2025.09.01
Nano Banana: Gemini 2.5 Flash Image(とQwen-Image-Edit)で画像生成・編集を試してみた
TL;DR
- GoogleのGemini 2.5 Flash Image (aka nano-banana)がリリースされました。従来のGeminiの画像生成・編集機能が大幅に強化されており、登場人物を再現した新しいシーンの生成やアイテムの抽出、複数画像を与えた編集などが可能です。
- また、最近のオープンウェイトモデルとして、AlibabaのQwen-Image, Qwen-Image-EditもOpenAI GPT Image 1やGemini 2.5 Flash Imageに匹敵する性能を持っています。これらはローカル環境で実行できる点がメリットです。
はじめに:Nano Bananaとは?
こんにちは、グループ研究開発本部のAI研究開発室のT.I.です。昨今の画像生成・編集AIの品質・性能は大幅に改良され、ちょっとしたスライド資料の挿絵やアイコンを生成したり、画像を簡単に編集してみたりと、自分のような(イラストが描けずPhotoshopも使えないような😢)データサイエンティスト(?)にもなかなかに便利なツールとなっています。さて、先日GoogleがGemini 2.5 Flash Image (通称Nano Banana)を発表しました「Introducing Gemini 2.5 Flash Image, our state-of-the-art image model」。以前のブログ「OpenAIのGPT Image 1 APIで入力画像に高い忠実度(high input fidelity)の画像生成を試してみた」では、Gemini(当時)の画像編集機能と比較して、GPT Image 1の方が優れていると感じましたが、果たしてGemini 2.5 Flash Imageはどうなのでしょうか?Gemini 2.5 Flash Image は、GeminiのアプリやAPI、Google AI Studioで利用可能です。早速、以前のブログで紹介した画像編集タスクを「クリスマス・シーズンの画像を、ビーチとヤシの木がある夏のシーズンの画像に変更してください。」といったプロンプトで3人組の画像を編集した結果の比較が以下となります。
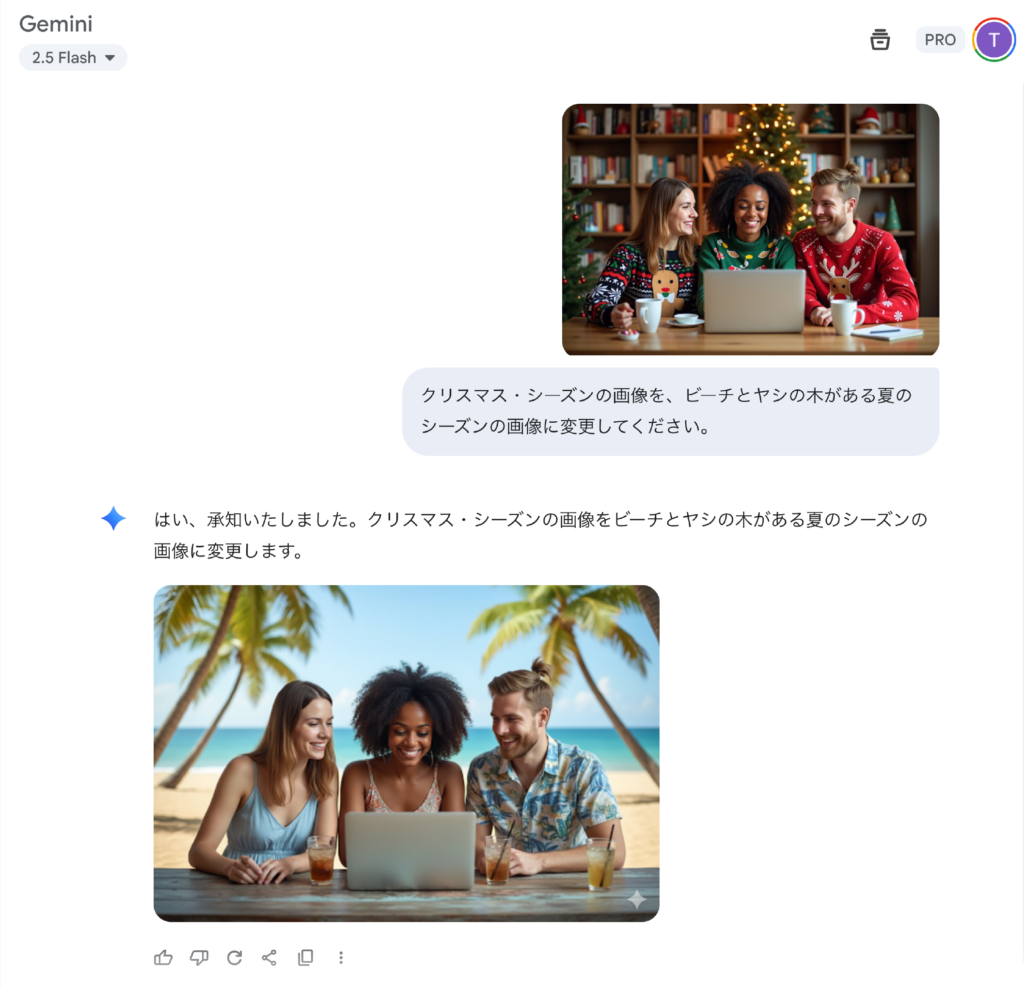
登場人物をそのままに簡単に編集できますね、以前のブログで紹介したGPT Image 1 High Fidelityと以前のGeminiでの編集結果と比較したのが以下の図です。

以前のGemini(左下)では変なセーターのままで、人物の顔の再現性が今ひとつでしたが、Gemini 2.5 Flash Image(右下)では、人物の顔も自然で服も夏らしい格好になっています。GPT Image 1 High Fidelity と比較しても人物の再現性は格段に高くなっております。また、GPT Image 1 High Fidelityでは、シンプルなTシャツですが、Gemini 2.5 Flash Imageではアロハシャツなどより凝った服装になっています。テーブルの飲み物もコーヒーから涼しげなドリンクに変更されている点など実に芸が細かいですね。
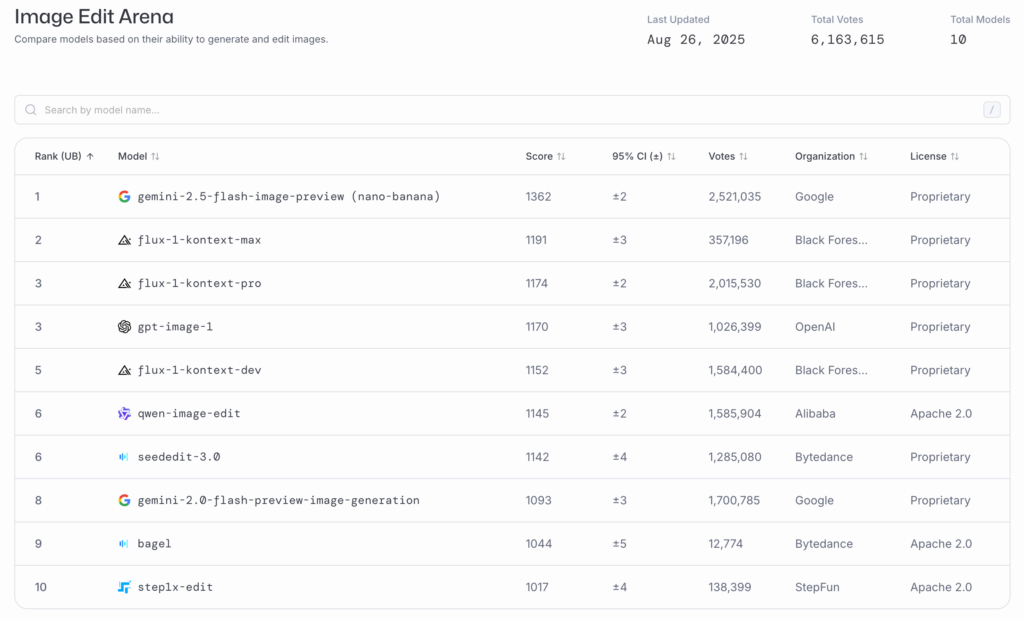
ちなみにこの「Nano Banana」というのはLMArenaで突如として画像生成・編集タスクで高性能を発揮して話題となった謎のモデルのコードネームでした。これが後の発表で、Gemini 2.5 Flash Imageであることが判明しました。
今回のブログでは、このGemini 2.5 Flash Image (Nano Banana)の紹介と、匹敵する画像生成・編集性能を誇るオープンウェイトモデルであるQwen-Image-Editとの比較を行います。
Gemini 2.5 Flash Imageで画像生成・編集してみる
Gemini 2.5 Flash ImageはGemini appやGemini API、Google AI Studioで利用可能です。Google AI Studioの場合はモデル名として「Nano Banana(gemini-2.5-flash-image-preview)」を選択します。
APIで画像生成・編集してみる
APIの利用方法については、公式のドキュメント「Image generation with Gemini (aka Nano Banana)」を参照してください。具体的なAPIの利用例と画像生成・編集におけるTipsが公開されています。まずは、PythonでAPIを利用するために必要なライブラリをインストールします。
$ pip install google-genai
また、APIの利用のためにGoogle AI StudioでAPIキーを取得して、GEMINI_API_KEYとして設定しておきます。Gemini APIを利用した画像生成は以下の通りです。モデル名としては、gemini-2.5-flash-image-previewを指定します。
from google import genai
from google.genai import types
from PIL import Image
from io import BytesIO
client = genai.Client()
prompt = (
"Nano bananaがおしゃれなレストランで提供されている様子を、Geminiのテーマで描いてください。"
)
response = client.models.generate_content(
model="gemini-2.5-flash-image-preview",
contents=[prompt],
)
for part in response.candidates[0].content.parts:
if part.text is not None:
print(part.text)
elif part.inline_data is not None:
image = Image.open(BytesIO(part.inline_data.data))
image.save("generated_image.png")
以上のコードを実行すると、以下のように画像だけではなく、Geminiからの返答も一緒に得られます。
はい、承知いたしました。Geminiのテーマでおしゃれなレストランで提供されているNano bananaの画像を作成します。どうぞ!
(by Gemini 2.5 Flash Image)

画像編集には、イメージファイルを読み込んで、プロンプトと一緒に与えます。
client = genai.Client()
prompt = (
"私の犬がnano bananaを食べている様子を、ふたご座の星座の下でおしゃれなレストランで描いてください。"
)
image = Image.open("./my_dog.jpg")
response = client.models.generate_content(
model="gemini-2.5-flash-image-preview",
contents=[prompt, image],
)
for part in response.candidates[0].content.parts:
if part.text is not None:
print(part.text)
elif part.inline_data is not None:
image = Image.open(BytesIO(part.inline_data.data))
image.save("generated_image.png")

なんかバナナをそのまま咥えているだけではありますが、元の犬がちゃんと再現されておしゃれなレストランにちょこんと座っている姿が可愛いですね。
もちろん複数の画像を与えて生成も可能です。
client = genai.Client()
sweater_image = Image.open('./sweater.png')
model_image = Image.open('./model.png')
text_input = """ECサイトのためのプロフェッショナルなファッション写真を作成してください。最初の画像の赤いセーターの画像を取りの2番目の画像の男性に着せてください。男性がセーターを着ているリアルで全身の写真を生成し、照明と影を屋外環境に合わせて調整してください。"""
response = client.models.generate_content(
model="gemini-2.5-flash-image-preview",
contents=[sweater_image, model_image, text_input],
)
image_parts = [
part.inline_data.data
for part in response.candidates[0].content.parts
if part.inline_data
]
if image_parts:
image = Image.open(BytesIO(image_parts[0]))
image.save('fashion_ecommerce_shot.png')
image.show()

与えたセーターとモデルの画像がうまく合成されており、背景の一部も変わっており街中の広場の様子が映るなど自然な写真に仕上がっています。
効果的なプロンプトのコツ (by Google)
効果的な生成プロンプトのコツとテンプレートなどについて公式のブログなどの情報が参考となりますので、参照してみてください。
- Tips for getting the best image generation and editing in the Gemini app
- Image generation with Gemini (aka Nano Banana)
- How to prompt Gemini 2.5 Flash Image generation for the best results
これらの記事では、以下のように効果的なプロンプトのポイントがまとめられています。
- Subject(被写体):明確で具体的に(例:「光る青い瞳を持つロボットバリスタ」など)
- Composition(構図):ショットのフレーミング(例:ワイドショット、ローアングルなど)
- Action(動作):何をしているか(例:コーヒーを淹れている、呪文を唱えている)
- Location(場所):どこで(例:火星の未来的なカフェなど)
- Style(スタイル):全体の美的表現(例:フィルムノワール、水彩画など)
- Editing Instructions(編集指示):既存画像の編集時は具体的に指示(例:「ネクタイを緑にする」「車を背景から削除する」)
また、より高品質な画像生成・編集のためのベストプラクティスとして以下のような解説があります。
- 描写を非常に具体的にする:描写を詳細にするほど結果を大きく改善(例:「ファンタジーの鎧」ではなく「銀箔の模様が刻まれ、高い襟と隼の翼のような形をした胴を持つ、エルフの豪華な板鎧」。
- 文脈と意図を明示:目的と文脈を伝えると精度向上(例:「ロゴを作成」ではなく「高級でミニマルなスキンケアブランドのロゴを作成」)
- 反復と修正:会話型インターフェースを活用し小調整を重ねる(例:「ほかはそのままで、キャラクターの表情をもっと真剣にしてください」)
- ステップバイステップでの生成:複雑なシーンは段階的に生成する(例:「まず、夜明けの穏やかな霧の森の背景を作る。次に前景に、苔むした古い石の祭壇を加える。最後にその祭壇の上に、一本の発光する剣を置く。」)
- 意味的なネガティブプロンプトを利用する:「車なし」と否定せず、「交通の気配のない、人気のない空っぽの通り」など肯定的に表現する
- カメラ表現で構図を制御:構造の制御のために具体的な撮影用語を使う(例:広角ショット、マクロショット、ローアングル視点など)
これらのポイントを押さえることで、より意図に沿った高品質な画像生成・編集が可能となりますので、色々と試してみてください。
画像生成・編集の例 (by Google)


Qwen-Image-Editと比べてみる
さて、Gemini 2.5 Flash Image (Nano Banana)の画像生成・編集性能は非常に高いのですが、昨今のオープンウェイトモデルの性能改善も著しくAlibabaのQwenチームが開発したQwen-Imageとそれを画像編集用に強化したQwen-Image-Editが注目されています。Qwen-Imageは、8月4日にリリースされたモデルで、200億パラメータのモデルで、画像生成で特に文字表現が強化されています。アルファベットだけではなく、中国語の文字表現も得意です(Qwen-Image: Crafting with Native Text Rendering)。そして、Qwen-Image-Edit(Qwen-Image-Edit: Image Editing with Higher Quality and Efficiency)は、Qwen-Imageをベースに画像編集を強化したモデル、8月19日にリリースされました。

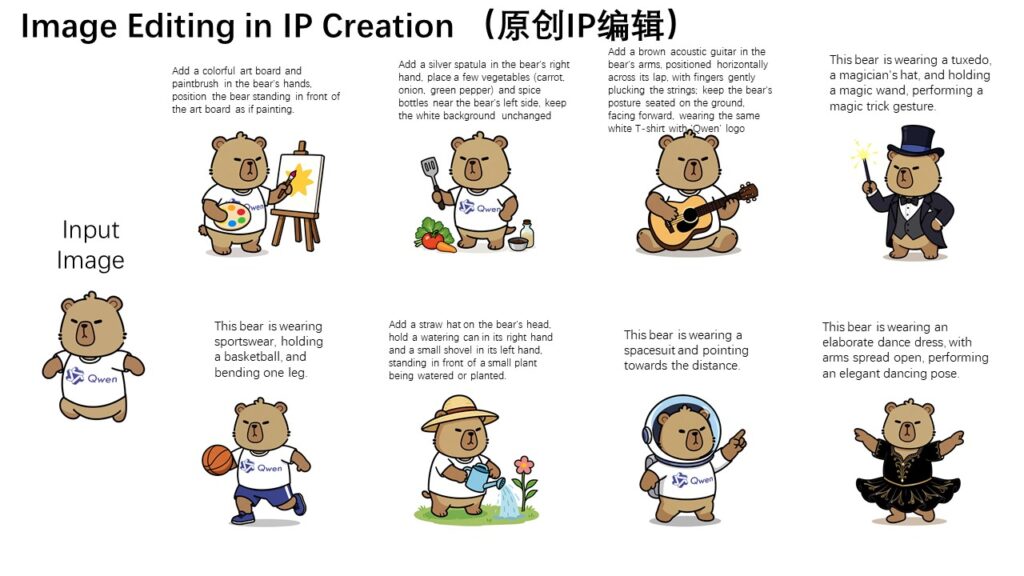
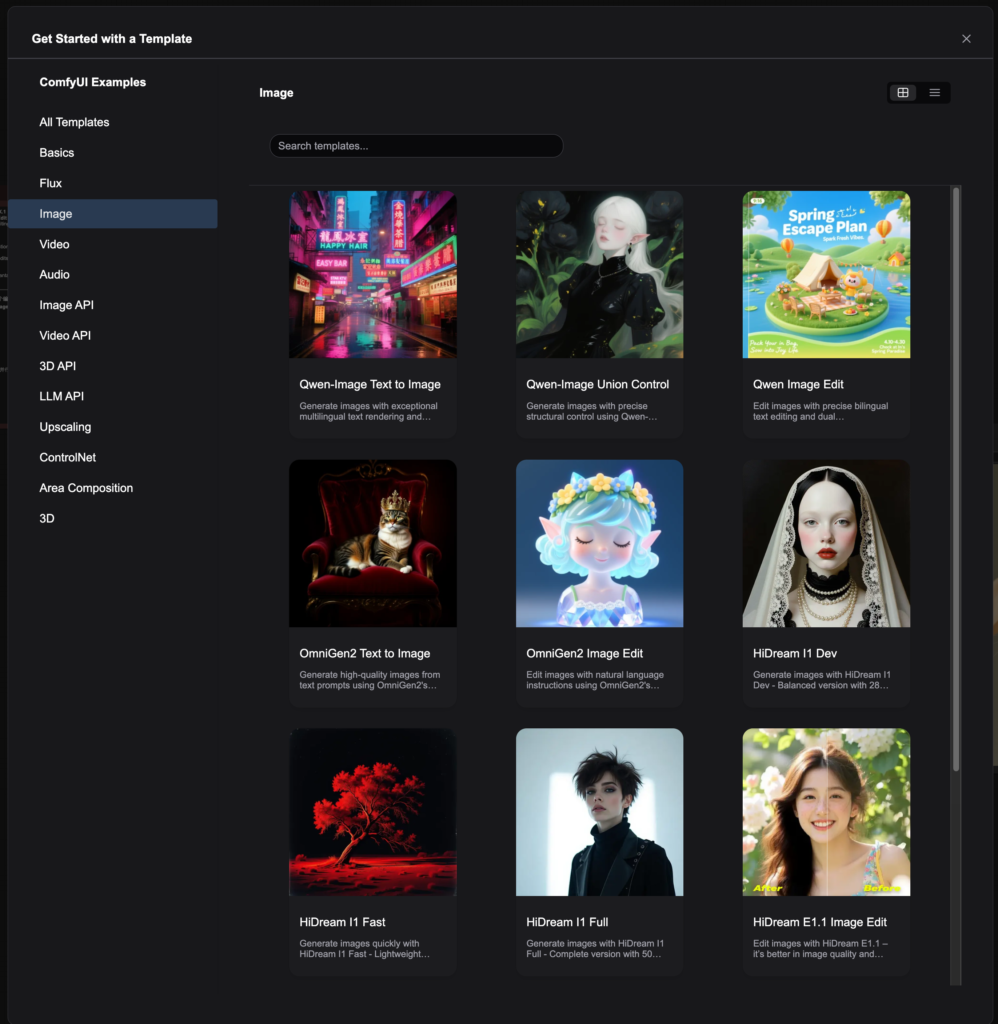
Qwen-Image-EditをComfyUIでの導入してみる
Qwen-Image(Qwen-Image-Edit)をローカル環境に導入するにはComfyUIを利用するのが便利です。画像生成プロセスのワークフローをGUIで構築するツールで画像生成だけではなく、動画生成なども可能です。最新バージョンでは、これらのモデルのワークフローが標準で用意されているのでテンプレートから選択し、必要なモデルのパラメータをダウンロードすれば利用可能です。
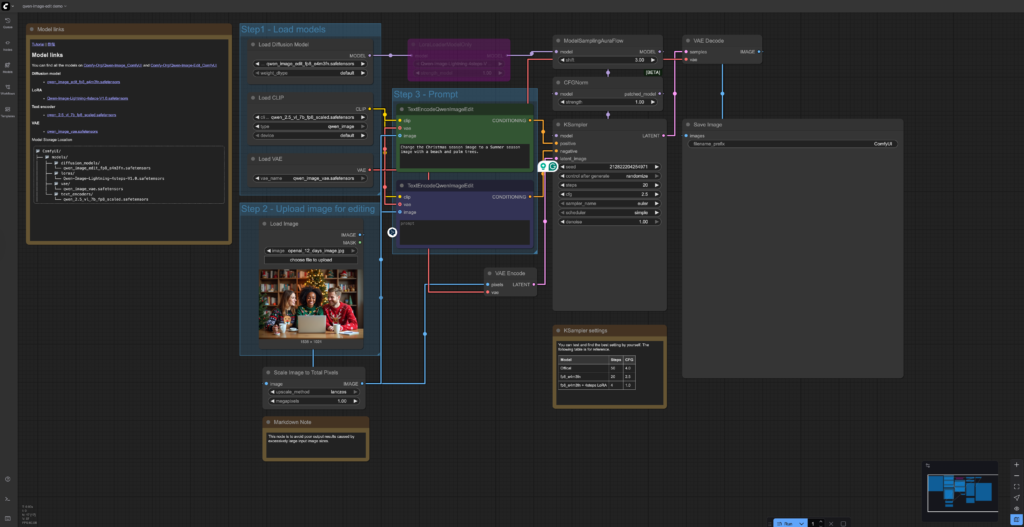
OpenAI GPT Image 1、Gemini 2.5 Flash Image、Qwen-Image-Editとの比較
さて、Qwen-Image-Editでは、どのような結果になるでしょうか。まずは、先ほどのクリスマスから夏のビーチサイドへの変更の比較です。

左下がQwen-Image-Editの編集結果です。よく見ると、オリジナルの人物や手前のテーブルなどの画像はそのままに背景のみが差し替えられていることがわかります。そのため登場人物の服はセーターのままで夏のビーチという文脈には合っていません。 その一方で、GPT Image 1 (High Fidelity)とGemini 2.5 Flash Imageでは、人物や手前のテーブルなど全て改めて生成していることがわかります。GPTやGeminiの文脈理解によるもので服装も夏らしいものに変更されています。
次にアイテム抽出の実験をしてみます。男性が来ているセーターを抽出して、白い背景に出力してもらいます。結果は以下の通りです。

以前のGeminiではあまり品質が高くなかったですが、Gemini 2.5 Flash Image ではトナカイのデザインや柄が微妙に違うものの品質は高くなっています。そして、Qwen-Image-Editはセーターのデザインの再現性が非常に高いです。オリジナルの画像とよくよく比較してみると分かりますが、元の画像からセーターの部分を抽出し、それを元に見えない箇所を補完しつつ生成しているものと思われます。
さて次は2枚の画像を与えて、人物の服を変更してみます。Qwen-Image-Editの場合、ComfyUIのワークフローを修正し、2枚の画像を結合して入力しプロンプトの指示を工夫して処理しています。
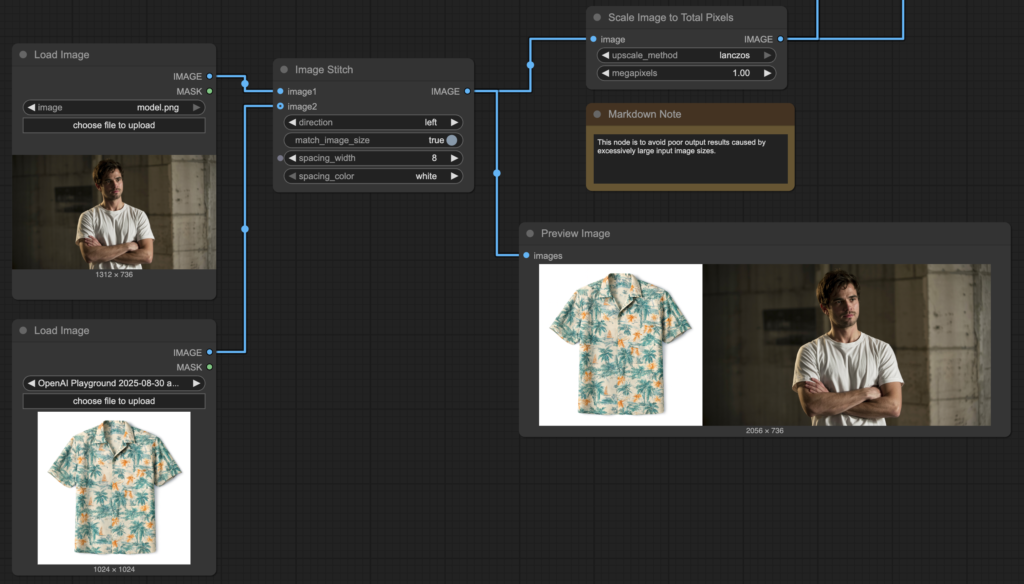
さて、結果は以下の通りです。

元のアロハシャツの柄の再現性としては、GPT Image 1 High Fidelity が最も正確ですが、画面が全体的にやや暗くなってしまっています。Gemini 2.5 Flash ImageとQwen-Image-Editのどちらもオリジナルの人物の再現性は高いものの、服の柄の細かい部分がやや異なっています。比較するとQwen-Image-Editの方が柄がぼんやりとしている印象を受けます。
まとめ
今回のブログでは、GoogleのGemini 2.5 Flash Image (Nano Banana)の紹介と、AlibabaのQwen-Image-Edit、OpenAI GPT Image 1による画像生成・編集の比較を行いました。オリジナルの画像の再現性の高さとしては、GPT Image 1 High Fidelity、Gemini 2.5 Flash Imageの順で高いように思われます。Qwen-Image-Editも再現性は高いのですが、GPT Image 1やGemini 2.5 Flash Imageのように一から生成しなおすというよりも、オリジナルの画像をベースにそれ以外の箇所を補完するような形で生成しているようなので比較には注意が必要です。生成画像の品質に関しては、GPT Image 1よりもGemini 2.5 Flash Imageの方がより綺麗でクオリティが高い印象を受けました。LMArenaのランキングが高いのも頷けます。なお、Qwen-Image-Editはオープンウェイトモデルであり、性能に関しては、ややクローズドモデルには敵わない印象はありますが、ローカル環境で実行できる点や漢字の文字表現ができる点が強みだと思います。

最後に
グループ研究開発本部 AI研究開発室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務などAI研究開発室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ募集職種一覧からご応募をお願いします。皆さんのご応募をお待ちしています。

参考資料
- Introducing Gemini 2.5 Flash Image, our state-of-the-art image model
- OpenAIのGPT Image 1 APIで入力画像に高い忠実度(high input fidelity)の画像生成を試してみた
- LMArena
- Image generation with Gemini (aka Nano Banana)
- Tips for getting the best image generation and editing in the Gemini app
- How to prompt Gemini 2.5 Flash Image generation for the best results
- Qwen-Image: Crafting with Native Text Rendering
- Qwen-Image-Edit: Image Editing with Higher Quality and Efficiency
- ComfyUI: The most powerful and modular visual AI engine and application.
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD