2025.04.07
GPT-4 APIを使ったダークパターン検出実験:Zero-shotからOne-shotまで
こんにちは、AI研究開発室のS.Y.です。
「webサイトのダークパターンをgpt-4oで検出してみる」という実験をしてみました。
結論ファースト
- GPT-4にスクリーンショット画像とテキスト情報を併せて入力することで、UI/UXの視覚的特徴と文脈を同時に把握しやすくなる
- ただしダークパターンの定義自体が抽象的な場合もあり、カテゴリ説明や具体的事例があるほどモデルの理解が明確になる
はじめに
近年、「ダークパターン」と呼ばれるユーザーを意図しない方向に誘導するUI/UXデザインが社会的な問題として注目を集めています。インターネット上での広告やECサイト、各種アプリケーションなど、多くの場面で見かけるようになりました。たとえば、解約ボタンが極端に見つけづらい場所に配置されているサブスクリプションページや、利用規約への同意を取りやすくするための紛らわしいボタン配置などが典型例です。
ユーザー体験を損ないかねないこうしたダークパターンを排除する動きは、年々大きくなっています。一部の国や地域では法的規制が検討されるなど、社会全体として対策の必要性が高まっている状況です。
本記事では、このダークパターンを大規模言語モデル(GPT-4)で自動検出できるかを実験的に試した取り組みについて紹介します。具体的には、スクリーンショットから抽出したテキストや補足情報をGPT-4に入力し、どのダークパターンに当てはまるかを分類させました。また、「ゼロショット学習」から「ワンショット学習」へ、どの程度プロンプトを工夫すれば精度が向上するのかを検証しています。
以下のセクションでは、ダークパターンの概要を簡単におさらいした上で、使用したデータセットやGPT-4による実験手法、得られた結果について詳しく見ていきます。
ダークパターンとは
ダークパターンの定義
ダークパターンは、ユーザーを本来望まない行動へと誘導するためのデザイン手法の総称です。UI/UXの配置や文言の微妙な差異を利用して、ユーザーが気づかないうちに有料のオプションに加入させたり、個人情報を過剰に取得したりするケースが典型的です。
社会的インパクト
一時的にはコンバージョン率を高めるなどの効果があるかもしれませんが、長期的にはユーザーからの信頼を損なうリスクが大きいと指摘されています。SNSやニュースサイトでもダークパターンの事例が取り上げられ、ユーザーの間でも問題意識が高まりつつあります。今後は法的規制や業界の自主ルール制定が一層進むと見込まれます。
実験概要
実験の目的
下記の検証です。
- Zero-shot学習でもある程度分類が可能なのか
- カテゴリの定義や簡易説明を追加すれば、どの程度精度が上がるのか
- 実例を提示するOne-shot学習でさらなる精度向上が見込めるか
使用データ: contextDP
本実験では、「contextDP」というデータセットを使用しました。
contextDP は、UI(ユーザインタフェース)上に現れるダークパターンを体系的に収集し、各パターンの位置を詳細にアノテーションした大規模データセットです。元論文では、モバイルアプリやウェブサイトから集めた数百枚規模のスクリーンショットを対象に、10種類のダークパターンを網羅的にラベリングしています。これにより、「どの画面のどの部分がダークパターンなのか」を、研究者や開発者が直接確認しやすい形で整理しているのが大きな特徴です。
本実験ではWebサイトに絞り、7種類のダークパターン+負例の、合計8ラベルを取り扱います。
扱うパターンは以下の通りです。
category_definitions = {
"ACTIVITY MESSAGE": "他のユーザーの活動を表示して、急がなければならないように思わせる",
"COUNTDOWN TIMER": "制限時間があるように見せかけて急がせる",
"LIMITED TIME MESSAGE": "時間的に制限されているかのように見せる表現",
"LOW STOCK MESSAGE": "在庫が少ないと表示して購入を急がせる",
"HIGH DEMAND MESSAGE": "需要が高くてすぐ売り切れるかのようなメッセージ",
"DEFAULT CHOICE": "初期状態でユーザーに不利な選択肢が選ばれている",
"ATTENTION DISTRACTION": "注意をそらすようなデザイン・要素",
}
GPT-4のマルチモーダル入力
GPT-4が提供するマルチモーダル機能を利用し、実際のスクリーンショット画像とその補足情報(テキスト)を同時にモデルへ入力しました。これにより、モデルがビジュアルレイアウトと文字情報の両方から判断を下せるようにしています。
GPT-4の出力
モデルはマルチラベリングタスクを行い、入力のスクリーンショットに対して1つ以上のラベルを割り当てます。
実験方法
ダークパターンを判定させるにあたって、以下3パターンのプロンプトを用意しました。いずれも「スクリーンショット画像」+「テキスト説明」をGPT-4に提供し、そこからモデルにカテゴリーを回答させます。
- Zero-shot learning (パターン①:カテゴリ名のみ
- ダークパターン8クラス(7種類+negative)のカテゴリ名だけを提示し、「画像を見たうえで、どのカテゴリに該当しますか?」と質問。モデルが持つ事前知識に依存し、どこまで正しく判定できるかを確認。
- Zero-shot learning (パターン②:カテゴリ名+説明)
- カテゴリ名と各カテゴリの説明を最初にまとめて提示した上で、「画像を見たうえで、どのカテゴリに該当しますか?」と質問。カテゴリ定義を明示することで、モデルの理解度がどう変化するかを検証。
- One-shot learning (パターン③:カテゴリ名+説明+実例)
- カテゴリ名と説明に加え、各カテゴリに対応する実際のスクリーンショットのサンプル1件を提示。具体例を提示することで、モデルがビジュアル含めた共通点を学習しやすくなるかを検証。
実験結果
精度の比較
今回の実験では、以下3つの手法を比較しました。
- Exp #1: Zero-shot学習(カテゴリ名のみ)
- Exp #2: Zero-shot学習+カテゴリ説明
- Exp #3: One-shot学習(カテゴリ名+説明+実例)
それぞれの手法で得られたOverall Metrics(Precision / Recall / F1)は次の通りです。
| Experiment | Precision | Recall | F1 |
|---|---|---|---|
| #1 | 0.5238 | 0.6011 | 0.5598 |
| #2 | 0.6142 | 0.6612 | 0.6368 |
| #3 | 0.7614 | 0.7322 | 0.7465 |
- Exp #1はPrecisionが約0.52、Recallが約0.60、F1スコアが0.56
- Exp #2では説明を追加したことで、3指標すべてが向上(F1=0.64程度)
- Exp #3は実例まで提示するOne-shot学習により、F1が0.75近くまで上昇
このように、Exp #3 > Exp #2 > Exp #1 の順で精度が向上していることがわかりました。これは、GPT-4が事前知識だけでなく、明示的な説明や具体的な例を与えられるほど、その推論がより正確になる傾向を示しています。
カテゴリ別の精度
さらに、各ダークパターンのカテゴリごとにPrecision / Recall / F1を算出した結果が下表です。
| Category | Exp #1 P | Exp #1 R | Exp #1 F | Exp #2 P | Exp #2 R | Exp #2 F | Exp #3 P | Exp #3 R | Exp #3 F |
|---|---|---|---|---|---|---|---|---|---|
| ACTIVITY MESSAGE | 0.50 | 0.10 | 0.17 | 0.60 | 0.60 | 0.60 | 0.58 | 0.70 | 0.64 |
| ATTENTION DISTRACTION | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| COUNTDOWN TIMER | 0.77 | 0.96 | 0.86 | 0.74 | 1.00 | 0.85 | 0.79 | 0.93 | 0.85 |
| DEFAULT CHOICE | 0.37 | 0.25 | 0.30 | 0.25 | 0.17 | 0.20 | 0.78 | 0.58 | 0.67 |
| HIGH DEMAND MESSAGE | 0.26 | 1.00 | 0.42 | 0.25 | 1.00 | 0.40 | 0.71 | 1.00 | 0.83 |
| LIMITED TIME MESSAGE | 0.30 | 0.92 | 0.45 | 0.41 | 0.73 | 0.53 | 0.52 | 0.62 | 0.56 |
| LOW STOCK MESSAGE | 0.56 | 0.95 | 0.71 | 0.65 | 0.89 | 0.76 | 0.67 | 0.95 | 0.78 |
| NO DP | 0.97 | 0.41 | 0.57 | 0.90 | 0.56 | 0.69 | 1.00 | 0.70 | 0.82 |
- COUNTDOWN TIMER や LOW STOCK MESSAGE などのカテゴリは、いずれの実験でも比較的高いRecallを示しており、認識しやすい特徴を持つ可能性がある
- ATTENTION DISTRACTION は全体的にPrecision / Recallともに低く、推定が難しいか、そもそもサンプルが少ないことも考えられる
- DEFAULT CHOICE のように、「Exp #3」でPrecisionが大幅に向上しているカテゴリもある
このように、カテゴリごとの難易度や、One-shot学習による精度向上の度合いが分かりやすく現れています。
考察
zero-shotの時点で精度が高いカテゴリ
COUNTDOWN TIMER、LOW STOCK MESSAGEはzero-shotの時点で精度が高いです。カテゴリ名だけで、それが言わんとしているイメージを事前知識のみでマッピングできていると言えそうです。
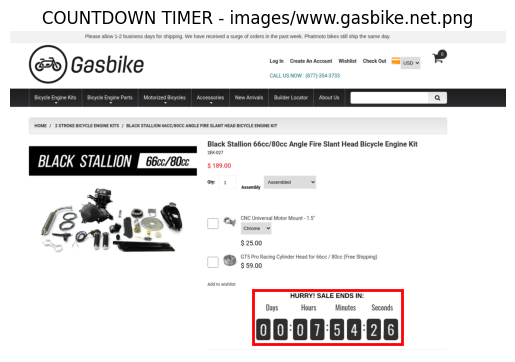
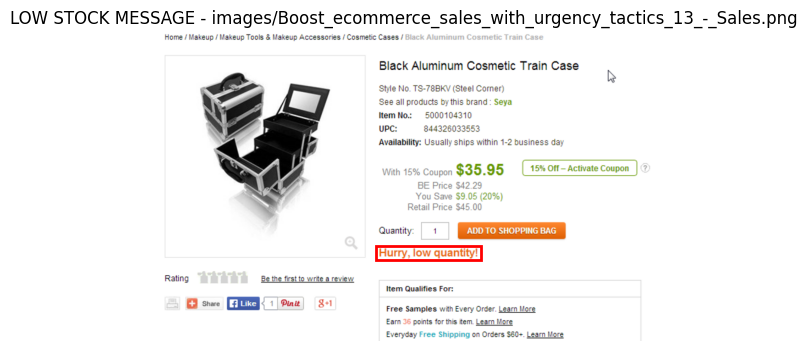
確かに、カテゴリ名だけでどんなビューになりそうなのか、だいたい推論できそうですね。
zero-shot + カテゴリ説明で精度が向上したカテゴリ
ACTIVITY MESSAGEはzero-shotに加えてカテゴリの説明をプロンプトで与えることで精度が向上しました。
{ "ACTIVITY MESSAGE": "他のユーザーの活動を表示して、急がなければならないように思わせる" }
モデルはACTIVITY MESSAGEの事前知識はあまり持っていないが、説明されればイメージとマッピングさせられるようです。
確かに人の場合でも、ダークパターンのドメインに明るくない場合(筆者含む)は、ACTIVITY MESSAGEと言われても「???」となるが、「他のユーザーの活動を表示して、急がなければならないように思わせるUI」と言われれば、下記のようなIUを想像できるのではないでしょうか。
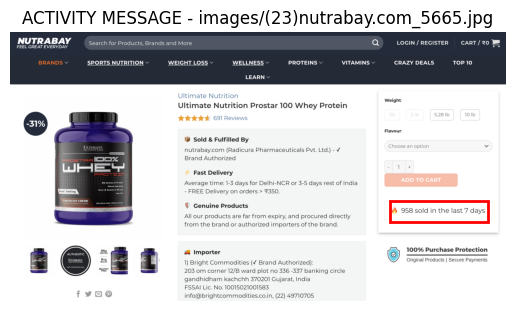
one-shotで精度が向上したカテゴリ
DEFAULT CHOICEは、one-shot learningにすると精度が大きく向上しました。
このカテゴリは解釈がかなり広く、簡単な説明だけでは理解するのは難しいように思われます。
{ "DEFAULT CHOICE": "初期状態でユーザーに不利な選択肢が選ばれている" }
この説明だと「”メールを受け取る”に最初からチェックが入っている」のようなパターンは想像できるかもしれませんが、実は下記もDEFAULT CHOICEです。
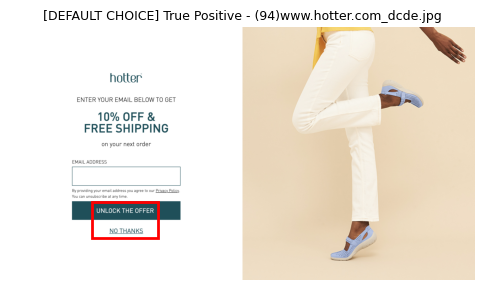
赤いbbox部分がその根拠で、「メールアドレスを入力してUNLOCK THE OFFERを選ぶ」というのがさも当然のようなUI設計になっています。
これについてはおそらく人間もモデルも、具体例を見せられてようやく識別パターンを構築できるような例でしょうし、one-shot learningで精度が向上するのは納得感があります。
全体的に精度が低いカテゴリ
ATTENTION DISTRACTIONは全体で正解0でボロボロですね。。
category_definitions = { "ATTENTION DISTRACTION": "注意をそらすようなデザイン・要素" }
このカテゴリを当てるのが難しいのには2つ理由があると考えています。
一つ目はカテゴリ説明がかなり抽象的なこと、二つ目はATTENTION DISTRACTIONとDEFAULT CHOICEのground truthがほぼ同一なことです。
二つ目がどういうことかというと、実はcontextDPのwebサンプルには、ATTENTION DISTRACTION単体がラベリングされているものはなく、全てDEFAULT CHOICEとの抱き合わせとなっていました。BBOXもATTENTION DISTRACTIONとDEFAULT CHOICEとでほぼ同じ領域となっていて、「あるUI設計が、どちらのカテゴリにも該当する」という状況でした。
実際、ground truthが[“ATTENTION DISTRACTION”, “DEFAULT CHOICE”]のサンプルは、[“DEFAULT CHOICE”]とラベリングされていていました。
これについてはプロンプトで、「ATTENTION DISTRACTIONとDEFAULT CHOICEは同じ設計に現れやすい」のような情報を加えてやると、精度が改善するかもしれません。
まとめ
結果の要約
- ゼロショットのみより、カテゴリの定義と実例まで提供したOne-shot学習が明確に高精度
- カテゴリによっては精度の向上幅が大きく、モデルが例示を取り込む効果が顕著
今後の可能性
- 言語モデルは与えるcontextをリッチにするとタスクの確度が上がりやすいことが知られているので、下記のような工夫でさらに精度が上がるかもしれません。
- few-shotにしてカテゴリ内で代表的なサンプルをいくつか見せるようにする。
- N-shotの際に、なぜその画像がそのパターンなのかもプロンプトに含める。
社会的にもダークパターン対策の重要性が増すなか、大規模言語モデルによるUI検証は有力なアプローチとなり得ます。今回の結果を足がかりに、より幅広いデータを用いた検証や、サービスへの組み込みに向けた取り組みに繋げられたら面白いなと思います。
付録
one-shotするコード
import re
def extract_labels_from_gpt_output(text, expected_categories):
"""
GPT出力からカテゴリ名のリストを抽出する(JSON形式 or 自然文サーチ)
"""
# 1. JSON形式を探してパース
match = re.search(r"\[[\s\S]*?\]", text)
if match:
json_str = match.group()
try:
return json.loads(json_str)
except json.JSONDecodeError:
print("⚠️ JSONが壊れています")
print("🔍 抽出された部分:\n", json_str)
# 2. JSONでないなら自然文からカテゴリ名をサーチ
print("🔍 自然文からカテゴリ名を抽出します")
found = []
for cat in expected_categories:
if cat in text:
found.append(cat)
return found
def ask_gpt4_one_shot(
target_image_path: str,
example_image_label_pairs: list,
category_definitions: dict,
client
):
prompt = build_prompt_with_examples(category_definitions, example_image_label_pairs)
categories = list(category_definitions.keys())
messages = [{
"role": "user",
"content": [{"type": "text", "text": prompt}]
}]
for example_path, label in example_image_label_pairs:
base64_example = encode_image(example_path)
messages.append({
"role": "user",
"content": [
{"type": "image_url", "image_url": {
"url": f"data:image/png;base64,{base64_example}", "detail": "high"
}}
]
})
messages.append({
"role": "assistant",
"content": json.dumps([label], ensure_ascii=False)
})
base64_target = encode_image(target_image_path)
messages.append({
"role": "user",
"content": [
{"type": "text", "text": "次の画像についても、同じ形式で分類してください。"},
{"type": "image_url", "image_url": {
"url": f"data:image/png;base64,{base64_target}", "detail": "high"
}},
]
})
response = client.chat.completions.create(
model="gpt-4o",
messages=messages,
temperature=0,
max_tokens=1000,
)
gpt_output = response.choices[0].message.content
return extract_labels_from_gpt_output(gpt_output, categories)
import openai
# 1. OpenAIクライアントの初期化
client = openai.OpenAI(
api_key="your-api-key-here"
)
# 2. 分類対象画像(予測したい画像)
target_image_path = "./images/target_ad.png"
# 3. 1-shot例(画像パスとラベルの組)
example_image_label_pairs = [
('drive/MyDrive/darkpattern/evaluation_dataset/web/images/kiiroo.com.png',
'ACTIVITY MESSAGE'),
('drive/MyDrive/darkpattern/evaluation_dataset/web/images/(233)www.sivanaspirit.com_5b1f.jpg',
'ATTENTION DISTRACTION'),
('drive/MyDrive/darkpattern/evaluation_dataset/web/images/(177)www.adoreme.com_a719.jpg',
'COUNTDOWN TIMER'),
('drive/MyDrive/darkpattern/evaluation_dataset/web/images/(233)www.sivanaspirit.com_5b1f.jpg',
'DEFAULT CHOICE'),
('drive/MyDrive/darkpattern/evaluation_dataset/web/images/HIGH_DEMAND_MESSAGE_2.png',
'HIGH DEMAND MESSAGE'),
('drive/MyDrive/darkpattern/evaluation_dataset/web/images/(337)www.floryday.com_3f1c.jpg',
'LIMITED TIME MESSAGE'),
('drive/MyDrive/darkpattern/evaluation_dataset/web/images/Boost_ecommerce_sales_with_urgency_tactics_13_-_Sales.png',
'LOW STOCK MESSAGE'),
('drive/MyDrive/darkpattern/evaluation_dataset/web/images/herringshoes.co.uk.png',
'NO DP')
]
# 4. カテゴリ定義(辞書形式でカテゴリ名と説明)
category_definitions = {
'ACTIVITY MESSAGE': '他のユーザーの活動を表示して、急がなければならないように思わせる',
'COUNTDOWN TIMER': '制限時間があるように見せかけて急がせる',
'LIMITED TIME MESSAGE': '時間的に制限されているかのように見せる表現',
'LOW STOCK MESSAGE': '在庫が少ないと表示して購入を急がせる',
'HIGH DEMAND MESSAGE': '需要が高くてすぐ売り切れるかのようなメッセージ',
'DEFAULT CHOICE': '初期状態でユーザーに不利な選択肢が選ばれている',
'ATTENTION DISTRACTION': '注意をそらすようなデザイン・要素'
}
# 5. 分類実行
result = ask_gpt4_one_shot(
target_image_path=target_image_path,
example_image_label_pairs=example_image_label_pairs,
category_definitions=category_definitions,
client=client
)
# 6. 結果出力
print("GPTによる分類結果:", result)
さいごに
グループ研究開発本部 AI研究開発室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務などAI研究開発室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD