2025.05.02
FramePack and FramePack-eichi 〜高速・省メモリなローカル動画生成AI〜
TL;DR
- Illyasviel氏が発表した動画生成AI「FramePack」は、最大60秒(30 fps)もの長時間の動画を破綻なく、それもローカルGPUで高速に生成できる技術です。必要なGPUメモリは僅か6GB、GeForce RTX 4090のような高速なGPUなら1フレームあたり2.5秒で生成可能です。
- FramePackは、最終フレームの画像を生成し初期フレームへ向けて時間を逆方向に動画を生成します。これにより長時間でも破綻の少ない高品質な動画生成を実現しています。また、生成時刻から遠いフレームの情報を順次圧縮することで、必要なメモリーを削減しています。
- そして有志が開発したFramePackの現地改修仕様(原文ママ)が「FramePack-eichi(叡智)」です。これは最初と最後の画像を与え途中を補完する動画を生成します。従来の動画生成AIより、更に安定した期待通りの動画の作成が可能です。
はじめに
こんにちは、グループ研究開発本部AI研究室のT.I.です。Illyasviel(Lvmin Zhang)氏が、2025年4月17日に「FramePack」という動画生成AIの技術を発表しました。これは入力画像とプロンプトから最大60秒(30 fps)もの長時間の動画を破綻なく、それもローカルのGPUで高速に生成できる技術です。130億パラメータのモデルを利用しますが、必要なGPUメモリは僅か6GBです。生成速度に関しては、GeForce RTX 4090のようなGPUを利用すれば、1フレームあたり2.5秒であり、1分強の時間があれば、1秒の動画を生成することができます。更に、「FramePack-eichi」という拡張も4月21日に発表されました。これは最初と最後のフレームの画像を与えて途中の動画を生成するもので、プロンプトのみの動画生成よりも、更に安定して期待通りの動画生成が可能となります。
ちなみにFramePackの開発者のIllyasviel氏は画像生成時に人物のポーズなどの制御を可能とする「ControlNet」やStable Diffusionの軽量・高速なユーザーインターフェース「Stable Diffusion WebUI Forge」といった生成AIの技術を開発した方でもあります。
FramePackとFramePack-eichiで動画を生成してみた
さて、まずはFramePackを動かしてみましょう。実行環境の作成は以下のようにGitHubからクローンして、必要なライブラリをインストールするだけです。
$ git clone [email protected]:lllyasviel/FramePack.git $ cd FramePack $ uv venv --python 3.10 $ source .venv/bin/activate $ uv pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126 $ uv pip install -r requirements.txt $ uv pip install xformers # 高速化のために xformersも入れてみました $ python demo_gradio.py
Gradioのアプリにアクセスすると、以下のような画面が表示されます。なお、初回実行時には必要なcheckpointをダウンロードするので、少し時間がかかりますので気長に待ちましょう。
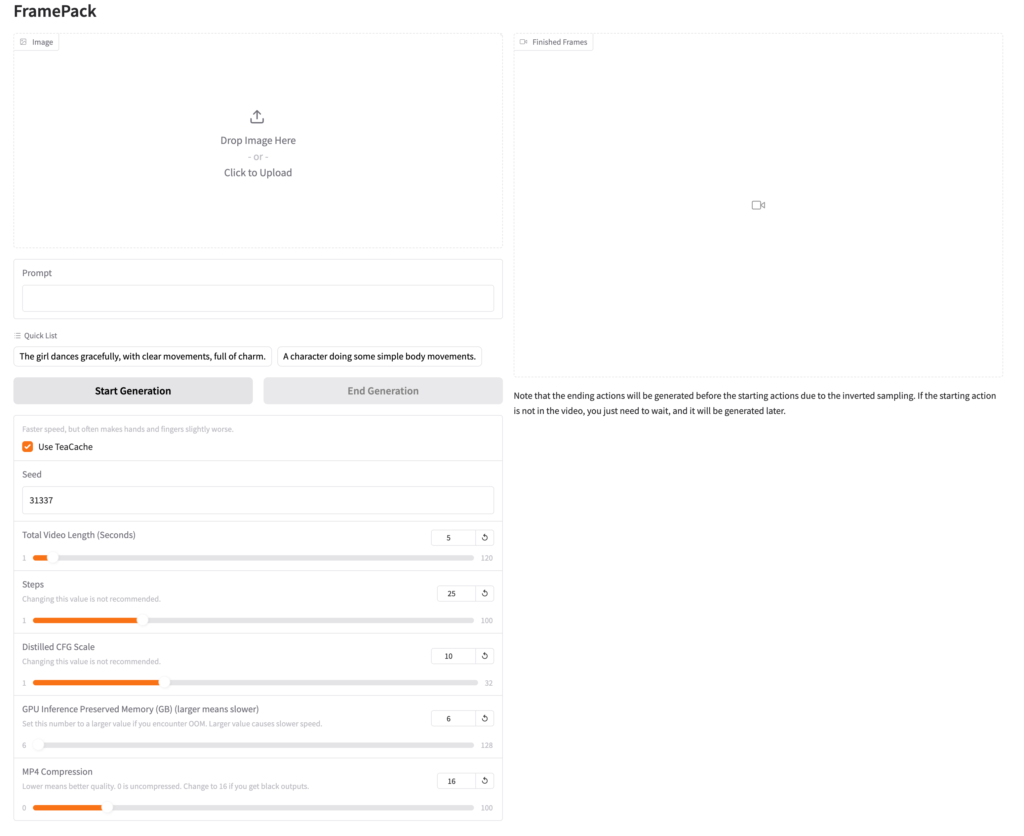
FramePackはText-to-Videoの生成AIではなく、Image-to-Videoの形式の生成AIです。まずは画像イメージを入力し、それとプロンプトを与えて動画を生成します。
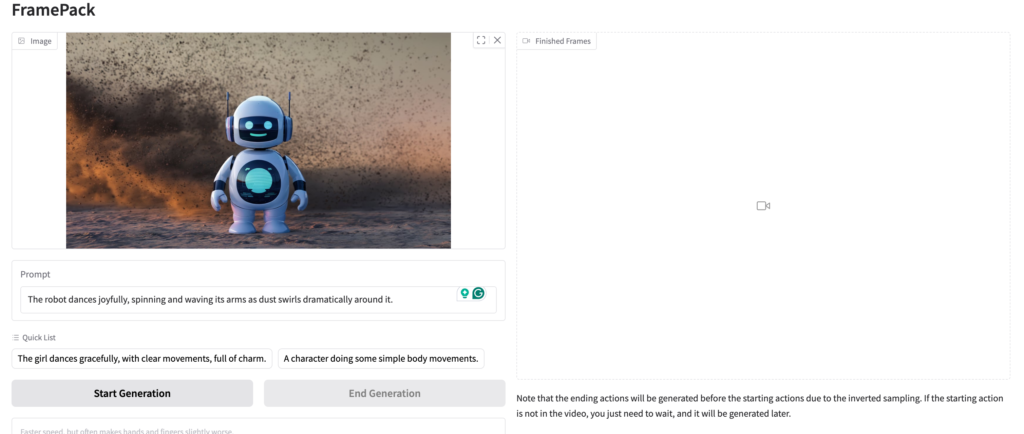
画像とプロンプトを与えてあとは生成するだけです。25ステップ単位で生成が順次実行され、動画が生成されていきます。今回の生成では、実行環境としては、GeForce RTX 4090を利用していますが、5秒の動画生成には数分間掛かるので待ちましょう。25ステップ完了するごとに、途中までのプレビューが表示されるので、それを見ながら待つことができます。
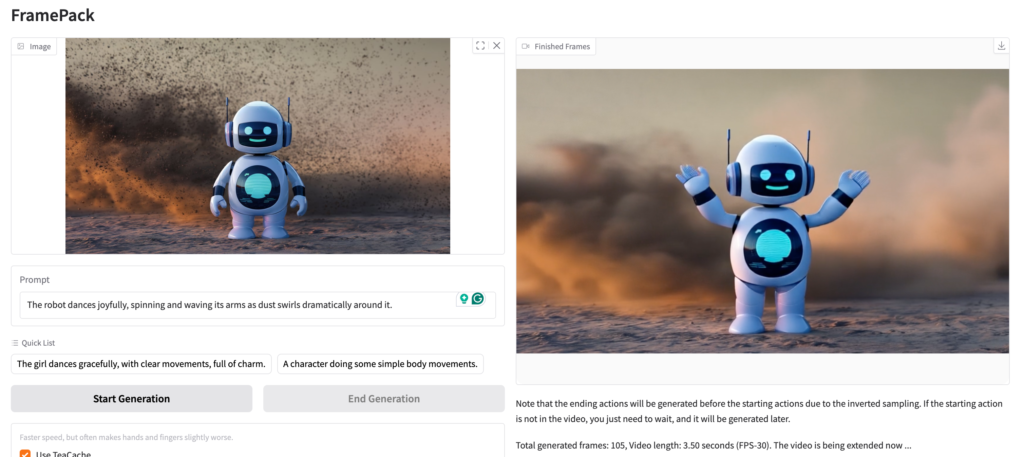
さてついに動画が完成しました。WebUI上でプレビューとダウンロードが可能です。
無事に踊って動いてますね🤖ローカルのGPUで僅か数分で手軽に動画生成ができるのは随分と便利になりました。
では、次にFramePack-eichiを試してみましょう。これは、FramePackをインストールした上で追加のモジュールとしてインストールします。インストールと実行手順は以下の通りです。今回のデモでは、Version 1.6.1 を使っておりますが、4月21日に公開されて以降、日々GitHubのアップデートが行われているので、最新のものとは異なる場合がありますので注意してください。
なお、名前の由来としては、GitHubのREADMEに以下のように書かれています。
Endframe Image CHain Interface (EICHI)
- Endframe: エンドフレーム機能の強化と最適化
- Image: キーフレーム画像処理の改善と視覚的フィードバック
- CHain: 複数のキーフレーム間の連携と関係性の強化
- Interface: 直感的なユーザー体験とUI/UXの向上
「eichi」は日本語の「叡智」(深い知恵、英知)を連想させる言葉でもあり、AI技術の進化と人間の創造性を組み合わせるという本プロジェクトの哲学を象徴しています。 つまり叡智な差分画像から動画を作成することに特化した現地改修仕様です。
熱い熱量を感じさせてくれる文章ですね…😅さて、FramePackをインストールした状態で以下のように追加して実行します。
$ git clone https://github.com/git-ai-code/FramePack-eichi.git eichi $ ls eichi/webui eichi_utils/ endframe_ichi.py lora_utils/ $ mv eichi/webui/* . $ python endframe_ichi.py
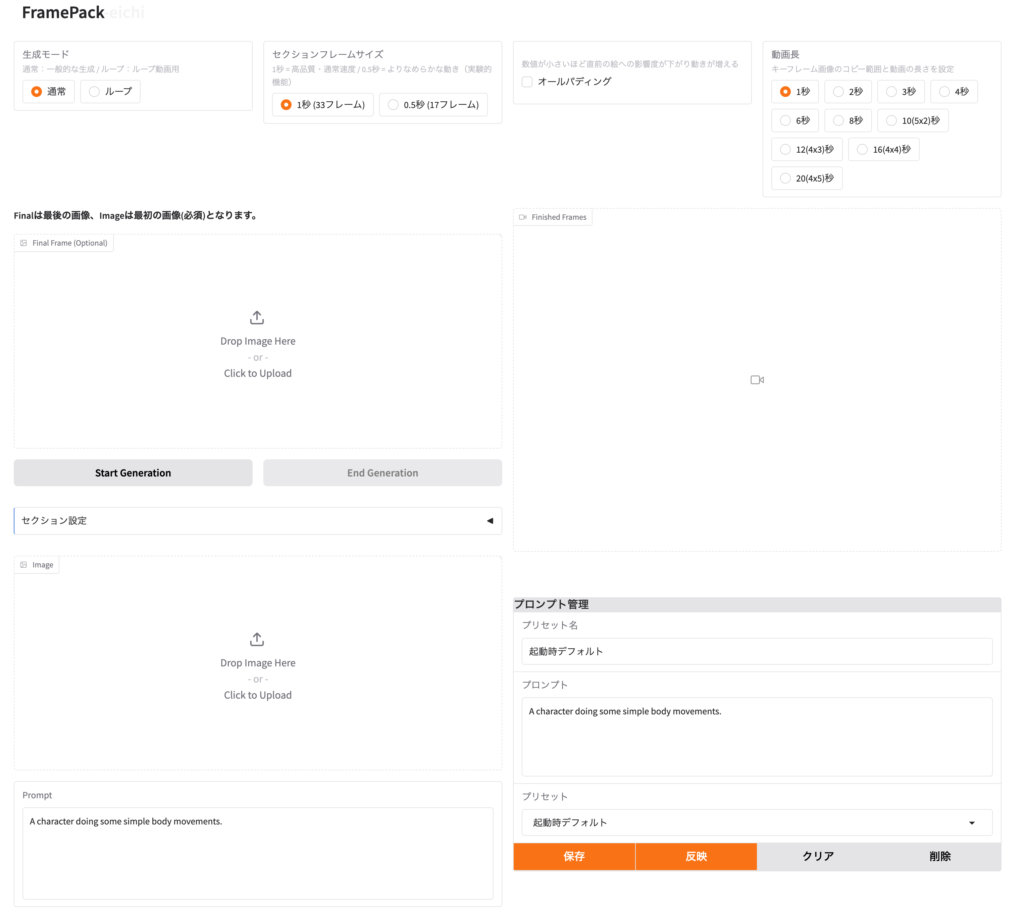
FramePack-eichiは開発者が日本人ということもありデフォルトでは日本語でメニューが表示されています。多言語への拡張なども現在進められているそうです。以下のように最初と最後のフレームの画像(更に途中のフレームの画像の指定も可)を入力します。上が最後のフレームで、下の方が最初のフレームである点に注意してください。あとは生成時間などを指定しプロンプトを与えて実行するだけです。生成時間は基本的にFramePackと同じです。
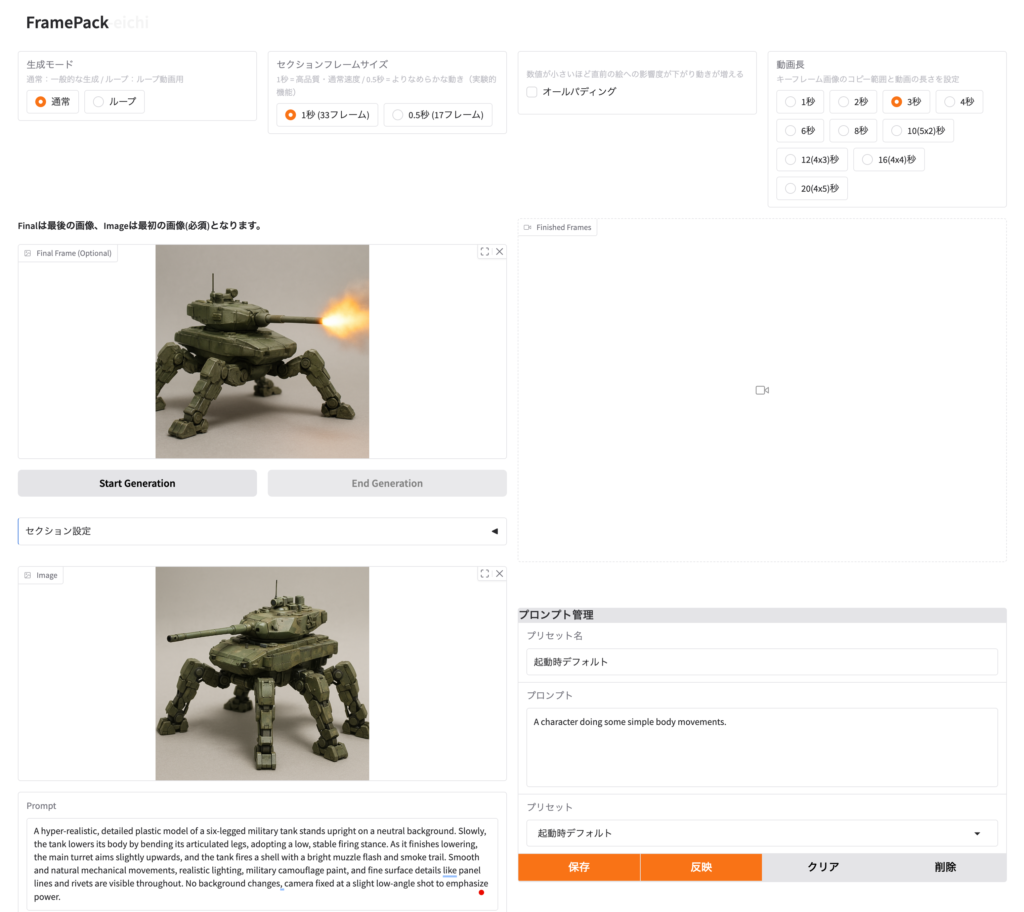
できました。指定した最後のフレームの間を補完してなめらかな動画が生成されます。向きを変えるアクションは中々に良いのですが、その後は何故か火炎放射器になってしまいました😢
FramePackの原理とは
さて、動画を作って遊ぶのも良いのですが、せっかくなのでFramePackの原理についても少し触れておきましょう。FramePackは、省コスト・高速で安定した長時間の動画生成を可能とするために、様々な技術的工夫がなされています。これまでの動画生成AIの問題点として、「Forgetting(忘却)」と「Drifting(ドリフト)」という2種類の問題点があります。この忘却とは、過去の情報が失われてしまい動画の一貫性が失われてしまうこと、後者のドリフトは生成を繰り返すうちに誤差が蓄積し品質が悪化することを指しています。忘却を回避するために記憶を強化し多くの情報を保持すると誤差の蓄積が増えるためドリフトが悪化、一方でドリフトを回避するために誤差伝播を減らすと、忘却が悪化するというトレードオフの関係にあります。
Anti-forgetting memory structureとanti-drifting sampling
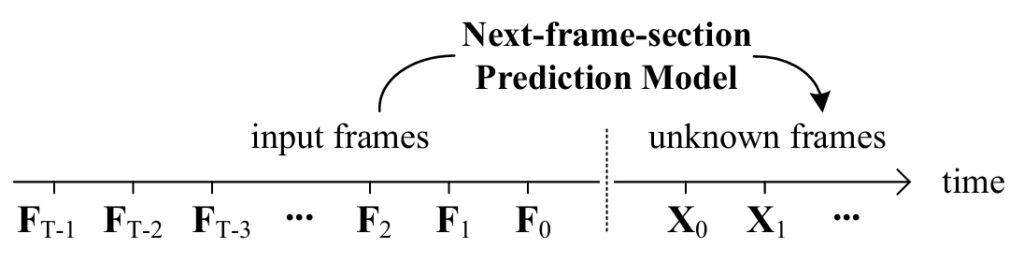
これらを回避するためにFramePackでは、「Anti-forgetting memory structure」と「anti-drifting sampling」という技術を用いています。以下は、動画生成をするNext-frame-section Prediction Modelの概要です。過去のフレーム(\(F_0, F_1, F_2, \cdots, F_{T-1}\))を入力し、その後のフレームの画像(\(X_0, X_1, \cdots \))を生成していきます。
ただ、動画の場合、直近のものほど重要度が増し、過去の情報ほど重要性が薄れていきます。FramePackでは、1フレーム前のものは1/2、2フレーム前は1/4のように、過去の時刻の情報を順次圧縮して利用しています。1フレームに必要なcontext length \(L_f\)(480p frameの場合では約1560)で、入力フレーム数\(T\)に対して予測したいフレーム数\(S\)とします。1フレームごとの圧縮率 \(\lambda\)とすると、必要なcontext lengthは以下のようになります。
$$
L = S \cdot L_f + L_f \sum_{i=0}^{T-1}\frac{1}{\lambda^i}
= S \cdot L_f + L_f \cdot \frac{1 – 1/\lambda^T}{1 – 1/\lambda}
\rightarrow \left(S + \frac{\lambda}{\lambda -1}\right) L_f \quad \text{for} \ T \rightarrow \infty
$$
過去の情報ほど順々に圧縮されるため、入力のフレーム数 \(T\)がいくら増えたとしても最終的に必要なcontext lengthは一定の入力長に保つことができます。このように圧縮された過去のフレームの情報をどのように保持するか以下のようなパターンが論文中では議論されています。

また、通常の動画生成では、過去から未来に向けて画像を順々に生成していきます。しかし、この場合では、エラーが蓄積するためドリフトを誘発します。FramePackが採用している Anti-drifting samplingでは、時間方向を逆に生成することで、ドリフトを回避します。最初にターゲットとなる未来の時刻の画像を生成し、スタート時刻へと逆方向に生成していきます。つまり初期条件とゴールが決まっているわけですから、その間の動画を補完することになります。以下の図の(a)が通常の動画生成方法で右の未来方向へ向かって順次フレームを生成します。そして、(b)のAnti-driftingでは、最初にゴールの未来のフレームも生成し、そこへ向かって未来方向へフレームを生成していく方法で、(c)のInverted anti-driftingは、未来方向から過去へ遡って生成していく方法です。
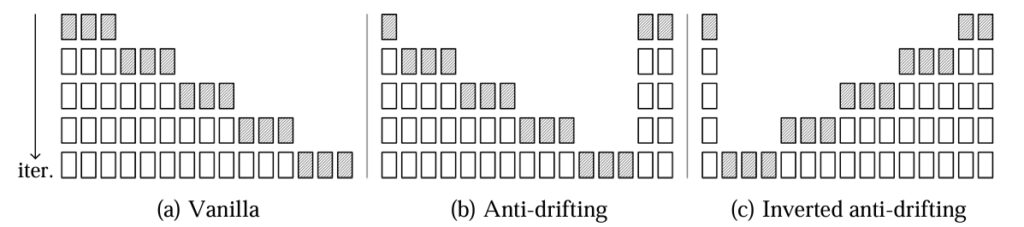
FramePackの論文では、これらの生成方法を比較したところ、(c) inverted anti-drifting sampling が最も良い結果を得られたとしています。
HunyuanVideo
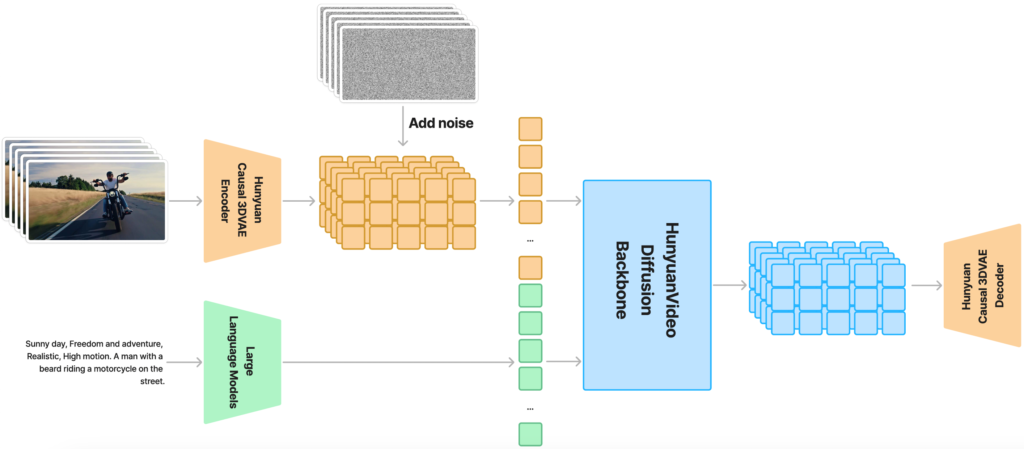
FramePackは、動画生成のアルゴリズムであって、そのコアとなる動画生成のモデルは「HunyuanVideo」をファインチューニングしたものを利用しています。HunyuanVideoは、Tenscentが開発し2024年12月に公開したオープンソースの動画生成AIのモデルです。パラメータ数は130億に上り、量子化していない場合では、最低でも45GBのGPUメモリが必要です。HunyuanVideoのアーキテクチャは以下の通りで、入力のEmbeddingをDiffusion Transformerで処理し、decoderで動画へと変換します。
まとめ
さて、今回、動画生成AIの新技術であるFramePackとFramePack-eichiを試してみました。昨年のSoraの発表以来、様々な動画生成AIサービスが発表されました。ローカル動画生成AIもありましたが、非常に長時間の生成時間とGPUメモリーが必要なため、手軽に試すことは難しい状況でした。FramePackでは、130億パラメータのモデルを利用しながらも、GPUメモリは僅か6GBで利用可能、GeForce RTX 4090のようなGPUを利用すれば、1フレームあたり2.5秒と、実用的な動画生成が可能になりました。入力画像を元に未来の画像から逆算して動画を生成するため品質と安定性が大きく改善されています。Stable Diffusionが公開されたときのように、動画生成に関しても今後様々な技術革新が進むと期待しております。
最後に
グループ研究開発本部 AI研究開発室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務などAI研究開発室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ募集職種一覧からご応募をお願いします。皆さんのご応募をお待ちしています。

参考資料
- FramePack [GitHub]
- Packing Input Frame Context in Next-Frame Prediction Models for Video Generation [arXiv:2504.12626]
- Packing Input Frame Context in Next-Frame Prediction Models for Video Generation [Project Page]
- FramePack-eichi [GitHub]
- ControlNet
- Stable Diffusion WebUI Forge
- HunyuanVideo [GitHub]
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD