-2-3 山田 大郎 サンプルビル 5 TEL: 03-1234-5678 担当:サンブル太郎 No. 数量 單位 金额 ■製作ディレクション S 120,0000 ¥350,000 2 Webデザインッパ 15 ¥20.0000 W1.050.000 3|バナー制作 ¥20.000 ¥350.000 4|Web広告運用 120,000 120,000 小計 WI.820,000 消費税(10%) ¥182.000 合計 12.002.000 お支払い期舉 2020年年2月29日 こちらの鉄行口座にお振込をお願い致します。 ●恐れ入りますが、配込手数料はお客様にてご負担ください。 お振込先詳細 CO银行 ○○支店 香過預金 12345678
突然改行なしになりましたが(笑)、精度は一番高い状態で取得できています。
なんといままで不可能だった「山田 太郎」がついに読み込まれています(泣)
いや、よく見たら「山田 大郎」になっているじゃないですか。。ただ大郎と太郎は人間の目でも判別が難しい箇所です。そこ以外は修正が必要ないのではという仕上がりになっています。もはや驚異的なレベルと言えるかもしれません。
金、金、金
さて最後の AI Builder ですが実は料金が段違いで高いです。
価格は容量見積もりのページで計算できます。
https://powerapps.microsoft.com/ja-jp/ai-builder-calculator/
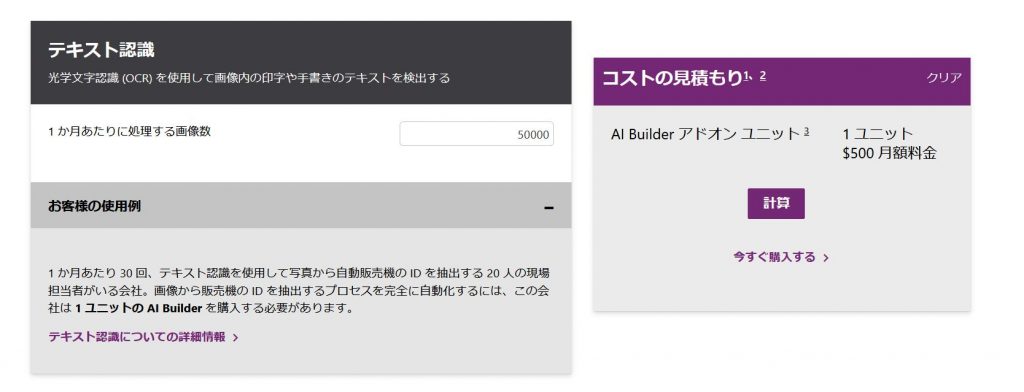
最低 $500 ~となっており(2000トランザクション)、月に5万以上はかかる見込みとなっています。
高いだけあって高精度なものが一瞬で作れるというメリットはありますが、エンジニア視点ですと少し手間をかけて Azure の API を直接叩くコードを実装したほうが長期的に考えると安いかなと思いました。
5000 回まで無料枠がありますし、 1,000 トランザクションあたり ¥112 となっています。
https://azure.microsoft.com/ja-jp/pricing/details/cognitive-services/computer-vision/
非エンジニアでも結構なものがつくれてしまう点は非常に魅力的な製品だと思います。
他に今回検証できていないもの
国内事業者だと Dx Suite さんがあります。AI OCR で No.1 シェアを誇っているようです。
https://dx-suite.com/price/
月額30000円と記載があります。1か月無料枠もありますので上記で検証したツール以上のものになるのか試してみたいと思いました。
Adobe Acrobat の OCR 機能も評判が良いものになっています。現段階で月額1,738円だったので全然リーズナブルだと思います。
https://acrobat.adobe.com/jp/ja/acrobat/how-to/ocr-software-convert-pdf-to-text.html
宣伝
次世代システム研究室では、最新のテクノロジーを調査・検証しながらインターネットのいろんなアプリケーションの開発を行うアーキテクトを募集しています。募集職種一覧 からご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD