2024.04.08
AWS SagemakerでHuggingFace基盤LLMをデプロイする
こんにちは。S.Y.です。
プロダクトにLLMを組み込むことを検討する際、「APIを使う or 自前でデプロイする」はひとつ大きなテーマだと思います。
OpenAIやAnthropicなどのプロバイダーが提供するAPIは手軽さの反面、rate limit・コスト・カスタマイズ性の低さなどがボトルネックとなる場面は少なくないかなと思います。
チームで使うちょっとしたツール程度であればAPIを使うのが良いでしょうが、本格的にサービスに組み込むとなると、自前でデプロイしたLLM環境が欲しくなるのではないでしょうか!
もちろん一から環境構築するのは至難の業ですが、最近では各クラウドベンダーがエンドユーザー向けのLLM開発・デプロイ・追加学習を手軽に行えるサービスを提供していて、自前のLLM環境を用意する敷居は低くなってきていると感じます。
今回は個人的にAWS Sagemakerを触る機会があったので、SagemakerでLLMのデプロイがどのくらい簡単にいくのか検証してみました。ちなみにAWSは昨年からHuggingFaceと提携するなど、Sagemakerを通じてHuggingFaceのモデルを簡単にデプロイできるような仕組みを作っているようです。なので今回は特にHuggingFaceのモデルに焦点を当てています。
結論
- SagemakerでHuggingFace基盤LLMのデプロイを検証した。
- Sagemaker Jumpstartで、LLMのリアルタイムエンドポイントを数クリックでデプロイ。Python SDKからも、30行ほどのコードで各エンドポイントタイプにモデルをデプロイ。
- 非同期系の処理を行うにはエンドポイントやバッチ変換の選択肢もあるが、自由なスクリプトをGPUインスタンスで動かせるSagemaker ProcessingJobを使うのもアリ。
- Sagemakerでのモデルデプロイ
-
Sagemaker Jumpstartからリアルタイムエンドポイントをデプロイ
- Python SDKでデプロイ
- サーバーレス推論
- 非同期推論
- バッチ推論
- 非同期でやるならもっと楽にできないか
- Sagemaker ProcessingJob
- まとめ
Sagemakerでのモデルデプロイ
まずはLLM抜きにして、Sagemakerでの機械学習モデルの扱いや、デプロイについて軽く触れます。
Sagemakerでは4種類のinference typeがあります。
- リアルタイム推論
- 非同期推論
- サーバーレス推論
- バッチ推論
リアルタイム, サーバーレス, バッチはお馴染みですし、名前から大体のイメージがつきますね。非同期推論はサーバーレスとバッチの組み合わせのようなもので、比較的大きめのデータ(~1GB)についてオンデマンドに起動するリソース上で処理を行い、結果をS3に格納します。
Sagemakerでは、下記の二つをまとめてSagemaker Model (以下、単に”モデル”と呼びます。)という単位でパッケージングして管理します。
- 推論のためのコンテナイメージ
- モデルアーティファクト(重みパラメータや推論コード)
コンテナが起動するとモデルアーティファクトが内部にコピーされ、コンテナに流れてくるデータに対して予測を行います。
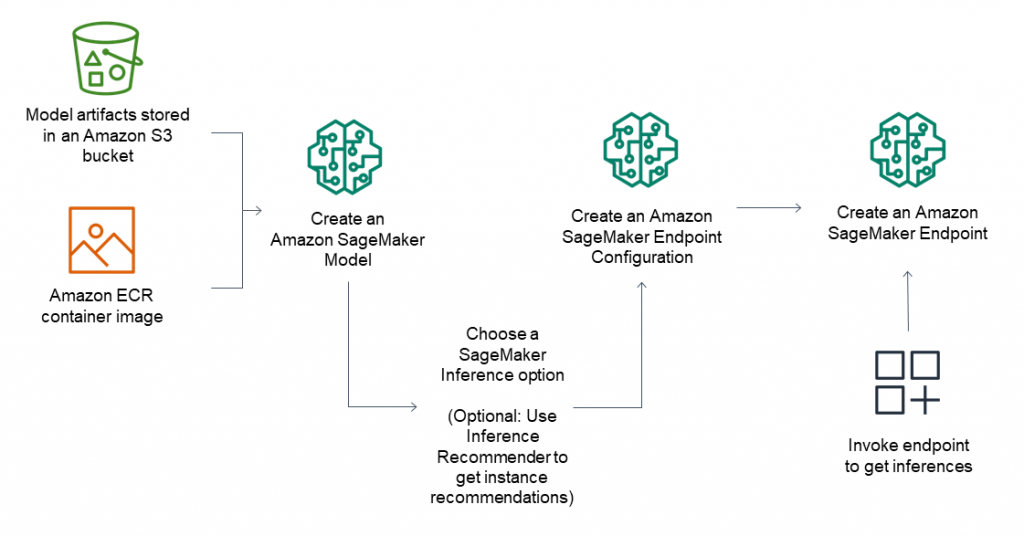
https://docs.aws.amazon.com/sagemaker/latest/dg/deploy-model.html より
コンテナイメージは、AWSが用意している各MLフレームワーク向けのものを使うか、カスタムコンテナを指定することもできます。カスタムコンテナを実装する際は、MMS (Multi Model Server)とSagemaker Inference Toolkitを使用することで、開発コストを抑えることもできます。
作成されたモデルは、リアルタイム, サーバーレス, 非同期推論のためにエンドポイントにデプロイしたり、バッチ変換ジョブに使用したりできます。
Sagemaker Jumpstartからリアルタイムエンドポイントをデプロイ
ではSagemakerでのLLMデプロイの話に戻ります。
Sagemakerを触ってみてまず印象的だったのが、JumpStartの存在です。
名前からしてノーコードですね。個人的にノーコード系はあまり期待を抱かないタイプの筆者ですが、果たしてこれはどうでしょうか。
JumpStartはその名のとおり、ジャンプするかのように(?)いきなりLLMのデプロイができます。具体的にいうと、数クリックでLLMが乗ったエンドポイントが立って、リクエストを受け付けている状態までできます。前章のモデルの仕組みとかコンテナがどうだとか、全く考えずにデプロイできました。
用意されているモデルはHuggingFaceのものがメインで、300種類以上あります!

使いたいモデルの詳細ページからDeployボタンを押して、インスタンスのタイプや数を指定するだけでDeployできます。今回はhuggingfaceのgemmaをデプロイします。インスタンスのタイプや数を指定して、リアルタイムエンドポイントにします。
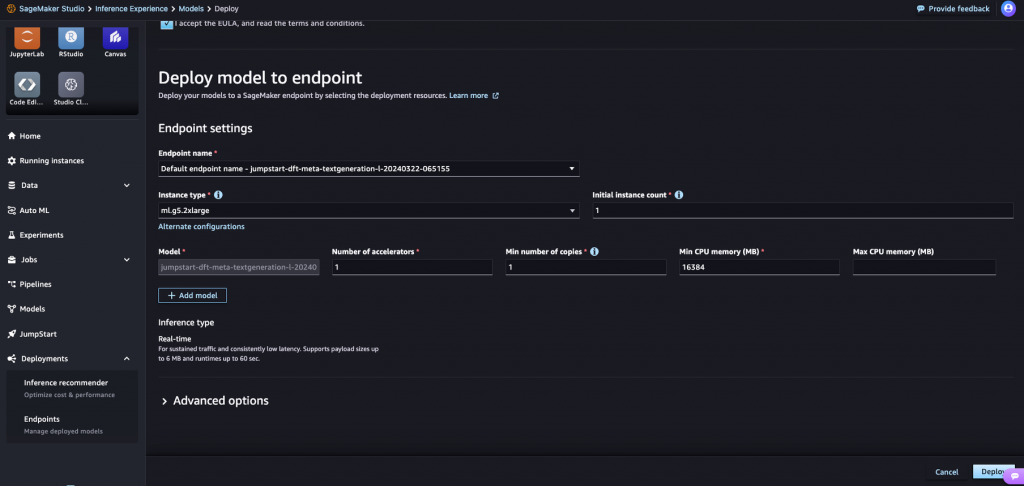
数分待つと、Endpointが作成されました。
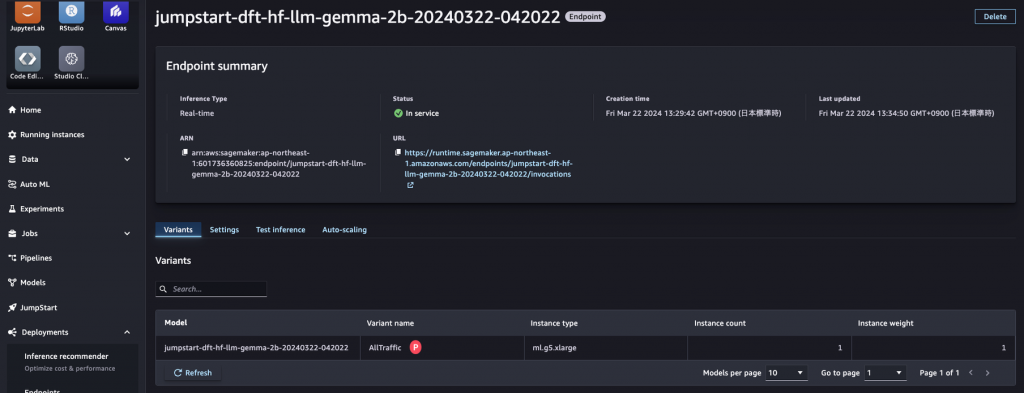
テストタブでリクエストの形式を確認できます。実際にリクエストを送ってレイテンシの確認もできます。
まさかの数クリックでデプロイできました!!これは楽ちんですね。
この調子でどんどんいきましょう。
サーバーレスにするには、作成時の設定でInitial Instance Countを0にすれば良いのでしょうか??

はい、0を指定すると怒られます。検証した限りだと、JumpStartからではリアルタイムエンドポイントだけ作成可能なようです。
やはり期待通り(?)、そうそう何もかもコンソールぽちぽちで上手くいくわけないですね。
しかし、常設のエンドポイントによるリアルタイム推論が求められるLLMサービスはchatbotくらいですし(そんなことはない)、現場ではコストや巨大データ処理などが絡んでくることが多々あるので、サーバーレス推論やバッチ推論が必要な機会の方が多いのではないでしょうか。(個人の意見)
これらのデプロイも簡単にやりたい!
ということでここからはJumpではなく、地に足を付けてPython SDKから基盤LLMのデプロイをやっていきましょう。
果たして、お手軽デプロイといくでしょうか??
Python SDKでデプロイ
結論から言うと、SDKでだいぶお手軽にできました!コードの行数でいうと、各エンドポイントタイプで2~30行程度でした。
HuggingFaceがSagemaker用のコンテナイメージとモデルアーティファクトを用意していて、それを元に前述の通りモデル作成 → エンドポイント作成ができます。(おそらく、Jumpstartでのエンドポイントデプロイも内部的には同じような流れになっている気がします)
この章では、HuggingFaceのintfloat/multilingual-e5-smallモデルを各エンドポイントタイプにデプロイしてみます。モデルの出力としては、入力文章に対する384次元のベクトル表現が取得できることを期待します。
Huggingfaceのモデルを使うには、Sagemakerが用意しているHuggingFaceModelクラスを使うのが一番シンプルです。使いたいモデルのIDやpython等のバージョンを指定してインスタンスを作れば、あとはメソッドでエンドポイントにdeployしたりバッチジョブを作成したりできます。
サーバーレス推論
まずはサーバーレス推論です。初回リクエスト時のリードタイムこそあるものの、リアルタイム推論に比べて大幅にコストを削減できるのがサーバーレスの魅力ですね。
deployメソッドにServerlessInferenceConfigを指定するとサーバーレスエンドポイントとしてデプロイされます。
import sagemaker
from sagemaker.serverless import ServerlessInferenceConfig
from sagemaker.huggingface.model import HuggingFaceModel
role = sagemaker.get_execution_role()
session = sagemaker.Session()
default_bucket = session.default_bucket()
serverless_config = ServerlessInferenceConfig(
memory_size_in_mb=3072,
max_concurrency=1
)
# Hub Model configuration. <https://huggingface.co/models>
hub = {
'HF_MODEL_ID':'intfloat/multilingual-e5-small', # model_id from hf.co/models
'HF_TASK':'feature-extraction', # NLP task you want to use for predictions
}
huggingface_model = HuggingFaceModel(
env=hub, # configuration for loading model from Hub
role=role, # iam role with permissions to create an Endpoint
py_version='py310',
transformers_version="4.37.0", # transformers version used
pytorch_version="2.1.0", # pytorch version used
)
huggingface_model.deploy(
endpoint_name=sagemaker.utils.name_from_base("intfloat-multilingual-e5-small"),
serverless_inference_config=serverless_config
)
数分するとエンドポイントが作成されました。タイプを確認するとちゃんとサーバーレスになっていますね。
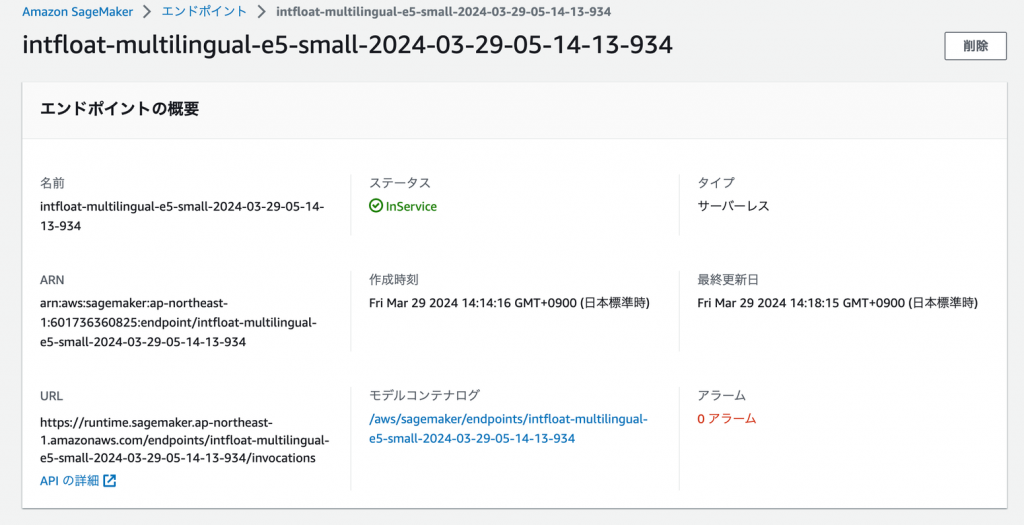
リクエストを投げてみます。今回はboto3のsagemaker_clientから投げます。(URLに直撃でhttpリクエストを投げたかったのですが、認証トークンが必要とかなんとかで直ぐには通らなかったので止めました。。)
import boto3
sm_runtime = boto3.client("sagemaker-runtime")
def req_to_endpoint(sm_runtime, req_body):
response = sm_runtime.invoke_endpoint(
EndpointName="intfloat-multilingual-e5-small-2024-03-29-05-14-13-934",
ContentType="application/json",
Accept="application/json",
Body=req_body
)
res = eval(response['Body'].read().decode('utf-8'))[0][0]
return res
req_body = bytes('{"inputs": "query: hello world!!"}', 'utf-8')
res = req_to_endpoint(sm_runtime, req_body)
print(len(res))
print(res[:10])
384次元のベクトルが取得できていることが確認できました。
384 [0.23527194559574127, 0.024941133335232735, -0.16354863345623016, -0.3448115289211273, 0.3437579572200775, -0.19365809857845306, 0.0384913831949234, 0.26228025555610657, 0.2501074969768524, 0.01969325914978981]
RAGのための分散表現計算など、オンデマンドでベクトルを計算したい場面ではE5モデル + serverlessエンドポイントが便利だと思います。
。。とは言ったものの、現状のサーバーレス推論はGPUが使えないのと、メモリが最大6GBまでしかスケールしないことがあり、いざLLMを本格的に運用するには力不足かもしれません。
非同期推論
お次は非同期エンドポイントです。
こちらもHuggingFaceModelインスタンスのdeployを実行します。AsyncInferenceConfigを指定すると非同期エンドポイントとしてデプロイされます。こちらはGPUインスタンスを指定できます。
async_inference_config = AsyncInferenceConfig(
output_path="s3://sagemaker-playground-360825601736/async_inference_output/",
)
hub = {
'HF_MODEL_ID':'intfloat/multilingual-e5-small', # model_id from hf.co/models
'HF_TASK':'feature-extraction', # NLP task you want to use for predictions
}
huggingface_model = HuggingFaceModel(
env=hub, # configuration for loading model from Hub
role=role, # iam role with permissions to create an Endpoint
py_version='py310',
transformers_version="4.37.0", # transformers version used
pytorch_version="2.1.0", # pytorch version used
)
predictor = huggingface_model.deploy(initial_instance_count=1,
instance_type = "ml.g4dn.xlarge",
async_inference_config=async_inference_config,
)
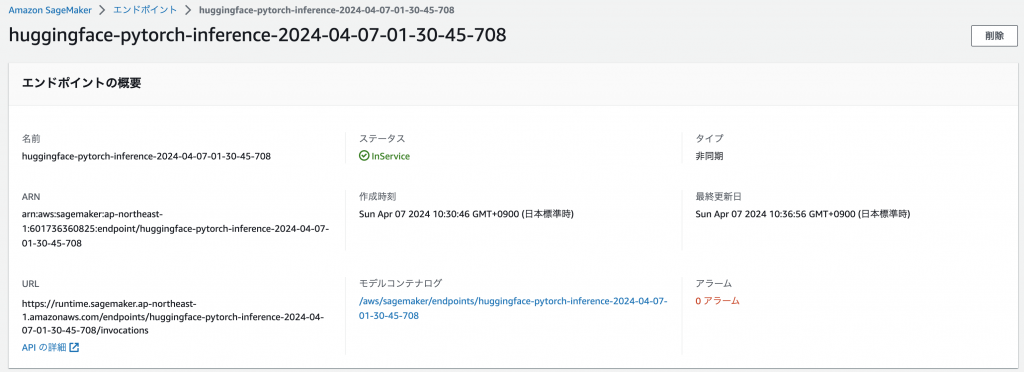
これで非同期エンドポイントができたので、リクエストを投げてみましょう。
まずはS3に予測させるファイルを配置します。今回はCSVでやってみます。
一つ注意点として、予測させたいカラムのカラム名は[“question”, “context”, “inputs”]のいずれかである必要があります。これはsagemaker-huggingface-inference-toolkitのお作法です。(sagemaker-huggingface-inference-toolkitは、HuggingFaceModelが使用するコンテナで動いているリクエストハンドラです。)
“Keyword”カラムに予測させたいデータを入れたCSVを配置して、下記のコマンドでエンドポイントにリクエストを投げます。
response = sagemaker_runtime.invoke_endpoint_async(
EndpointName='huggingface-pytorch-inference-2024-04-03-01-48-34-284',
ContentType='text/csv',
InputLocation='s3://sagemaker-playground-360825601736/async_inference_input/tmp_single_data_inputs_header.csv',
)
output_pathに指定したS3のディレクトリに.outという拡張子のoutファイルが生成されました。今までoutファイルのことは知らなかったのですが、普通にテキストファイルなんですね。
openして確認してみます。
with open("195f7b08-f0a4-4d56-8b40-ef2086674d89.out", "r") as f:
output = eval(f.read())
print(output)

どうやらリスト形式で返ってきているようです。ちゃんと384次元のベクトルになってはいるのですが、リストが4つくらい入れ子になっているのは謎です。
ちなみに、非同期推論の呼び出し元のシステムはどうやってジョブの完了や生成物の場所を把握するのかというと、非同期エンドポイントの作成時にオプションでAmazon SNSのトピックを登録できるので、これを通じて呼び出し元にメッセージを送ることになります。
バッチ予測
最後はバッチ予測です。
huggingface_modelを作るところまでは今までと同じです。
バッチ予測のジョブの投げ方はこんな感じです。こちらもGPUインスタンスを指定できます。
batch_job = huggingface_model.transformer(
instance_count=1,
# instance_type='ml.p3.2xlarge',
instance_type="ml.m4.2xlarge",
output_path="s3://sagemaker-playground-360825601736/batch_inference_output", # we are using the same s3 path to save the output with the input
strategy='MultiRecord')
batch_job.transform(
data='s3://sagemaker-playground-360825601736/async_inference_input/tmp_single_data_inputs_header.csv',
content_type='text/csv',
split_type='Line')
strategyやらsplit_typeやらが出てきましたね。これらはS3にあるcsv等の構造化された入力データを、どのような形でコンテナ内のモデルサーバーに送るかを指定しています。
strategyはSingleRecordとMultiRecordが選べて、モデルサーバーに送るhttpリクエストに含めるレコードを、単数にするか複数にするかを制御します。csvの場合は行がレコードになります。sagemaker-huggingface-inference-toolkitはMultiRecordを想定した作りになっているっぽいので、MultiRecordにしましょう。(text/csvのリクエストが来た際にheaderを確認する処理が実装されているのですが、SingleRecordだとそこでlist index out of rangeが出ました。)
split_typeはレコードの区切りです。csvの場合は行ごとの区切りになるので、Lineを指定します。
予測結果は、”inputファイル名.out”というこれまた.out形式で出力されます。
with open("tmp_single_data_inputs_header.csv.out", "r") as f:
output = eval(f.read())
print(output)
まぁ非同期推論の時と同じですね。入れ子になったリストにベクトルが入っています。
非同期でやるならもっと楽にできないか
ここまで、各エンドポイントタイプへのHuggingFaceモデルのデプロイを見てきました。
リアルタイムエンドポイントであれば、JumpStartで数クリックで作成できましたし、他のエンドポイントタイプもSDKでHuggingFaceModelのインスタンスを作成しconfigを添えてdeployメソッドを呼ぶだけという、わずか数行のコードでデプロイが可能でした。
一方で基盤LLMを使うというユースケースにおいては、非同期推論やバッチ推論には使いやすさや柔軟性といった観点で少し物足りなさを感じました。
非同期に推論するシチュエーションでは、推論結果に対し更に加工処理が入り、最終的な成果物が作られることが多いと思います。推論部分と前後処理はデプロイライフサイクル(更新のタイミング)が違う場合が多く、基本的にはこれらを分けた構成にしておいた方が、保守運用がしやすいです。
一方で、推論部分のデプロイライフサイクルが非常に長い(ほぼ更新がない。同じモデルを使い続けるなど)場合は、推論部分と前後処理を一つのコンポーネントとして纏めてしまった方がシンプルなこともあります。
今回のように基盤モデルを使うといったケースは、頻繁にモデル更新が入ることもなく、まさに推論部分を切り離さなくても良さそうなケースではないでしょうか!?
(それらしいことを書いてきましたが、「非同期な推論でhttpサーバーとか意識したくない!Google Colaboratoryなどでうまくいったコードを、なるべくそのまま動かしたい!」というのが本音です。)
さて、推論と前後処理を分離せずに、LLM推論を処理の一部に組み込んだような非同期処理(もちろんサーバーレスで)はどのように実現したらいいでしょうか?
AWS的考えて、まずLambdaが思い浮かびました。が、LambdaはGPUが使えません。それにタイムアウトが15分と、LLMでの非同期処理には非常に心許ない制約です。
どこかにGPUが使えてタイムアウトが長いLambdaみたいなやつはないものでしょうか。。
Sagemaker ProcessingJob
ありました。GPUが使えてタイムアウトが長いLambdaみたいなやつ、ありました。
その名も、Sagemaker ProcessingJobです。
これはデータ処理ジョブを発行するSagemakerのサービスで、マネージコンソールやSDKからJobを発行すると指定したインスタンスリソース上でコンテナが立ち上がり、スクリプトが完了したらリソースが消える、という流れです。
単体でジョブを発行することもできますが、Training/InferenceのPipelineに組み込んで、特徴量作成や学習データのTrain/Testスプリットなどに使用するのが主な使われ方だと思います。
このジョブで動かすスクリプトを「HuggingFaceのモデルをロード -> 推論 -> その他の処理」を一気にやるようなスクリプトにして、GPUインスタンス上で動かしてやろう、という魂胆です。
。。とここで、残念なお知らせです。
awsではservice quotaが結構細かく設定されていて、SagemakerはProcessingJobやエンドポイントで使用するインスタンスタイプについて、種類ごとにquotaがあります。そして、ProcessingJobで使用できるGPUインスタンス数について、各インスタンスタイプのquotaがデフォルトで軒並み0に設定されていました。アカウントレベルのquotaなので引き上げリクエストを上げられるのですが、検証には間に合わず。。
また、HuggingFaceProcessorというこれまたHuggingFaceが用意したProcessingJob用のクラスがあるのですが、これはGPUインスタンスでしか動かないような仕様になっているらしく。。
なので今回は、「ProcessorにはPytorchProcessorを使う。PytorchProcessorにはhuggingfaceライブラリが入ってないので、コンテナが立ち上がる際にpipインストールするようにする。これを普通のインスタンス上で動かす」という、当初の魂胆からはだいぶ離れたやり方をします。
まぁでもギリギリ、「GPUが使え(るはず)てタイムアウトが長いLambdaみたいなやつ」は体感できそうですね。
気を取り直してジョブを投げてみましょう。
↓動かすスクリプトはこんなかんじです。DataframeのKeywordカラムに対して、マップ関数でE5モデルによる予測を適用し、新しいカラムを作っています。あくまでいつもやっているデータ変換の一環としてLLMの処理が入っている感じがしますね。
これこれ、こういうのでいいんだよ。
from langchain.embeddings import HuggingFaceEmbeddings
import boto3
from urllib.parse import urlparse
import pandas as pd
if __name__ == "__main__":
input_data_path = "/opt/ml/processing/input/tmp_data.csv"
hf_embeddings_model_path = "intfloat/multilingual-e5-large"
model = HuggingFaceEmbeddings(
model_name=hf_embeddings_model_path,
)
df = pd.read_csv(input_data_path)
keyword_column_name = "Keyword"
df["emb"] = df[keyword_column_name].map(lambda x: model.embed_documents([x])[0])
output_path = "/opt/ml/processing/output/output.csv"
df.to_csv(output_path, index=None)
このスクリプトと必要なライブラリ(今回はhuggingface)を記載したrequirements.txtをprocessing_source_dirというディレクトリに置きます。このディレクトリはジョブの実行時にコンテナで展開され、requirements.txtがあればまず中身をpipインストールします。
ジョブを投げるコードはこちらです。
from sagemaker.pytorch.processing import PyTorchProcessor
pytorch_processor = PyTorchProcessor(
framework_version='2.2',
image_uri='763104351884.dkr.ecr.ap-northeast-1.amazonaws.com/pytorch-inference:2.2.0-cpu-py310-ubuntu20.04-sagemaker',
role=get_execution_role(),
instance_type='ml.m5.xlarge',
instance_count=1,
base_job_name='frameworkprocessor-PT'
)
pytorch_processor.run(
code='processing-script.py',
source_dir='processing_source_dir',
inputs=[
ProcessingInput(
input_name='data',
source='s3://sagemaker-playground-360825601736/async_inference_input/tmp_data.csv',
destination='/opt/ml/processing/input/'
)
],
outputs=[
ProcessingOutput(output_name='output', source='/opt/ml/processing/output/', destination='s3://sagemaker-playground-360825601736/processing_output/')
]
)
source_dirとその中のスクリプトファイルをそれぞれ指定します。
ProcessingInputのsourceは入力データのロケーション、destinationはコンテナ内のどこにコピーするかを指定します。スクリプト側ではdestinationからデータをロードするようにしておきます。
ProcessingOutputでは逆に、sourceでコンテナ内の成果物の場所、destinationでそれをS3のどこにコピーするか、を指定します。
上記コードを実行するとProcessingOutputnおdestinationにoutput.csvが出力されます。
まとめ
SagemakerでHuggingFace基盤モデルのデプロイを色々試しました。
Sagemakerでのコンテナベースなモデルデプロイの仕組みや、その上で動くsagemaker-huggingface-inference-toolkitのお作法で若干ハマることもありましたが、慣れている方にはどうってことないと思います。サービスの技術選定において、APIを使う場合との比較もサッとできると思います。
さいごに
グループ研究開発本部 AI研究開発室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務などAI研究開発室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。皆さんのご応募をお待ちしています。
参考文献
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD