2022.07.07
本番に強いモデルを作るために
はじめに
こんにちは。グループ研究開発本部 AI研究開発室のS.Y.です。
今回は機械学習プロダクトでよく起こる (そしておそらく最も悩ましい)、サービング時のモデル精度が学習時の精度と比べて下がってしまう問題について、一般的な原因や対策方法、そしてそういった現象の監視や対策をGCPを使ってどのように(どこまで)実現できるのかを調べてみます。
データドリフトと分布スキュー
学習時とサービング時でモデル精度が悪化する原因はいくつか考えられますが、ここでは学習時とサービング時のデータが大きく乖離することに起因するデータドリフトを扱います。
データの違い(スキュー)として、主なものはふたつあります。
- スキーマスキュー: 学習データとサービング データが同じスキーマに従っていない場合に発生します。データのrangeが異なったり、学習時になかったカテゴリがサービング時に出現したりといったものがあります。原因として、学習時とサービング時でデータ処理が異なったり (学習時は実験コードの延長でpythonを使うが、本番ではパフォーマンス要件を満たすために別のより高速なライブラリを使用する、など)、サービング時に障害が発生したりすると発生します。
- 分布スキュー: トレーニング データの特徴量の分布がサービング データと大きく異なる場合に発生します。サービングデータに比べてトレーニングデータに偏りがある場合や、時間経過によって特徴量の分布が自然と変化する場合にも発生します。
どちらもGCPではTensorflow Data ValidationやVertexAI Model Monitoringを使って検出できます。また、Tensorflow Transformを使って前処理をモデルに含めてしまったり、VertexAI Endpointにデプロイすることで、学習時とサービング時で処理を統一でき、スキーマスキューのリスクをある程度取り除くことができます。
分布スキューについて、Dive into Deep Learningを参考に、原因と対処法について深堀ります。
Distribution Shift
分布スキューのうち、時間経過によって自然と引き起こされるもの(季節性のトレンド等)については、最新のデータを使ったモデルの再学習で対応できます。
一方で、最新の学習データへのアクセスが難しいような場合や、偏ったデータでしか学習できない場合(例: 日本のデータで学習させたいがラベル付きのデータがないため、アメリカのラベル付きデータで学習したモデルを日本のデータに適用する)にも、手元にある学習データを使ってスキューを起こさないように工夫して学習する方法があります。
この方法を適用するには、データがどのように変化しているのか(Distribution Shift)についての仮定をおき、その仮定毎に対処する必要があります。
Covariate Shift (共変量シフト)
入力の分布が学習時(p_t)とサービング時(p_s)で変化する一方で、ラベリング関数すなわち条件付き分布P(y|x)は変化しないと考えられる場合、共変量シフトを仮定します。
サービング環境で精度が出ない際にまず疑うDistribution Shiftで、最も議論されるシフト仮定です。
共変量シフトが起こる例として、犬と猫の写真で学習した識別器に、犬と猫のイラストを識別させようとした場合、おそらく識別器はイラストをうまく識別できないでしょう。


Label Shift (ラベルシフト)
共変量シフトとは対照的に、クラスラベルの条件付き分布P(x|y)が変化する一方で、入力特徴量はドメイン間で変化しないと仮定します。yがxを引き起こすと考えられる場合は、ラベルシフトは妥当な仮定となります。
ラベルシフトを仮定できる例として、症状を入力として、その症状を引き起こした病気を診断することを考えます。同じ症状でも、医学の進歩具合や医師の熟練度の違い(P(x|y)が異なる)が原因で、国によって違う病気と診断される可能性があり、ラベルシフトを仮定できます。
Distribution Shiftの修正
Distribution Shiftの修正について議論するにあたり、Empirical Riskというものを下記で定義します。
\[
E_{p(x,y)}[l(f(x),y)]=\int\int l(f(x),y)p(x,y)dxdy
\]
この呼び方は統計学の分野で多く用いられ、式の意味としては、p(x,y)からサンプリングされたデータ全体についてのLoss(正解ラベルyと予測f(x)の差)の期待値です。Machine Learnnigではこれを最小化する方向に学習が進みます。
Covariate Shiftの修正
p(x)をサービング時の特徴量の分布、q(x)を学習時の特徴量の分布とします。
covariate shiftでは「ラベリング関数は変化しない、つまりp(y|x)=q(y|x)である」ことを仮定するので、サービング時のEmprircal Riskは下記のようにp(x), q(x)を使って変換できます。
\[
\int\int l(f(x),y)p(y|x)p(x)dxdy=\int\int l(f(x),y)q(y|x)q(x)\frac{p(x)}{q(x)}dxdy
\]
つまり、真に最小化したい(しかし学習時の時点では分からない)サービング時のEmpirical Riskは、学習時のEmpirical Riskを「学習時とサービング時の特徴量の分布の比」で重み付けすることで得られます。学習時にだけ多く現れるようなサンプルについては重みを小さくして、逆に学習時にはあまり現れないがサービング時になると頻出するようなサンプルは重みを大きくするということです。
サンプルiの重みをβiとして下記のように定義すると、
\[
\beta_i:=\frac{p(x_i)}{q(x_i)}
\]
学習時に行うべきLossの最小化は、最終的に下記のようなものになります。
\[
\underset{f}{minimize}\frac{1}{n}\sum_{i=1}^n \beta_il(f(x_i),y_i)$
\]
この比率βは分からないので、様々な手法で推定する必要があります。例えばロジスティック回帰を使ったβの推定方法では、学習データの特徴とサービングデータの特徴を見分けるロジスティック回帰モデルを作成し、モデルが明確に見分けられるサンプルに対して、学習データだと判別されたものには小さい重みを、サービングデータだと判別されたものには大きい重みをつけます。
この方法では、parameterized functionのh(x)を用いて、サンプルiについての比率βiを下記のように求めることができます。学習時/サービング時のデータの特徴量のみが必要で、サービング時のデータのラベルは必要ありません。
\[
\beta_i=\frac{1/(1+exp(-h(x_i)))}{exp(-h(x_i))/(1+exp(-h(x_i)))}=exp(h(x_i))
\]
得られたβを使ってサンプルの重み付けをすると、covariate shiftを抑えた学習ができます。
VertexAI Model Monitoringによるスキュー/ドリフトの検出
GCPではVertexAI Model Monitoringでデータスキューやデータドリフトを検出することができます。
VertexAI Model Monitoringでは、モデルがデプロイされているエンドポイントに対してモニタリングジョブを作成します。モニタリングジョブでは、予測実行のログをBQに保存し、サービングデータのスキーマや統計情報を作成します。学習データとサービングデータを比較してデータスキューを検出したり、サービングデータを時間毎に比較してデータドリフトを検出したりできます。
モニタリングジョブは、python APIやgcloudコマンドで作成できます。将来的にコンソールからの作成もできるようになるようです。
こちらのチュートリアルをVertexAI Worckbench上で実行し、エンドポイントに対してモニタリングジョブを設定してみます。
元のコードでは必要なパッケージの最新版をインストールしていますが、基本的に全てのパッケージで最新版を入れるとdependencyエラーが発生します。特にtensorflow data validationはバージョン毎に動くtensorflowのバージョンが異なるので、バージョン指定してインストールする必要があります。
! pip3 install {USER_FLAG} --quiet google-api-python-client==1.8.0
! pip3 install {USER_FLAG} --quiet tensorflow==2.8.2
! pip3 install {USER_FLAG} --quiet google-auth-oauthlib==0.4.6
エンドポイントにデプロイするモデルをインポートします。今回はGCSにアップロードされているpublicなモデルを使います。このモデルは、とあるゲームのプレイヤーが今後解約するかどうかを判別します。
import json
MODEL_NAME = "churn"
IMAGE = "us-docker.pkg.dev/cloud-aiplatform/prediction/tf2-cpu.2-5:latest"
ENDPOINT = "us-central1-aiplatform.googleapis.com"
churn_model_path = "gs://mco-mm/churn"
request_data = {
"model": {
"displayName": "churn",
"artifactUri": churn_model_path,
"containerSpec": {"imageUri": IMAGE},
"explanationSpec": {
"parameters": {"sampledShapleyAttribution": {"pathCount": 5}},
"metadata": md,
},
}
}
with open("request_data.json", "w") as outfile:
json.dump(request_data, outfile)
output = !curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://{ENDPOINT}/v1/projects/{PROJECT_ID}/locations/{REGION}/models:upload \
-d @request_data.json 2>/dev/null
# print(output)
MODEL_ID = output[1].split()[1].split("/")[5]
print(f"Model {MODEL_NAME}/{MODEL_ID} created.")
# If auto-testing this notebook, wait for model registration
if os.getenv("IS_TESTING"):
time.sleep(300)
インポートしたモデルをendpointにデプロイします。
ENDPOINT_NAME = "churn"
output = !gcloud --quiet beta ai endpoints create --display-name=$ENDPOINT_NAME --format="value(name)"
# print("endpoint output: ", output)
ENDPOINT = output[-1]
ENDPOINT_ID = ENDPOINT.split("/")[-1]
output = !gcloud --quiet beta ai endpoints deploy-model $ENDPOINT_ID --display-name=$ENDPOINT_NAME --model=$MODEL_ID --traffic-split="0=100"
print(f"Model deployed to Endpoint {ENDPOINT_NAME}/{ENDPOINT_ID}.")
endpointに対してモニタリングジョブを開始します。
通知を送るメールアドレスや、ジョブの間隔、スキューやドリフトと見なすthresholdなどを設定していきます。いくつかのヘルパー関数は定義を省略しています。詳細はtutoralのノートブックをご参照ください。
DATASET_BQ_URLでは、学習に使用したトレーニングデータを指定します。
USER_EMAIL = "YOUR EMAIL" # @param {type:"string"}
JOB_NAME = "churn"
# Sampling rate (optional, default=.8)
LOG_SAMPLE_RATE = 0.8 # @param {type:"number"}
# Monitoring Interval in seconds (optional, default=3600).
MONITOR_INTERVAL = 3600 # @param {type:"number"}
# URI to training dataset.
DATASET_BQ_URI = "bq://mco-mm.bqmlga4.train" # @param {type:"string"}
# Prediction target column name in training dataset.
TARGET = "churned"
# Skew and drift thresholds.
SKEW_DEFAULT_THRESHOLDS = "country,cnt_user_engagement" # @param {type:"string"}
SKEW_CUSTOM_THRESHOLDS = "cnt_level_start_quickplay:.01" # @param {type:"string"}
DRIFT_DEFAULT_THRESHOLDS = "country,cnt_user_engagement" # @param {type:"string"}
DRIFT_CUSTOM_THRESHOLDS = "cnt_level_start_quickplay:.01" # @param {type:"string"}
ATTRIB_SKEW_DEFAULT_THRESHOLDS = "country,cnt_user_engagement" # @param {type:"string"}
ATTRIB_SKEW_CUSTOM_THRESHOLDS = (
"cnt_level_start_quickplay:.01" # @param {type:"string"}
)
ATTRIB_DRIFT_DEFAULT_THRESHOLDS = (
"country,cnt_user_engagement" # @param {type:"string"}
)
ATTRIB_DRIFT_CUSTOM_THRESHOLDS = (
"cnt_level_start_quickplay:.01" # @param {type:"string"}
)
skew_thresholds = get_thresholds(SKEW_DEFAULT_THRESHOLDS, SKEW_CUSTOM_THRESHOLDS)
drift_thresholds = get_thresholds(DRIFT_DEFAULT_THRESHOLDS, DRIFT_CUSTOM_THRESHOLDS)
attrib_skew_thresholds = get_thresholds(
ATTRIB_SKEW_DEFAULT_THRESHOLDS, ATTRIB_SKEW_CUSTOM_THRESHOLDS
)
attrib_drift_thresholds = get_thresholds(
ATTRIB_DRIFT_DEFAULT_THRESHOLDS, ATTRIB_DRIFT_CUSTOM_THRESHOLDS
)
skew_config = ModelMonitoringObjectiveConfig.TrainingPredictionSkewDetectionConfig(
skew_thresholds=skew_thresholds,
attribution_score_skew_thresholds=attrib_skew_thresholds,
)
drift_config = ModelMonitoringObjectiveConfig.PredictionDriftDetectionConfig(
drift_thresholds=drift_thresholds,
attribution_score_drift_thresholds=attrib_drift_thresholds,
)
explanation_config = ModelMonitoringObjectiveConfig.ExplanationConfig(
enable_feature_attributes=True
)
training_dataset = ModelMonitoringObjectiveConfig.TrainingDataset(target_field=TARGET)
training_dataset.bigquery_source = BigQuerySource(input_uri=DATASET_BQ_URI)
objective_config = ModelMonitoringObjectiveConfig(
training_dataset=training_dataset,
training_prediction_skew_detection_config=skew_config,
prediction_drift_detection_config=drift_config,
explanation_config=explanation_config,
)
model_ids = get_deployed_model_ids(ENDPOINT_ID)
objective_template = ModelDeploymentMonitoringObjectiveConfig(
objective_config=objective_config
)
objective_configs = set_objectives(model_ids, objective_template)
monitoring_job = create_monitoring_job(objective_configs)
モニタリングジョブの作成は完了です。
チュートリアルでは、違う分布から生成したテスト用データを流してskewのアラートを発生させるコードがあるのですが、これを実行してもアラートが発生しませんでした。。
Threshouldsの設定とテスト用データのズレ加減が合っていないとか、原因は色々と考えられますが、うまくいくとendpointの画面に下記のようなアラートが表示され、内容を確認できるようです。
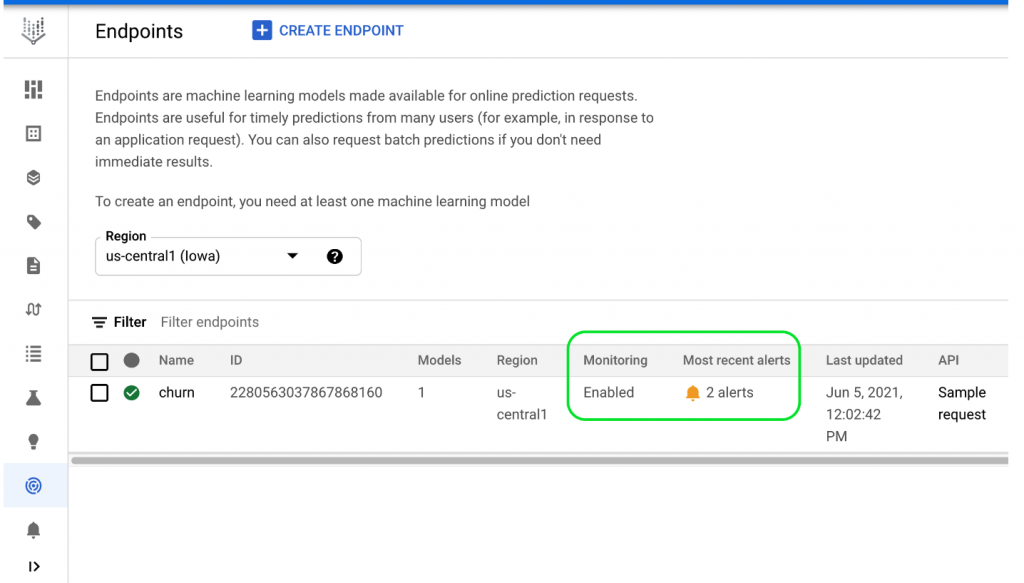
コストについて
VertexAIでスキュー/ドリフトの監視を行うモニタリングジョブを開始すると、以下について料金が発生します。
- BigQueryに保存されているリクエスト/レスポンスデータについての保存コスト。(普通のBQと同じ料金計算)
- 統計情報を作成するために分析されたデータについて、$3.50/GB。
- トレーニングデータの統計情報作成については、モニタリングジョブ開始時の1回のみ課金。
- リクエストデータの統計情報作成については、設定したインターバル毎に課金。
サンプリングレートを設定し、サブセットに対するモニタリングを行うことでコストを抑えることができます。
Tensorflow Data Validationを用いたデータのバリデーション
VertexAI Model MonitoringはTensorflow Data Validation(TFDV)で作成したデータ群についての統計情報やスキーマを使って、スキュー/ドリフトを検知しています。
TFDV単体でも統計情報・スキーマの作成、分布の可視化、分布差異の検出ができるので試してみます。
実運用時ではVertexAI Model Monitoringを使ったスキュー/ドリフト検知の方が遥かに簡単かつ便利なのでTFDVを単体で使うことはあまりないとは思いますが、サービングデータの分布が時間経過でどの程度変化するかを事前に把握したり、VertexAI Model Monitoringで検知したアラートを深掘りする場合には役立つと思います。
またここで作成したスキーマは、Tensorflow Extended(TFX)パイプラインのExample Validatorで読み込み、入力データの異常検知に使用できます。
こちらのチュートリアルをベースに実践していきます。
READMEに書いてある通りに、custom container imageをベースにVertexAI Workbenchのインスタンスを作成します。
TFDVは内部でapacke beamを使ってデータを処理します。チュートリアルでは2種類のnotebookがあって、それぞれlocalとDataflowでbeamを動かします。
一部notebookの内容が古くて動かないので、適宜更新します。
## パッケージの更新 !pip install -U apache_beam !pip install -U tensorflow_data_validation ## 公開データセットのlocationの更新 TRAINING_DATASET='gs://workshop-datasets/covertype/training/dataset.csv' TRAINING_DATASET_WITH_MISSING_VALUES='gs://workshop-datasets/covertype/data_validation/training_missing/dataset.csv' EVALUATION_DATASET='gs://workshop-datasets/covertype/evaluation/dataset.csv' EVALUATION_DATASET_WITH_ANOMALIES='gs://workshop-datasets/covertype/data_validation/evaluation_anomalies/dataset.csv' SERVING_DATASET='gs://workshop-datasets/covertype/serving/dataset.csv'
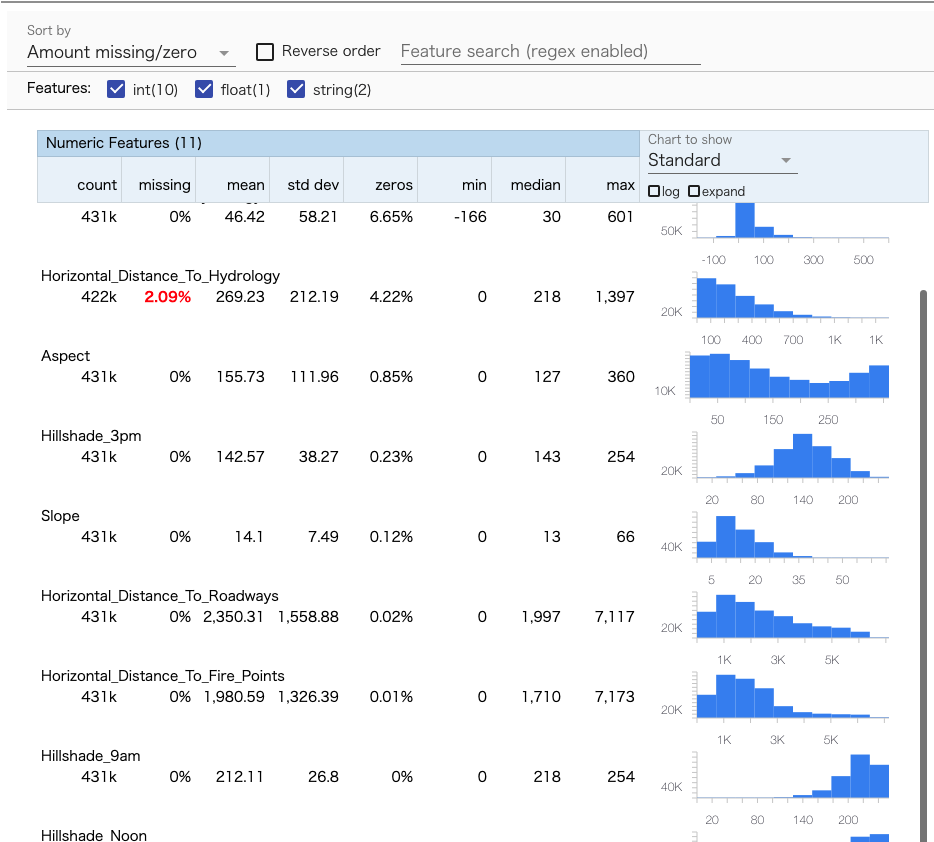
gcsからデータを読み込みstatsを作成します。検証の途中で何故かgcsの公開データセットにアクセスできなくなった(403: Access Denied)ので、Workbenckインスタンスのローカルにあるcsvファイルを読み込みます。tfdv.visualize_statisticsで、Facetsを用いたstatsの可視化が可能です。欠損やzeroの割合が多いfeatureがひと目でわかります。
train_stats = tfdv.generate_statistics_from_csv(
# data_location=TRAINING_DATASET_WITH_MISSING_VALUES
data_location = "../../datasets/covertype/covertype_training_missing.csv"
)
tfdv.visualize_statistics(train_stats)
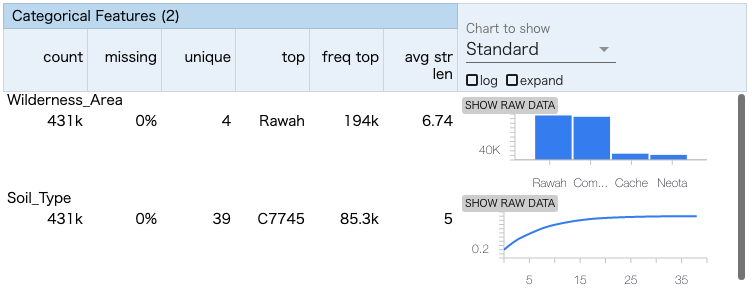
TFDVはstatsからschemaを推測します。tfdv.display_schemaでschemaを確認し、足りない部分や間違っている部分を修正して正しいschemaを作成します。
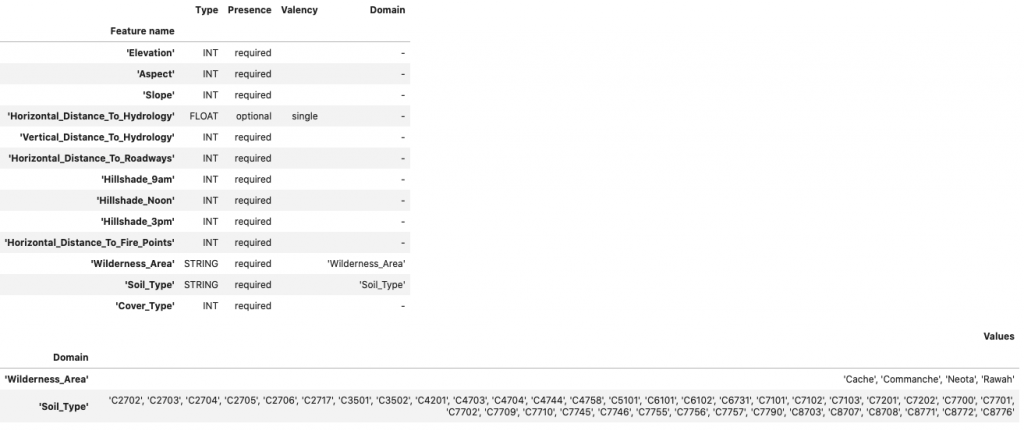
今回の問題はclassificationなので、正解ラベルとなるCover_Typeはcategoricalであることを期待します。また、斜面の傾斜を表すSlopeは0~90の範囲で定義されることが事前に分かっているので、RangeのDomainを設定します。
# Cover_Typeは1~7のcategorilcalを期待 tfdv.set_domain(schema, 'Cover_Type', schema_pb2.IntDomain(name='Cover_Type', min=1, max=7, is_categorical=True)) # 傾斜は0°~90°を期待 tfdv.get_feature(schema, 'Slope').type = schema_pb2.FeatureType.FLOAT tfdv.set_domain(schema, 'Slope', schema_pb2.FloatDomain(name='Slope', min=0, max=90)) tfdv.display_schema(schema=schema)
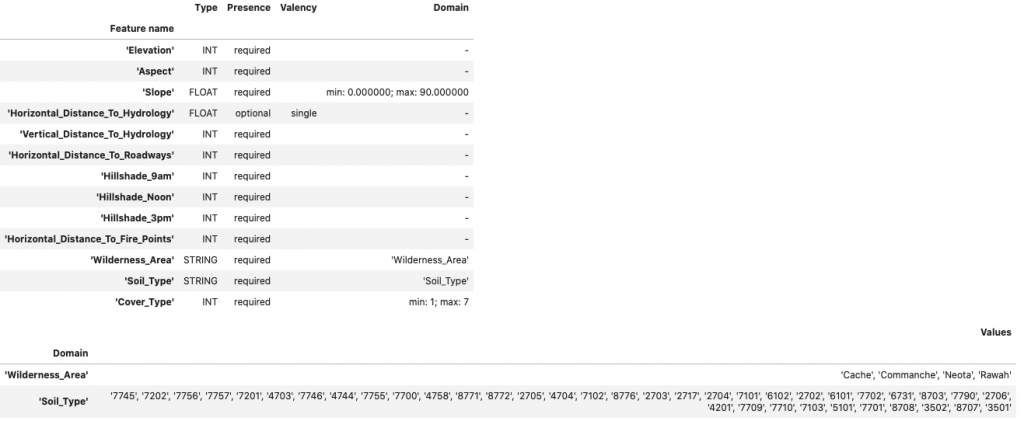
追加したDomainが反映されていますね。
修正したschemaを元に、正しいstatsを作成します。
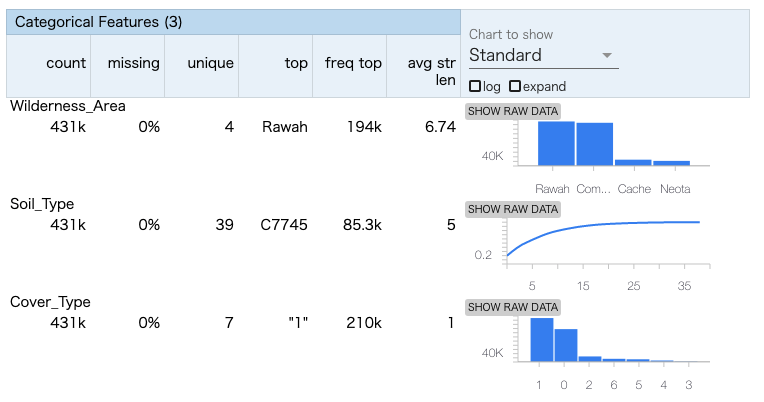
Cover_Typeがcategoricalとして扱われるようになりました。
まとめ
- サービング時のモデルの精度低下を引き起こすデータドリフトについて、その幾つかのパターンについての一般的な原因や対処法を調査した。
- スキーマスキューは、システム構成やデータ処理を工夫してある程度対策できる。
- 分布スキューは学習の工夫で抑制できる。問題によって適切なDistribution Shiftを仮定し、それに合った手法を選択する。
- GCPでデータドリフトを検知・対処する方法を調査した。
- GCPではVertexAI Model Monitoringで学習時とサービング時のデータのズレ(スキュー)や、時間経過に伴うデータの分布の変化(ドリフト)を検出し、アラートを出せる。
- VertexAI Model Monitoringは内部でTensorflow Data Validationを使用している。これは単体で使用してデータ群間のスキーマ・分布の差異を可視化したり、機械学習パイプラインに組み込むことで異常がある場合に学習を止めることもできる。
最後に
グループ研究開発本部 AI研究開発室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務などAI研究開発室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。皆さんのご応募をお待ちしています。
参考
Dive Into Deep Learning Chapter4.9
Google Cloud – Vertex AI – 特徴のスキューとドリフトをモニタリングする
Google Cloud – TensorFlow Data Validation によるトレーニング /
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD