2023.03.27
「投資可能 × 解釈可能」:投資ポートフォリオと資産評価モデル
こんにちは。次世代システム研究室のK.S.(女性、外国人)です。
お久しぶりです。
2022年の上半期には、カモにならないアルゴリズム取引の連載にて、「取引コストと戦略入門編と意思決定編」を書かせて頂きました。今年も引き続き金融AIの関連記事を書かせて頂こうかと思います。
が、勝手な想いで、2022年の相場を振り返ると、為替相場は大きく変動し、円安から円高まで、マーケットが急激に進んでいました。世界的なインフレがあり、米国の利上げを巡って株式市場が乱高下していました。こういう金融の非定常性を理解し、何が起こるのかを解釈したいと、もやもやしています。
ということで、今年はまず初めに「投資可能 × 解釈可能」の関連技術を探って、連載していきたいと思います。今回は関連する課題を解決できそうな技術の調査から入り、自分と似たような想いで解説している論文を紹介します。
著者は、機械学習モデルが銘柄選択に役に立つためには、投資可能、解釈可能、興味深い(investable, interpretable, and interesting)ではなければならないと主張しています。そこで、技術的に、本当に著者が主張通りに使えそうかを見ていきたいです。
用語が多いので、おまけに「用語集」を付けておきます。また、この論文で使った資産評価モデルを試してみた実装コードもおまけに入れておきます。
目次
1. 投資サイクル
はじめに、投資サイクルについて復習します。投資サイクルは4つのステップがあり、①資産管理、②ポートフォリオ構築、③取引実行、④投資のパーフォーマンス測定です。前回のブログは少し③と④を紹介しましたので、今回は①と②について中心に話したいです。
①資産管理では、アセットアロケーションによって、資金のリスクコントロールの範囲で、効率的なリターン(利益率)を考えた上で、資産(アセット)を配分(アロケーション)します。ここでは、定性的に経済の基礎的諸条件で選ぶことが多いですが、定量的に機械学習などでモデルを作ってバックテストし、利益が出そうな商品を選んで投資してみることもあります。これは、ブラックボックス的なモデルから安心に投資するため、なぜこの商品が選べたのかの解釈が欲しいです。これが説明ができないと、投資可能(investable)かどうかの判断が厳しいです。
②ポートフォリオ構築について、選んだふさわしい商品を資金内で組み合わせます。複数の投資対象の中から、収益性やリスクを考慮して、最適な投資比率を決定します。ポートフォリオを構築することで、単一の投資対象に比べて、リスクを分散させ、収益性を向上させることが期待できます。機械学習を利用してポートフォリオを構築する場合、一般的に、下記のような手順が行われます。
データの収集 → データの前処理 → 特徴量の選択 → 学習モデルの構築 → 最適化 → ポートフォリオの構築
ここで、構築したモデルがブラックボックスであることが問題視されることがよくあります。入力と出力の関係はわかっていますが、その内部の仕組みが複雑であり、解釈性が欠如してしまいます。構築したモデルがどのような要因に基づいて投資判断を行ったのかがわからないため、投資家はその判断に基づくリスクや収益性を正確に評価できない場合があります。つまり、解釈可能(interpretable)でないと、投資家が信頼できる情報を得ることにならず、投資可能(investable)かどうかも判断できません。
機械学習モデルの解釈性を高める手法は沢山あり、それほど新しい分野ではありません。よく聞かれる有名な手法は、「特徴量の重要度の可視化、SHAP(SHapley Additive exPlanations)値、LIME(Local Interpretable Model-agnostic Explanations)、グラフ理論」あたりだと思います。
しかしながら、金融業界では他の分野より、解釈性が強く求められていると言えますし、解釈したい目線も異なります。そこで、金融系のため、提案された解釈可能な手法も発展してきています。
それでは、今回は「②ポートフォリオ構築」を目的とし、「投資可能 × 解釈可能」論文を紹介します。
2. Investable and Interpretable Machine Learning for Equities論文の紹介
Investable and Interpretable Machine Learning for Equities論文のゴールは投資可能かつ解釈可能な機械学習を実現し、株式市場の将来のリターンを予測、役に立つポートフォリオを構築することです。「投資可能と解釈可能」の意図としては、①モデルが「投資可能」で、実際の投資家が使用できるような信頼性の高い結果を生成することが必要です。②モデルが「解釈可能」で、モデルがどのように予測を行い、どの要因が重要であるかを理解できることが必要です。
論文の関連技術は下記の図でまとめました。流れは一般的な機械学習フローですが、解釈(Interpretation)部分が強く注目されるのがポイントです。Prediction Inputsはデータ処理や特徴作成など、Modellingはいくつかの一般的に使われているモデルの比較、InterpretationはModel Fingerprintsという手法の適用、Prediction Targetはリターンの評価です。それでは、それぞれを説明していきます。
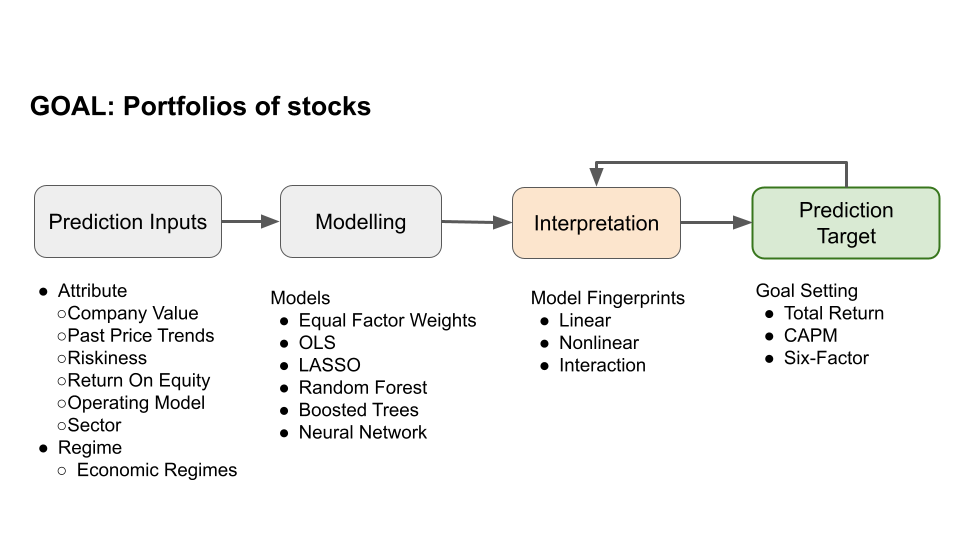
2.1. Prediction Inputs
データは1992年12月から2022年9月までの米国の株式市場 S&P500の銘柄で構成されています。注目は最も大きな株式市場の中で最も流動性が高く、取引しやすい証券でした。
予測変数(下記の図)は理論と直感に基づき検討したようです。「余談ですが、やっぱり直感が入ってしまうようです。直感だと、人間が解釈しやすいのでしょう」
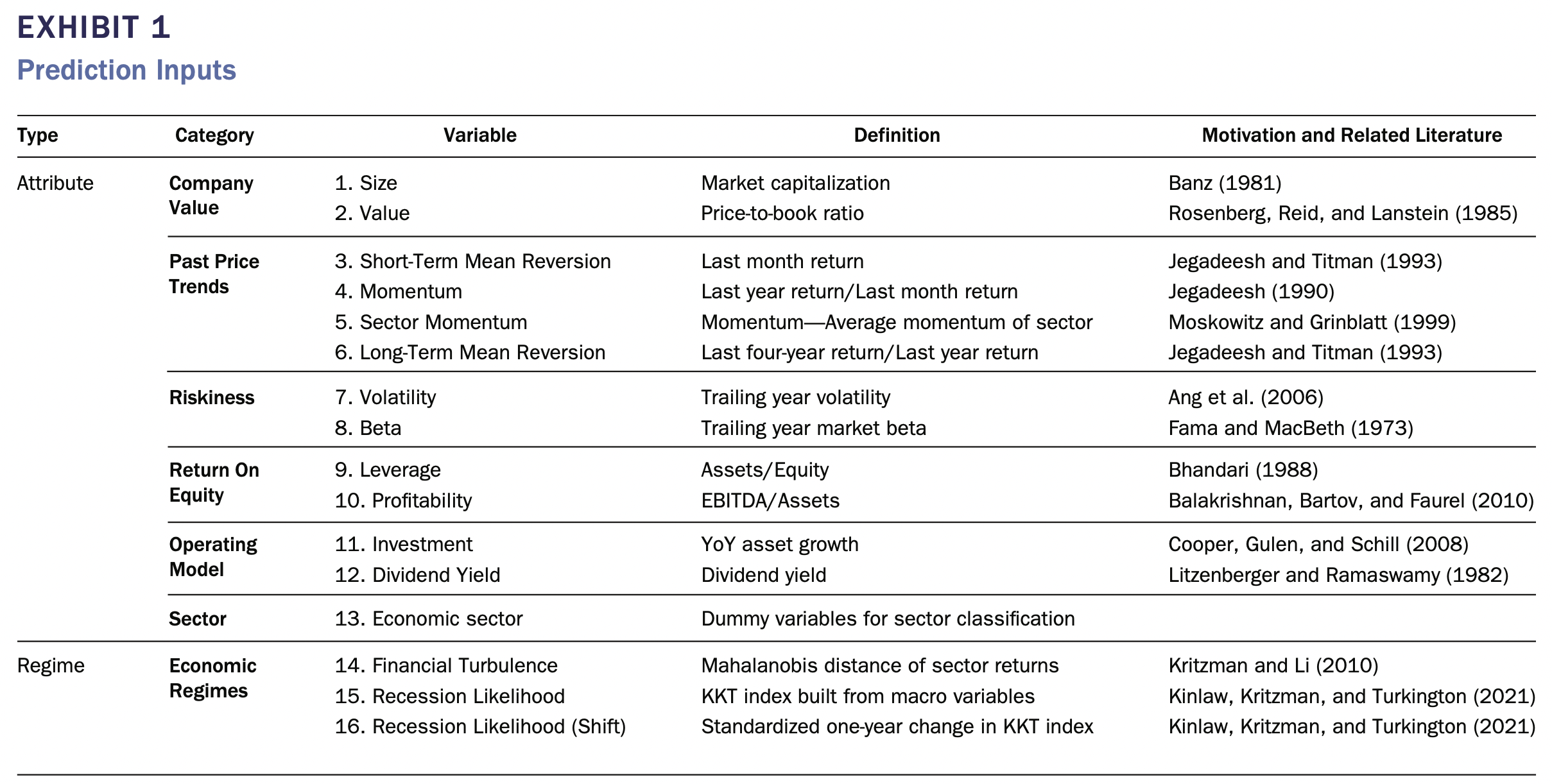
この図はInvestable and Interpretable Machine Learning for Equitiesより引用
予測変数は、2つのタイプに分類され、①毎月すべての企業について測定される企業レベルの属性(Attributes)と、②月に1回測定されるレジーム指標(Regime Indicators)です。証券属性はRefinitivのデータ、レジーム指標はState Street Global Marketsからのデータです。
2.2. Modelling
モデルは一般的に使われているモデルですので、詳細は省略しますが、使ったのは下記です。
- Equal factor weights
- Ordinary least squares (OLS) linear regression
- Least absolute shrinkage and selection operator (LASSO)
- Random forest
- Boosted trees
- Neural network
2.3. Interpretation
この論文では、機械学習モデルを解釈するため、2020年に提案されたModel Fingerprintというフレームワークを適用しました。この手法の詳細は次のブログを書きますので、楽しみにしていただければと思います。
手短に説明しますと、Model Fingerprintはモデル非依存(Model-Agnostic)なツール(モデルに依存しない説明手法)で、予測変数がグローバルレベルとローカルレベルの両方で予測がどのように貢献しているかのインサイトを提供します。Model Fingerprintは三つに分けられ、各変数の線形効果(Linear prediction effects)、各変数の非線形効果(Nonlinear prediction effects)、各変数のペアの相互作用効果(Pairwise interaction effect)です。
2.4. Prediction Target
基本モデルは各銘柄の翌月のトータルリターンを予測し、結果を示します。この論文は、いくつかのベンチマークとその目標超過リターン(target excess return)を紹介し、資本資産価格モデル(CAPM;Sharpe 1964)に加え、Fama and French(2015)の5ファクターにモメンタムを加えた6ファクターモデルも考慮されました。目標リターンは各銘柄の1年リターンを関連性ファクターのリターンに回帰させ、直近のデータポイントの超過リターンを記録することで作成されました。時間軸は1ヶ月から12ヶ月に調整されました。
「余談ですが、確かに、資産評価をするのに、単純なリターンでの評価のみより、CAPMやFama and Frenchのような一般的な線形モデルを使うと解釈しやすいと感じます。」
2.5. Results
このブログは論文の改善結果より、技術に応じてどういう見方が使えるのかを注目したいので、結果の雰囲気を紹介します。
なお、解釈可能という意図のもと、InterpretationのModel FingerprintとPrediction Targetの可視化結果を見せたいと考えます。
この論文はそれぞれの機械学習モデルの挙動を解釈するため、Model Fingerprint手法を使用しました。下記の図で示すように、同じデータで学習しても、各モデルが異なるルールを学習していることがわかります。どのモデルも完璧ではないので、多様性に価値が見られます。線形効果(Linear)はBoosted TressとNeural Networkでほぼ同じであり、ある程度の安心感があります。しかし、Boosted TressはMomentumとValue、およびその他の要因に大きく依存していることが見られますが、Random ForestはVolatilityとBetaに焦点を当て、全く異なります。また、Boosted Tressは最も非線形性(Nonlinear)が高く、Neural Networkは最も相互作用(Interactions)が強かったです。ここで、Regime Variablesは強い方向性を持つ効果がなく、主に属性の効果を条件づけることと言えそうです。
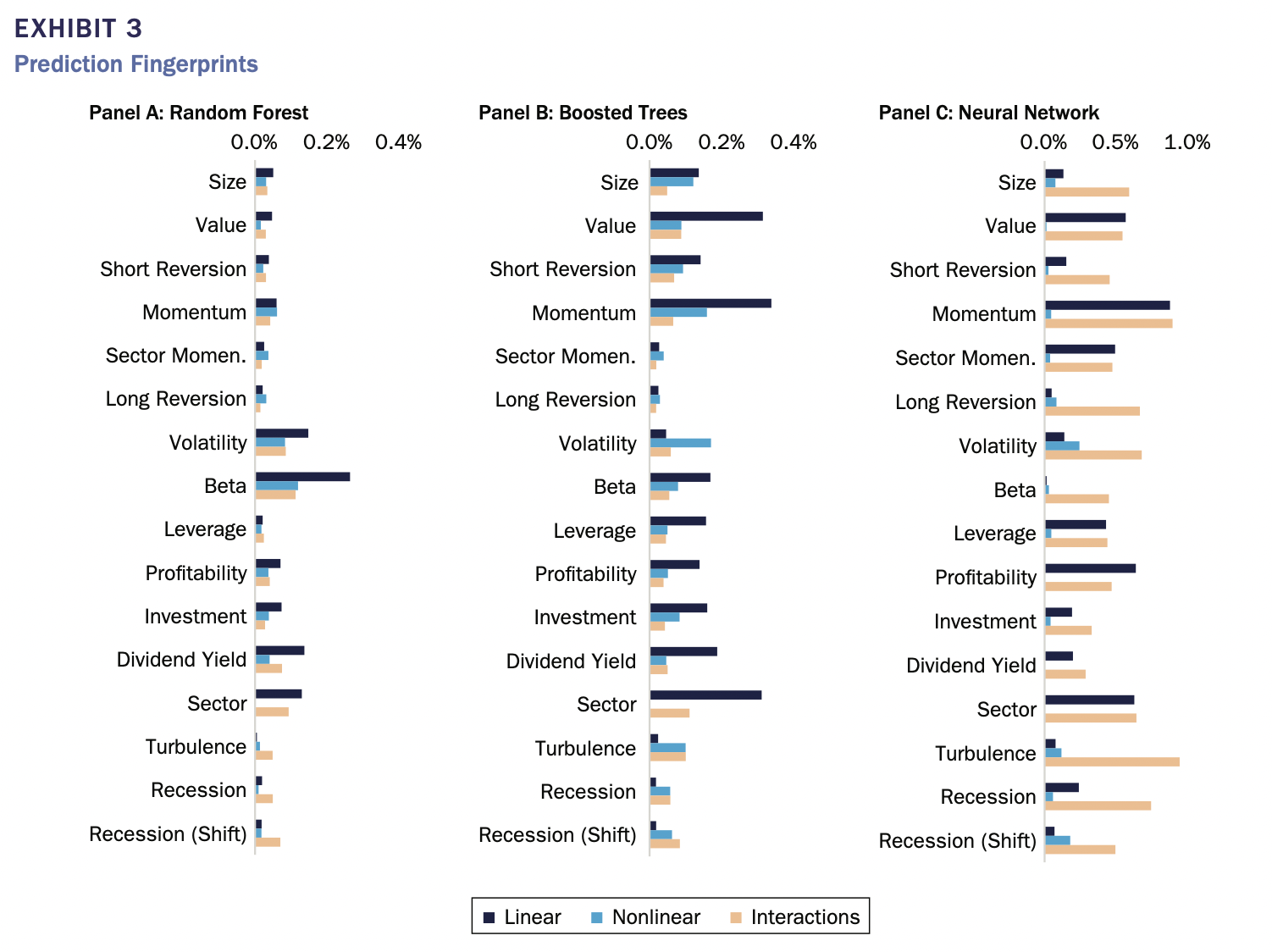
この図はInvestable and Interpretable Machine Learning for Equitiesより引用
Prediction Targetの結果について、下記の図は目標の組み合わせごとに、テストサンプルのReturn-to-Risk Ratiosを示したものです。各モデルのベンチマークとの相対評価になります。Total Returnは年率リターンを年率ボラティリティで割ったものとして算出されました。CAPMおよびSix-Factorは事後回帰適合ベンチマークを上回るリターンとボラティリティが算出されます。
12ヶ月のケースでは、若干異なるリバランスルールが導入されました。毎月のウェイトを完全に修正する代わりに、ポートフォリオの12分の1をローリングベースで修正する。この方法で、選択した各銘柄が1年間ポートフォリオに留まるようにすることで、保有期間と予測期間を一致させ、同時に月ごとに構成を徐々に変化させることが可能になりました。
Equal Factor WeightsはTotal ReturnやCAPM targetに対して緩やかなアウトパフォームが得られますが、Six-Factorがよくなりました。一方、機械学習モデルは、一貫して価値を高めているように見えます。しかし、機械学習の優位性の大きさは、他の多くの論文で報告されているものよりも小さいことが強調されています。著者が示した性能の大きさは、実装可能で解釈可能な戦略として現実的なものであることが書かれています。
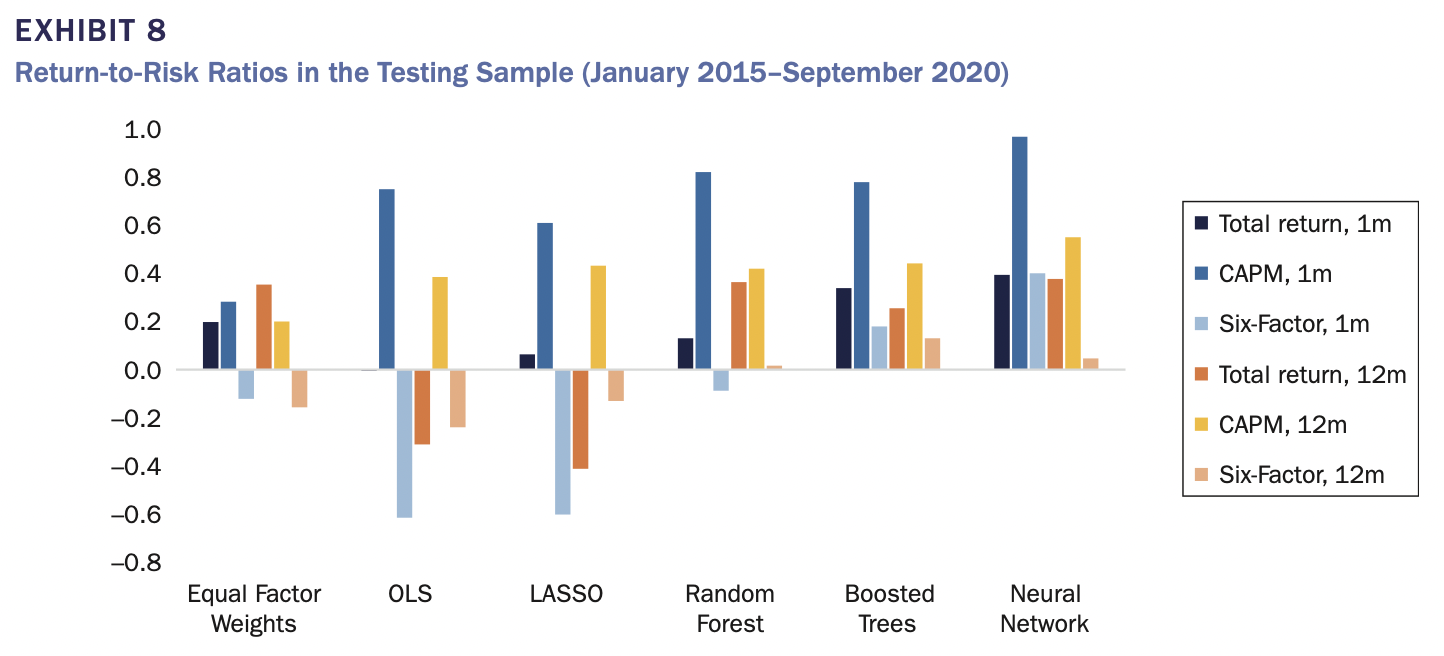
この図はInvestable and Interpretable Machine Learning for Equitiesより引用
3. おまけ
折角ですので、おまけに論文から検討された技術などを少し試してみたいと思います。まず、用語を紹介します。それから、CAPMやFama&Frenchモデルを説明します。最後に、この二つの評価モデルを実装します。
3.1. 用語集
特徴量に使われたPast Price TrendsのReversionとMomentum、RiskinessのVolatilityとBetaは、よく使われていますので、説明します。
- Reversion:市場から一時的に乖離した値動きが、遅かれ早かれ元の水準に戻る傾向があるという考え方です。これは、市場が過去の平均やトレンドラインから逸脱したときに、その逸脱が一時的であると仮定するものです。リバージョン戦略は、逸脱した価格が元の水準に戻ることを期待し、逸脱が検出された時点で逆張りのポジションを取ることで利益を得ようとする戦略です。
- Momentum:市場が一定期間において一定の方向に動く傾向があるという考え方です。モメンタム戦略は、過去の市場トレンドに従ってトレードし、価格が上昇傾向にある銘柄に買い、下落傾向にある銘柄に売りのポジションを取ることで利益を得ようとする戦略です。モメンタム投資家は、市場が上昇し続けている場合は買い、下落し続けている場合は売りをすることが多く、過去の株価変動のトレンドに注目して投資判断を行います。
- Volatility:金融市場における投資対象の価格変動の大きさや不安定性のことを指します。つまり、価格変動が激しく、予測しにくい状態を表します。
- Beta:金融市場において、特定の投資対象のリターンが、全体市場のリターンにどれだけ連動しているかを示す指標です。つまり、投資対象が全体市場とどの程度の相関性を持っているかを表します。
また、Return(リターン)は投資や資産運用において、投資家や運用者が得た集積や利益のことを指します。今回のブログで話しているのは期待リターンと超過リターンです。期待リターン(Expected return)は投資家が特定の資産又はポートフォリオから期待するリターンのことです。超過リターン(超過収益、Excess return)は投資した商品の収益率が運用の目標とするベンチマークをどのくらい上回ったかを示します。超過リターンは資産やポートフォリオの実際のパフォーマンスを評価するために利用されます。一方、期待リターンは投資家が将来のリターンを予測するために利用され、適切な投資決定を下すための重要な要素です。
3.2. Factor model
Factor Modelは資産のリターンが共有要因(factor)によって、決定されるモデルです。式は下記のように表せます。
$$ R_{i} = \alpha _{i}+\beta _{1i}f_{1}+\beta _{2i}f_{2}+\beta _{3i}f_{3}+…+\beta _{ki}f_{k}+\varepsilon _{i} $$
\( R_{i} \)は資産\( i \)のリターン、\( \alpha \)は定数、\( \beta_{ki} \)は資産\( i \)のfactor\( k \)の係数、\( f_{k} \)はfactorで確率変数で全ての資産に影響を与える要因、\( \varepsilon _{i} \)は資産特有の変動です。
factorは利用目的によって、異なります。例えば、市場全体の変動だけと考えるときに、CAPMがよく使われているし、複数のfactorsを考える時に、Fama-French three-factor modelやfive-factor modelがよく適用されます。
3.3. Capital Asset Pricing Model
The Capital Asset Pricing Model(CAPM)は投資家がどのように資産を評価するかを示す経済学的モデルです。CAPMはリスクに対する適正なリターンを計算するために使用され、Single Factor Modelとも呼ばれています。下記のような式で表せます。
$$ R_{it} = R_{Ft} + \beta _{i}(R_{Mt}-R_{Ft}) $$
\( R_{it} \)は \( t \)時刻におけるポートフォリオ\( i \)の期待リターン(expected return)、\( R_{Ft} \)は リスクフリーレート、\( R_{Mt} \)は市場の全体のリターン、\( \beta _{i} \)個別株式が持つリスクです。
CAPMの計算は下記になります。
- リスクフリーレート(Risk Free Rate)の決定
- マーケットリターン(Market Return)の決定
- ベータ値(\( \beta \))の計算
- 適正なリターンの計算
例えば、ある株式のベータ値が1.2で、リスクフリーレートが4%、市場の全体のリターンが9%である場合、適正なリターンは 「4% + 1.2 × (9% – 4%) = 10%」です。
3.4. Fama-French five factor plus momentum model
Fama-French three factorモデルはリターンの変動に、マーケットリスク(Market Risk)、企業希望の差(Size of firms)、簿価時価比率(Price to Book Ratio)の要因を加えたモデルです。Fama-French five factor モデルはFama-French three factorモデルに収益性(Profitability)と投資(Investment)の要因に加えたモデルです。さらに、Fama-French five factor plus momentumモデルはFama-French five factor モデルにmomentumを加えたモデルです。下記になります。
$$ R_{it} = R_{Ft} + \beta _{i}(R_{Mt}-R_{Ft})+s_{i}SMB_{t}+h_{i}HML_{t}+r_{i}RMW_{t}+c_{i}CMA_{t}+m_{i}MOM_{t}+\varepsilon _{it} $$
CAPMと同じく\( R_{it} \)は \( t \)時刻におけるポートフォリオ\( i \)の期待リターン(expected return)、\( R_{Ft} \)は リスクフリーレート、\( R_{Mt} \)は市場の全体のリターン、\( \beta _{i} \)個別株式が持つリスクです。さらに、Fama-French five factorに4つの項が加えられます。
- \( s_{i}SMB_{t} \)はSmall Minus Big「時価総格(Size)」で、企業の時価総額に基づく小規模企業と大規模企業間のリターンの広がりを説明するものです。小企業が大企業をアウトパフォームする傾向があることから、「小企業効果」と呼ばれます。また、「小企業は最大企業よりも成長機会の量が多いと言われている」とも言われています。また、小規模な会社は、より不安定なビジネスを行う傾向があり、より高い収益を期待できると思われます。
- \( h_{i}HML_{t} \)はHigh Minus Low「価値(Value)」で、バリュー株とグロース株のリターンの差を説明するものです。簿価の低い企業(グロース株)が、簿価の高い企業(バリュー株)をアンダーパフォームすることを意味します。このリターンの増加より、リスクとリターンの関係を直接的に適用されています。
- \( r_{i}RMW_{t} \)はRobust Minus Weak「収益率(Profitability)」で、堅牢と弱い収益性の差を説明するものです。収益性は収益から売上原価、販売費・一般管理費、支払利息のすべてを簿価純資産で割ったものです。自己資本利益率(ROE)が高いところから、低いところを引いた値です。
- \( c_{i}CMA_{t} \)はConservative Minus Aggressive「投資(Investment)」で、投資方針の低い企業と高い企業のリターンの差を説明するものです。保守的な企業とは、投資方針が低い企業で、積極的な企業はより高い投資度合いを示します。投資率は、有形固定資産の年間変動額と棚卸資産の年間変動額のすべてを総資産の簿価で除したものです。
最後に、\( m_{i}MOM_{t} \)はMomentumの要素です。
3.5 実装で試してみた
それでは、試してみます。
実装環境
環境はGoogle Colaboratoryを利用しました。
データセット
商品の時系列データはyfinance libraryから取得し、factorsの値はgetFamaFrenchFactors libraryから、ダウンロードしました。
import yfinance as yf
start = '2000-01-01'
end = '2022-12-31'
stock_list = ['MUFG', 'SONY', 'TM', '1808.T', '7832.T', '9001.T',
'^GSPC', '^TNX']
rename_dict = {'TM': 'Toyota', '1808.T':'Haseko',
'7832.T': 'Bandai', '9001.T': 'Tobu',
'^GSPC': 'S&P500', '^TNX': "Treasury"}
stock_dfs = pd.DataFrame()
for stock in stock_list:
stock_dfs[stock] = yf.download(str(stock), start, end)["Adj Close"]
stock_dfs.reset_index(inplace=True)
stock_dfs.rename(columns=rename_dict, inplace=True)
stock_dfs.head()
# plot
fig, axs = plt.subplots(figsize=(15,10), ncols=3, nrows=math.ceil(len(stock_dfs.columns[1:])/3))
for ax, col in zip(axs.flatten(), stock_dfs.columns[1:]):
ax.plot(stock_dfs['Date'], stock_dfs[col])
ax.set_title(col)
plt.tight_layout()
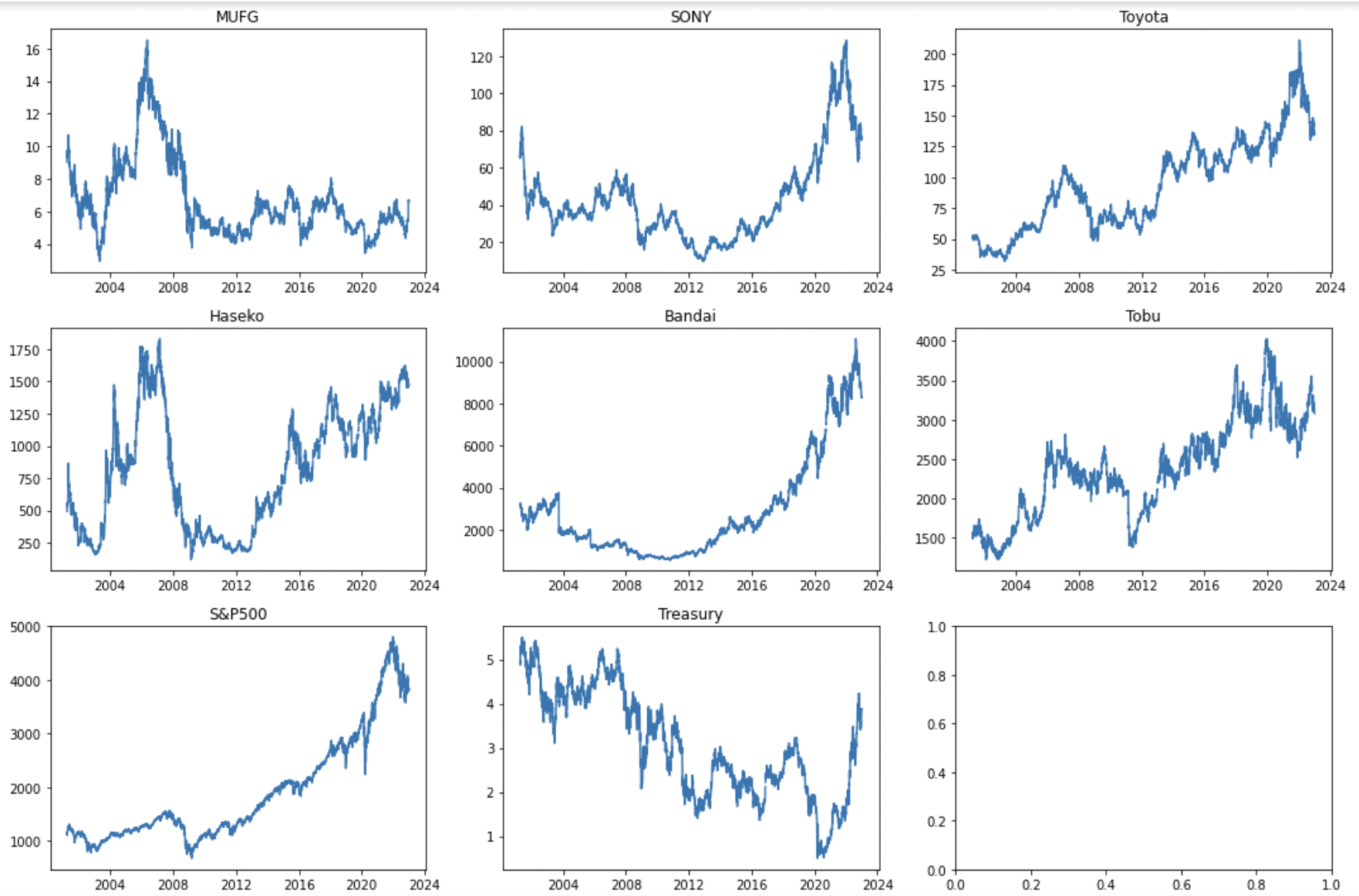
データ処理
簡単に月ごとのプライスリターンを計算します。
# total return
stock_returns_dfs = stock_dfs.set_index("Date").resample('M').last().pct_change().dropna()
stock_returns_dfs.head()
factor取得
Kenneth French libraryから、Fama French factorsを取得することが可能ですので、それを使います。
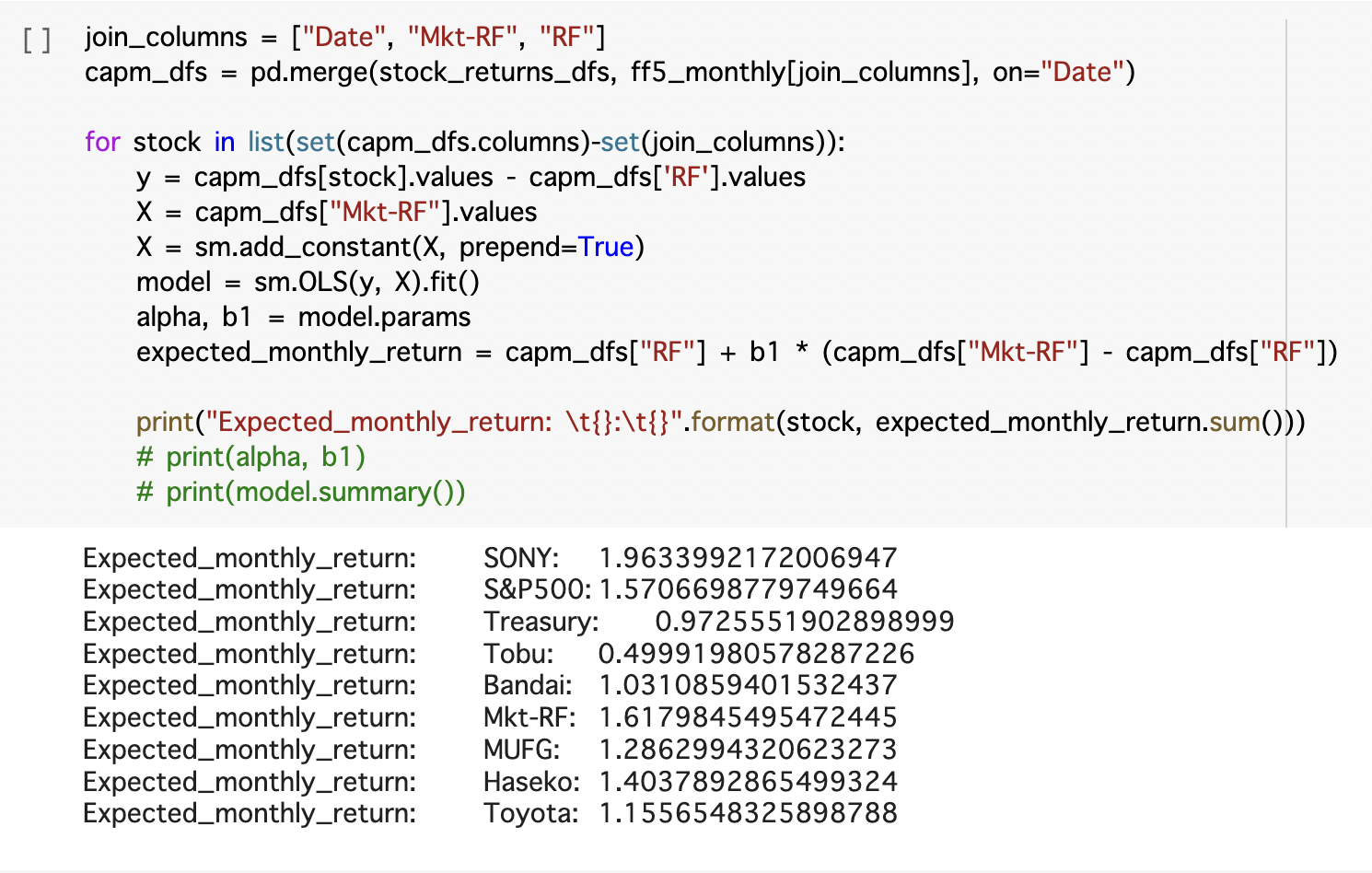
CAPM実装
いくつかの銘柄でCAPMモデルを使って適正なリターンを計算します。上記で説明したように、まず、リスクフリーレートとマーケットリターンの値を決定することが必要です。今回はKenneth French libraryから取得したfactors値をそのまま使いました。それから、線形モデルで、ベータ値を計算し、銘柄ごとの適正なリターンを計算します。イメージは下記のようにコードになります。ところで、見せたいのは実装の雰囲気だけで、データ処理やモデリングは適当なため、計算結果は参考にしないでください。
Fama-French five factor model実装
いくつかの銘柄でFama-French five factorモデルを使って適正なリターンを計算します。CAPMモデルと同じようなやり方で、factorsの要因が増えただけです。
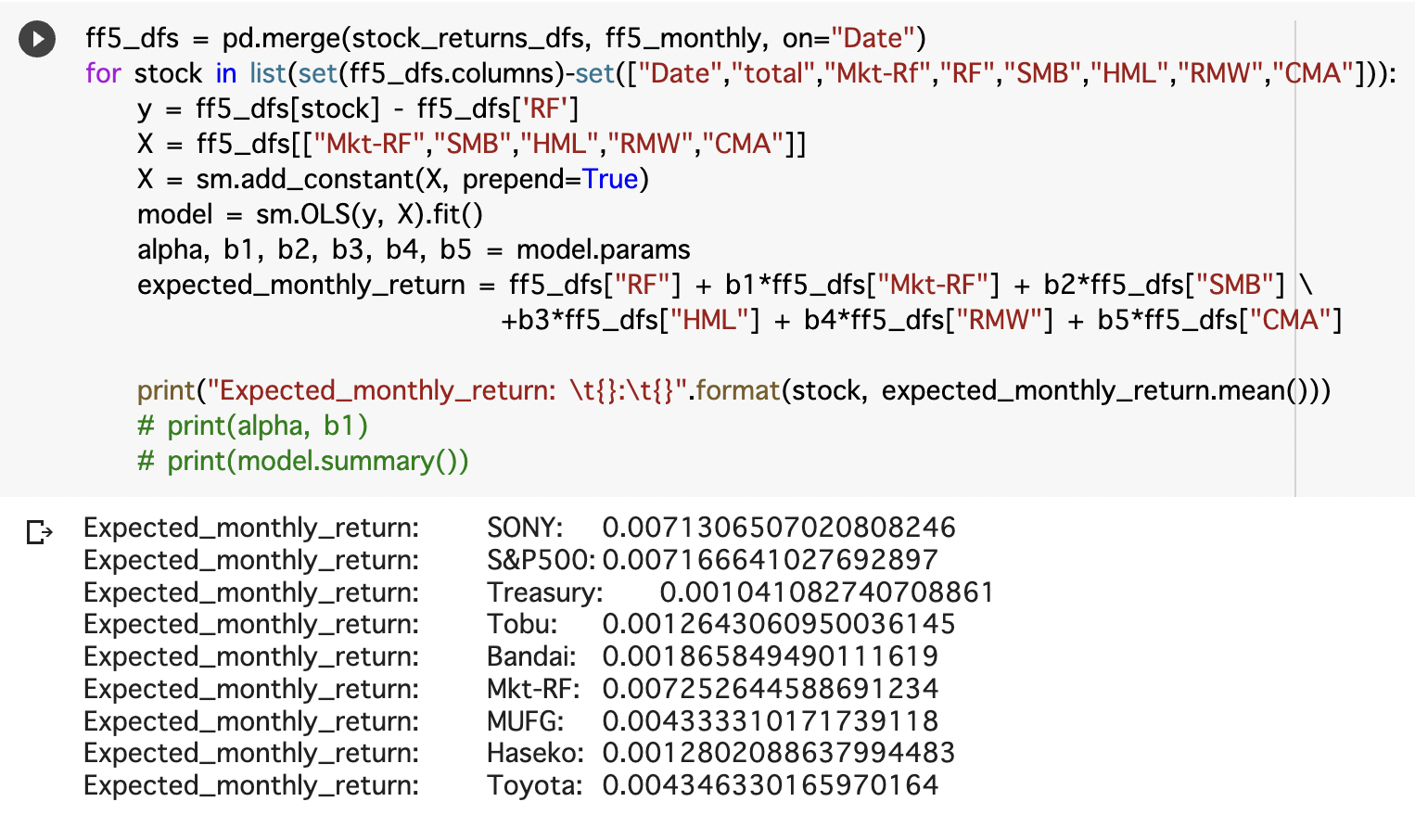
4. まとめと考察
今回は「投資可能 × 解釈可能」の関連技術を調査し、Investable and Interpretable Machine Learning for Equities論文を紹介しました。また、論文で使った資産評価モデルを試してみました。
最後に
グループ研究開発本部 AI研究開発室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務などAI研究開発室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧からご応募をお願いします。皆さんのご応募をお待ちしています。
一緒に勉強しながら楽しく働きたい方のご応募をお待ちしております。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD





