2024.10.08
Google Cloud (GCP)Document AIを使ったデータ抽出の最適化
1. はじめに
こんにちは。次世代システム研究室のK.X.Dです。
現在関わっているプロジェクトでは、契約書の請求書を審査する機能を実装しています。
ユーザーが効率的に請求書の審査情報を入力できるよう、アップロードされた請求書の画像ファイル(jpeg, png など)やPDFファイルから自動的にテキストを抽出する必要があります。
現状では、プロジェクトの基盤としてGCPを使用しており、GCPのCloud Vision APIを活用して以下のように実装しています。
- Cloud Vision APIで請求書ファイルからテキストの全文を抽出
- プログラミング言語でRegexを使用して該当項目を抽出
ただし、ユーザーがアップロードする請求書の形式が多様なため、定期的に精度を調整し、Regexの抽出パターンを増やしていく必要があります。
しかし、抽出パターンが増えるほど、Regexのロジックが複雑になり、メンテナンスが困難になるという課題が生じています。
この問題を解決するために、GCPのDocument AIソリューションを調査しました。
結論ファースト
- ドキュメントファイルの処理性能は非常に高く、実際の運用にも導入可能です。
- フィールド定義が単に銀行口座を示す英字のみであっても、正確に銀行口座や銀行名義などのデータを抽出できます。
2. GCPのDocumentAIとは?
Document AIは、GCPが提供するOCRのAIサービスです。
非構造化データの書類から、名前、住所、電話番号、日付、金額などの任意の情報を抽出することができます。また、日本語のドキュメントにも対応しています。
3. 用途
Document AIが提供する主な機能
- デジタル化
- Vision AIのOCR機能とほぼ同様に、ドキュメントファイルからテキストを抽出することができます。
- 抽出
- Form Parser:ドキュメントに含まれるフォームをキーとバリューのペア形式で抽出することができます。
- Custom Extractor:トレーニング済みのモデルをベースに、自分のドキュメントに合わせた抽出機能(該当データのラベル付け)を定義することができます。
- 基盤モデル(Foundation Model)、ファインチューニングモデル:ドキュメントのレイアウトがバラバラの場合でも、GCPのトレーニング済みモデルを使用して対応することが可能です。
- モデルベース:ドキュメントのレイアウトがあまり変わらない場合は、すべての抽出レイアウトのトレーニングデータを投入し、抽出機能をカスタマイズすることができます。
- テンプレートベース:企業の給与明細のように、ドキュメントのレイアウトが固定されている場合は、特定の抽出テンプレートを使用して抽出機能をカスタマイズすることが可能です。
- Layout Parser:ドキュメントのレイアウト構造を抽出できます。
例:HTMLのpageHeader、pageFooter、paragraph、tableなど、それぞれのコンポーネントを定義して抽出します。
- 分類
- カスタムドキュメント分類器:給与明細、契約書、請求書などのドキュメントをカテゴリごとに分類することができます。
- カスタムドキュメントスプリッター:ドキュメントの境界を特定し、分割することができます。
- サマライザー
- ドキュメントの要約を生成することができます。
4. 解決できる課題
基盤モデル(Foundation Model)やファインチューニングモデルでは、ドキュメントのレイアウトがばらついている場合でも、GCPのトレーニング済みモデルを使用して対応することができます。
これらの機能を活用すれば、テキスト抽出後のポストプロセス処理が不要になります。
また、これまで課題となっていた複雑でメンテナンスが難しいRegex処理を排除することも可能です。
定期的にRegexのメンテナンスを行う代わりに、ファインチューニングモデルに対してうまく抽出できなかった請求書を学習させるだけで済むようになります。
5. 料金
Vision API (2024-07-10時点)
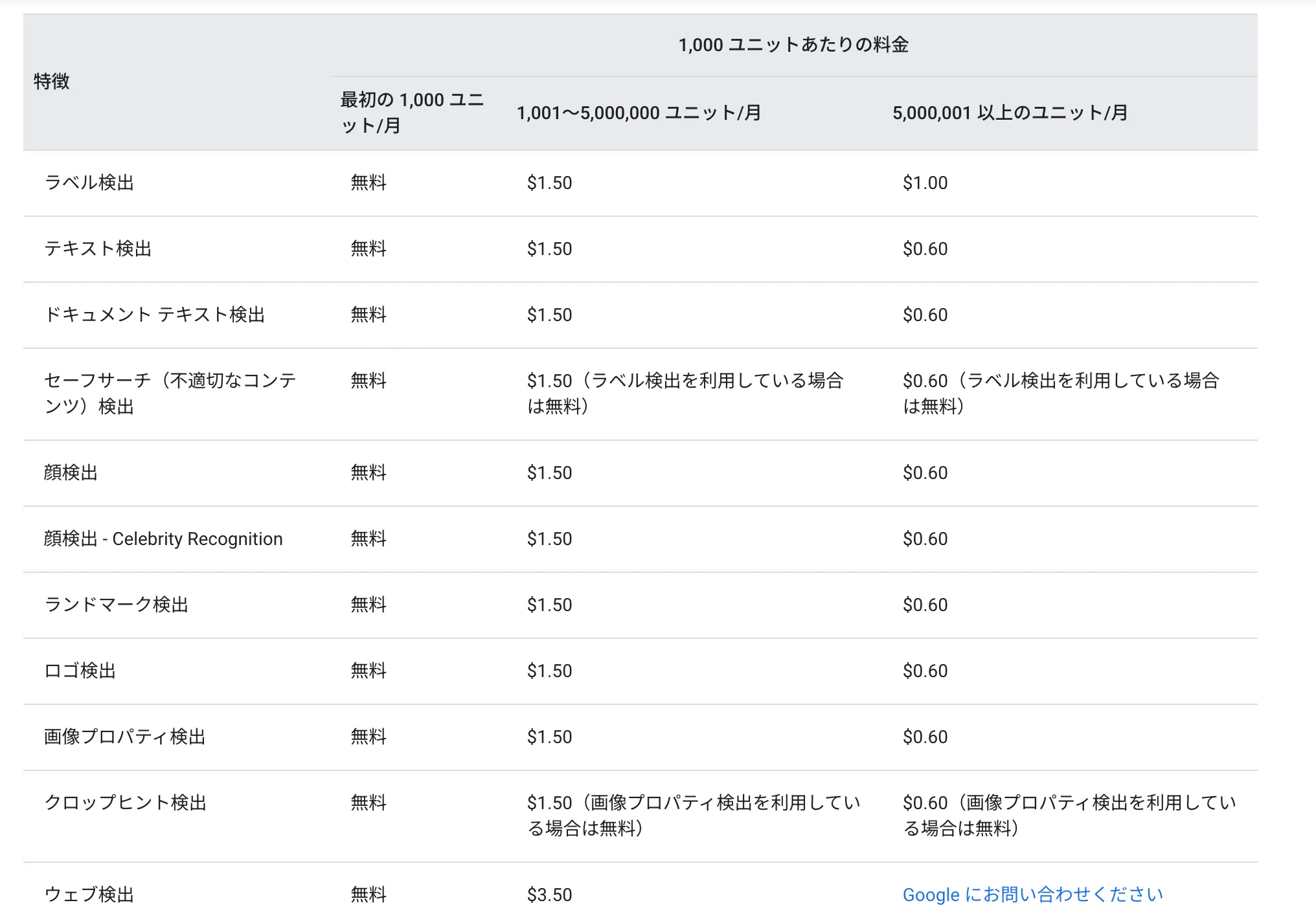
Document AIの抽出機能料金 (2024-07-10時点)
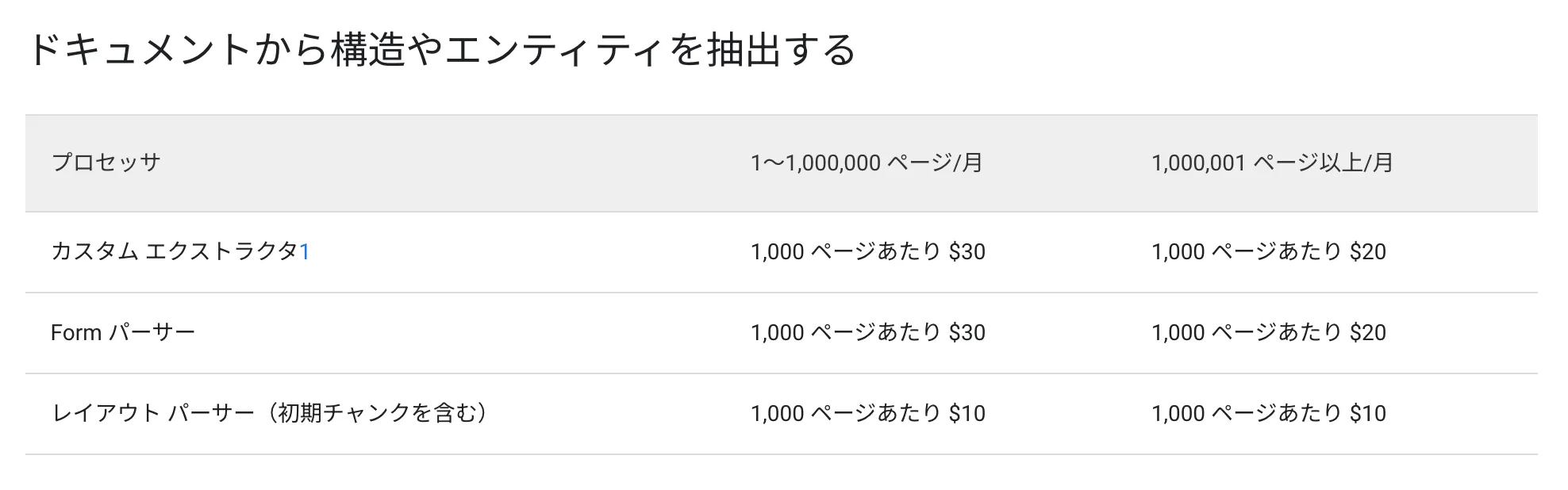
Vision APIより料金が高くなることが予想されますが、実際の運用に支障をきたすほどの料金ではありません。
料金を考慮する場合、ユーザーのリクエストを制限する案も検討できます。
6.日本語の請求書に対するテキスト抽出機能の実験
実験内容
この実験では、Document AI の基盤モデルとファインチューニングを使って、請求書から振込先フィールドを取得します。その取得結果を比較します。
ファインチューニングにて、10件程度の異なるドキュメントで追加学習を行うことで、さまざまな形式に対応した自動認識精度を向上させることができます。
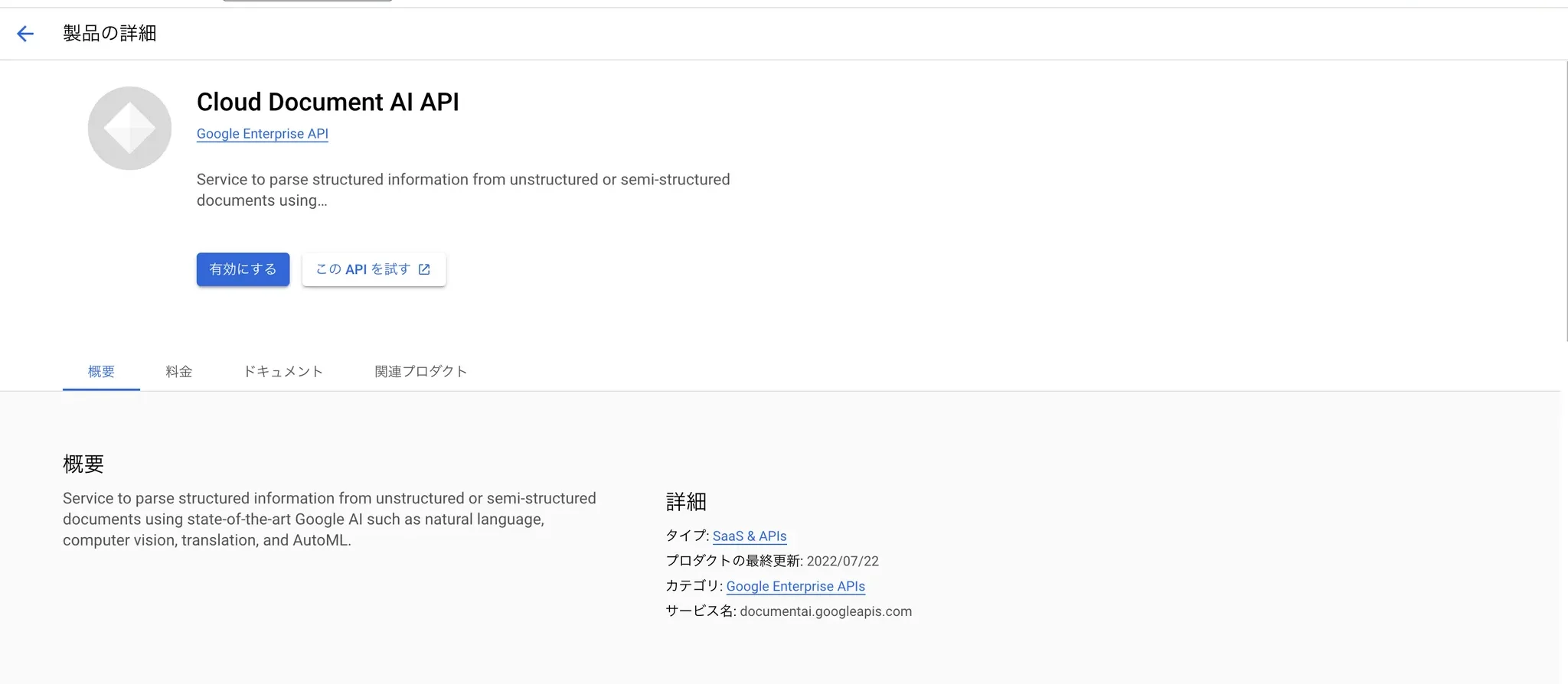
6.1 Cloud Document AIのAPIを有効にする
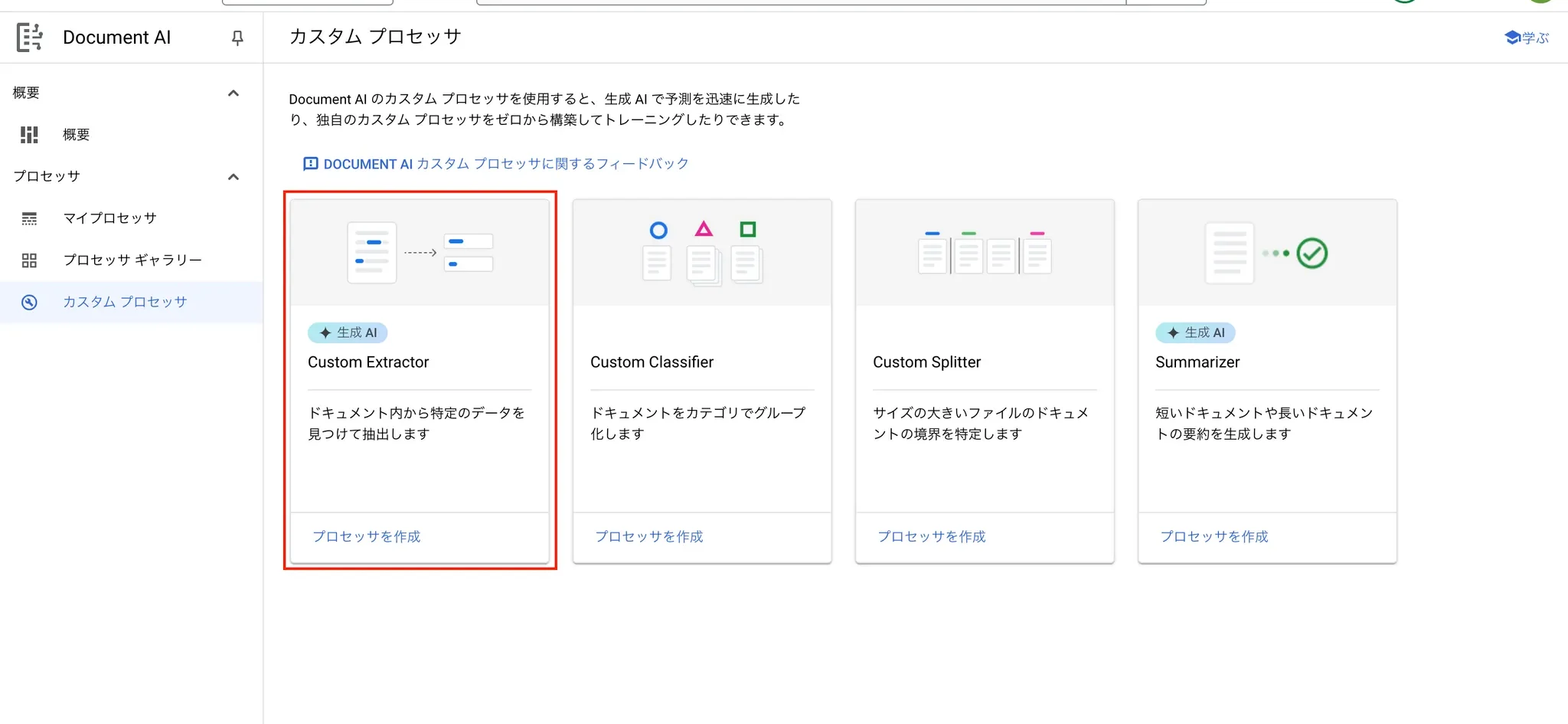
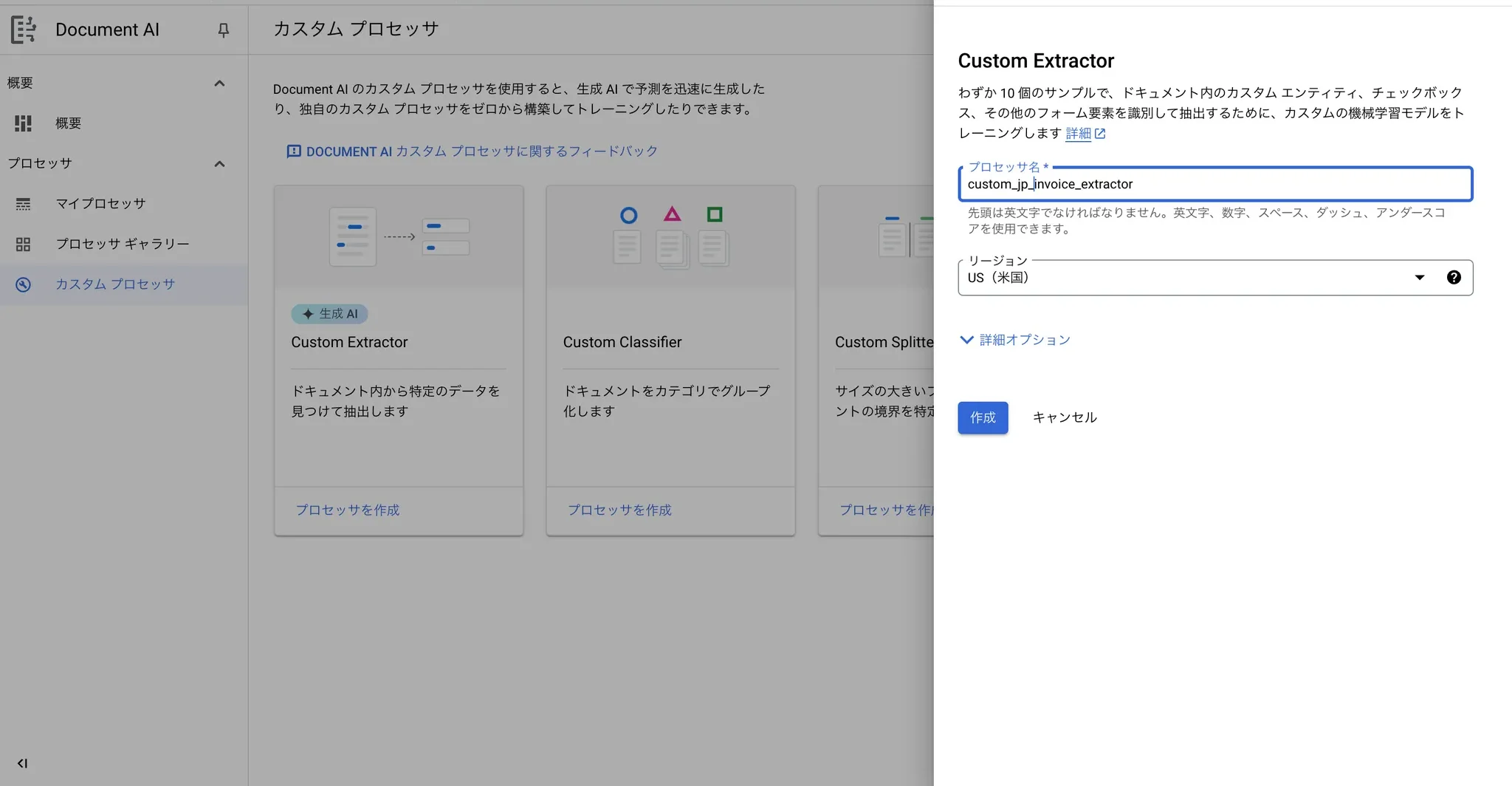
6.2 Custom Extractorでプロセッサを作成する
リージョン:データストレージと処理を行うロケーションを意味します。
6.3 プロセッサが抽出するカスタムフィールドを定義する
今回に請求書にある振込先の銀行情報フィールドを作りました。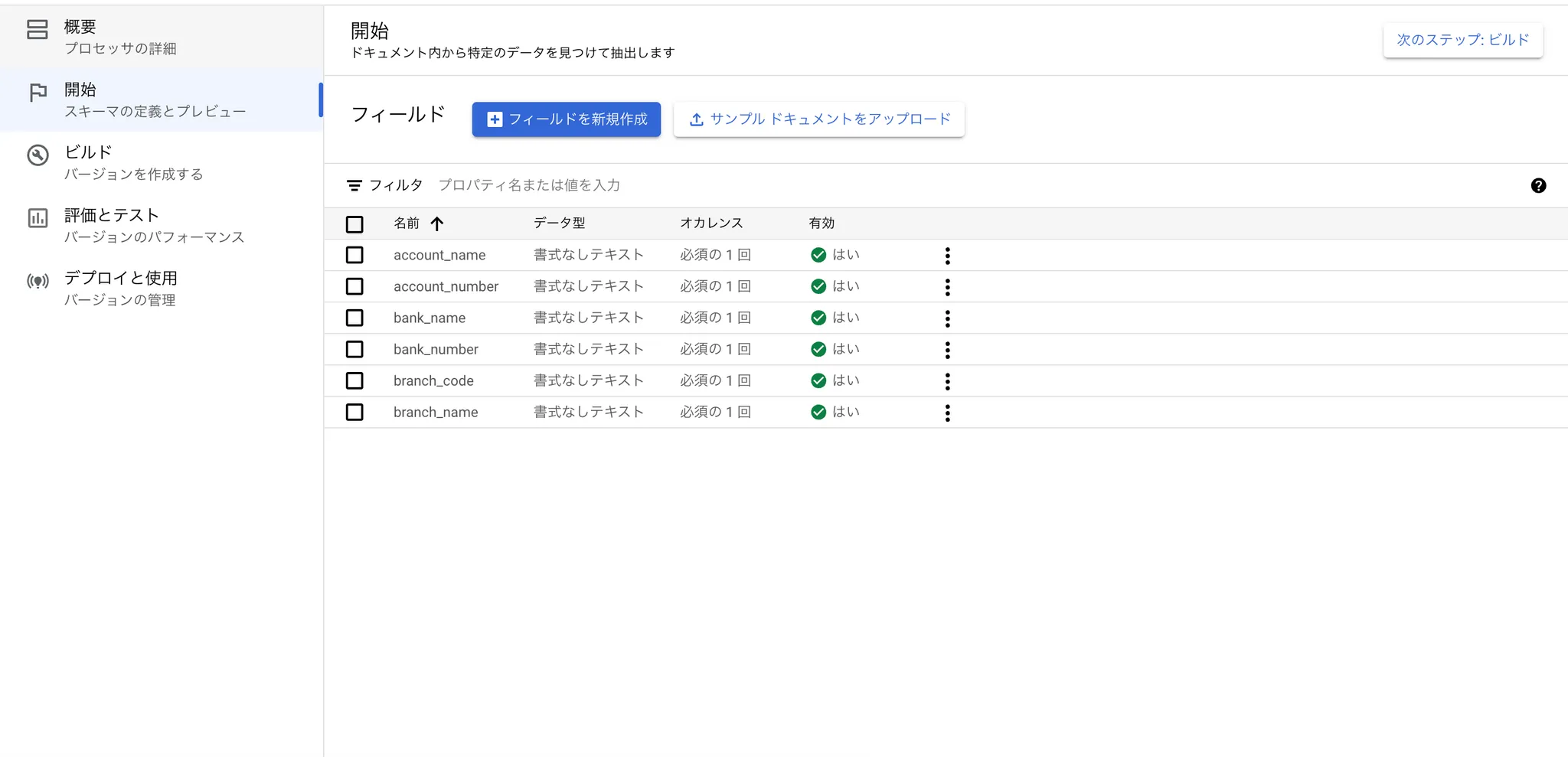
モデルには選択肢があります。
A)基盤モデルを使用する場合
事前にトレーニング済みのデータを利用するため、トレーニングデータを新たに学習させる必要はありません。
B)ファインチューニングを使用する場合
事前にトレーニング済みのデータに加えて、追加のデータを学習させることができます。これにより、ドキュメントをインポートしてトレーニングデータを学習させることが可能です。
2つとも検証してみようと思います。
6.4 ドキュメントのインポート
「自動ラベル付けを使用したインポート」を選択すると、インポートされたデータから自動でラベル付けが行われます。
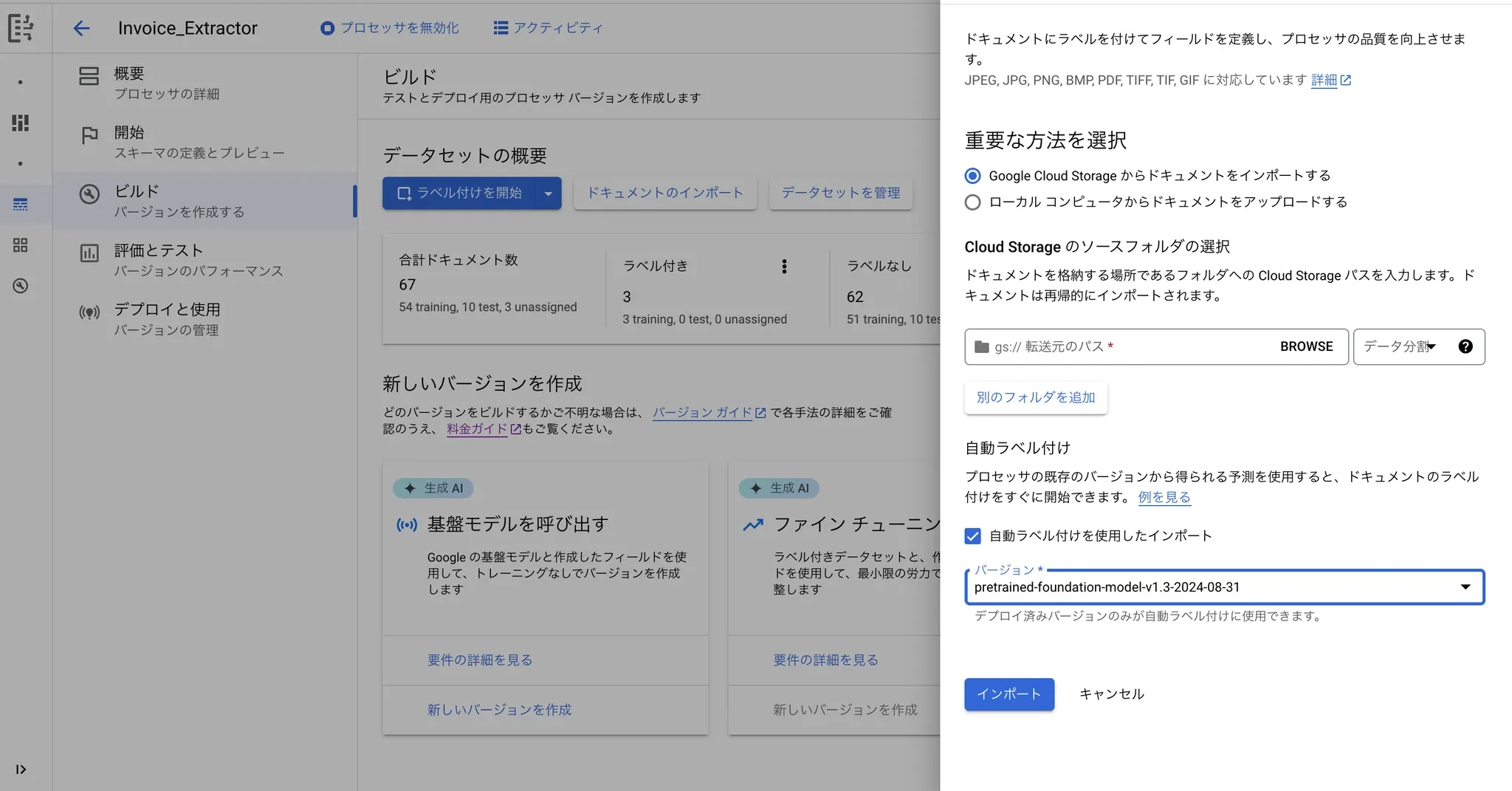
自動でラベル付けできないデータは、「ラベル付けを開始」から手動でラベル付けすることができます。
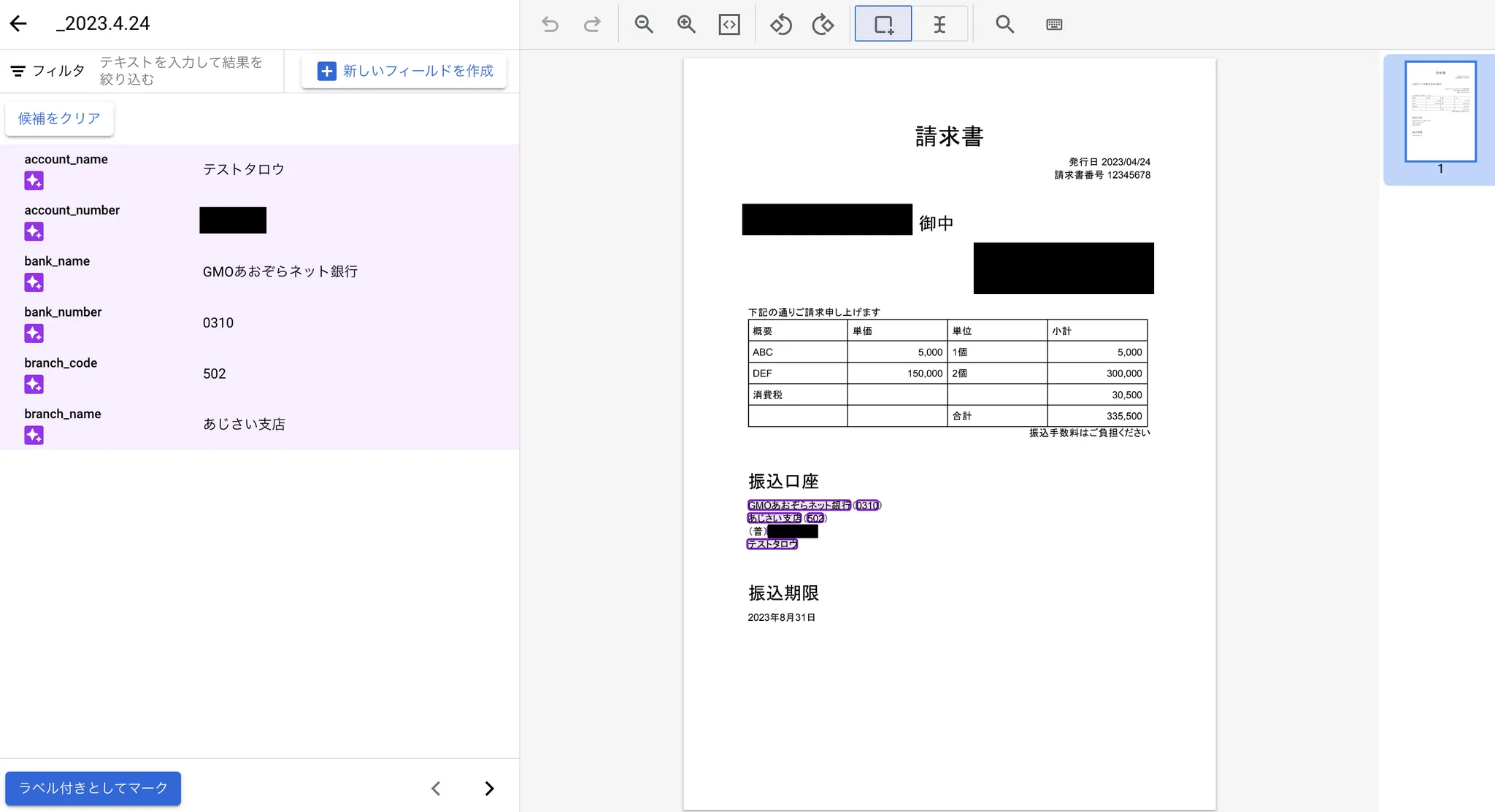
6.5 評価
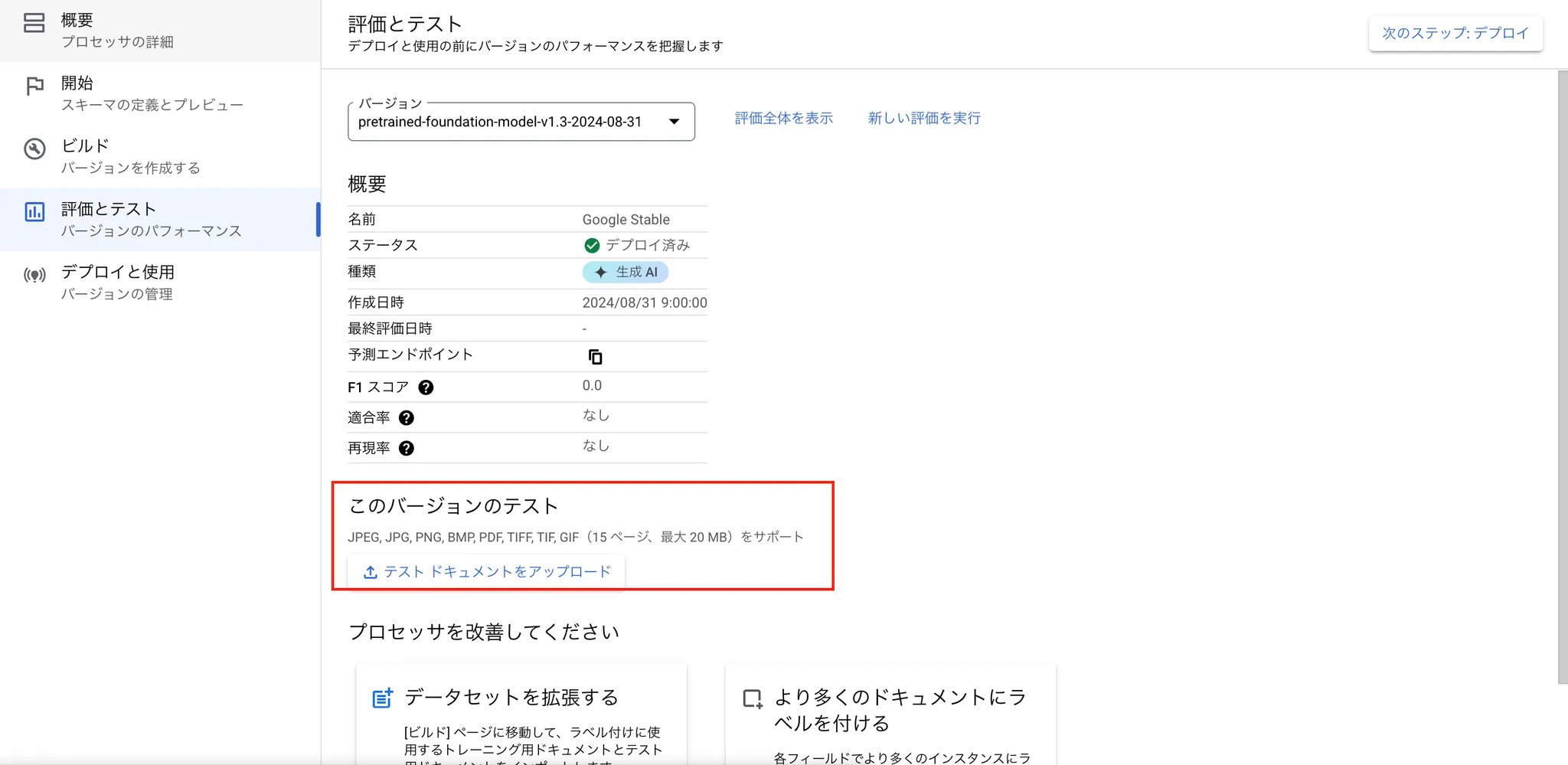
- ファインチューニングを使用した場合:手元にある請求書正式10件ぐらいに学習させて、別の請求書の同じ形式で正しく抽出できています。

- 基盤モデルを呼び出した場合:手元にある請求書を正式に10件ほど学習させずに、同じように正確な抽出ができていました。
今回の実験ではいずれの場合でも高精度でした。テスト請求書の範囲では、2つのモデルの性能をまだ判別できていません。実際に、より多くの形式の請求書を試す必要があると思います。
7. 結論
フィールド定義が単純に銀行口座を示す英字だけであっても、正確に銀行口座や銀行名義などのデータを抽出できています。さすがAIの時代です。
Document AIは、ドキュメントファイルの処理性能が非常に高いため、ぜひ実際の運用に導入してみてください。
宣伝
次世代システム研究室では、最新のテクノロジーを調査・検証しながらインターネットのいろんなアプリケーションの開発を行うアーキテクトを募集しています。募集職種一覧 からご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD