2020.07.06
GPUマシン上にDataiku 7を構築してFX予測してみた
こんにちは。次世代システム研究室のT.D.Qです。
最近、データを活用する目的で異なるスキルセットを持っている人々がコラボレーションして仕事の効率を向上するため、データ分析・機械学習プロジェクト向けのプラットフォームがあるか調査してみました。この問題を解決するため、Databricks, KNIME、RapidMinerやDataRobotなどがデータサイエンス・機械学習プラットフォームを提供しています。その中に、最近データサイエンス&機械学習プラットフォームのリーダーになったDataikuが面白いと思うので、今回の記事でDataikuを検証して紹介したいと思います。
DataikuのData Science Studio(DSS)
Dataikuは企業においてデータサイエンス、機械学習を誰もが使えるようにするための一元的データプラットフォームData Science Studio(DSS)を提供しています。データを活用する時に、共通のプラットフォームであるDSSでデータエンジニア、データサイエンティストだけではなく異なるスキルセットを備える人々が横断し、一緒にコラボレーションすることでデータの準備から大規模な分析、機械学習の導入、Pipelineの構築・管理を実現することが簡単になります。
DSSは複数プランを提供している中に、Community無料版があって、有料プランからビッグデータ処理機能(Hadoop、Sparkなど)が無くすことになっていますがGPUマシンで機械学習を行うと十分使えると思います。特に、3月18日にリリースされたDataiku 7は、機械学習プロジェクトの開発や、統計分析、ホワイトボックスAIが強化されましたので、今回は最新無料版のDSS 7.0.2で機械学習の開発環境を構築してFX予測してみたいと思います。
無料版で実現可能な機能はDataikuのホームページに掲載しているのでご参照ください。
環境構築
今回もGPUクラウド by GMOの1GPUプランのマシンで、Googleが提供するtensorflow/tensorflow:latest-gpuイメージをベースしてDataikuの環境構築手順を加えて機械学習のGPU開発環境を構築するためのDockerfileを作成しました。
Dataikuはオンプレ環境向けのDSSのDocker Imageを提供していますが、デフォルトGPUサポートしていないですので、GPU使いたいなら自分の環境と合わせて追加インストールする必要がありますので少し面倒です。以下のファイルは今回の検証で作成したDockerfileです。
FROM tensorflow/tensorflow:latest-gpu # インストール済みのパッケージをアップデート RUN apt-get -y update && apt-get install -y wget --no-install-recommends # sudoをインストール。dataikuユーザを作成するため。 RUN apt-get install -y sudo # DataikuのJAVA環境をインストール RUN apt-get update && \ apt-get install -y openjdk-8-jdk && \ apt-get install -y ant && \ apt-get clean && \ rm -rf /var/lib/apt/lists/* && \ rm -rf /var/cache/oracle-jdk8-installer; # Fix certificate issues, found as of # https://bugs.launchpad.net/ubuntu/+source/ca-certificates-java/+bug/983302 RUN apt-get update && \ apt-get install -y ca-certificates-java && \ apt-get clean && \ update-ca-certificates -f && \ rm -rf /var/lib/apt/lists/* && \ rm -rf /var/cache/oracle-jdk8-installer; # Setup JAVA_HOME, this is useful for docker commandline ENV JAVA_HOME /usr/lib/jvm/java-8-openjdk-amd64/ RUN export JAVA_HOME # dataikuユーザを追加 RUN useradd dataiku \ && mkdir -p /home/dataiku /home/dataiku/dss \ && chown -Rh dataiku:dataiku /home/dataiku /home/dataiku/dss \ && echo "dataiku:dataiku" |chpasswd \ && echo "dataiku ALL=(ALL) NOPASSWD:ALL" >> /etc/sudoers.d/dataiku \ && chmod 0440 /etc/sudoers.d/dataiku # Entry point WORKDIR /home/dataiku USER dataiku # Dataikuをダウンロード RUN wget https://cdn.downloads.dataiku.com/public/dss/7.0.2/dataiku-dss-7.0.2.tar.gz RUN tar xzf dataiku-dss-7.0.2.tar.gz # 依存関係をインストール RUN sudo apt-get -y update \ && sudo -i "/home/dataiku/dataiku-dss-7.0.2/scripts/install/install-deps.sh" -yes -without-java # Dataikuをインストール RUN DKUJAVABIN=/usr/bin/java dataiku-dss-7.0.2/installer.sh -d /home/dataiku/dss -p 10000 RUN sudo -i "/home/dataiku/dataiku-dss-7.0.2/scripts/install/install-boot.sh" "/home/dataiku/dss" dataiku # Dataikuを起動する RUN /home/dataiku/dss/bin/dss start
上記のDockerfileを使ってDocker Imageをビルドします。
sudo docker build -t dss_gpu . -q=false --no-cache=true
ビルドしたDocker Imageを確認しましょう。
~/research/quy$ sudo docker images | grep dss_gpu dss_gpu latest a19078fda67c 21 hours ago 6.47GB
Docker Containerを起動します。GPUを使いたいので、今回「–runtime nvidia」を付けました。
sudo docker run --runtime nvidia -p 10000:10000 -d dss_gpu:latest
実行環境の設定
DSSにログイン
無料版向けのユーザを登録して初期Adminアカウントが自動的に発行されたのでこのアカウントを使ってログインします。
深層学習(Tensorflow)の実行環境を作成
早速、機械学習の実行環境を作成します。今回は、tensorflow-gpu 1.15.3を使うことになっています。
FX予測
プロジェクト作成
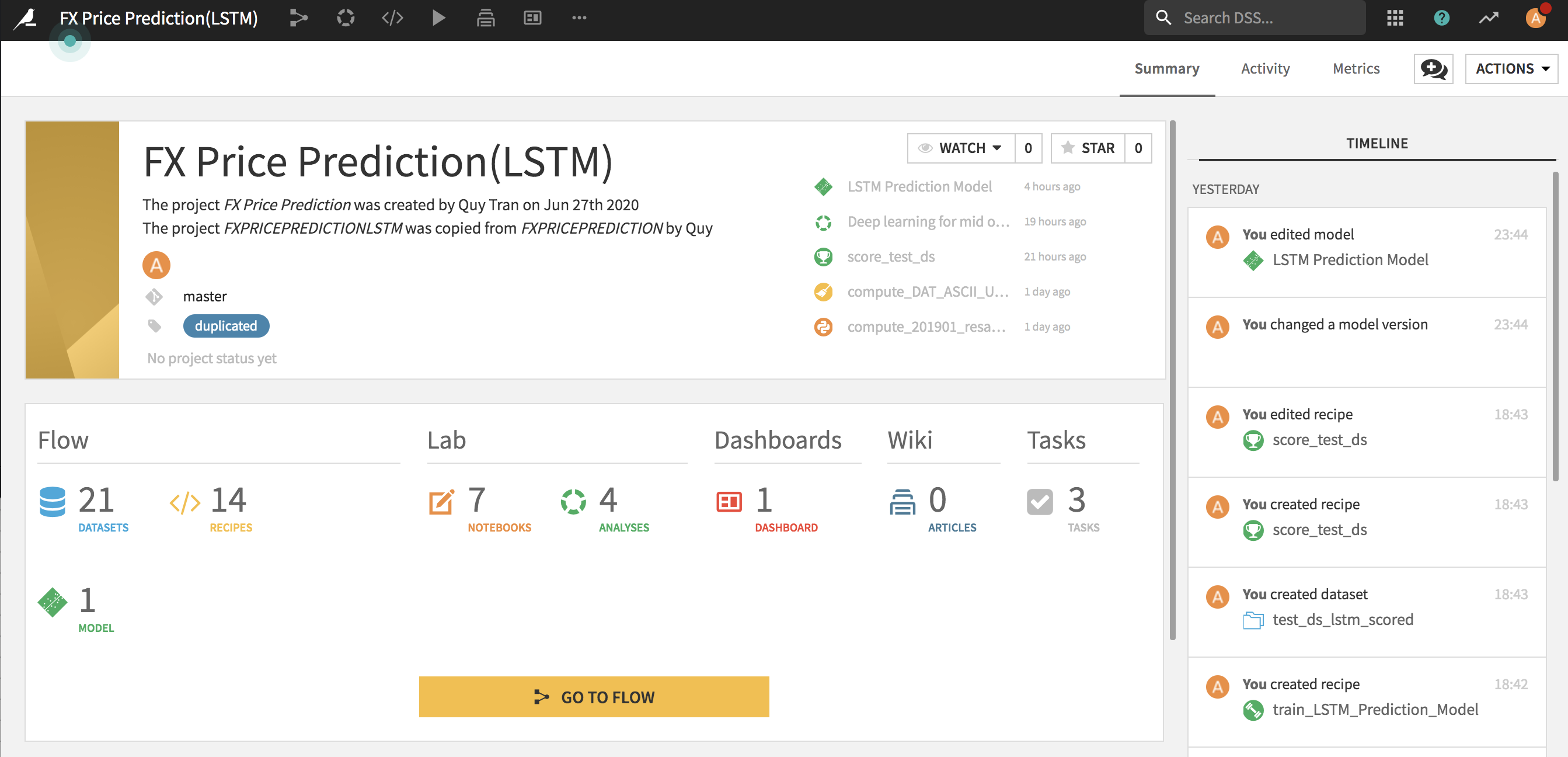
今回はFX予測するため、マイページから新しいプロジェクトを作成しました。突然ですが、以下のイメージは完成した状態ですが、プロジェクトページはこんな感じですね。
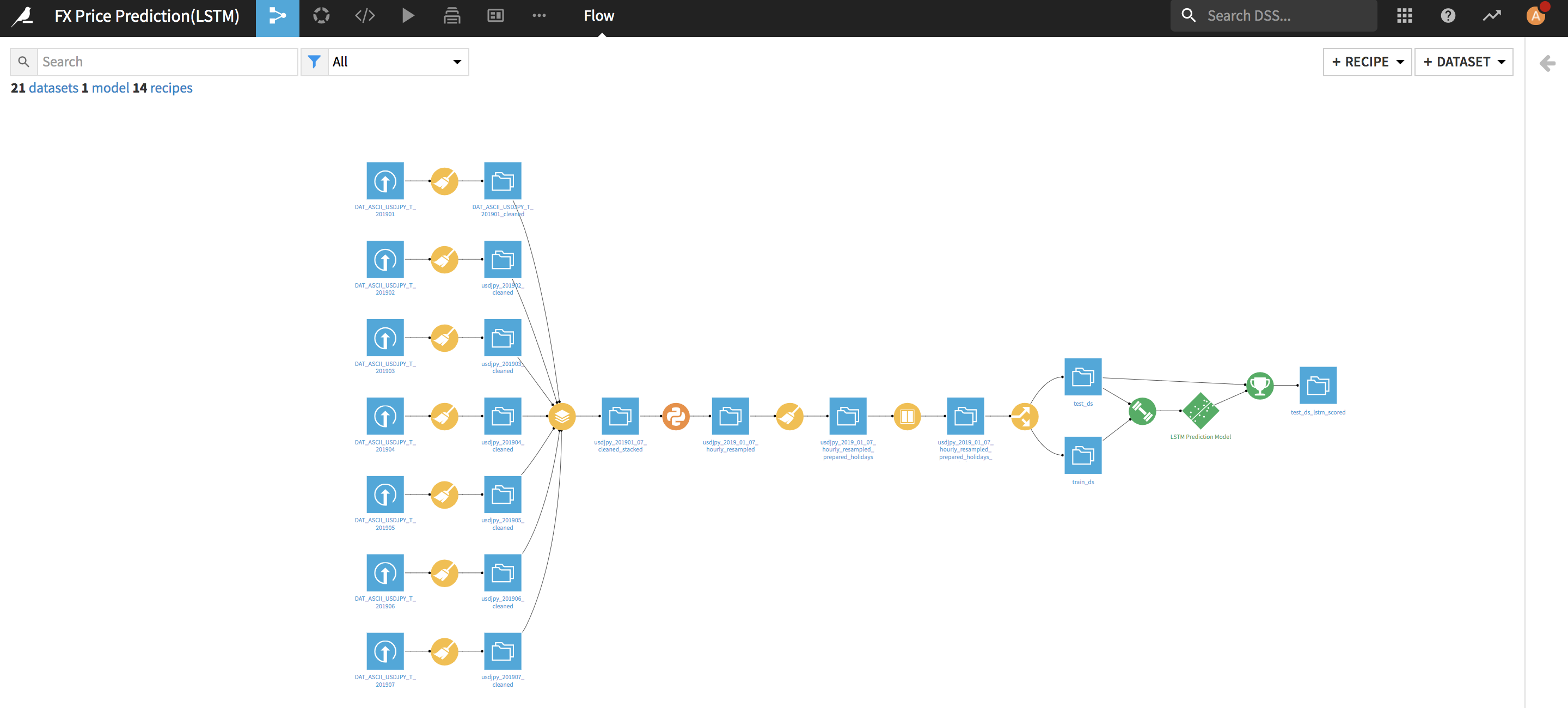
全体的な流れは下記のイメージです。
データインポート
今回の検証は histdata.comからドル円データをダウンロードして使いたいと思います。2019年1月〜2019年7月で7CSVファイルをダウンロードしてDSSにインポートしました。
データの前処理
ダウンロードしたドル円データをそのままDataikuにImportしたので、データの前処理を行わないといけないです。日付データ型変換や不要となるデータを削除し、2019年1月分〜2019年7月分のデータセットを統合するまでしました。この処理をDataikuが提供している機能(Recipe)を使って簡単に対応できました。
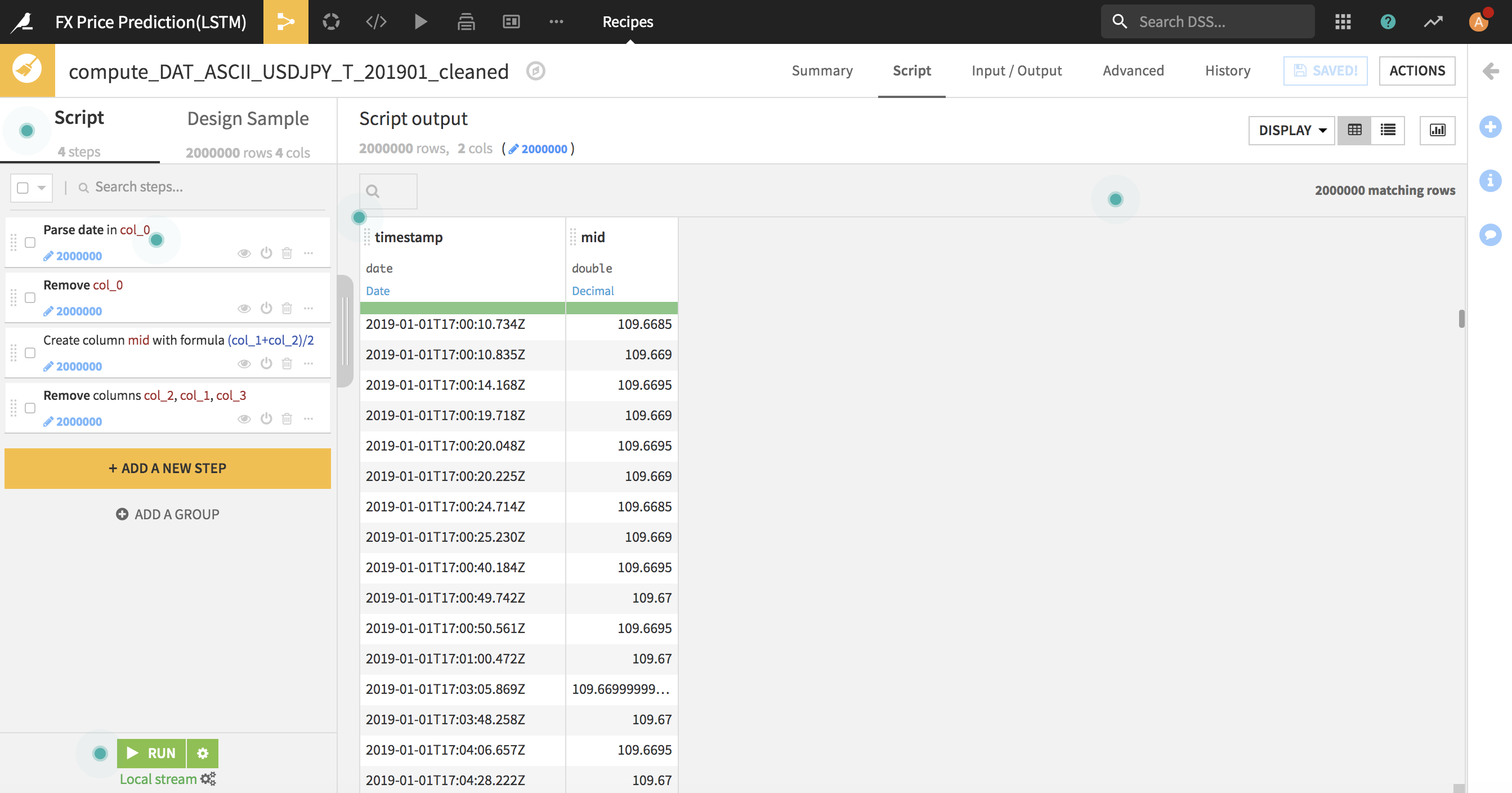
特徴量エンジニアリング
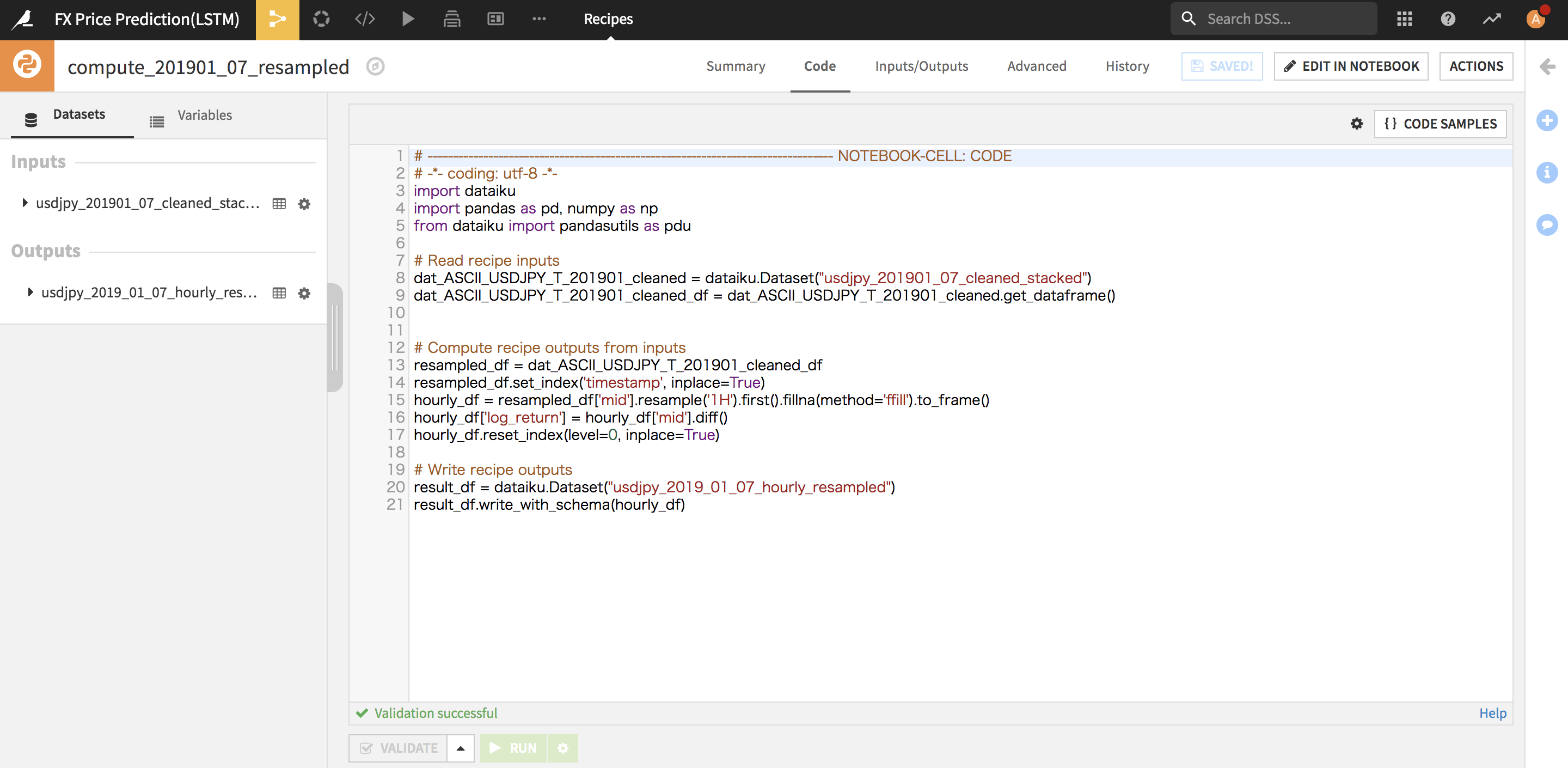
FXのMIDプライスを予測したいので、データセットにあるBIDとASKからMIDプライスを計算して、1時間足にResamplingを行いました。Resampling部分は下記の感じでPythonで実装しました。
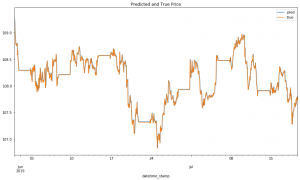
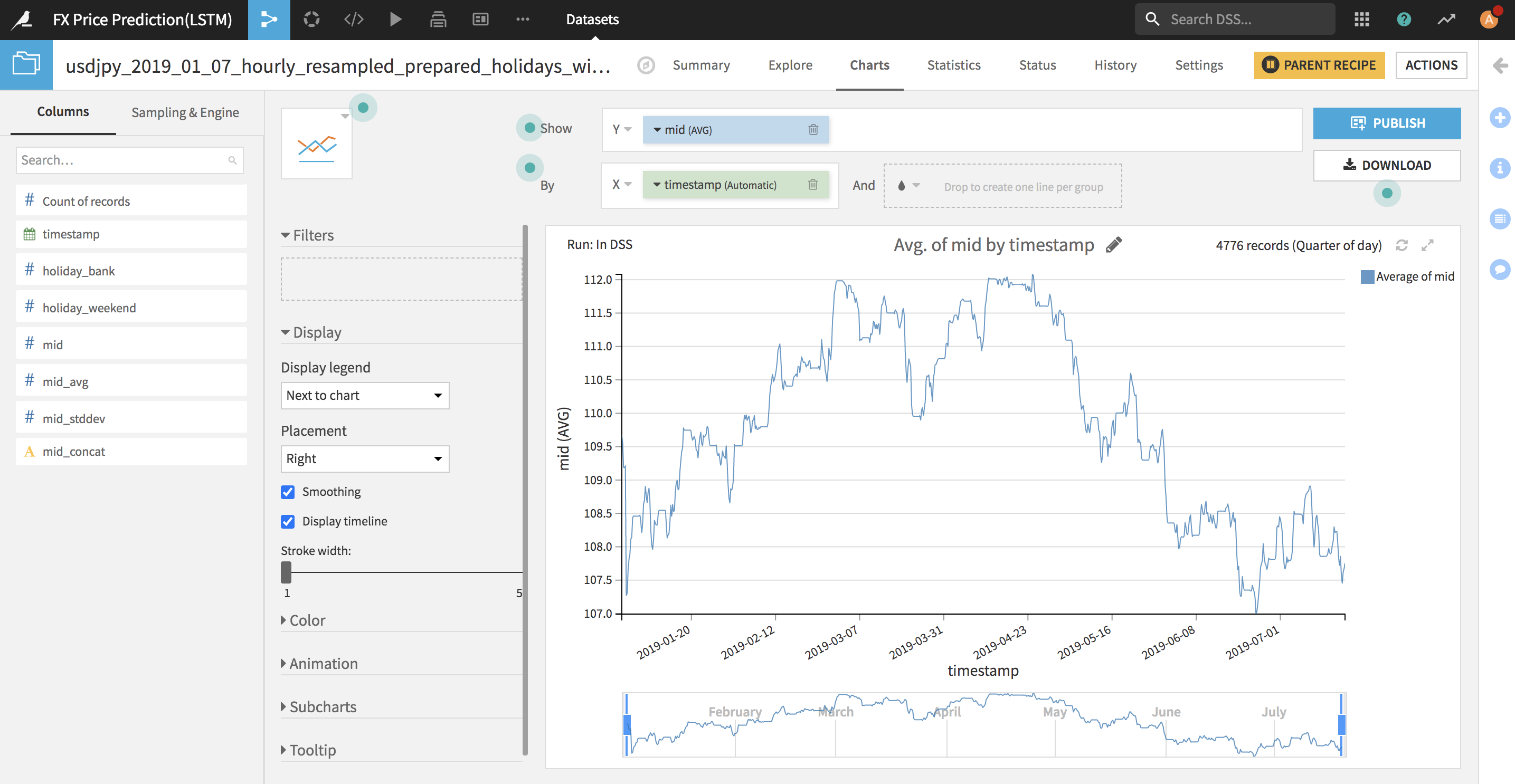
以下はReSampling後のMIDプライスグラフです。
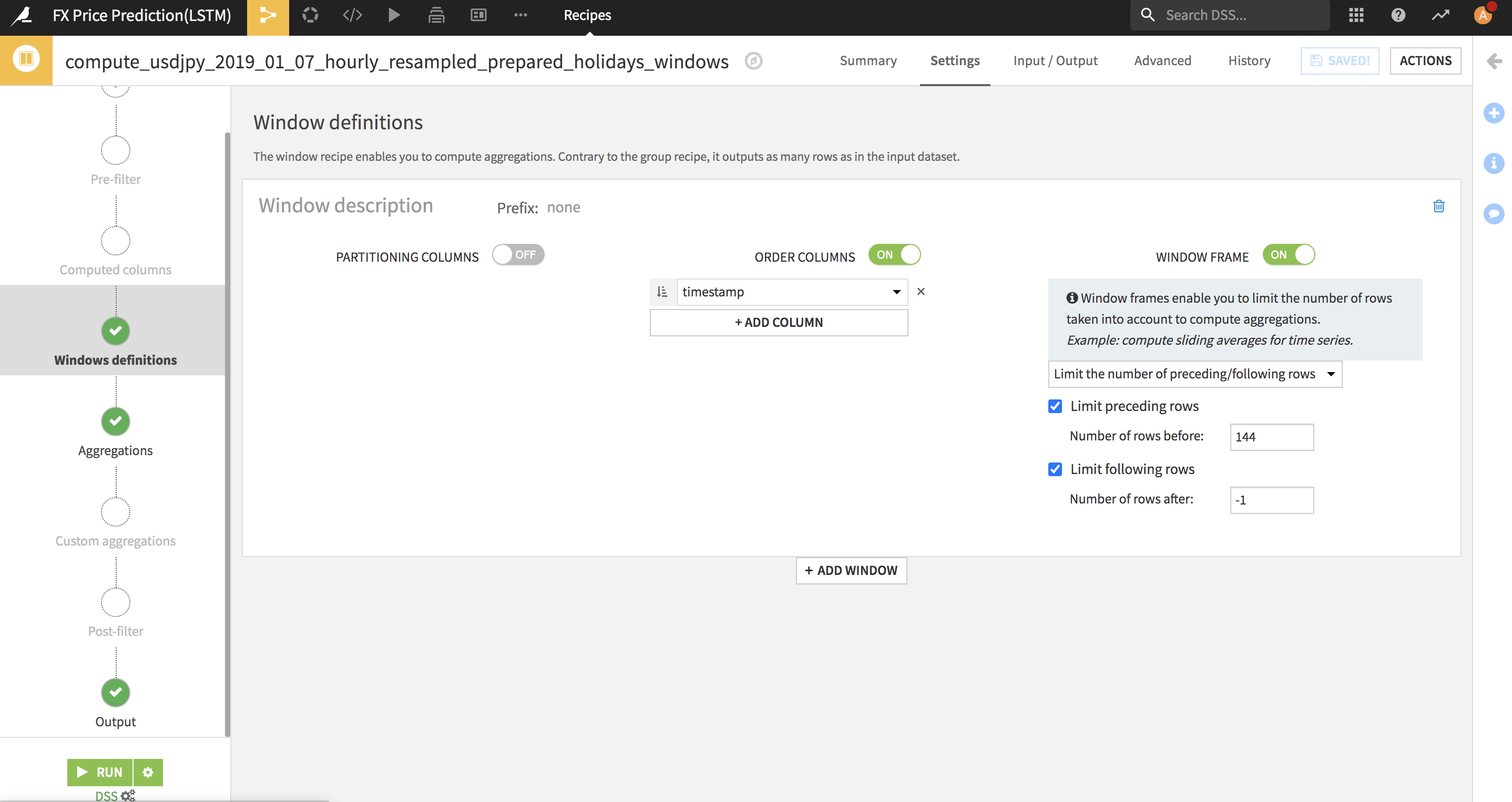
また、今回は144時間を学習して次の1時間のプライスを予測してみたいので、DataikuのWindow Recipeを使って実現しました。次は、DataikuのSplit Recipeを使ってTrain DatasetとTest Datasetを分割しました。
モデルの実装
ひとまずLSTMモデルでFX予測したいと思いますので、DSSのDesignページにてDeep Modelingの「Architecture」でLSTMモデルを実装してみました。
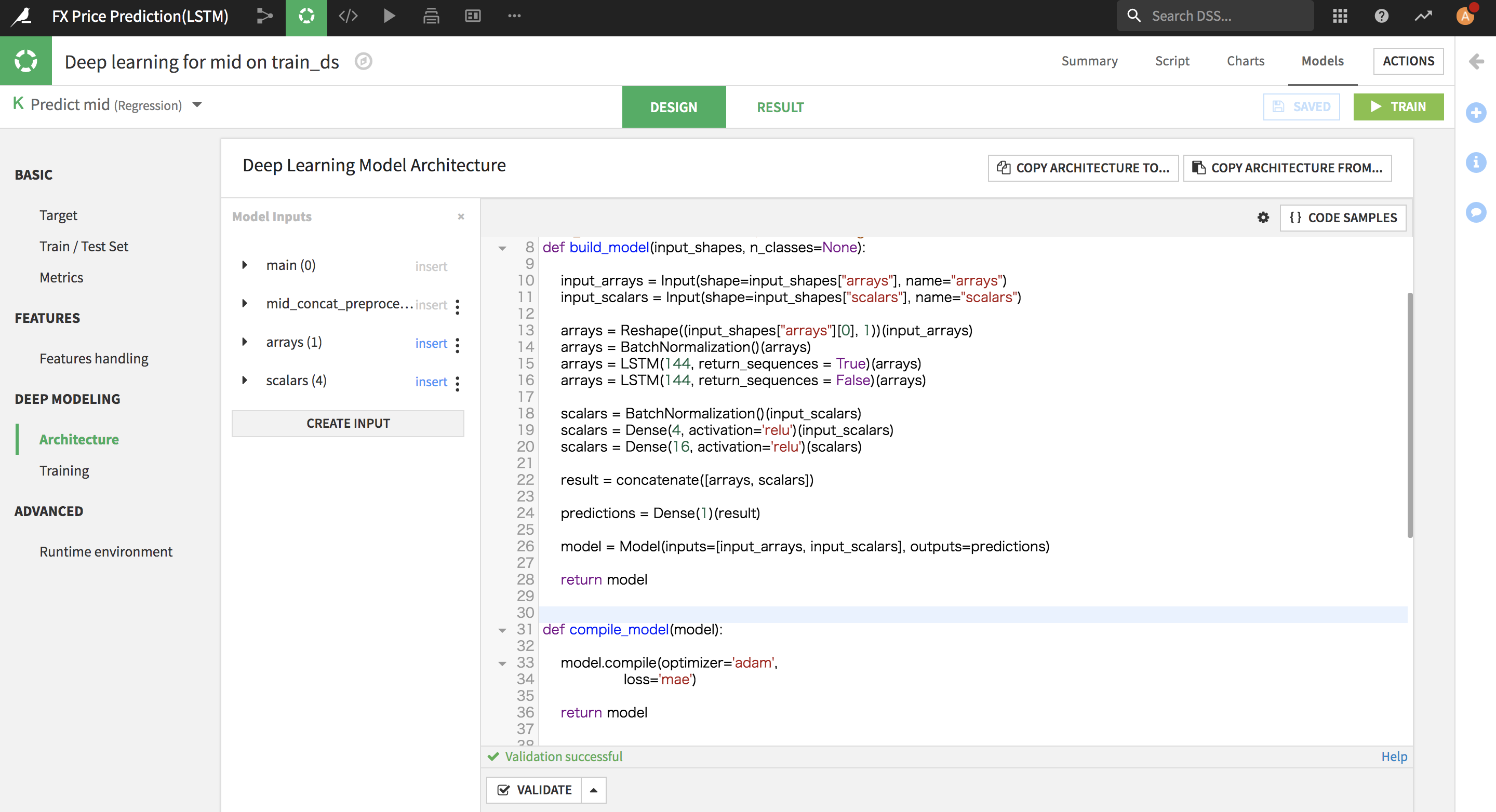
モデルトレーニング
早速モデルトレーニングを行います。Trainを実行する前にGPUをONすることができました。
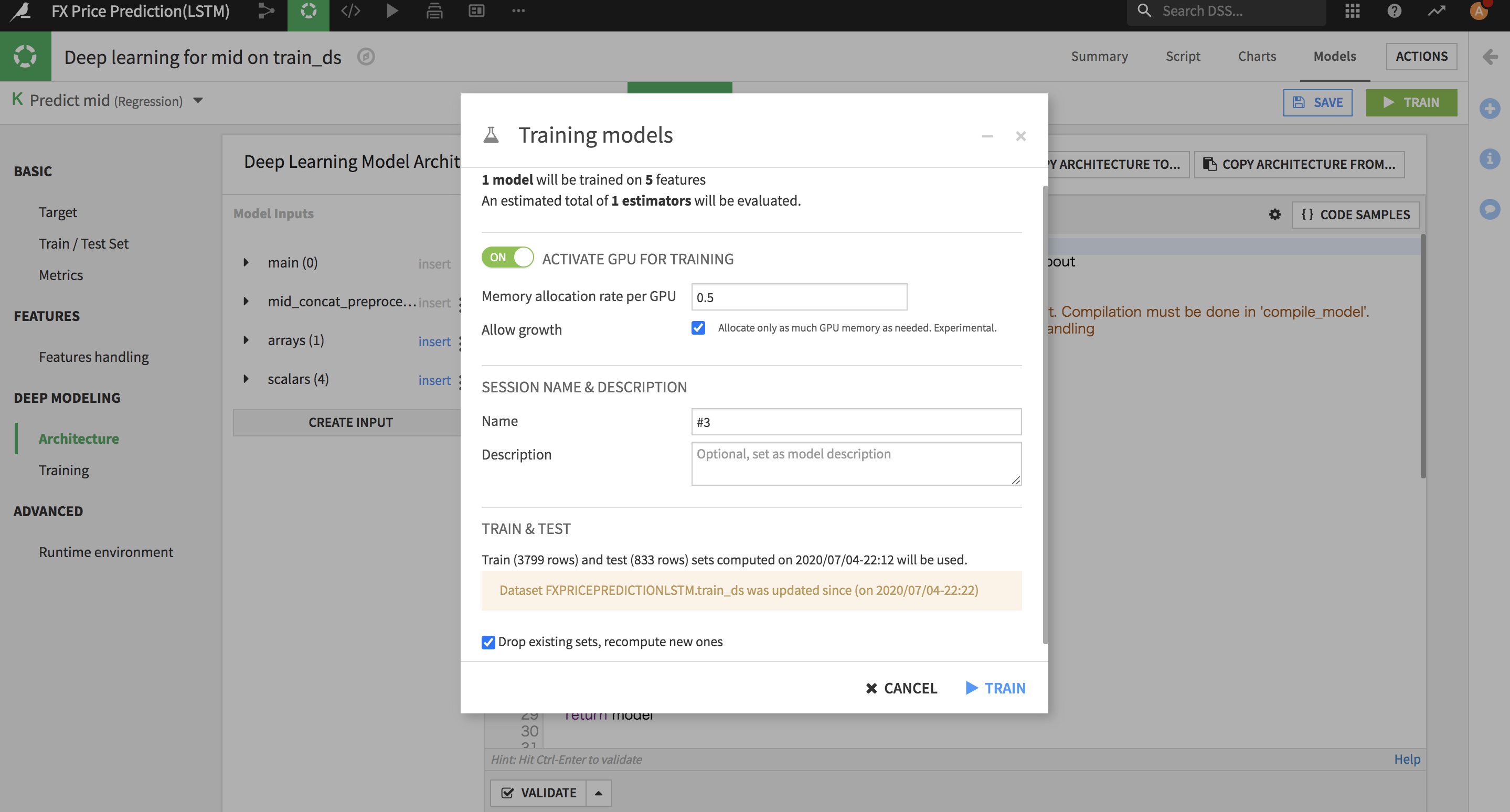
※Tensorflow2系はDSSのVisual Machine Learningをまだサポートしてないようですので、
DSSのGUIで「Train」機能を実行するときにエラーが出て実行できません。
GPUでTensorflow 2系を使いたいなら同梱するJupyter Notebookでモデルトレーニングは可能です。
トレーニング結果の確認
以下はトレーニング途中のイメージです。平均絶対誤差(MAE:Mean Absolute Error)指標で評価したいのでDataiku DSSのモデルデーザインページでこの指標を選択しました。見事、MAEがどんどん下がっていくので良い感じですね。
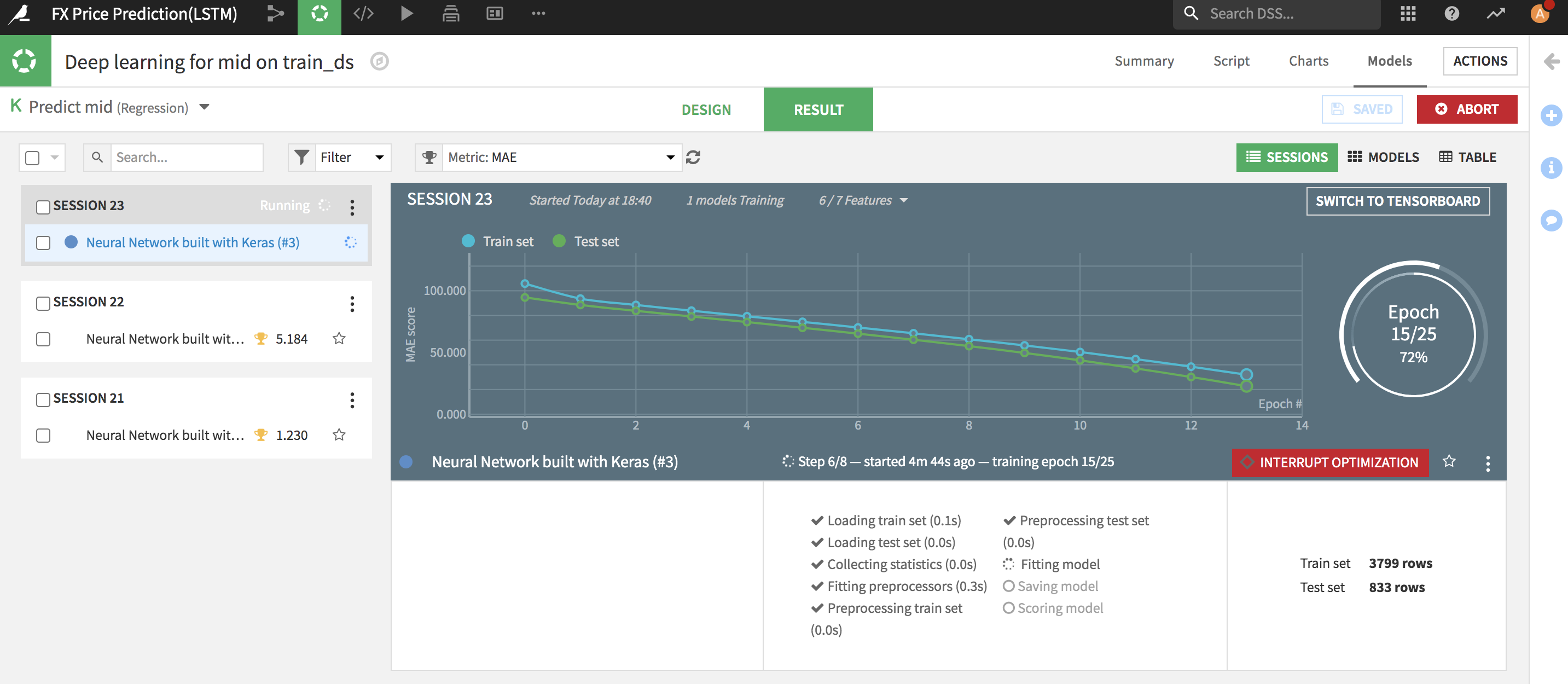
モデルトレーニング完了した時はこんな感じです。
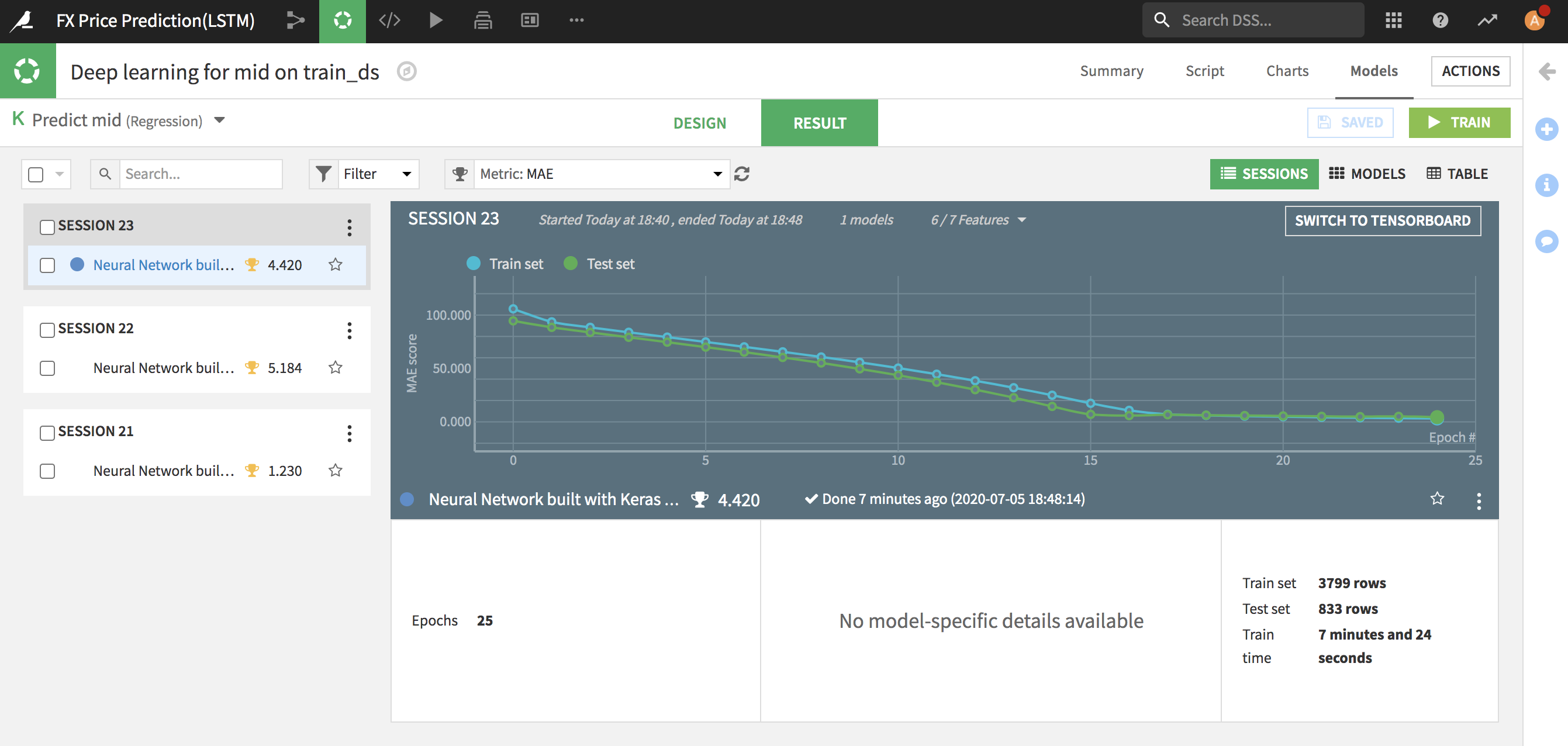
過去にトレーニングした情報も確認可能です
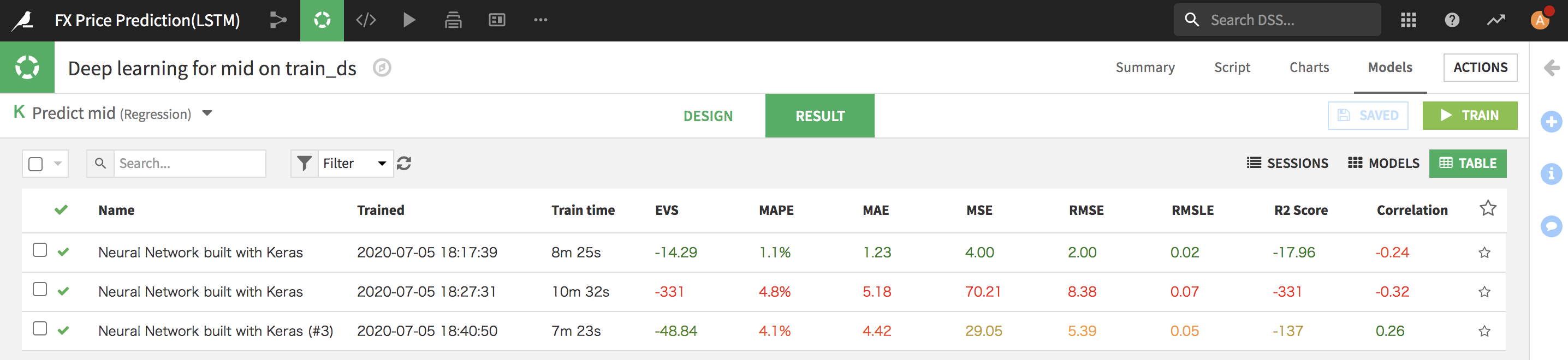
モデルを少し詳細まで確認
DSSでトレーニング後に特定のModelの詳細情報を確認できます。
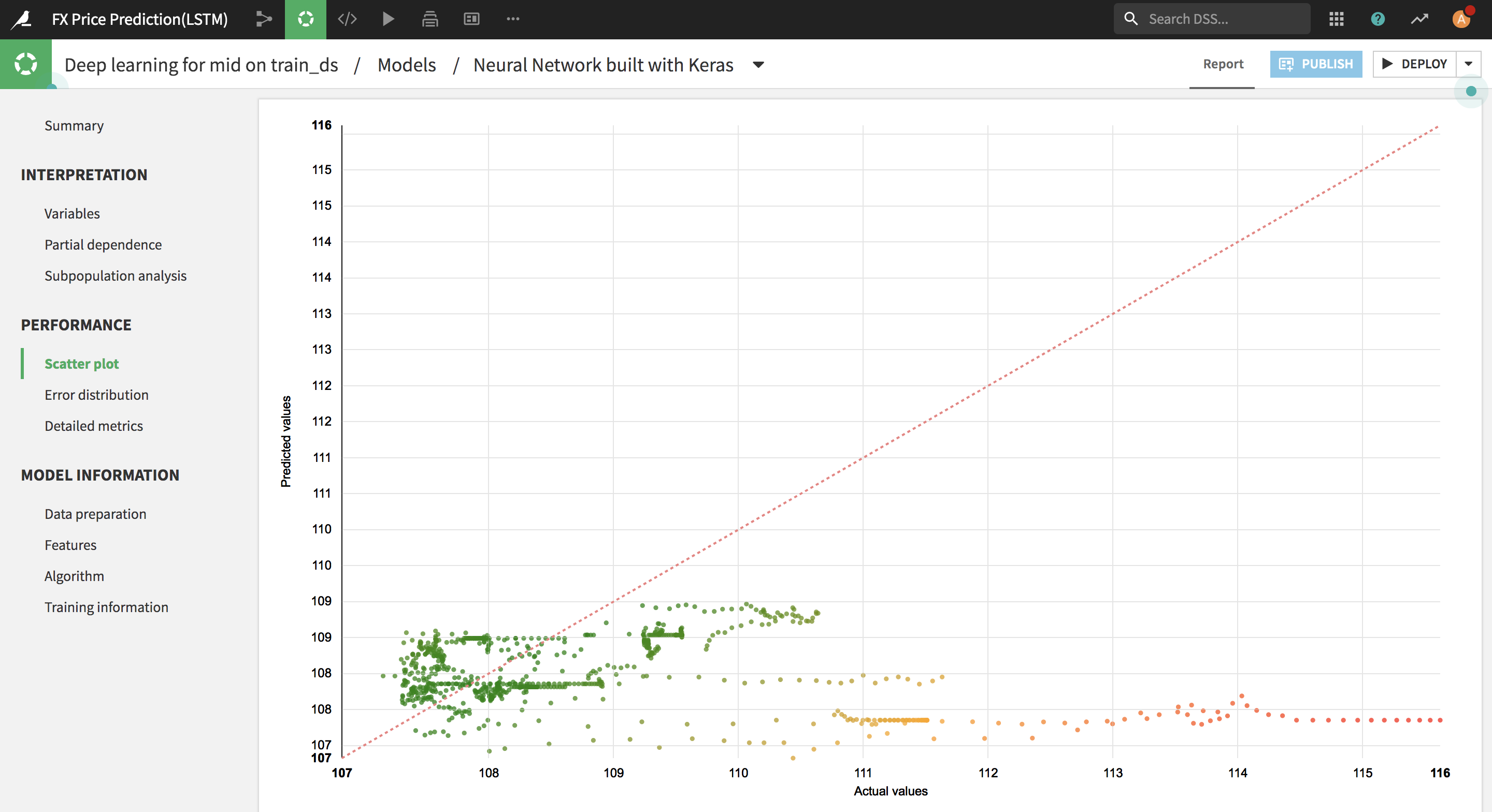
上のイメージは、Dataikuが自動的に生成してもらったMIDプライスの予測値(Predicted values)と実際値(Actual values)の比較ページです。結果はまだ今一でモデルをチューニングして改善する余地があると思いますが、Dataikuは予測結果を説明するため色々な機能を揃っているので嬉しいですね。
所感
今回はDataiku DSS 7.0.2無料版を使って深層学習の開発環境を構築してFX予測してみて下記の点について気に入っています。
1. 複数なデータソースからのデータ収集が簡単にできるが、サーバのHDDに中間データソース(Samplingしたデータ)を保存しているので場合によってはサーバのHDD容量も用意する必要がある。
2. DSSはデータ分析・機械学習プロジェクトは十分機能がほぼ揃っている。特にデータハンドリングのし易さ。データの前処理と加工は視覚的で機能が揃っています。Pythonで自分やりたいことも実現可能なので柔軟性が高いです。
3. DSSのGUIでDeep learningのサポートはまだ限定的(?)。同梱するGPUの実行環境にバージョンが古いので使えないので自分で設定しないといけないです。GUIでTrainするとTensorflow 2系、Kerasの最新バージョンなどを使うとエラーで落ちることになっているのでJupyterNotebookでTrainすることになります。今回はTensorflow1系で一旦大丈夫だそうですが次のリリースにこの問題解決を期待します。
4. 拡張機能(Plugins)が多いので便利です。時系列分析、AutoMLのH2Oもありますので色々なことが実現できそうですね。
5. 今回の記事は紹介しないですが、Dataikuでは一気に複数のモデルを実行可能ですので、同じデータでどんなモデルが良いか確認可能になります。そして説明可能なモデルも用意してもらっているのでデータ準備できたらモデルを選択して実行するだけなので非常に便利だと思います。もちろん、高精度を出すまではチューニングが必要だと思います。
今回はDataiku DSS 7.0.2というデータサイエンスプラットフォームを検証するため、Dockerで開発環境を構築してFX予測をやってみました。使ったのは無料版DSSですが、作業に必要な機能がほぼ揃っているので、このFX予測課題を実現しやすい環境だと思います。ただ、DSSは独自なコンセプトが結構あるので、最初に少し使いにくかったです。DSSを使いこなすため、Dataikuが提供しているチュートリアルを全部やってみて全体的な流れを把握していただくことをオススメです。
最後に
次世代システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。
皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD