2019.04.16
Loading Data into Big Query with Cloud Functions and Dataflow
こんにちは、次世代システム研究室のN.M.です。
Use Case
You have application logs that you need to load into Google Big Query in a timely fashion. You could use command line Google Cloud tools to upload the files (gsutil cp), and then load the files into Big Query via the CLI (bq load), however you cannot be sure the file upload is complete when you run the load command unless you wait a long time. For big files of several GB this can stretch into hours.
Also, it is possible that the upload command will fail and in that case you will not wish to run the load command at all.
You may also need to massage the data, in which case you cannot just use a bq load command to upload the log file to Big Query. We will use an event driven approach, whereby the load only executes if and when the file is successfully uploaded, and this all happens inside Google Cloud. So when a log file is uploaded to a Google Cloud Storage bucket, data from the file is loaded into Big Query.
Approach
We will upload our data to GCS using gsutil cp but we will use a Cloud Function that is triggered whenever a file is uploaded to a specific bucket, the Cloud Function will then invoke our Dataflow Pipeline which will load the data into our target Big Query table.

Cloud Function
Our cloud function will be written in NodeJS 6 compatible Javascript. Google offers the following options for creating Cloud Functions: Node.js 6, Node.js 8, Node.js 10(beta), Python, Go Here is the code for our Cloud Function
const { google } = require('googleapis');
exports.myCloudFunction = function (event, callback) {
const PROJECT_ID = 'my-project-123456';
const DATASET_ID = 'test_dataset';
const STAGING_DIR = 'test-cloud-staging';
const file = event.data;
console.log(`file: `, file);
const filename = file.name;
let jobName = '';
console.log(`read gs://${file.bucket}/${filename}`);
let parameters = {};
let match = filename.match(/(\d{8})-\w+/);
if (match) {
// Get the date of the log
const date = match[1];
parameters.input = `gs://${file.bucket}/${filename}`;
parameters.output = `${PROJECT_ID}:${DATASET_ID}.mytable_${date}`;
jobName = `load-logs-${date}-${new Date().getTime()}`;
// Dataflow parameters
let data = {};
data.projectId = PROJECT_ID;
let resource = {};
resource.parameters = parameters;
resource.jobName = jobName;
resource.gcsPath = `gs://${STAGING_DIR}/template-staging/LoadLogTemplate`;
data.resource = resource;
console.log(`dataflow parameters: ${JSON.stringify(data)}`)
// call dataflow
google.auth.getApplicationDefault(function (err, authClient) {
if (err) {
throw err;
} if (authClient.createScopedRequired && authClient.createScopedRequired()) {
authClient = authClient.createScoped([
'https://www.googleapis.com/auth/cloud-platform',
'https://www.googleapis.com/auth/userinfo.email'
]);
}
const dataflow = google.dataflow({ version: 'v1b3', auth: authClient });
dataflow.projects.templates.create(data, function (err, response) {
if (err) {
console.error("problem running dataflow template, error was: ", err);
}
console.log("Dataflow template response: ", response);
if (typeof callback === 'function') {
callback();
}
});
});
} else {
console.log('not target file.');
if (typeof callback === 'function') {
callback();
}
}
};
First we set some basic configuration such as the project ID, target dataset in Big Query and the location of our Dataflow template. Dataflow templates are collections of code and resources necessary to run a Dataflow job in Google Cloud. These files are stored in Google Cloud Storage. In this sample we see they are stored at gs://test-cloud-staging/template-staging/LoadLogTemplate (from line 32).
We check if the filename matches an expected pattern at line 18. For the purposes of this sample, we are just using a simple pattern, but in production this would probably be more specific to match only certain types of logs. On line 46, we see the Dataflow template is called.
Dataflow Pipeline
Below is the code for our Dataflow Pipeline.
import java.io.ByteArrayInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.net.URL;
import java.nio.charset.StandardCharsets;
import com.google.api.client.util.Charsets;
import com.google.api.services.bigquery.model.TableRow;
import com.google.common.io.Resources;
import org.apache.beam.sdk.Pipeline;
import org.apache.beam.sdk.PipelineResult;
import org.apache.beam.sdk.coders.Coder;
import org.apache.beam.sdk.io.Compression;
import org.apache.beam.sdk.io.TextIO;
import org.apache.beam.sdk.io.gcp.bigquery.BigQueryIO;
import org.apache.beam.sdk.io.gcp.bigquery.TableRowJsonCoder;
import org.apache.beam.sdk.options.Description;
import org.apache.beam.sdk.options.PipelineOptions;
import org.apache.beam.sdk.options.PipelineOptionsFactory;
import org.apache.beam.sdk.options.ValueProvider;
import org.apache.beam.sdk.transforms.DoFn;
import org.apache.beam.sdk.transforms.ParDo;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public abstract class LoadLogs {
private static final Logger LOG = LoggerFactory.getLogger(LoadLogs.class);
public static interface LoadLogsOptions extends PipelineOptions {
@Description("Path of the file to read from")
ValueProvider<String> getInput();
void setInput(ValueProvider<String> value);
@Description("Path of the BigQuery table")
ValueProvider<String> getOutput();
void setOutput(ValueProvider<String> value);
}
static void main(String[] args) throws IOException {
LoadLogsOptions options = PipelineOptionsFactory.fromArgs(args).withValidation().as(LoadLogsOptions.class);
Pipeline p = Pipeline.create(options);
final String TABLE_SCHEMA = "your_table.schema";
String schema = getSchema(TABLE_SCHEMA);
p.apply(TextIO.read().from(options.getInput()))
.apply(ParDo.of(new JsonToTableRow()))
.apply(BigQueryIO.writeTableRows().to(options.getOutput()).withJsonSchema(schema)
.withWriteDisposition(BigQueryIO.Write.WriteDisposition.WRITE_APPEND)
.withCreateDisposition(BigQueryIO.Write.CreateDisposition.CREATE_IF_NEEDED));
PipelineResult result = p.run();
try {
result.waitUntilFinish();
} catch (UnsupportedOperationException e) {
// do nothing
} catch (Exception e) {
e.printStackTrace();
}
}
private static String getSchema(String schemaFileName) throws IOException {
URL url = Resources.getResource(schemaFileName);
return Resources.toString(url, Charsets.UTF_8);
}
/** Converts UTF8 encoded Json records to TableRow records. */
protected static class JsonToTableRow extends DoFn<String, TableRow> {
@ProcessElement
public void processElement(ProcessContext c) {
TableRow row;
String json = c.element();
// Parse the JSON into a {@link TableRow} object.
try (InputStream inputStream =
new ByteArrayInputStream(json.getBytes(StandardCharsets.UTF_8))) {
row = TableRowJsonCoder.of().decode(inputStream, Coder.Context.OUTER);
c.output(row);
} catch (IOException e) {
LOG.error("Failed to serialize json to table row: " + json, e);
}
}
}
}
Google Dataflow scripts use the Apache Beam API. Beam is short for ‘Batch and Stream’. The Beam API presents a unified processing model for batch jobs and Streaming programs. Lines 46 to 50 show the Apache Beam Pipeline in action. This is a sequence of apply steps, which apply a PTransform (Pipeline Transform) to a PCollection (Pipeline Collection). See here for a complete explanation of the Beam API.
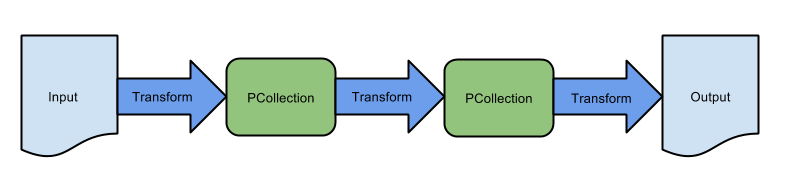
Lines 31 to 37, show how we can retrieve the parameters passed to the Dataflow from the Cloud Function. We use Apache Beam ValueProvider class. The use of the ValueProvider class allows us to refer to variables whose values are not known until runtime.
The core logic of the LoadLogs class is in the main method. We see here that we specify to create a table if necessary on line 50 and we specify the schema on line 45. The schema file name is ‘your_table.schema’, this is a file that should be placed in the Java resources directory, since we are accessing it via the Resources API. This schema file should be in the designated format for the BigQueryIO API, which is JSON containing an outer {“fields”:[]} element, vs the JSON format for the bq CLI which is just the inner [].
The purpose of the JsonToTableRow class is just to convert the incoming JSON records to a row format for Big Query. If you need to do additional data massaging you can also do that here.
Project Structure and Deployment
Your project structure should look something like this:
your-project/
├── cloud_function
│ ├── index.js
│ └── package.json
└── src
└── main
├── java
│ └── LoadLogs.java
└── resources
└── your_table.schema
package-lock.json specifies the dependencies and versions needed for your Cloud Function as shown below:
{
"name": "cloud_function",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"author": "Your name",
"license": "Your license",
"dependencies": {
"googleapis": "^28.1.0"
}
}
To deploy the Cloud Function a command similar to below should be used:
$ gcloud beta functions deploy myCloudFunction --stage-bucket cloud-fn-staging --trigger-resource log_load --trigger-event google.storage.object.finalize
When invoked from the cloud_function directory, this command will deploy myCloudFunction to the cloud-fn-staging GCS bucket and this will be invoked whenever a file is uploaded to log_load. The cloud-fn-staging bucket should be created before running the command.
To deploy the Java Dataflow template, use Maven or Gradle. If using Maven the deploy command would look similar to below:
mvn compile exec:java \ -Dexec.mainClass=LoadLogs \ -Dexec.args="--project=<your project> \ --stagingLocation=gs://test-cloud-staging \ --templateLocation=gs://test-cloud-staging/template-staging/LoadLogTemplate \ --runner=DataflowRunner"
Our Cloud Function expects the Dataflow Template to be located at gs://test-cloud-staging/template-staging/LoadLogTemplate, and the DataflowRunner will deploy our LoadLogs Dataflow as a template to that location.
Also note that we are using version 2.5.0 of the google dataflow API (com.google.cloud.dataflow’, name: ‘google-cloud-dataflow-java-sdk-all’, version: ‘2.5.0’)
Summary
We have shown how to implement near real time ingestion of application logs into Google Big Query.
Using this technique, we have experienced total data processing time for a compressed 10GB file, from upload to GCS until loading into Big Query, of under 20 minutes. This is a significant improvement on the gsutil cp and bq load approach first mentioned.
The sample source code shown was intentionally very simple to aid understanding, but of course there is much more functionality to the various API’s mentioned.
For example, multiple output tables are possible, it is also possible to decide on the output table and schema dynamically for each row to be ingested using the DynamicDestination API. Here is a good explanation of DynamicDestinations.
As mentioned data massaging is easy to implement. It’s also easy to upload compressed logs and uncompress them in the Dataflow template using the TextIO API withCompression method.
Here are more ideas on Dataflow use cases.
One of the best articles on this subject is Triggering Dataflow with Cloud Functions.
次世代システム研究室では、グループ全体のインテグレーションを支援してくれるアーキテクトを募集しています。インフラ設計、構築経験者の方、次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ募集職種一覧からご応募をお願いします。
皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD