2025.06.28
自作MCPサーバーでBigQueryを触る必要はないのに触ってみる
こんにちは、グループ研究開発本部・AI研究開発室のY. O.です。業務におけるLLMの活用範囲がどんどん増えてきています。生産性や価値創造を得る代償として、思考力・英語力・タイピング力を失っているような気もする今日この頃です。
筆者の業務でこれほどまでにLLMの活用範囲が拡大している背景として、LLM基盤モデルの進化もさることながら、LLMが各種外部ツールを利用できるような共通プロトコルであるMCP (Model Context Protcol)が整備されたことも非常に大きいです。
ということで今回は、MCPを自分で触ってみよう!うーんビジネスメンバでも聞き馴染みのあるBigQueryにしようかな!チャットベースでクエリ発行できたら嬉しいし!、ということでMCP × BigQueryを題材にすることにしました。が、自作のMCPでBigQueryを触りに行く必要は全く無いようです
TL;DR
- BigQueryを自作MCPで触りに行くデモはすぐに実装できる
- GCPはMCP Toolbox for Databasesという形でMCPをサポートする方針
- GCPはVertex AIを生成AI系サービスを触るエコシステムとし、既存ラインナップと深く連携させていくようだ
BigQuery × MCPサーバー
自作MCPサーバーの準備
LLM は直接BigQueryにSQLを投げられません。MCPサーバーをクッションとして、
- LLM(今回はClaude Code)からMCPサーバーへの「ツール呼び出し」要求が走る
- Claude CodeがSQLを作成し、BigQueryジョブを送信
- BigQueryから返却されるJSONの結果をClaude Codeが再構成し、最終回答を生成
という 3 段階で接続します。
Claude Code側でのMCP登録
- Claude CodeでMCPサーバーを準備する際、プロジェクト内でのみ有効となる設定を行うためには
.mcp.jsonという名称でファイルを作成する必要があります。~/.claude.jsonをいじってしまうと全てのプロジェクトに共通反映されてしまうので注意が必要です。
{
"mcpServers": {
"bigquery-server": {
"command": "uv",
"args": ["run", "python", "bigquery_mcp_server.py"],
"env": {}
}
}
}
自作BigQuery用MCPサーバーの作成
- pyproject.toml
[project]
version = "0.1.0"
requires-python = ">=3.10"
dependencies = [
"fastmcp>=2.9.2",
"google-adk>=1.5.0",
"google-cloud-bigquery>=3.25.0",
"mcp[cli]>=1.9.4",
"python-dotenv>=1.1.1",
]
- bigquery_mcp_server.py
import os
from typing import Any, Dict, Optional
from datetime import datetime
from dotenv import load_dotenv
from google.cloud import bigquery
from mcp.server.fastmcp import FastMCP
# 環境変数読み込み
load_dotenv()
# 設定
MAX_BYTES_BILLED = int(os.getenv("MAX_BYTES_BILLED", "1000000000"))
# MCPサーバー初期化
mcp = FastMCP("BigQuery MCP Server")
def get_bigquery_client() -> bigquery.Client:
return bigquery.Client()
@mcp.tool()
def dry_run_query(sql: str) -> Dict[str, Any]:
"""
SQLクエリのドライランを実行してコストを事前確認
"""
client = get_bigquery_client()
job_config = bigquery.QueryJobConfig(dry_run=True, use_query_cache=False)
job = client.query(sql, job_config=job_config)
bytes_processed = job.total_bytes_processed
cost_usd = (bytes_processed / (1024**4)) * 6.25
allowed = bytes_processed <= MAX_BYTES_BILLED
return {
"bytes_processed": bytes_processed,
"bytes_processed_gb": round(bytes_processed / (1024**3), 2),
"estimated_cost_usd": round(cost_usd, 4),
"max_bytes_allowed": MAX_BYTES_BILLED,
"allowed": allowed
}
@mcp.tool()
def execute_query(sql: str, limit: Optional[int] = None) -> Dict[str, Any]:
"""
SQLクエリを実行してデータを取得
"""
client = get_bigquery_client()
job_config = bigquery.QueryJobConfig(
maximum_bytes_billed=MAX_BYTES_BILLED,
use_query_cache=True
)
if limit and "LIMIT" not in sql.upper():
sql = f"{sql.rstrip(';')} LIMIT {limit}"
job = client.query(sql, job_config=job_config)
result_set = job.result()
rows = [dict(row) for row in result_set]
return {
"data": rows,
"total_rows": result_set.total_rows,
"returned_rows": len(rows),
"bytes_processed": job.total_bytes_processed
}
@mcp.tool()
def describe_table(table_id: str) -> Dict[str, Any]:
"""
テーブルのスキーマと詳細情報を取得
"""
client = get_bigquery_client()
table = client.get_table(table_id)
schema = [{
"name": field.name,
"type": field.field_type,
"mode": field.mode,
"description": field.description
} for field in table.schema]
return {
"table_id": table.table_id,
"dataset_id": table.dataset_id,
"project": table.project,
"num_rows": table.num_rows,
"num_bytes": table.num_bytes,
"schema": schema
}
if __name__ == "__main__":
mcp.run()
公式BigQuery MCPサーバーは存在しない
Googleは公式でMCPをサポートしていないと思います。そのため、GitHubでPython/TypeScriptでの実装が多く見られます。おおよそ「読み取り専用 + 最大スキャン量制限 + etc.」といった機能が実装されており、Claude Codeから十分使いやすいクオリティのように見えます(もちろん自己責任で利用)。
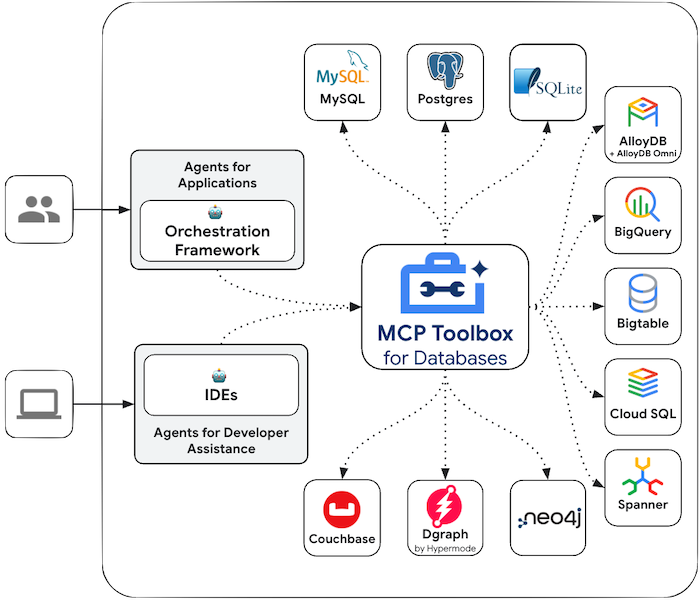
MCP Toolbox for Databases
MCP Toolbox for Databasesとは
先ほどGoogleは公式でMCPをサポートする気がなさそうという点に触れましたが、個別サービスごとへのMCPサーバーではなく、“全部のせ・シンプル”な一つの枠組みであるMCP Toolbox for DatabasesをOSS提供により、MCP化する方針のようです。
もともと、Gen AI Toolbox for Databasesとして2025/2/7にベータ版リリースされていた(https://cloud.google.com/blog/products/ai-machine-learning/announcing-gen-ai-toolbox-for-databases-get-started-today)のですが、このときはBigQueryはサポートされていませんでした。
2025/4/23のv0.4.0からBigQueryがサポートされるようになり、名称もMCP Toolbox for Databasesとなっています。
現状の利用方法としては、ユースケースに合わせて接続するサービスを指定し、Cloud Runにデプロイするということなのだと思いますが、利用が増えてきたらこのMCP Toolbox for Databases自体が新しいマネージドサービスになりそうな気もしますね。
Claude Code側でのMCP登録
上記の自作MCPサーバーでのデモと同様、Claude CodeでMCPサーバーとして利用できるようにするため、.mcp.jsonを編集していきます。
{
"mcpServers": {
"bigquery-toolbox": {
"command": "docker",
"args": [
"exec", "-i", "bigquery-toolbox",
"/toolbox", "--stdio", "--prebuilt", "bigquery"
],
"env": {}
}
}
}
MCP Toolbox for Databasesイメージの起動
MacbookでMCP Toolbox for DatabasesのDockerイメージを起動します。BigQueryへのクエリジョブを実行するために、.envファイルでPROJECT_IDとGOOGLE_APPLICATION_CREDENTIALSが設定されている必要がありました。
docker run -d --name bigquery-toolbox \ --platform linux/amd64 \ -p 2269:2269 \ --user $(id -u):$(id -g) \ --env-file .env \ -v $HOME/.config/gcloud:$HOME/.config/gcloud:ro \ -v /etc/passwd:/etc/passwd:ro \ -v /etc/group:/etc/group:ro \ -e HOME=$HOME \ us-central1-docker.pkg.dev/database-toolbox/toolbox/toolbox:latest \ /toolbox --prebuilt bigquery --port 2269 --address 0.0.0.0
考察
Vertex AIを生成AI系サービスの中心に
Google公式の単体サービスのMCPは無いことを見てきましたが、どういう世界を描いているのでしょうか。少しだけ考察して今回の記事を終えようと思います。
-
ロックインしたい(一貫した開発体験!)
- 単体MCPサーバーを公式化すると、他社LLMで簡単にBigQueryを直接利用できるようにしてしまう
-
Vertex AI系サービスがMCP Toolbox for Databasesを利用するようにしたい
- 技術的に価値が低い
-
自然言語でBigQueryを触りたい、だけであれば、Gemini in BigQueryがその役目を完遂している
-
基本的なモチベーションは上記の“一貫した開発体験”という部分にあると思います。
また、今回のブログでは取り扱いませんでしたが、GCPでAgenticなサービスを構築する際のファーストチョイスとしては、Vertex AI Agent Builderになるようです。これはGUIもしくは、yamlでの100行程度の設定でAgentをデプロイできるサービスです。
このサービスがファーストチョイスなのであればBigQueryにも簡単にアクセスできるような仕組みのはず…と思いましたが、このAgent BuilderがBigQueryにクエリを発行したい、といった場合は今回検証したようにMCP Toolbox for Databasesをどこかで起動しておく必要があります。やはり、MCP Toolbox for Databasesに、GCPサービスを利用するためのMCP周辺機能を吸収させるということには変わりはないようです。
さいごに
グループ研究開発本部 AI研究開発室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務などAI研究開発室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ募集職種一覧からご応募をお願いします。皆さんのご応募をお待ちしています。
参考資料
[1] https://github.com/modelcontextprotocol
[2] https://github.com/googleapis/genai-toolbox
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD