2025.04.07
テーブル設計の考慮不足でトラブル発生
こんにちは。次世代システム研究室のM.Mです。
テーブル設計時に考慮が足りておらず、その結果、データベースが高負荷になり、担当しているWEBサービスに影響を与えてしまいました。
今回は、そのサービス影響を与えたテーブルの問題確認と対策について検討してみました。
※利用していたデータベースはGoogle Cloud SQLのPostgreSQLだったので、PostgreSQLでの話になります。
1. どのような要件を満たすためのテーブルだったか?
実際の要件とは違いますが、以下のような要件です。
・ユーザーが月にスマホ画面を何回タップするか集計したい。
Aさんは3月に5000回、4月に6000回、・・・
Bさんは3月に7000回、4月に7500回、・・・
・月ごとに合計何回タップされたか集計したい。
3月は12000回、4月は13500回、・・・
・ユーザーが当月何回タップしたかリアルタイムで画面に表示させたい。
テーブルにて管理する情報としては、ユーザーID、対象月、タップ回数のみではありますが、リアルタイムで画面にタップ回数を表示させたいので、タップする度にカウントアップ処理が必要になり、画面表示のタイミングでカウント数を取得する必要があります。
このような要件の場合、どのようなテーブル構成にすればいいのでしょうか?
2. どのようなテーブル構成にしたか?
カラムについて
- user_id (どのユーザーか)
- target_ym (何年何月の集計か)
- count (何回タップしたか)
主キー・インデックスについて
- ユーザー、月単位での集計なのでuser_idとtarget_ymで主キー
- 月ごとでも集計したいとのことなので、target_ymにインデックス
DDL
create table user_monthly_count ( user_id integer not null, target_ym integer not null, count integer not null, created_at timestamp without time zone not null, updated_at timestamp without time zone not null, primary key (user_id, target_ym) ); create index user_monthly_count_target_ym_idx on user_monthly_count(target_ym);
データ処理イメージ
毎月、初回タップ時に対象月のデータをinsertし、その後、翌月になるまで対象月のデータをupdateでカウントアップしていく流れになります。
例えば、3月に初めてタップしたタイミングで以下のようなinsertを行う。
insert into user_monthly_count values(1, 202503, 1, now(), now());
それ以降、3月の間は、以下のようにupdateを行いカウントアップしていく。
update user_monthly_count set count = count + 1, updated_at = now() where user_id = 1 and target_ym = 202503;
4月になったら、新たにtarget_ymを202504として同様の処理が行われていきます。
このような処理がユーザー毎にリアルタイムで行われていきます。
また、画面表示のため以下のようなselectもリアルタイムで行われている状態となります。
select * from user_monthly_count where user_id = 1 and target_ym = 202503;
特に複雑な処理でもなく、user_idとtarget_ymの複合主キーであることから、複合主キーのインデックスが利用されるので、インデックスの考慮もされています。
月ごとの集計は、target_ymを使ってsum(count)とするだけです。
3. テーブルの問題確認
確認環境としては、Cloud SQL PostgreSQL 15を利用しています。
・target_ym(202503)で100件登録する
insert into user_monthly_count(user_id, target_ym, count, created_at, updated_at)
select
user_id, 202503, 1, now(), now()
from
generate_series(1,100) as user_id
;
・登録状況を確認する
SELECT schemaname, relname, n_live_tup, n_dead_tup, last_vacuum, last_autovacuum, last_analyze, last_autoanalyze FROM pg_stat_all_tables where schemaname = 'public';
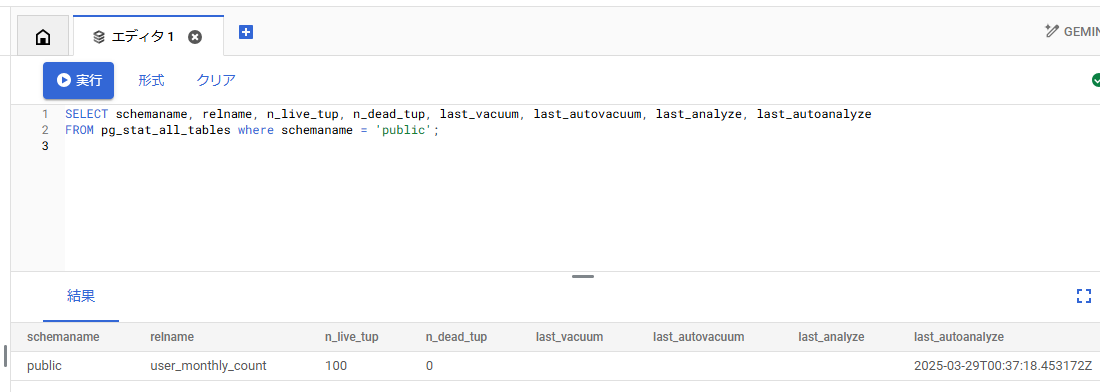
n_live_tupを見ると100件登録されていることが確認できます。
・タップ回数を取得するSQLを実行する
EXPLAIN ANALYSE SELECT * FROM user_monthly_count where user_id = 55 and target_ym = 202503;
user_idは適当に55にしています。(特に意味はありません)
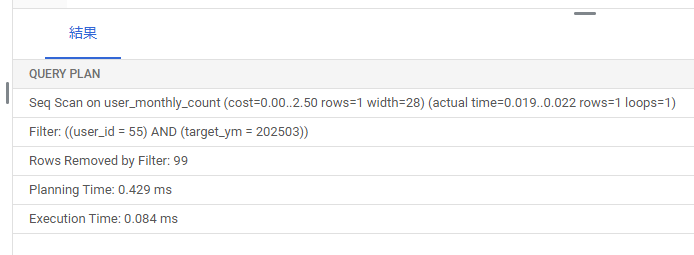
フルスキャンになっています。
100件しか登録されていないので、インデックスを利用するよりフルスキャンの方が効率がよいと判断したのでしょう。
・target_ym(202503)に追加で2,999,900件登録して合計300万件登録されている状態にする
insert into user_monthly_count(user_id, target_ym, count, created_at, updated_at)
select
user_id, 202503, 1, now(), now()
from
generate_series(101,3000000) as user_id
;
・登録状況を確認する

n_live_tupを見ると300万件登録されていることが確認できます。
登録した後すぐだからか、オートアナライズは動いていないようです。
・再度、タップ回数を取得するSQLを実行する
EXPLAIN ANALYSE SELECT * FROM user_monthly_count where user_id = 55 and target_ym = 202503;
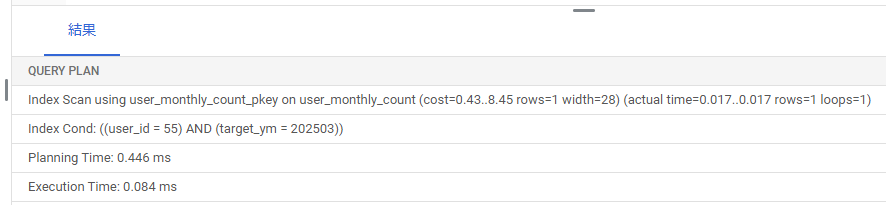
意図したとおり、複合主キーを利用したインデックス(user_monthly_count_pkey)が使われています。
特に問題なさそうです。
では翌月になった想定でtarget_ym(202504)で検証を進めていきます。
・翌月としてtarget_ym(202504)で100件登録する
insert into user_monthly_count(user_id, target_ym, count, created_at, updated_at)
select
user_id, 202504, 1, now(), now()
from
generate_series(1,100) as user_id
;
・登録状況を確認する

n_live_tupが3000100になっており100件追加されたことが確認できます。
また、オートバキューム・オートアナライズも動いたようです。
・タップ回数を取得するSQLを実行する(今回は202504です)
EXPLAIN ANALYSE SELECT * FROM user_monthly_count where user_id = 55 and target_ym = 202504;
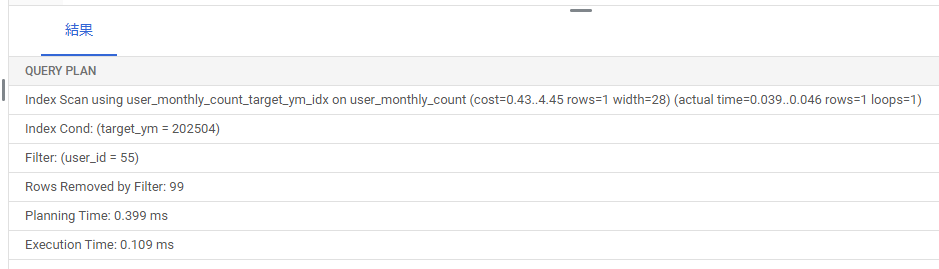
ん?月ごとに合計何回タップされたかも集計するために作ったtarget_ymだけのインデックス(user_monthly_count_target_ym_idx)が使われている。なぜ?
先ほどと同様、複合主キーを利用したインデックススキャンになってほしかったのだが。
202504の件数が100件しかないからか?user_id = 55は2件しかないのだが・・・
・target_ym(202504)に追加で99,900件登録して合計10万件登録されている状態にする
insert into user_monthly_count(user_id, target_ym, count, created_at, updated_at)
select
user_id, 202504, 1, now(), now()
from
generate_series(101,100000) as user_id
;
・登録状況を確認する

3,100,000件登録されている状態になりました。登録前のアナライズ日時と変化がないので、オートアナライズは動いていないようです。
・再度、タップ回数を取得するSQLを実行する
EXPLAIN ANALYSE SELECT * FROM user_monthly_count where user_id = 55 and target_ym = 202504;
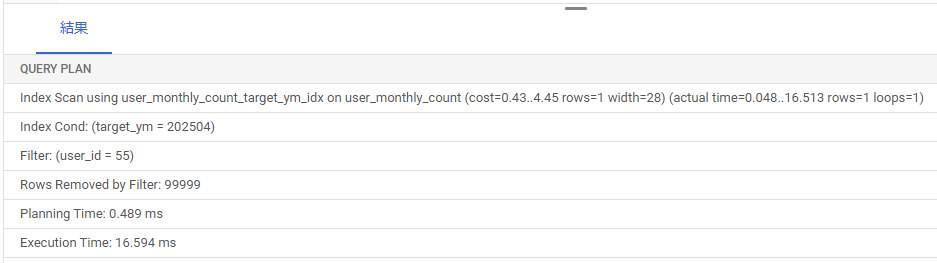
10万件にしても、target_ymだけのインデックス(user_monthly_count_target_ym_idx)が使われたままです。
しかも100件登録時と10万件登録時と比較すると0.109msから16.594msと遅くなっています。
・登録状況を確認する

特にオートアナライズは動いていない。
・手動でアナライズする
ANALYSE user_monthly_count;

last_analyzeにて手動アナライズがされたことが確認できます。
・再度、タップ回数を取得するSQLを実行する
EXPLAIN ANALYSE SELECT * FROM user_monthly_count where user_id = 55 and target_ym = 202504;
スクリーンショット取り忘れていましたが、アナライズ後は複合主キーを利用したインデックススキャンになっていました。
アナライズされると意図したインデックスが使われるが、それまでの間は、月次集計用のインデックスが使われパフォーマンス遅延が発生することが分かりました。
確認できたこと
画面表示の際はインデックス(user_monthly_count_pkey)が利用され、バッチで月次の集計をする際は、インデックス(user_monthly_count_target_ym_idx)が利用される想定だった。
月初1日からリアルタイムで対象月のデータが徐々に登録されていくことになるが、
月初1日はしばらくtarget_ymのデータが少ない状態が続くためか、画面表示用のSELECTでも月次集計用インデックスが使われてしまいパフォーマンス遅延が発生する。
ある程度の件数が登録されオートアナライズが動くまでパフォーマンスが遅延することが確認できた。
またオートアナライズの条件は以下となっております。
解析閾値 = 解析基礎閾値 + 解析規模係数 * タプル数
PostgreSQL 15.4文書
ということは、運用して月数が進むほど、総件数(タプル数)は多くなるので、解析閾値が高くなるため、なかなかオートアナライズが動かないことになる。
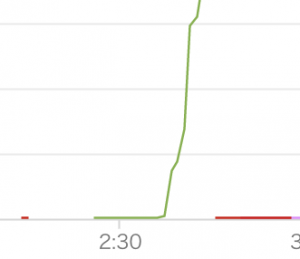
実際にトラブルが発生したサービスは、かなりのリクエスト数のあるサービスで、以下の図のようにCPUが100%になってしまいました。
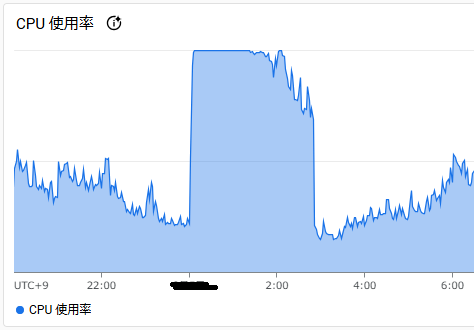
トラブルの際は、復旧が最優先となり、手動アナライズすれば復旧するのかもよく分からず、月次集計処理はバッチでありパフォーマンスが求められていないものであったため、一番確実な月次集計用インデックスを削除することで対応しました。
とはいえ、インデックスを削除してフルスキャンになったらどうしようと怖い思いをしました。
(手動アナライズすれば復旧すると分かっていたとしても、翌月同じことが発生する可能性があるので、最終的には月次集計用のインデックスは削除したとは思います)
4. 対策検討
テーブル設計時に以下の点は考慮しておくべきだと思います。
バッチで集計する目的のインデックスは本当に必要なのか?
Cloud SQLであればサーバーレスエクスポートなど負荷をオフロードできる仕組みも存在する。
データ増加によるアナライズやバキュームについて考慮できているか?
データが増えてきてアナライズやバキュームがなかなか行われない状況になってくるとパフォーマンスが悪くなってくる。
数か月後のデータがどうなっているのか考慮できているか?
過去日付データは使われなくなる場合、パーティショニングやテーブルを分割するなどしてtruncateで過去データを消せた方がよい。
このあたりをテーブル設計時にしっかり考慮できていれば、このトラブルは発生しなかったかも知れません。
ただ、数か月先のテーブルの状況を意識した設計は難しいところでもあります。
今回は、意図しないインデックスが使われたことが原因ではあるので、Cloud SQLでヒント句が使えないか確認してみました。
ヒント句は使えるのか?
PostgreSQLでは、pg_hint_planという拡張機能を利用することで実現できるようです。
Cloud SQLでその拡張機能が利用できるか?
cloudsql.enable_pg_hint_plan フラグを on に設定します。
PostgreSQL の拡張機能を構成する
設定をすれば利用できるようです。(再起動が必要なのは辛い…)
<h4ヒント句をつけて実行する
EXPLAIN ANALYSE SELECT /*+ IndexScan(user_monthly_count user_monthly_count_pkey) */ * FROM user_monthly_count where user_id = 55 and target_ym = 202507
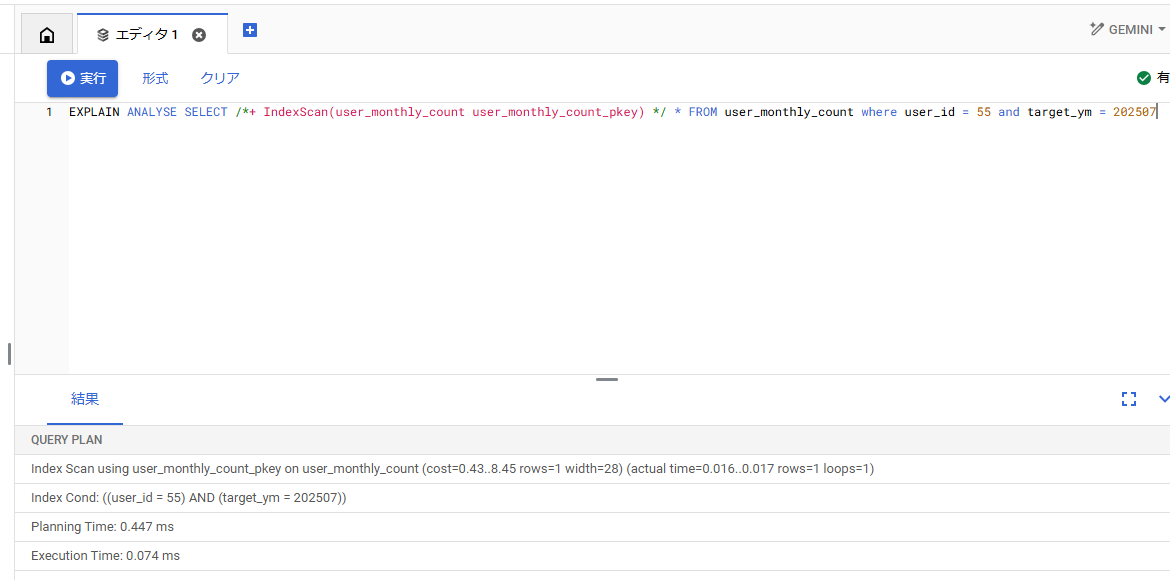
ヒント句をつけない状態で実行すると、月次集計用のインデックスが使われていましたが、上記のようにヒント句をつけると、指定したインデックス(user_monthly_count_pkey)を使うようになりました。
5. まとめ
トラブルの原因は、リアルタイムでの参照用のインデックス、バッチでの集計用のインデックスがあり、月初1日は対象月のデータが少なく徐々に登録されてくるという特徴から、意図しないインデックスが使われるようになったからではあります。
PostgreSQLではないですが、アナライズが動いて逆に意図しないインデックスが使われるようになってトラブルになったこともあります。
今回のようなトラブルになりにくくするためにも、作成しようとしているインデックスが本当に必要か?特にバッチやデータ分析用のインデックスなど作成しなくても対応できる方法がないか?を見直すことは重要だと思います。
また、実際にトラブルになった時は、「エラーがでている」「サービスが動かずレスポンスが返ってこない」状況となりユーザー影響もでているのでパニック状態になります。
そのような状況の中、問題の原因を見つけ対応する必要があるため、かなり追い込まれます。
ヒント句をつけて暫定対応ができる状態にしておくだけでも、心に余裕ができるのではないかと思いました。
最後に、次世代システム研究室では、グループ全体のインテグレーションを支援してくれるアーキテクトを募集しています。アプリケーション開発の方、次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ募集職種一覧からご応募をお願いします。
皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD