2023.07.09
RetrievalQAとChatGPTで社内文書のQA ツール
こんにちは。次世代システム研究室のB.V.Mです。宜しくお願いします。
1. 結論ファースト
- LangChainで簡単にLLMを使用してインポートデータを元に回答できます。
- RetrievalQA: 関連するテキストチャンクを取得してから、OpenAIに質問を送ります。
- ほとんどのケースでは、回答は良好な結果を得ていますが、求める回答が長い場合には結果が不安定になることがあります。
目次
2.目標
現在、私たちはプロジェクトAPIの仕様に関するQ&AシステムをAIで作成したいと考えています。 ChatGPTは素晴らしいですが、プライベートデータや最新のデータは利用できません。
プライベートデータを読み込んでQ&Aシステムを作りたい場合、LangChainとRetrievalQAを使用することで問題が解決できるとのことで、検証してみました。
この記事では、LangChainとOpenAIのAPIを使用して、約10行のコードで.csvデータセットと通信する方法について説明します。そのため、インポートしたcsvファイルの内容を質問応答システムで簡単に検証できます。
システム構成は、一旦PythonのJupyter Notebookで構築しました。これにより、QA(Question – Answer)システムの結果が即座に確認できます。
2.1 LangChainとRetrievalQAについて
LangChainは、大規模言語モデル(LLM)を使用してアプリケーションの作成を簡素化することを目的としたフレームワークです。LangChainのユースケースは、ドキュメント分析と要約、チャットボット、コード分析など、一般的な言語モデルのユースケースと広範に重複します。Chat GPTでウィキペディアデータを利用したい場合、LangChainを使うことでChatGPT APIとウィキペディアデータセットの両方を利用できるようになります。そのため、Lang(言語)Chain(連鎖)と呼ばれています。
RetrievalQA(Retrieval Question Answering)は、自然言語処理(NLP)の一分野であり、質問応答(Question Answering)の一種です。RetrievalQAは、与えられた質問に対して、大規模なテキストデータセットから適切な回答を抽出することを目指します。もちろん他の方法もあります。
LangChain内でLLMを使用して質問応答を行うための下記のように4つの方法があります。
- Load_qa_chain: すべてのテキストを読み込み、複数のドキュメントを受け入れます。
- RetrievalQA: load_qa_chainを内部で使用し、関連するテキストチャンクを最初に取得します。
- VectorstoreIndexCreator: RetrievalQAと同じ機能を持ち、より高レベルのインターフェースを提供します。
- ConversationalRetrievalChain: チャットの履歴をモデルに渡す必要がある場合に便利です。
大まかには同じで、2番目のRetrievalQAが中心部分ですので、それを理解すれば十分です。
3. 今回開発して検証した内容
検証内容を簡単に説明させていただきます。
https://id.gmo.jp/ やhttps://point.gmo.jp/ などの公開情報からいくつか内容を
gmo.csvファイルに入れて、データを用意します。
RetrievalQAを利用して、用意したデータに関する質問してみます。
3.1 OpenAI API キー準備
まずOpenAI API キーを取得必要です。 発行するのに次のリンクを使用したら取得できます。
https://platform.openai.com/account/api-keys
3.2 Python ライブラリインストール
下記のようにコマンドラインで実行したらlangchain、openai、chromadb、tiktoken Python ライブラリをインストールできます。
!pip install -q langchain openai chromadb tiktoken
3.3 jupyter notebookで検証
下記のコードのようにjupyter notebookにてライブラリ、API キー、および .csv データセットを読み込みます。
ちなみに、現時点では、データセットが大きすぎると費用がかかり、また精度も低下する可能性があるため、行数をあまり多くしない方が良いです。おすすめの行数は2000行以下です。
from langchain.document_loaders import CSVLoader from langchain.indexes import VectorstoreIndexCreator from langchain.chains import RetrievalQA from langchain.llms import OpenAI import pandas as pd import os os.environ["OPENAI_API_KEY"] = "sk-xxxx"
“sk-xxxx”は3.1で取得したのキーを入れてください。
gmo.csvファイルのデータの中から1つの例を見て、その内容に関する質問をして検証したいと考えています。
| title: | GMOポイントの種類 |
| content: | GMOポイントには「通常ポイント」「期間限定ポイント」の2種類のポイントがあります。 |
CSVLoaderでデータをロードします。ちなみに、今回検証したのはcsvファイルですが、Document loadersにより色々なデータがロードできます。例えば:AWS S3 Directory, AWS S3 File, Discord, DuckDB, Email, Microsoft Excel, Git, Google Drive…です。
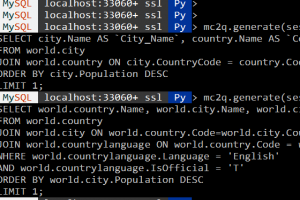
# Load the dataset loader = CSVLoader(file_path='gmo.csv') index_creator = VectorstoreIndexCreator() # vectorstore を構築する docsearch = index_creator.from_loaders([loader]) chain = RetrievalQA.from_chain_type(llm=OpenAI(), chain_type="stuff", retriever=docsearch.vectorstore.as_retriever(), input_key="question", return_source_documents=True) print(type(docsearch)) print(docsearch)
実行結果:
class 'langchain.indexes.vectorstore.VectorStoreIndexWrapper'; vectorstore=<langchain.vectorstores.chroma.Chroma object at 0x11dc03220>
結果によりdocsearchオブジェクトにデータがvectorstoreとして保存されました。
return_source_documents=Trueを設定によりどこドキュメントを参照したかわかるようになります。
3.3.1 タイトルに関連質問
上記のサンプルデータについてタイトルに関連する「ポイントの種類」についての質問してみました。
「ポイントの種類」と「ポイントの種類を詳しく説明してください」2つの質問を出しました。結果がかなり良いです。ポイントの種類のおおまかな情報が出られ、詳しく解説したいの質問の場合:ポイント期限情報も提供されました。

3.3.2日本語と英語の質問
ChatGPTはもちろん複数の言語に対応していますが、私自身が外国人であるため、英語の質問を検証してみたいと思います。日本語と英語の質問の両方を試してみましょう。
まず日本語の質問です。

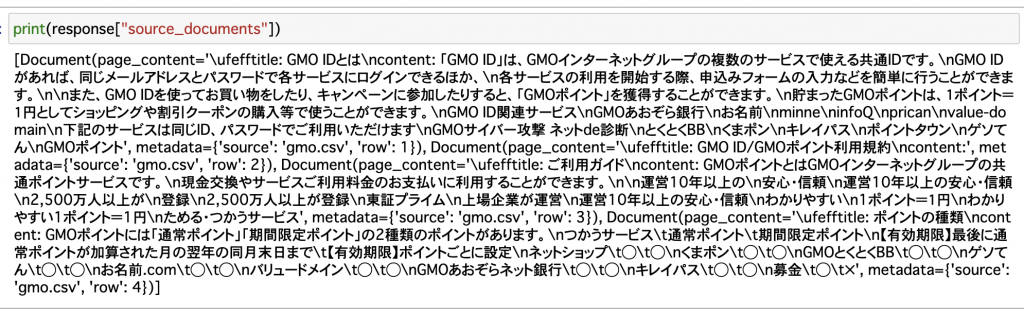
今回は英語の質問:

元の参照したソースの確認したら英語の質問と日本語の質問が同じところを参照しました。
3.3.3日付けに関係質問
2023年07月について

2023年06月と07月について

詳しく質問したら時点の詳細も提供できました。逆に、最初から全部データを回答できるはずが回答してくれませんでした。

3.3.4 内容の一部のデータについての質問
GMO ID関係サービスについて質問したら、元々のデータセットに”content”カラムの一部のデータだけです。でもちゃんと回答してくれました。

この内容により、ロードしたデータが全部格納されて、”question”と関連のデータが一部同じでもちゃんと抽出できました。
3.3.5 長い回答欲しい場合、結果が不安定
“GMO ID利用規約をください”という質問を出しました。参照データがちゃんと出来ていますが、回答が不安定です。
回答できたが、あまり良くない、詳細ではない結果:

回答が” I don’t know.”になってしまったケースもあります。
両方のケースですが、ちゃんと参照データが正しく参照していました。

感想
LangChainとRetrievalQAを利用して、わずか数行のコードでプライベートデータを読み込んでQA機能を検証できてすごいと思います。今後LLMの進化がもっと期待できるとお思います。OpenAIのキーを利用してお金がかかるため、今後LLaMaなどローカルのモデルも活躍だと思います。
参考リンク
- https://shabeelkandi.medium.com/chat-with-an-excel-dataset-with-openai-and-langchain-5520ce2ac5d3
- https://towardsdatascience.com/4-ways-of-question-answering-in-langchain-188c6707cc5a
- https://point.gmo.jp/
- https://id.gmo.jp/
- https://viblo.asia/p/langchain
- Llamaindex を用いた社内文書の ChatGPT QA ツールをチューニングする
最後に
次世代システム研究室では、グループ全体のインテグレーションを支援してくれるアーキテクトを募集しています。インフラ設計、構築経験者の方、次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ募集職種一覧からご応募をお願いします。 皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD