2015.12.18
Spark MLlib Word2Vec/K-Meansを用いた単語のクラスタリング
この記事はApache Spark Advent Calendar 2015の18日目の記事です。
はじめまして。次世代システム研究室のT.Nです。
単語をベクトル化して、その類似度や加減算等の処理を可能にするWord2Vec
単体としてだけではなく、今ではSpark MLlibでも提供されているため、大量データでも取り扱いが比較的容易になっています
当記事では、そのSpark Word2Vecを用いて単語をベクトル化し、それをクラスタリング化することで単語をカテゴライジングする方法をご紹介したいと思います
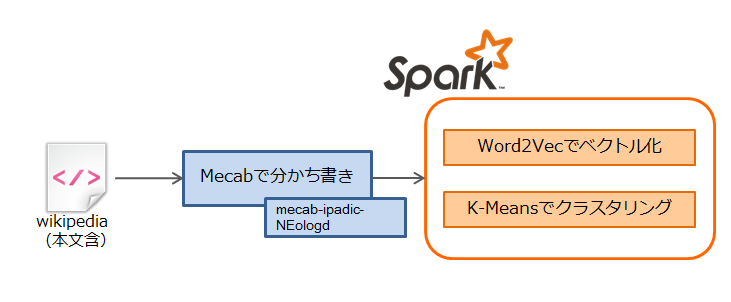
処理概要
処理は大きく分けて2つの工程に分かれます
- WikipediaのデータをWord2Vecが処理できる形式に加工する
- Spark MLlib Word2Vec/K-Meansを使い、ベクトル化・クラスタリングを実施する
なお、Inputデータはある程度大きなもの(加工後で100MB以上)では有りますが、サンプリングしたデータを使用します
そのため、wikipedia全体を取り込んだ時は精度が落ちることも考えられるので、その点留意ください
※1 今回は全データではなく、https://dumps.wikimedia.org/jawiki/latest/jawiki-latest-pages-articles3.xml.bz2のみを使用
分かち書きデータ作成
先述したとおりInputデータはwikipediaを加工して使用します
分かち書きにはMecabを使用しますが、wikipediaは新語も非常に多く、デフォルトの辞書を使用すると満足行く結果が得られません
そこで今回はユーザ辞書としてmecab-ipadic-NEologdを使用します(参考リンク)
今回扱うような新語が得意な辞書で、更新速度も早く、登録ペースもタイムリーで素晴らしいユーザ辞書となっています
ちょっとこの辞書を使うとどうなるか見てみましょう
例えば
「広瀬すず、吉田羊、BABYMETALらが受賞 最も輝いた女性に贈る「VOGUE JAPAN Woman」発表」
という文章を、この辞書を使って形態素解析してみます
通常の辞書であれば「吉田羊」は「吉田」と「羊」の名詞2つに別れそうですが、ここでは固有名詞だとちゃんと認識しています
広瀬すず 名詞,固有名詞,人名,一般,*,*,広瀬すず,ヒロセスズ,ヒロセスズ、 記号,読点,*,*,*,*,、,、,、 吉田羊 名詞,固有名詞,一般,*,*,*,吉田羊,ヨシダヨウ,ヨシダヨー、 記号,読点,*,*,*,*,、,、,、 BABYMETAL 名詞,固有名詞,一般,*,*,*,BABYMETAL,ベビーメタル,ベビーメタル ら 名詞,接尾,一般,*,*,*,ら,ラ,ラ が 助詞,格助詞,一般,*,*,*,が,ガ,ガ 受賞 名詞,サ変接続,*,*,*,*,受賞,ジュショウ,ジュショー 記号,空白,*,*,*,*, , , 最も 副詞,一般,*,*,*,*,最も,モットモ,モットモ 輝い 動詞,自立,*,*,五段・カ行イ音便,連用タ接続,輝く,カガヤイ,カガヤイ た 助動詞,*,*,*,特殊・タ,基本形,た,タ,タ 女性 名詞,一般,*,*,*,*,女性,ジョセイ,ジョセイ に 助詞,格助詞,一般,*,*,*,に,ニ,ニ 贈る 動詞,自立,*,*,五段・ラ行,基本形,贈る,オクル,オクル 「 記号,括弧開,*,*,*,*,「,「,「 VOGUE JAPAN 名詞,固有名詞,一般,*,*,*,VOGUE JAPAN,ヴォーグジャパン,ヴォーグジャパン Woman 名詞,一般,*,*,*,*,* 」 記号,括弧閉,*,*,*,*,」,」,」 発表 名詞,サ変接続,*,*,*,*,発表,ハッピョウ,ハッピョー
今回はこの中から名詞のみを抜き出し、デリミタを半角スペース/文章毎に改行でセパレートするようにInputファイルを作成しています
上記文章であれば以下の用に加工します
(標準化のため単語内の半角スペース削除と、アルファベット小文字を大文字に変換しています)
広瀬すず 吉田羊 BABYMETAL ら 受賞 女性 VOGUEJAPAN WOMAN 発表
Sparkを用いたWord2Vec/K-Means
先ほどwikipediaから作成したコーパスデータを元にSpark MLlibを実行します
今回はLocal実行のためSparkContextもlocal指定されていますが、クラスタ上で実行する際には適宜変更してください
(Macbook Airで30分以上かかりますので気長に待ってください)
import java.io.PrintWriter
import org.apache.spark.SparkContext
import org.apache.spark.mllib.clustering.KMeans
import org.apache.spark.mllib.feature.Word2Vec
import org.apache.spark.mllib.linalg._
import org.apache.spark.rdd.RDD
object WordToVecCluster {
def main(args: Array[String]): Unit = {
// ローカル実行のため適当な名称で
val sc = new SparkContext("local", "example")
// 分かち書きしたファイルを指定
val path = "input.txt";
val source: RDD[String] = sc.textFile(path);
// 分かち書きが半角スペース区切りなので、これをWord2Vecが処理出来る形に変更
val input = source.map(content => content.split(" ").toSeq)
// Word2Vecを用いて単語をベクトル化(100次元:デフォルト)する
// 精度を上げるためイテレーション数を1(デフォルト)→3に変更している
val model = new Word2Vec().setNumIterations(3).fit(input);
// 単語単位
// Word2Vecでベクトル化したデータを、K-Meansで処理できるようにVector型に変換する
val wordvec = model.getVectors.map(x => new DenseVector(x._2.map(elem => elem.toDouble)).asInstanceOf[Vector]).toSeq
// K-Meansを用いてクラスタリング
// クラスタ数
val k = 1000
// イテレーション数
val maxItreations = 10
// クラスタリング実行
val clusters = KMeans.train(sc.parallelize(wordvec) , k, maxItreations)
// クラスタリング結果をファイルに出力
val file = new PrintWriter("out.txt")
model.getVectors.foreach { tuple =>
println(tuple._1 + ": cluster => " + clusters.predict(Vectors.dense(tuple._2.map(_.toDouble))))
}
file.close()
}
}
結果サンプル
上記のコードを実行すると、単語と所属するクラスタが紐付いたテキストファイルが作成されます
奄美群島: cluster => 288 日本語字幕: cluster => 791 ベイスターズ: cluster => 239
さてせっかくクラスタリングしたので、似た単語がどういうクラスタにいるのかちょっと見てみましょう
例1:サッカー関連単語
国内リーグのチームと海外サッカーの単語が分かれていますね
海外サッカーがある程度ひとくくりになっていますが、これがリーグごとに分かれたりするともっと面白いのですが
Jリーグ : cluster => 421 京都パープルサンガ : cluster => 421 サガン鳥栖 : cluster => 421 清水エスパルス : cluster => 421 東京ヴェルディ : cluster => 421 ヴィッセル神戸 : cluster => 421 大分トリニータ : cluster => 421 名古屋グランパスエイト : cluster => 421 アビスパ福岡 : cluster => 421 レアル・マドリード : cluster => 347 レアル・ソシエダ : cluster => 347 デル・ボスケ : cluster => 347 リーガ・エスパニョーラ : cluster => 347 ドイツ代表 : cluster => 347 インターコンチネンタルカップ : cluster => 347 UEFAチャンピオンズリーグ : cluster => 347
例2:懐かしのアニメ関連単語
30代、40代には好きな人も多いであろうキン肉マンについては、1クラスタに集中しています
キャラクターから、担当声優、主題歌を歌った串田アキラまでがまとまっています
ただ担当声優さんは他にも色々やっていますし、「正義」までクラスタリングされているのはやりすぎですね
おそらくinputデータがwikipediaの一部であるためこうなったのではないでしょうか
範囲を増やせばもう少しクラスタリングが変わるのであろうことが予想されます
ゆでたまご: cluster => 144 キン肉マン: cluster => 144 キン肉マンII世: cluster => 144 ウォーズマン: cluster => 144 バッファローマン: cluster => 144 テリーマン: cluster => 144 ラーメンマン: cluster => 144 ウルフマン: cluster => 144 ネプチューンマン: cluster => 144 ジェロニモ: cluster => 144 イワオ: cluster => 144 神谷明: cluster => 144 銀河万丈: cluster => 144 佐藤正治: cluster => 144 郷里大輔: cluster => 144 塩沢兼人: cluster => 144 田中秀幸: cluster => 144 串田アキラ: cluster => 144 正義: cluster => 144
余談ですが2代目、3代目のラーメンマンの声優がいるのに、慣れ親しんだ初代蟹江栄司さんの名前がありませんね(辞書自体には登録あり)
Word2Vecでは取り込んだ単語の出現回数が少ないとベクトルが作成されない仕様(デフォルト:5)があるので、そこにひっかかったのではないかと推測しています
例3:失敗(?)例
上記2つは成功例ですが、もちろんそんなに全てが上手く分かれているわけではありません
下記では小説の名前と、007のサブタイトルと、イタリアとスイスとスロヴェニアと…結構カオスなことになっています
隠された共通点があるのかもしれませんが、ちょっと人間にはわかりませんね
実際に何らかのビジネスに使う場合は、こういうデータの精度をあげていくのが非常に重要かつ難しいポイントになりそうですね
推理小説 : cluster => 716 冒険小説 : cluster => 716 ラジカル : cluster => 716 サンダーボール作戦 : cluster => 716 ムーンレイカー : cluster => 716 核抑止 : cluster => 716 ティチーノ州 : cluster => 716 スロヴェニア : cluster => 716 イタリア料理 : cluster => 716
まとめ
今回はwikipediaの一部データを使用し、ベクトル化/クラスタリングをSparkで実施してみました
内容は非常に興味深いものでしたが、精度の向上やデータ増加に伴う過学習の発生など実際に扱うには課題も多くありそうです
しかし単語をベクトル化し、数値化できれば色々な数学の理論が適用できるようになるのもわかりました
気軽に試すことができるので、興味を持たれた方は是非試してもられればと思います
次世代システム研究室では、アプリケーション開発や設計を行うアーキテクトからスマホアプリ開発まで、変化を楽しむエンジニアを募集しています。次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧からご応募をお願いします。
皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD





