2022.04.05
機械学習モデルを軽量化せよ!Tensorflow Liteのモデル最適化について
次世代システム研究室のT.Sです。機械学習が一般的になり、Web等のサーバサイドのようなパワフルなサーバ上ではなく、メモリもCPUも脆弱なモバイル端末上で動くことも多くなってきました。そのようなプログラムを開発する際に注意しなければいけない点としてモデルの軽量化(最適化)になります。性能が限定されているモバイル端末やIoT機器では、サーバサイドとは事情が異なりますからね。今回は、Tensorflow Liteが用意しているモデル最適化の仕組みをご紹介し、理解の助けになればよいかと思います。またモバイル端末だけではなく、通常のサーバサイドでも処理高速化で使えるテクニックがあるので、是非どこで使えるのかを含めご覧いただければと思います
TL;DR
量子化やその他最適化手法を用いると精度を大きく損なわず、モデルサイズを下げることが可能です。モバイルデバイスやIoT機器での利用の際には省メモリ、高速化、通信量削減のためこのような手法を利用を検討すると良いかと思われます。
Tensorflow Liteとは
Tensorflow Liteとは、モバイル端末やIoTデバイスなど性能に制限のある端末で機械学習モデルを動作させるのに必要な機能を追加してTensorflow ファミリーの一つになります。最適化の手法一覧などはTensorflow Liteのマニュアルをご覧いただければと思いますが、機械翻訳されているせいか日本語が読みずらいところも多いため、内容をわかりやすくご説明できればと思います。
今回紹介する最適化の手法
今回は以下の3つを紹介いたします。モデル自体を小さくして、最適する手法としての「量子化」。そして重みを工夫することにより、圧縮性能などを高める「プルーニング(枝刈り)」「クラスタリング」の計3つとなります
- 量子化
- プルーニング(枝刈り)
- クラスタリング
量子化
量子化というと若干何をやっているのかわかりにくいですが、平たく言うと「これまで浮動小数点(単精度/倍精度)で持っていた重みなどの値を、別の小さな値に変換してモデルサイズの縮小や処理の高速化を図るもの」だと理解いただければと思います(語弊はあるかもしれませんが。。。)。Tensorflow Liteで用意されている量子化のうち、今回はトレーニング後に実施する以下の代表的な3つの量子化手法をご紹介いたします。
- ダイナミックレンジ(Dynamic range quantization)
- 完全な整数(Full integer quantization)
- 半精度浮動小数点数量子化(Float16 quantization)
ダイナミックレンジ
まず1つ目はダイナミックレンジになります。ダイナミックレンジという表現からは何を実施するか若干わかりにくいですね。この手法は浮動小数点で持っていたWeightを整数(int8)に変換する手法となります。単精度浮動小数点であれば32bitのデータを,8bitに変換するわけですから単純にモデルサイズは1/4となります。
ただ浮動小数点を整数に変換すると言われてもどうやるの?というお話がありますよね。これについての仕様もTensorflow Liteでは明確に記載されています。
詳細はこちらをご覧いただければと思いますが、計算式は以下となっています。
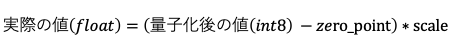
zero_pointを無視すれば、実際のweightを除算してint8を得られるようなscaleを学習するということになります。こう考えると難しいお話ではないですよね。ちなみにこのScaleはテンソル全体で一つというわけではなく、チャンネルごとに別の値が設定されています。
概念を理解したところでコーディング方法を見てみましょう。
kerasで学習してmodel.fitするところまでは従来どおりです。このmodelをtensorflow Lite形式に変換をするために converterを作成します。
converter = tf.lite.TFLiteConverter.from_keras_model(model)
次に実際にConvertします。ちなみにtf.lite.OptimizeにはDEFAULTを含め4つの値が要されていますが、[OPTIMIZE_FOR_SIZE]と[OPTIMIZE_FOR_LATENCY]は既にDeprecatedとなっておりDEFAULTと同様、[EXPERIMENTAL_SPARSITY]はexperimentalのため基本はDEFAULT利用になることが多いかと思います。
converter.optimizations = [tf.lite.Optimize.DEFAULT] tflite_quant_model = converter.convert()
変換自体は以上となります。変換自体は非常に簡単ですね。inferenceは若干癖があり、特にandroidなどのkotlin上で動作させるためにはnumpyなどがないため面倒なのですがここでは趣旨がずれるため割愛します
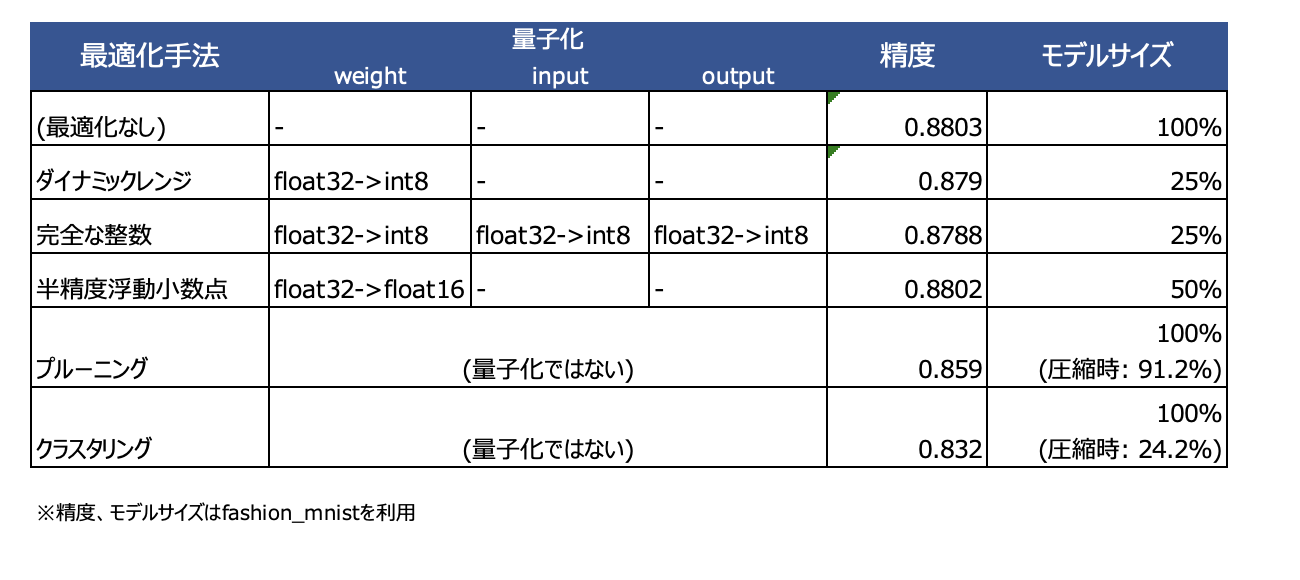
ちなみにfashion mnistで実際に精度とモデルサイズを比較した結果は以下となります。精度がほぼ変わらないにも関わらず、モデルサイズは大きく削減されていますね。
- 精度
- 量子化前: 0.880
- 量子化後: 0.879
- モデルサイズ
- 量子化前: 408,876 byte
- 量子化後: 104,192 byte
完全な整数
次に「完全な整数」による最適化になります。ダイナミックレンジもfloat32->int8で整数化でしたが、こちらも整数とあります。何が違うのでしょうか?
これを理解するのにまずマニュアルに乗っているコードを見てみましょう。
def representative_data_gen():
for input_value in tf.data.Dataset.from_tensor_slices(train_images).batch(1).take(100):
yield [input_value]
converter = tf.lite.TFLiteConverter.from_keras_model(model)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.representative_dataset = representative_data_gen
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
converter.inference_input_type = tf.uint8
converter.inference_output_type = tf.uint8
tflite_model_quant = converter.convert()
※https://www.tensorflow.org/lite/performance/post_training_integer_quant?hl=jaより抜粋
先程のダイナミックレンジと比較するとどうでしょう? converter.optimizationsのところまでは同一ですが、これにrepresentative_dataset以降が追加されており、input値のサンプル値を取得していますね。ここが「完全な整数」という意味になります。
つまりダイナミックレンジで実施していたweightのint8化は同一で、これに加えてinput, outputテンソルもint8化しているというわけです。これですべてがint8に変換されるため「完全な」という修飾子がついているわけですね。表にすると以下のようなイメージになります。ちなみにbiasも同様にfloat -> intされているようですが、こちらはint8ではなくもう少し大きい精度になっているようです。
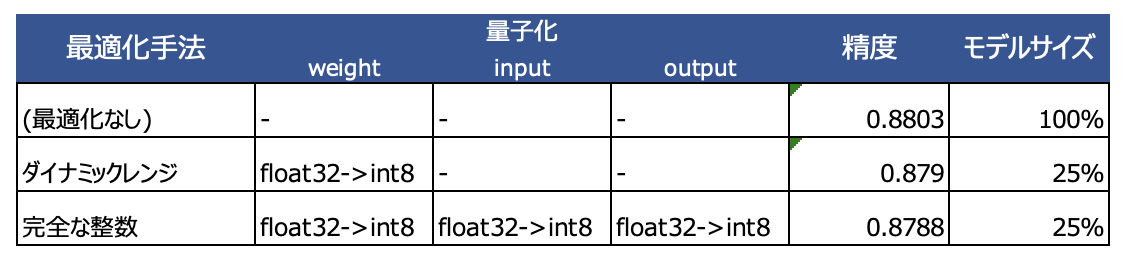
モデルサイズの削減率自体はweightの変換がfloat -> int8のため同一になっています。ただ処理時間自体はダイナミックレンジより高速化されているとのため精度と合わせてみてどちらを利用するか考えることになります。
半精度浮動小数点数量子化
最後に「半精度浮動小数点数量子化」になります。これは名が体を表しており、わかりやすいですね。読んで字の如くfloat32->float16に変換するということになります。これまでの整数量子化は浮動小数点から整数に変わる処理のため、GPUというよりはCPUで処理しているアーキテクチャが適しているとあります。しかし、この半精度浮動小数点数量子化は、浮動小数点のままであるため、単精度浮動小数点での処理を最適化しているGPUに適しているようです。そのため利用しているプロセッサがCPU or EdgeTPUの場合は整数量子化、CPU or GPUの場合は半精度浮動小数点数量子化が適しているという考え方もあるようです。
変換コードは以下となります。こちらも非常にわかりやすいですね。
converter.optimizations = [tf.lite.Optimize.DEFAULT] converter.target_spec.supported_types = [tf.float16] tflite_fp16_model = converter.convert()
※https://www.tensorflow.org/lite/performance/post_training_float16_quant?hl=jaより抜粋
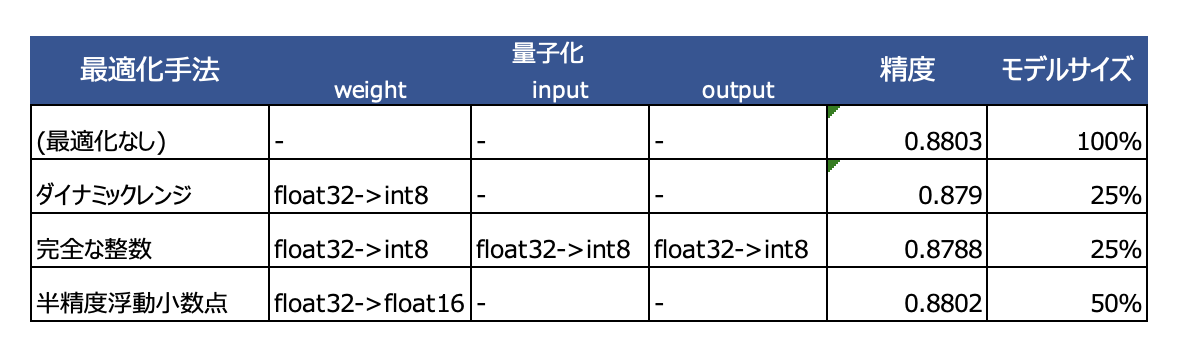
こちらも加えて表した表が以下となります。結果としてどの手法も精度は損なわず、モデルサイズの削減が実施できていることがわかります。ただこれはfashion mnistのような単純なデータセットだからということもありますし、各ケースに置いて試行した上で最適なものを探す必要はあるかと思います。
プルーニング(枝刈り)
次はプルーニングになります。プルーニング自体は決定木周りでよく聞く用語であり、耳馴染みのある方も多いのではないでしょうか(あちらは日本語訳すると剪定とされることも多いですが、基本的な考え方は同一です)。プルーニングの処理イメージは以下の図を御覧ください
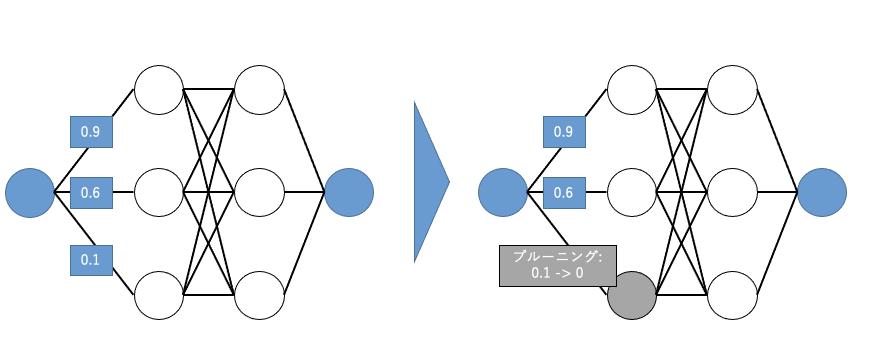
量子化はweightなどの値をfloat32から別のサイズへ変更してモデルサイズを削除していましたが、プルーニングはこれと異なります。図にあるように重要でないパラメータを0に変換することにより、その計算を省略してしまうことが目的となります。
コードとしては以下でprune_low_magnitude関数を使って再度modelを学習する感じですね。
import tensorflow_model_optimization as tfmot
pruning_params = {
'pruning_schedule': ConstantSparsity(0.5, 0),
'block_size': (1, 1),
'block_pooling_type': 'AVG'
}
prune_low_magnitude = tfmot.sparsity.keras.prune_low_magnitude
model = prune_low_magnitude(model, **pruning_params)
model_for_pruning.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
model_for_pruning.fit(train_images, train_labels, batch_size=128, epochs=10, validation_split=0.1)
さてこの結果精度とサイズはどうなったでしょうか?
- 精度
- プルーニング前: 0.880
- プルーニング後: 0.859
- モデルサイズ
- プルーニング前: 408,876 byte
- プルーニング後: 408,876 byte
精度は予想通り一定低下していますが、モデルサイズが変わっていませんね?処理効率はあがるものの、これではあまり意味がないのでは…と思ってしまいますが、プルーニングの原理を知っていればこの結果は当然であることがわかるかと思います。なぜならプルーニングは単に数値を0にして枝刈りしているだけなので、floatで確保している領域は変わりませんので当然サイズも変わりません。ただしサイズと言う意味では0値が増えるため圧縮効率は良くなっています。IoTデバイスのように通信容量も限られており、ギリギリまで容量を削減したい場合などに適した手法であることがわかりますね。
- モデルサイズ
- プルーニング前非圧縮: 408,876 byte
- プルーニング前圧縮(gzip): 121,276 byte
- プルーニング後圧縮(gzip): 110,695 byte
クラスタリング
最後はクラスタリングです。こちらも機械学習でよく出てくる単語でイメージしやすいですね。処理イメージは以下の図を御覧ください。
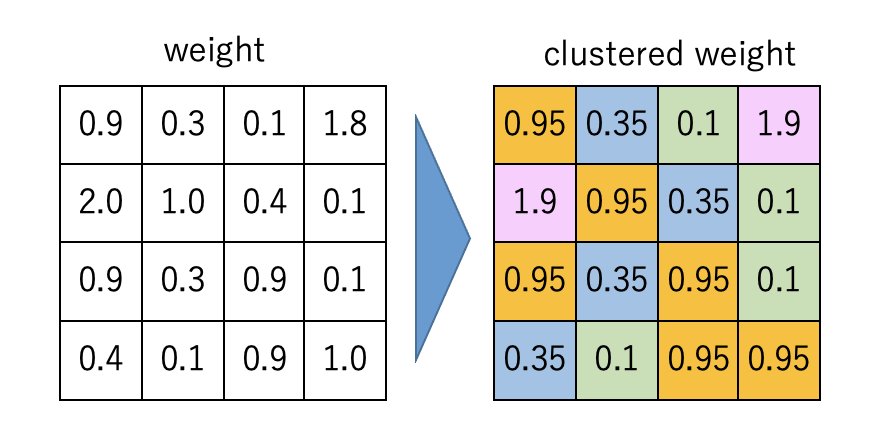
名前のごとく値をクラスタリングした上で、同一クラスタの値を重心値(centroid)で共通化させます。ではこの結果精度とサイズはどうなるでしょうか?(サイズはなんとなく予想がつくかと思いますが。。)
- 精度
- クラスタリング前: 0.880
- クラスタリング後: 0.832
- モデルサイズ
- クラスタリング前非圧縮: 408,876 byte
- クラスタリング前圧縮(gzip): 121,276 byte
- クラスタリング後圧縮(gzip): 29,303 byte
サイズはプルーニングと同様圧縮すると大きく下がるようです。しかもクラスタリングのほうがサイズが劇的に下がっていますね。今回は16クラスタで実施したため、カーディナリティも低くなり圧縮効率が高くなったためと予想されます。反面精度は一番低くなっています。しかもこの値はクラスタ数やepochにかなり左右され、ひどいときには0.3台にもなっていました。サイズ圧縮率は高いかわりに。かなりピーキーであるためちょっと使いづらい印象を受けています。
すべての結果をまとめると以下のような表となります。単純にモデルサイズを削減し、処理効率を高めたい場合にまず量子化をして、その上で通信容量も削減したい場合にプルーニング、クラスタリングを試したほうが良いのではないかという感覚でおります。あくまで、これは私個人の1意見ですしモデルによっても大きく状況はことなるため、それぞれのケースで試行して最適な手法をさがしていただければと思います
次世代システム研究室では、ビッグデータ解析プラットフォームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧からご応募をお願いします。
一緒に勉強しながら楽しく働きたい方のご応募をお待ちしております。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD