2021.07.05
KubernetesベースのSparkクラスターを検証するー既存Hadoopクランスターと連携編
こんにちは。次世代システム研究室のT.D.Qです。
前回のブログよりConoha VPSでSpark on Kubernetesクラスターの構築について紹介しました。その後このKubernetesクラスター上にHadoopクラスターを構築してSparkの検証を行おうと思いましたが、同部署別のメンバーが別のVPSサーバでHadoop(+Delta Lake)クラスターを構築したので、代わりにこのHadoopクラスターに接続してうまく使えるか検証したので今回の記事で紹介したいと思います。
今回やりたいこと
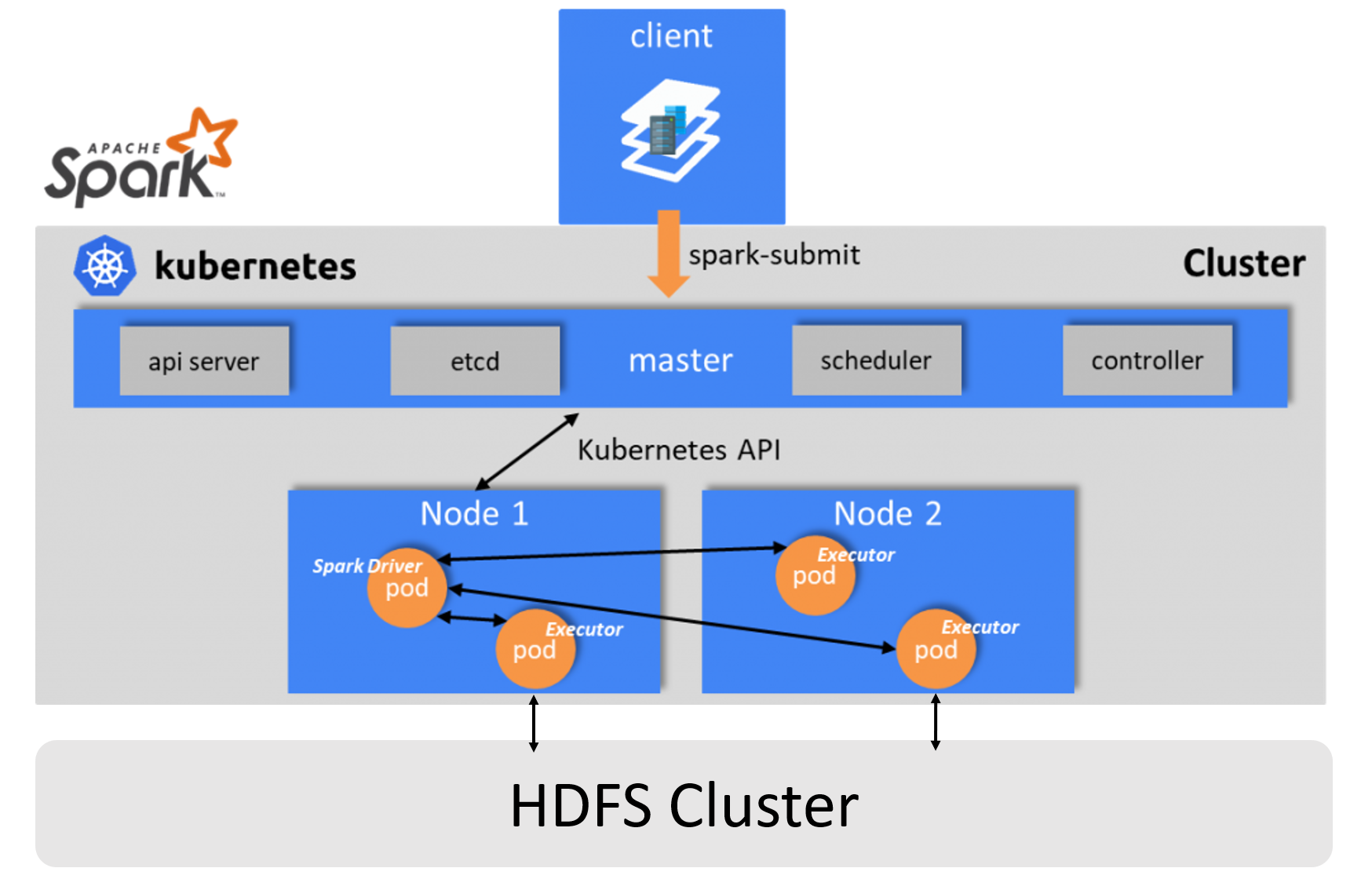
今回やりたいことは、一言で言うとHDFS ClusterがSpark on Kubernetes ClusterのStorage Layerにすることです。以下の図でイメージしやすいです。
ちなみに、以下の図でHDFSクラスターのアーキテクチャーです。ご存知な方が多いと思いますが念のため記載しておきます。
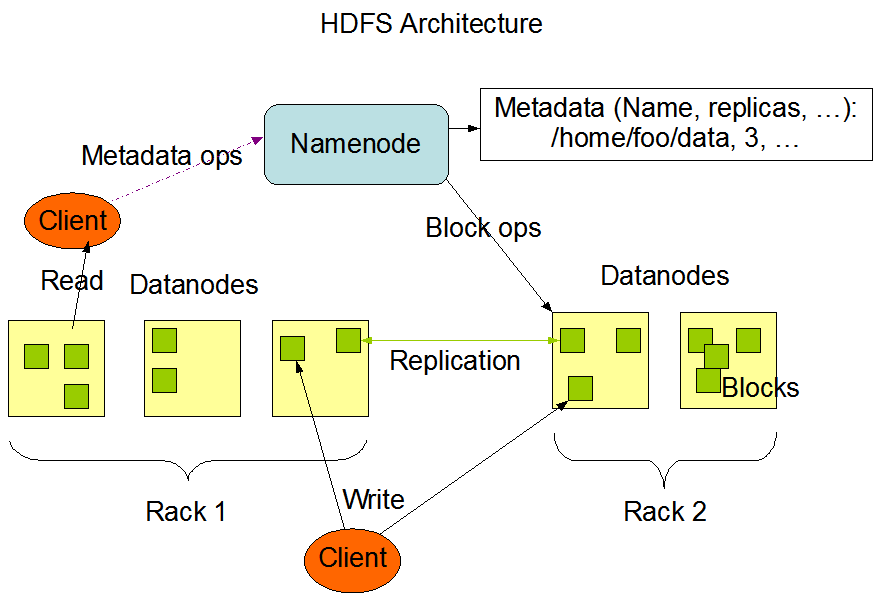
上記のHDFSクラスターのアーキテクチャー図から見ると、基本的にはSpark on KubernetesクラスターのContainerに接続対象HDFS ClusterのHDFS Clientがあれば実現できると思います。
Hadoopクラスターのネットワークに移動
もともと同じ部署なので各メンバーが一つの検証ようのConoha VPSアカウントで複数のVPSマシンを起動して別々のクラスターを構築しました。ただし、プライベートネットワークセグメントが全然違うので、Spark on KubernetesクラスターとHadoopクラスターの通信はできませんでした。幸い、Kubernetesクラスターの再構築が比較的にしやすいので以下の手順でSpark on KubernetesクラスターをHadoopクラスターのプライベートネットワークセグメントに移動しました。
① 資材をバックアップし、KubeSprayでK8sクラスターを削除
②Kubernetesクラスターのネットワークセグメント移動
・Conoha Control Panelでマシンごとに停止
・「プライベートネットワーク」画面でHadoopクラスターのネットワークセグメントに接続し、Internal IPを確認
・VPSマシンを起動し、新しいInternal IPでhosts、ネットワーク設定を更新
③ Kubernetesクラスターを再構築
全マシンの設定完了後、KubeSprayのInventoryファイルに新しいIPを更新して、クラスターを再構築
④ LensにKubernetesクラスターを接続するための設定
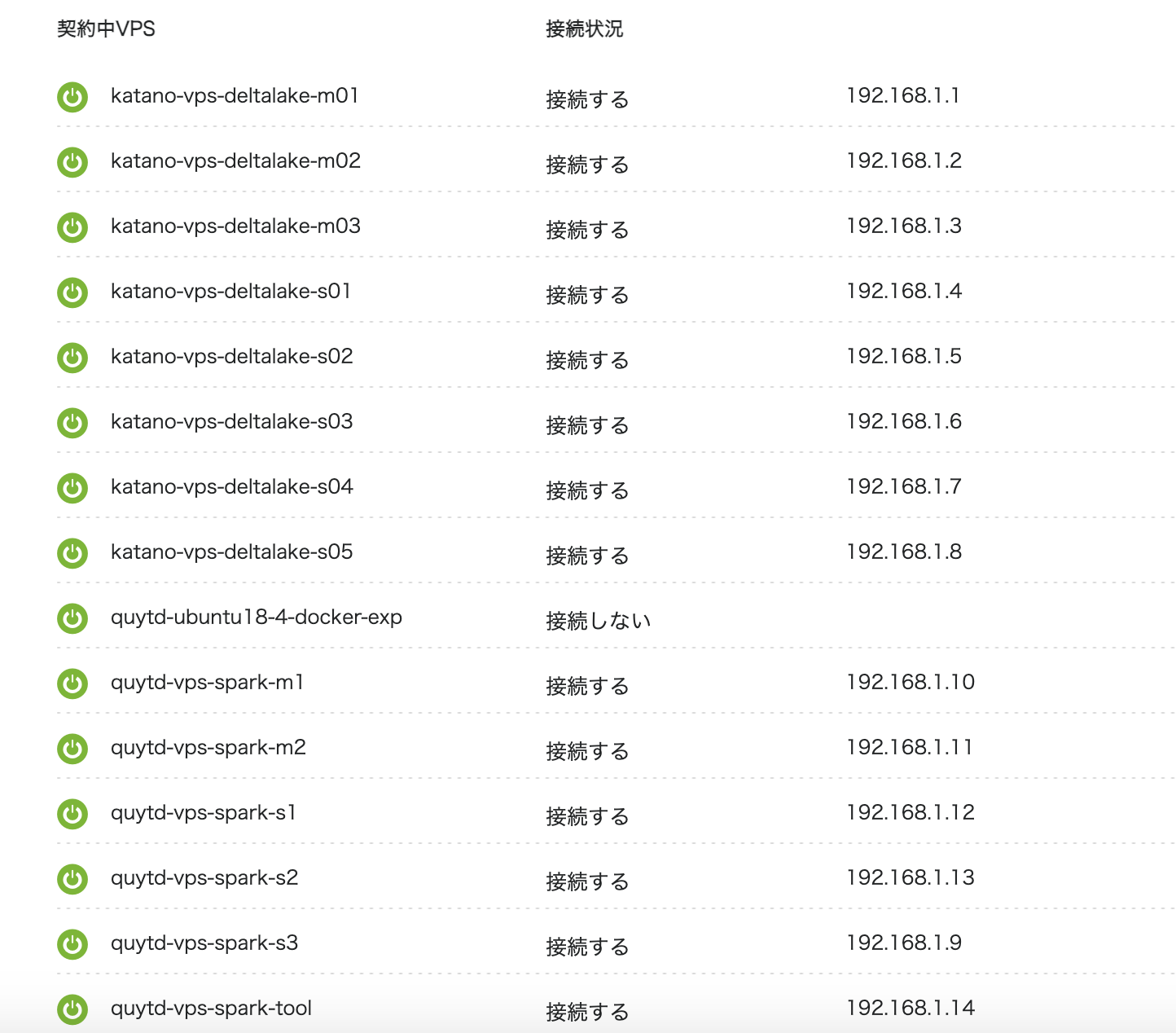
以下の感じでKubernetesクラスターをHadoopからスターに接続することができました。
HDFS Client対応するContainerの構築
Dockerfileのカスタマイズ
Kubernetes上でSparkを使うため、Sparkのソースと同梱するDockerFileとビルドツールで専用のDocker Imageをビルドする必要がありますが、
このDockerFileはHDFS非対応です。Kubernetesクラスター上で実行するSpark Containerが別のHadoopクラスターに接続するため、DockerFileをカスタマイズする必要があります。
今回はpySparkを使うため、SparkのベースイメージのDockerfileを加えて、Python対応のDockerfileの一部を使います。Dockerfile2個の統合後は以下の内容になります。
#
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
ARG java_image_tag=11-jre-slim
FROM openjdk:${java_image_tag}
ARG spark_uid=185
# Before building the docker image, first build and make a Spark distribution following
# the instructions in http://spark.apache.org/docs/latest/building-spark.html.
# If this docker file is being used in the context of building your images from a Spark
# distribution, the docker build command should be invoked from the top level directory
# of the Spark distribution. E.g.:
# docker build -t spark:latest -f kubernetes/dockerfiles/spark/Dockerfile .
USER 0
RUN set -ex && \
sed -i 's/http:\/\/deb.\(.*\)/https:\/\/deb.\1/g' /etc/apt/sources.list && \
apt-get update && \
ln -s /lib /lib64 && \
apt install -y bash tini libc6 libpam-modules krb5-user libnss3 procps && \
mkdir -p /opt/spark && \
mkdir -p /opt/spark/examples && \
mkdir -p /opt/spark/work-dir && \
touch /opt/spark/RELEASE && \
rm /bin/sh && \
ln -sv /bin/bash /bin/sh && \
echo "auth required pam_wheel.so use_uid" >> /etc/pam.d/su && \
chgrp root /etc/passwd && chmod ug+rw /etc/passwd && \
rm -rf /var/cache/apt/*
COPY jars /opt/spark/jars
COPY bin /opt/spark/bin
COPY sbin /opt/spark/sbin
COPY kubernetes/dockerfiles/spark/entrypoint.sh /opt/
COPY kubernetes/dockerfiles/spark/decom.sh /opt/
COPY examples /opt/spark/examples
COPY kubernetes/tests /opt/spark/tests
COPY data /opt/spark/data
ENV SPARK_HOME /opt/spark
WORKDIR /opt/spark/work-dir
RUN chmod g+w /opt/spark/work-dir
RUN chmod a+x /opt/decom.sh
##### ここからはPythonの実行環境を構築する #########
RUN mkdir ${SPARK_HOME}/python
RUN apt-get update && \
apt install -y python3 python3-pip && \
pip3 install --upgrade pip setuptools && \
# Removed the .cache to save space
rm -r /root/.cache && rm -rf /var/cache/apt/*
COPY python/pyspark ${SPARK_HOME}/python/pyspark
COPY python/lib ${SPARK_HOME}/python/lib
WORKDIR /opt/spark/work-dir
ENTRYPOINT [ "/opt/entrypoint.sh" ]
# Specify the User that the actual main process will run as
USER ${spark_uid}
Hadoop Clientの設定
Hadoopクラスターに接続するため、稼働するContainerがそのクラスターのユーザー及び設定情報を持つ必要があります。Hadoopクラスターの構築手順と同様user、group及び必要なディレクトリを以下の通りに設定しました。
# Add users for Spark and Hadoop cluster
RUN groupadd hadoop && \
groupadd hdfs && \
useradd -N -g hadoop zookeeper && \
useradd -g hadoop -G hdfs hdfs -m && \
useradd -N -g hadoop yarn -m && \
useradd -N -g hadoop -u ${spark_uid} -m spark && \
mkdir /usr/lib/hadoop && \
mkdir -p /var/log/hadoop && \
mkdir -p /var/log/yarn && \
mkdir -p /var/run/hadoop && \
mkdir -p /var/run/yarn && \
mkdir /var/log/spark && \
mkdir /var/run/spark && \
mkdir -p /var/hadoop/yarn/{local,recovery}
RUN chown root:hadoop /var/hadoop && \
chown -R hdfs:hadoop /var/run/hadoop && \
chown -R hdfs:hadoop /var/log/hadoop && \
chown -R yarn:hadoop /var/log/yarn && \
chown -R yarn:hadoop /var/run/yarn && \
chmod 775 /var/log/hadoop && \
chmod 775 /var/log/yarn && \
chown -R spark:hadoop /var/log/spark /var/run/spark
Hadoopクラスーの設定情報をImageにコピー
SCPコマンドでHadoopクラスターを構築するとき展開した/usr/lib/hadoop/hadoop-3.2.2をDocker Imageをビルドマシンに移動してImageビルド時にコピーするコマンドを用意する。ビルド時に「/usr/local/spark」からbuildコマンド実行するので、マシンの「/usr/local/spark/kubernetes/dockerfiles/spark8s/hadoop-3.2.2」にSCPしておきました。
Dockerfileに以下のビルドコマンドを追加します。
# Set up Hadoop environment
COPY kubernetes/dockerfiles/spark8s/hadoop-3.2.2 /usr/lib/hadoop/hadoop-3.2.2
RUN cd /usr/lib/hadoop && \
ln -s hadoop-3.2.2 current && \
chown -R root:hadoop /usr/lib/hadoop/hadoop-3.2.2 && \
chmod 775 /usr/lib/hadoop/current/etc/hadoop && \
cd /etc && \
ln -s /usr/lib/hadoop/current/etc/hadoop hadoop
次に、sparkユーザーの環境変数を設定しましょう。Dockerfileの後尾に以下のコマンドを追加することで対応できます。
USER ${spark_uid}
# Set environment variables for spark user in order to access to HDFS
RUN touch /home/spark/.bash_profile
ENV HADOOP_HOME /usr/lib/hadoop/current
ENV HADOOP_CONF_DIR ${HADOOP_HOME}/etc/hadoop
ENV HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_HOME}/lib/native
ENV LD_LIBRARY_PATH="${LD_LIBRARY_PATH}:${HADOOP_COMMON_LIB_NATIVE_DIR}"
ENV PATH=${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:/opt/spark/bin:/opt/spark/sbin:${PATH}
ENV PYTHON_PATH=/usr/bin/python3
早速、Docker Imageをビルドして確認しましょう。Sparkのソースと同梱するビルドツールを使うのでコマンドは以下のとおりです。
k8sadmin@quytd-spark-tool:~$ cd /usr/local/spark k8sadmin@quytd-spark-tool:/usr/local/spark$ sudo bin/docker-image-tool.sh -r quytd -t v3.2.1 -p kubernetes/dockerfiles/spark8s/Dockerfile build 〜〜一部抜粋〜〜 Successfully built f70981d7b243 Successfully tagged quytd/spark:v3.2.1 Successfully built edf35405b7b2 Successfully tagged quytd/spark-py:v3.2.1
ビルドが成功したのでImageを確認しましょう。ツールから2個のImageファイルを作成しましたが、今回使いたいものがquytd/spark-pyになります。
k8sadmin@quytd-spark-tool:/usr/local/spark$ sudo docker images | grep v3.2.1 quytd/spark-py v3.2.1 edf35405b7b2 3 hours ago 3.19GB quytd/spark v3.2.1 f70981d7b243 3 hours ago 613MB k8sadmin@quytd-spark-tool:/usr/local/spark$
ビルドしたImageが問題ないか確認するため、DockerからContainerを立ち上がって確認したいと思います。
sudo docker run -it quytd/spark-py:v3.2.1 /bin/bash spark@2aed70d6b90c:/$ hdfs dfs -ls / 2021-07-04 11:03:21,326 WARN hdfs.DFSUtilClient: Namenode for k-deltalake remains unresolved for ID nn1. Check your hdfs-site.xml file to ensure namenodes are configured properly. 2021-07-04 11:03:21,560 WARN hdfs.DFSUtilClient: Namenode for k-deltalake remains unresolved for ID nn2. Check your hdfs-site.xml file to ensure namenodes are configured properly. 2021-07-04 11:03:22,078 INFO retry.RetryInvocationHandler: java.net.UnknownHostException: Invalid host name: local host is: (unknown); destination host is: "katano-vps-deltalake-m02.testspark.com":8020; java.net.UnknownHostException; For more details see: http://wiki.apache.org/hadoop/UnknownHost, while invoking ClientNamenodeProtocolTranslatorPB.getFileInfo over katano-vps-deltalake-m02.testspark.com:8020 after 1 failover attempts. Trying to failover after sleeping for 925ms.
うまくHDFSクラスターのNamenodeのホスト名を解消できなかったのでようです。原因を調べてみます。
Hadoopクラスターのホスト問題と回避
上記のエラーログを確認したら、以下の内容がありましたので、Hadoopクラスターの設定ファイル(core-site.xml, hdfs-site.xmlなど)にクラスターのNamenodeやDatanodeがFQDNで記述されていますが、Containerの/etc/hostsには記載してないのでうまくHadoopクラスターに接続できなかったです。
Namenode for k-deltalake remains unresolved for ID nn1.Check your hdfs-site.xml file to ensure namenodes are configured properly. Namenode for k-deltalake remains unresolved for ID nn2.Check your hdfs-site.xml file to ensure namenodes are configured properly. java.net.UnknownHostException: Invalid host name
実は、DockerのImageをビルドするときは/etc/hostsが変更してもビルド後にリセットされて変更内容が残らなく、Docker runでContainerを起動するときに「—add-host FQDN:IP」で/etc/hostsにFQDNとIPを追加できますが、今回はKubernetesを使うのでこの方法は難しいですね。一方でKubernetesもこの方法を非推奨でHostAliasesの対応方法を提案しました。
ただし、Spark on Kubernetesのユーザーケースで考えるとやはり適用も難しいかと思いました。StackOverflowなどこの問題で悩んでいる人が結構いますね。よく考えたら今回はContainerからHadoopクラスターの各ノードに通信できたら良いっていう感じなので、ひとまずHadoopの設定ファイルにFQDNがホストのIPに置き換えることで解決できるのではないかと思いましたので、core-site.xml, hdfs-site.xml, yarn-site.xmlで実施し、Docker Imageを再度ビルドしました。まあ、綺麗なやり方ではないと思いますが、稼働中なContainerからHDFSに接続できるようになりました。
ちなみに、ContainerからHDFSにファイル書き込み、読み込みが問題ないことを確認しました。良さそうですね。
sudo docker run -it quytd/spark-py:v3.2.1 /bin/bash spark@2aed70d6b90c:/$ hdfs dfs -ls /tmp Found 5 items drwxr-xr-x - spark hadoop 0 2021-07-03 06:20 /tmp/delta-table drwxr-xr-x - hdfs hadoop 0 2021-06-06 05:42 /tmp/exp_data drwx-wx-wx - spark hadoop 0 2021-04-01 01:50 /tmp/hive drwxrwxrwx - hdfs hadoop 0 2021-04-03 00:11 /tmp/load_data drwxrwxrwx - hdfs hadoop 0 2021-07-02 22:48 /tmp/spark8s spark@2aed70d6b90c:/$ spark@2aed70d6b90c:/$ echo "1,2,3,4,5,6" > /tmp/test.txt spark@2aed70d6b90c:/$ hdfs dfs -put /tmp/test.txt /tmp/spark8s/ spark@2aed70d6b90c:/$ hdfs dfs -ls /tmp/spark8s/test.txt -rw-r--r-- 3 spark hadoop 12 2021-07-03 09:17 /tmp/spark8s/test.txt spark@2aed70d6b90c:/$ hdfs dfs -cat /tmp/spark8s/test.txt 1,2,3,4,5,6 spark@2aed70d6b90c:/$
Spark Operatorを導入する
Dockerより単一ContainerからHadoopクラスターに接続できましたので、Kubernetesを使ってpySparkアプリケーションで複数のContainerを起動して検証したいと思います。
今回、以下のpySparkスクリプトでHDFSに接続の検証します。
from pyspark.sql import SparkSession
sparkSession = SparkSession.builder.appName("SparkSimpleHDFSIO").getOrCreate()
# Read data from HDFS
df_load = sparkSession.read.csv('/tmp/spark8s/test.txt')
df_load.show()
sparkSession.stop()
前回の記事と同様の場所に展開して、PythonのHTTPサーバーでファイルを提供できるようにしておく。
cd /var/local/www/spark8s/ python3 -m http.server 30001
前回のブログはSpark-submitを対応するホスト(quytd-spark-toolマシン)からSpark-submitコマンドを実行しましたが、作業のMacbook PCなどKubectlを実行可能だがspark-submitを対応しないマシーンからも実行できるようにしたいので、Spark Operatorを導入しました。
Spark OperatorがKubernetesを開発したGoogle社から提供している機能で、Kubernetes上のApache Sparkアプリケーションのライフサイクルを管理するための優れたKubernetesオペレーターです。詳細はSpark Operatorの公開資料をご参照ください。ちなみに、Spark Operatorをうまく使えば、上記の/etc/hosts問題を解決できる可能性があると思います。
Spark OperatorのArchitectureは以下のイメージです。

今回、Spark Operatorのインストール手順を参考してLensのConsoleで以下のHelmコマンドを使ってインストールしました。
$ helm repo add spark-operator https://googlecloudplatform.github.io/spark-on-k8s-operator $ helm install sparkoperator spark-operator/spark-operator --namespace spark-operator --create-namespace
SparkOperatorはKubernetesの世界に入るのでspark-submitはYAMLファイルで実装されます。検証用のスクリプトは以下の感じで、ファイル名が「spark-operator/pyspark-hdfs-simple-io.yaml」にします。
apiVersion: "sparkoperator.k8s.io/v1beta2"
kind: SparkApplication
metadata:
name: spark-hdfs-io
namespace: default
labels:
app: spark8s
version: 3.1.1
spec:
type: Python
pythonVersion: "3"
mode: cluster
image: "quytd/spark-py:v3.2.1"
imagePullPolicy: Always
mainApplicationFile: "http://192.168.1.14:30001/hdfs_simple_io.py"
sparkVersion: "3.1.1"
restartPolicy:
type: Never
driver:
cores: 1
coreLimit: "1200m"
memory: "512m"
labels:
version: 3.1.1
serviceAccount: spark
podSecurityContext:
runAsUser: 185
executor:
cores: 1
instances: 1
memory: "512m"
labels:
version: 3.1.1
serviceAccount: spark
podSecurityContext:
runAsUser: 185
早速LensのConsoleからSpark Operatorを適用コマンドを実行して結果を確認したいと思います。
kubectl apply -f spark-operator/pyspark-hdfs-simple-io.yaml sparkapplication.sparkoperator.k8s.io/spark-hdfs-io created
LensでSparkジョブの実行が完了したことを確認できたのでDriver Podを確認しましょう。
% kubectl describe pod/spark-hdfs-io-driver ~~~一部抜粋〜〜〜 Name: spark-hdfs-io-driver Node: quytd-spark-tool/192.168.1.14 Status: Succeeded IP: 10.233.73.7 Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled 2m12s default-scheduler Successfully assigned default/spark-hdfs-io-driver to quytd-spark-tool Normal Pulling 2m11s kubelet Pulling image "quytd/spark-py:v3.2.1" Normal Pulled 2m9s kubelet Successfully pulled image "quytd/spark-py:v3.2.1" in 2.358226966s Normal Created 2m9s kubelet Created container spark-kubernetes-driver Normal Started 2m9s kubelet Started container spark-kubernetes-driver
「Status:Succeeded」なのでpySparkジョブの実行が正常終了したようですね。Driver PodのLogを確認しましょう。
kubectl logs pod/spark-hdfs-io-driver ~~~一部抜粋〜〜〜 2021-07-03 10:28:48,824 INFO codegen.CodeGenerator: Code generated in 57.497623 ms +---+---+---+---+---+---+ |_c0|_c1|_c2|_c3|_c4|_c5| +---+---+---+---+---+---+ | 1| 2| 3| 4| 5| 6| +---+---+---+---+---+---+
KubernetesからもpySparkのスクリプトの実行結果は想定の通りで良さそうですね!
Delta Lakeの検証
最近、DataBricks社がDelta Lake 1.0を発表したので、この機会でDelta Lakeを対応する環境にしてDelta Tableだけ軽く確認したいと思います。Hadoopクラスターが構築された後にアイオワ州のお酒販売のデータセットを以下のDeltaテーブルフォーマットで作成されましたので、そのまま使いたいと思います。
[spark@katano-vps-deltalake-m01 ~]$ hdfs dfs -ls /apps/spark/warehouse/deltalake_db.db Found 2 items drwxr-xr-x - spark hadoop 0 2021-04-03 09:24 /apps/spark/warehouse/deltalake_db.db/iowa_liquor_sales drwxr-xr-x - spark hadoop 0 2021-04-03 10:43 /apps/spark/warehouse/deltalake_db.db/iowa_liquor_sales_large
環境設定
Delta Lakeを使うため、PySparkシェルにDelta Lakeのパッケージを読み込んで接続することは一般的ですが、今回はバッチモードでSparkOperatorからDelta Lakeのテーブルにクエリできるように設定したいと思います。そのため、Kubernetes上に動いているContainerに以下の2点が揃う必要がある
① Pythonのdelta-sparkに関係するPackageがインストールされる
②Sparkのjarsフォルダーにdeltalakeに関係するjarsファイルが存在する
①を対応するため、Python実行環境構築部分に「pip3 install delta-spark」を追加しましょう。
RUN mkdir ${SPARK_HOME}/python
RUN apt-get update && \
apt install -y python3 python3-pip && \
pip3 install --upgrade pip setuptools && \
pip3 install numpy && \
pip3 install delta-spark && \
# Removed the .cache to save space
rm -r /root/.cache && rm -rf /var/cache/apt/*
②のJarsファイルを用意するため、Dockerfileに以下のコマンドを追加します。
WORKDIR /opt/spark/jars
RUN wget https://repo1.maven.org/maven2/io/delta/delta-core_2.12/1.0.0/delta-core_2.12-1.0.0.jar && \
wget https://repo1.maven.org/maven2/org/antlr/antlr4/4.7/antlr4-4.7.jar && \
wget https://repo1.maven.org/maven2/org/antlr/antlr4-runtime/4.7/antlr4-runtime-4.7.jar && \
wget https://repo1.maven.org/maven2/org/antlr/antlr-runtime/3.5.2/antlr-runtime-3.5.2.jar && \
wget https://repo1.maven.org/maven2/org/antlr/ST4/4.0.8/ST4-4.0.8.jar && \
wget https://repo1.maven.org/maven2/org/abego/treelayout/org.abego.treelayout.core/1.0.3/org.abego.treelayout.core-1.0.3.jar && \
wget https://repo1.maven.org/maven2/org/glassfish/javax.json/1.0.4/javax.json-1.0.4.jar && \
wget https://repo1.maven.org/maven2/com/ibm/icu/icu4j/58.2/icu4j-58.2.jar
DockerFileを保存してSparkのImageビルドツールで再度ビルドし、Kubernetesの各ノードに使えるようにするためRegistryにPushしておきます。
pySparkスクリプトの準備
Delta Lakeを検証するためのpySparkスクリプトは以下の感じで、delta_lake.pyとしてPythonのHTTPサーバーで提供するようにしておきます。
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, expr
from delta.tables import DeltaTable
# Enable SQL commands and Update/Delete/Merge for the current spark session.
# we need to set the following configs
spark = SparkSession.builder \
.appName("quickstart") \
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") \
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog") \
.config("hive.metastore.warehouse.dir", "hdfs://192.168.1.1:8020/apps/spark/warehouse/deltalake_db.db") \
.enableHiveSupport() \
.getOrCreate()
# Read the table
print("############ Reading the table ###############")
df = spark.read.format("delta").load("/apps/spark/warehouse/deltalake_db.db/iowa_liquor_sales")
df.show(5)
spark.stop()
以下のようにSparkOperatorのYAMLファイルを準備します。
apiVersion: "sparkoperator.k8s.io/v1beta2"
kind: SparkApplication
metadata:
name: spark-delta-lake
namespace: default
spec:
type: Python
pythonVersion: "3"
mode: cluster
image: "quytd/spark-py:v3.2.1"
imagePullPolicy: Always
mainApplicationFile: "http://192.168.1.14:30001/delta_lake.py"
sparkVersion: "3.1.1"
restartPolicy:
type: Never
driver:
cores: 1
coreLimit: "1200m"
memory: "512m"
labels:
version: 3.1.1
serviceAccount: spark
executor:
cores: 1
instances: 2
memory: "512m"
labels:
version: 3.1.1
serviceAccount: spark
結果確認
Spark OperatorをApplyしてDelta Lakeスクリプトが実行が無事に終了したようです。
% kubectl apply -f spark-operator/pyspark-delta-lake.yaml
sparkapplication.sparkoperator.k8s.io/spark-delta-lake created
~ % kubectl describe pod/spark-delta-lake-driver
Name: spark-delta-lake-driver
Node: quytd-spark-s1/192.168.1.12
Labels: spark-app-selector=spark-8db654d45f3946c187348b9addc2f5fe
spark-role=driver
version=3.1.1
Status: Succeeded
Delta Tableからデータを取得できるか確認しましょう
% kubectl logs pod/spark-delta-lake-driver ~~一部抜粋~~ +-------------------+----------+------------+----------------+-------------------+------+--------+--------------------+-------------+------+--------+-------------+-------------+--------------------+-----------+--------------------+----+-------------+-----------------+-------------------+------------+------+------------------+-------------------+ |invoice_item_number| sale_date|store_number| store_name| address| city|zip_code| store_location|county_number|county|category|category_name|vendor_number| vendor_name|item_number| item_description|pack|bottle_volume|state_bottle_cost|state_bottle_retail|bottles_sold| sale|volume_sold_liters|volume_sold_gallons| +-------------------+----------+------------+----------------+-------------------+------+--------+--------------------+-------------+------+--------+-------------+-------------+--------------------+-----------+--------------------+----+-------------+-----------------+-------------------+------------+------+------------------+-------------------+ | S32988900055|2016-06-28| 3942|Twin Town Liquor|104 Highway 30 West|Toledo| 52342|104 Highway 30 We...| 86| Tama| 1062310| SPICED RUM| 395| Proximo| 46502| Kraken Black Mini| 4| 750| $10.75| $16.13| 1|$16.13| null| null| | S32988900001|2016-06-28| 3942|Twin Town Liquor|104 Highway 30 West|Toledo| 52342|104 Highway 30 We...| 86| Tama| 1062300| FLAVORED RUM| 260| Diageo Americas| 43314|Captain Morgan Gr...| 12| 750| $8.26| $12.39| 2|$24.78| null| null| | S32988900002|2016-06-28| 3942|Twin Town Liquor|104 Highway 30 West|Toledo| 52342|104 Highway 30 We...| 86| Tama| 1062300| FLAVORED RUM| 260| Diageo Americas| 43352|Captain Morgan Pi...| 12| 750| $8.26| $12.39| 1|$12.39| null| null| | S32988900003|2016-06-28| 3942|Twin Town Liquor|104 Highway 30 West|Toledo| 52342|104 Highway 30 We...| 86| Tama| 1062300| FLAVORED RUM| 65| Jim Beam Brands| 44350| Calico Jack Cherry| 12| 750| $6.30| $9.45| 2|$18.90| null| null| | S32988900004|2016-06-28| 3942|Twin Town Liquor|104 Highway 30 West|Toledo| 52342|104 Highway 30 We...| 86| Tama| 1062300| FLAVORED RUM| 370|Pernod Ricard USA...| 42676|Malibu Passion Fr...| 12| 750| $7.49| $11.24| 2|$22.48| null| null| +-------------------+----------+------------+----------------+-------------------+------+--------+--------------------+-------------+------+--------+-------------+-------------+--------------------+-----------+--------------------+----+-------------+-----------------+-------------------+------------+------+------------------+-------------------+ only showing top 5 rows
HDFSに存在しているDelta Tableからデータをちゃんと取得できるようになっています。よさそうです!
所感
いかがでしょうか?今回はKubernetesクラスターは別のHadoopクラスターと連携し、HDFSクラスターをK8sクラスターのStorage Layerにする内容について紹介しました。既存Hadoopクラスターにすでデータが蓄積しているがSparkクラスターだけもっと柔軟性を向上したい時にこの対応案は選択肢の1つではないでしょうか。自分が連携できた後Spark OperatorでpySparkジョブの実行やDelta Lakeの検証も実施することができましたのでこのクラスター構成でSpark on Kubernetesを引き続き検証して知見を広げていきたいと考えています。Kubernetesで柔軟性向上することを期待できまると思いますが、Kubernetes自体が概念が多くてうまく運用できるまで学習時間がかかってしまい、場合によってはKubernetesのことに時間が集中してしまう恐れがあると思いますので、技術選定のときにちゃんと検討した方が良さそうです。
最後に
次世代システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。
皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD