2024.07.08
データサイエンティストが実務で覚えるEMR Serverlessのコスト削減
はじめに
こんにちは。グループ研究開発本部、AI研究開発室のY.Tです。
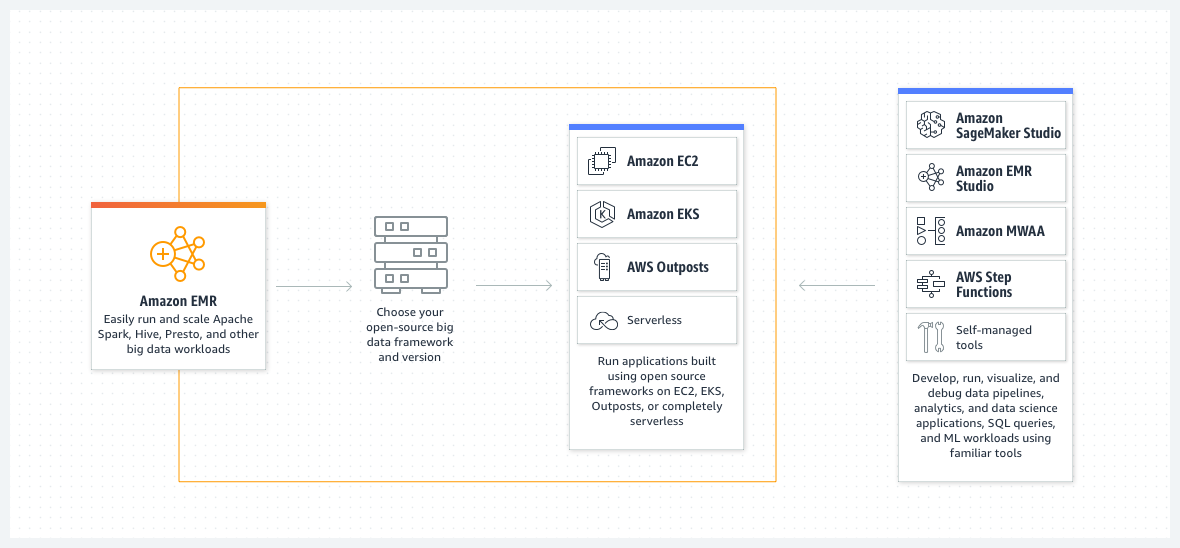
皆様、EMRはご存知でしょうか? 簡単に説明すると、ペタバイトスケールのデータをオープンソースフレームワークを利用して扱うための基盤です。
では、使ったことがある方は? 個人ではあまり使わないですよね。そのはずです。個人ではEMRを利用するほどの大規模データの分散処理を書くケースが多くないと思います。
クラウド化されてマシになったとはいえクラスター管理も手間がかかります。
最近ではEMR Serverlessというサーバーレスなサービスが利用できるようになっており利用のしきいはさらに下がったものの、真価を発揮するサイズのデータを扱い始めるとコストはしんどいものがある。
処理を記述する分には、PythonなどでDataFrameのような記述が提供されており、Pandas等のフレームワークに慣れた人であればあまり困ることはないです。ただ、そういうサービスですので、パフォーマンスチューニングやコスト削減に関する個人の記事のような情報は集めるのに苦労します。
最近、実務で触る機会があったので、今後Sparkを触る方や、今の苦しみを忘れた未来の自分のために、効果のあったポイントを備忘録のように書いておこうと思いました。
あ、教科書的には、公式のPerformance Tuningに書いてあることが、もう、全てです。AWSの提供するチューニングガイドもかなり参考になります。
具体的な実行例も、わかりやすい結果が見えるサイズだとコストが、、、というところで、ご容赦ください。あくまで備忘録として、ということで!
まず、ARM使いましょう
本当にこれ。
ARMインスタンスが料金が安く設定されていて、選べるならARMを選んだ方がお得、みたいなことは他のAWSサービスを使っていてもあるかと思いますが、EMR Serverlessも同様です。
ちょっと単位が細かくてわかりづらいですが、大体30%ぐらいARMのコストが安く設定されています。
料金 – Amazon EMR Serverless
- Linux/ARM(東京リージョン)
- 1 時間あたりの vCPU 単位 0.052585USD
- 1 時間あたりの GB 単位 0.005746USD
- Linux/x86(東京リージョン)
- 1 時間あたりの vCPU 単位 0.065728USD
- 1 時間あたりの GB 単位 0.007189USD
自分たちのケースでは、x86のCPUのWindows端末がローカル環境のメンバーの方が多かったことに合わせて、最初はAWS側もx86にしました。
しかし、さすがにカタログスペックでコストが違いすぎるしアーキテクチャの違いが問題になるような使い方してるところないでしょう、ということでARMに変えました。
特にエラーや計算コストの変動はなく、料金の比較でもカタログ通りに30%程度安くなりました。
ローカル環境が直近のバージョンのMacなどであれば、迷いなくARM、そうでなくてもARMですね。
Cache()
sparkは遅延評価です。まずは計算グラフ(DAG)が定義され、集計などを行うタイミングで初めて評価されます。
loggerなどで処理時間を出力してみるとわかりやすく、具体的にはfilter()などの関数が爆速で終了し、count()やshow()などをしているタイミングで時間がかかっていることがわかります。
spark web uiを眺めてみるのも良いでしょう。
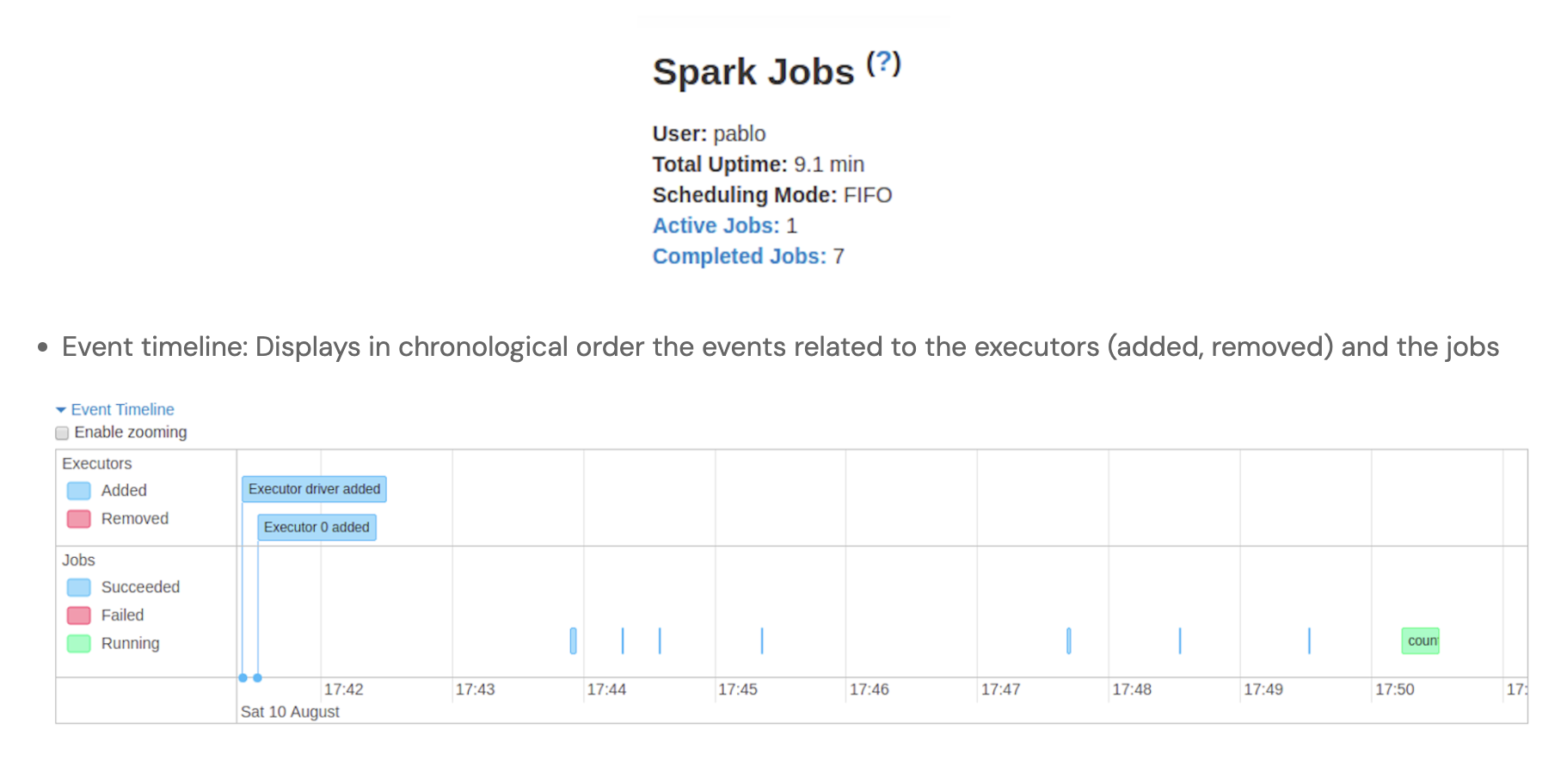
基本的に、DAGは都度、全て評価されます。そのため、特に何もしないと、そこそこのサイズの全く同じ計算が数度走るということになります。
cache()はDAGの途中結果をメモリに置くような処理です。cache()を実行すると、以後のDAGの評価はcache()を記述して以降のDAGのみが評価されます。
で、これを考えずに書くとどうなったかというと、具体的には次のような失敗をやります。
df_result = df.agg(~~~) # そこそこコストの重い処理
df_result_hourly = df_result.groupBy("hour").agg(~~~)
# 結果テーブルから時間帯ごとの集計も出す。
特に違和感のない時間帯別集計処理の追加ですね。しかし、# そこそこコストの重い処理 のDAGの評価が無駄に2回走っています。
df_result = df.agg(~~~)
df_result.cache()
df_result_hourly = df_result.groupBy("hour").agg(~~~)
こうすれば解決。これにより、時間帯別集計処理が、結果テーブルの集計の後から評価されるようになりました。
cache()しないと、実際のケースでコストが倍近くかかってました。恐ろしいですね。
当然、メモリにデータを置くので空間計算量と時間計算量のトレードオフにはなります。しかし、集計後のデータのサイズは大きくないので、多くのケースで重い集計が走った後はcache()をしておけば良いでしょう。
以後の計算で使用されないcache()は解放することも忘れないようにしましょう。やりすぎるとOOMで処理が落ちます。気をつけましょう。
遅延評価の分散処理はやや人類に早いところがあり、コードから適切にcache()を入れるのは難しいかもしれません。
spark web UIを活用しましょう。画面を眺めていると、ほぼ同じ計算コストのStageが二つあったり、似たようなDAGが評価されていたりすることに気づくかもしれません。cache()しましょう。
後述しますが、cache()をすることで逆に遅くなるケースもあります。難しいですね。
Join
sparkがうまく性能を発揮できないのはどのようなケースだろう。答えは「うまく分散できない計算をやらされてる時」、具体的にはデータを処理ノードに分割したら、データサイズがノードごとに偏ってしまったケースがあります。
その原因はJoinの仕方にあるかもしれません。
そのような状況になっているかは、また、spark web uiを見ているとわかるかもしれない。他のノードに比べて、ノード間のデータの転送(Shuffle)が多い、動いてる時間がやたら長いといったノードがあれば、気にしてみよう。
大きいテーブルに小さいテーブルをjoinする場合、Broadcast Joinが有効です。
# 小さなDataFrameをブロードキャスト broadcasted_small_df = broadcast(small_df) # ブロードキャストジョインの実行 joined_df = large_df.join(broadcasted_small_df, large_df["join_column"] == small_df["join_column"], "left")
このように書くと、小さいDataFrameが全ノードに配置されてJoin処理が走るようになり、データ転送の面で効率的になります。
JoinについてはBroadcast Join以外にもいくつかあり、クエリヒントのように明示的に指定したりできて工夫のポイントがありますが、実はあまり気にしなくて良いのかもしれません。
というのも、新しいバージョンでは、Adaptive Query Execution (AQE)が有効であり、クエリの実行計画にはかなり最適化がかかります。
joinする前にfilterで件数を減らす、とかそういった基本的なところをやっておけば、細かい工夫はあまり労力に見合わないのでは、という気がしてきます。
注意してほしいのがcache()の影響です。cache()の前後で最適化の評価が切れるらしく、cache()の入れ方によっては最適化の邪魔をするケースがあるようです。
joinの工夫も最低限必要ですが、結局のところは
新しいバージョンを使って、便利な機能を享受しよう。
大事です。さすがクラウドサービス。
どうしてもしんどいData Skew, Sort
ソートは苦手です。なぜなら結局、ソートする時には分散がしづらいから。
# ウィンドウ仕様の定義: nameでパーティション化し、dateでソート
window_spec = Window.partitionBy("name").orderBy("date")
# 各パーティション内での行番号を追加
df_with_row_number = df.withColumn("row_number", row_number().over(window_spec))
こんなふうにできる限り分散してパーティションごとにソートをしたりしますが、パーティションごとのデータに偏りがあると大変です。名字でパーティションしてソートをかけると、大量の佐藤さん、伊藤さん、高橋さんが、それぞれ一つのワーカーに押しかけて最悪OOMでしょう。
OOMを避けるために、ワーカーのリソースの最大に合わせて、リソース設定をしなければいけません。
これがデータの偏り(Data Skew)です。Joinのところでもデータの偏りに触れましたが、パーティションごとにソートをかけなくてはいけない状況でのData Skewはわりとどうしようもないように思います。
解決として例えば、
- カテゴリを見直してソートの単位をさらに分割できるようにする。
- 処理のなかでデータを分割したり、色々工夫
という感じだと思います。
ビジネスロジック上、高橋は高橋以上に分割できず高橋全体にソートをかける必要がある、となってしまうなど、それ以上分割できないことは多いでしょう。
分散のソートはまた厄介なので、結局、シンプルな実装にして耐える形になることが多そうです。
自分のケースでは、ソートは諦めてシンプルな実装とし、リソース設定は落ちないギリギリを攻める、みたいなことをしました。
設定
項目多すぎ!
大丈夫です。安心しましょう。色々と設定を入れてみましたが、結局そんなに書く必要がなかったです。多くのケースで必要であろう機能はデフォルトでOnで、基本はそんなに書かなくていいです。
そんな設定の中で、まず確認した方が良い1番の設定はおそらくこれ。
spark.executor.memory, spark.executor.cores
executor、分散処理を行うノードのメモリとコアの設定。デフォルトは結構小さいです。一方、増やしすぎても計算が早くなるわけでもないので程よく、OOMにならない程度のサイズで。
実際に十分に大きく設定して計算してみて、spark web uiを見て決めるのも良いでしょう。
そして重要なパラメータはこれです。
spark.dynamicAllocation.enabled = true
EMR Serverlessではデフォルトでtrueになっており、計算の大きさに合わせてExecutorの数を増大・縮退させます。ApplicationのLimitが近づくと、計算コストに関わらず増大が鈍化し、Limitは超えません。
これがあるおかげで、計算で最大どれくらいメモリを使うか、などはあまり考えなくてよく、各Executorが落ちなければいいぐらいの気持ちで設定できます。
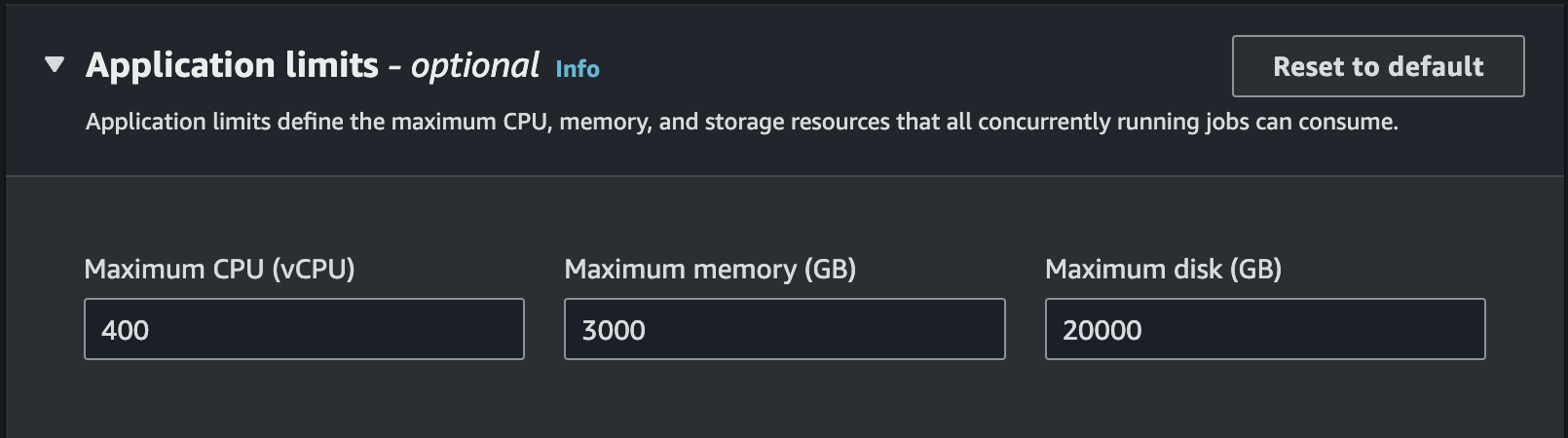
あとはjobのタイムアウトを設定しておきましょう。Applicationの作成後のJobのsubmit時に設定できます。
デフォルトが720minで長めなので、ジョブに合わせて少し短くしても良いかもしれない。この設定のおかげで、謎のバグにより10分で終わるはずのjobが1日動き続けた、なんて事態を防ぎます。
最後に、自分たちのケースではコスト削減に役立ったこの設定を書いておきます。
spark.dynamicAllocation.maxExecutors
デフォルトがInfinityなのですが、これを定数にしました。基本は任せておけば良いと思います。
偏ったデータへのソートを行わなければならないケースでは、Joinなどが一瞬で終わり、その時に拡大したリソースを贅沢に無駄遣いしながら、重いソートが走っているノードの処理を10分くらい待つということが発生しました。
そこで、ソートの時の無駄を省く狙いで動的リソース確保に制限をかけたところ、実行時間は伸びましたが総計算リソースが減りコストはかなり抑えることができました。
かなりHACKですが、何かの参考になれば。
最後に
色々と書きましたが、バージョンは新しいのを使っておきましょう〜みたいな面白みのない項目が多かったと思います。
実際のところ、かなりの部分を勝手にやってくれるので、特に自分が細かく設定を入れる部分はほとんどなかったりします。Joinのあたりは他のDBのクエリを書くときでも、似たようなことが言われますね。
小規模なチームでもビッグデータを当たり前のように使う時代ですし、何かの役に立てば幸いです。
ちなみに、このブログ内のサンプルコードは多分にGPT-4oを用いて書かれています。こんなふうに。
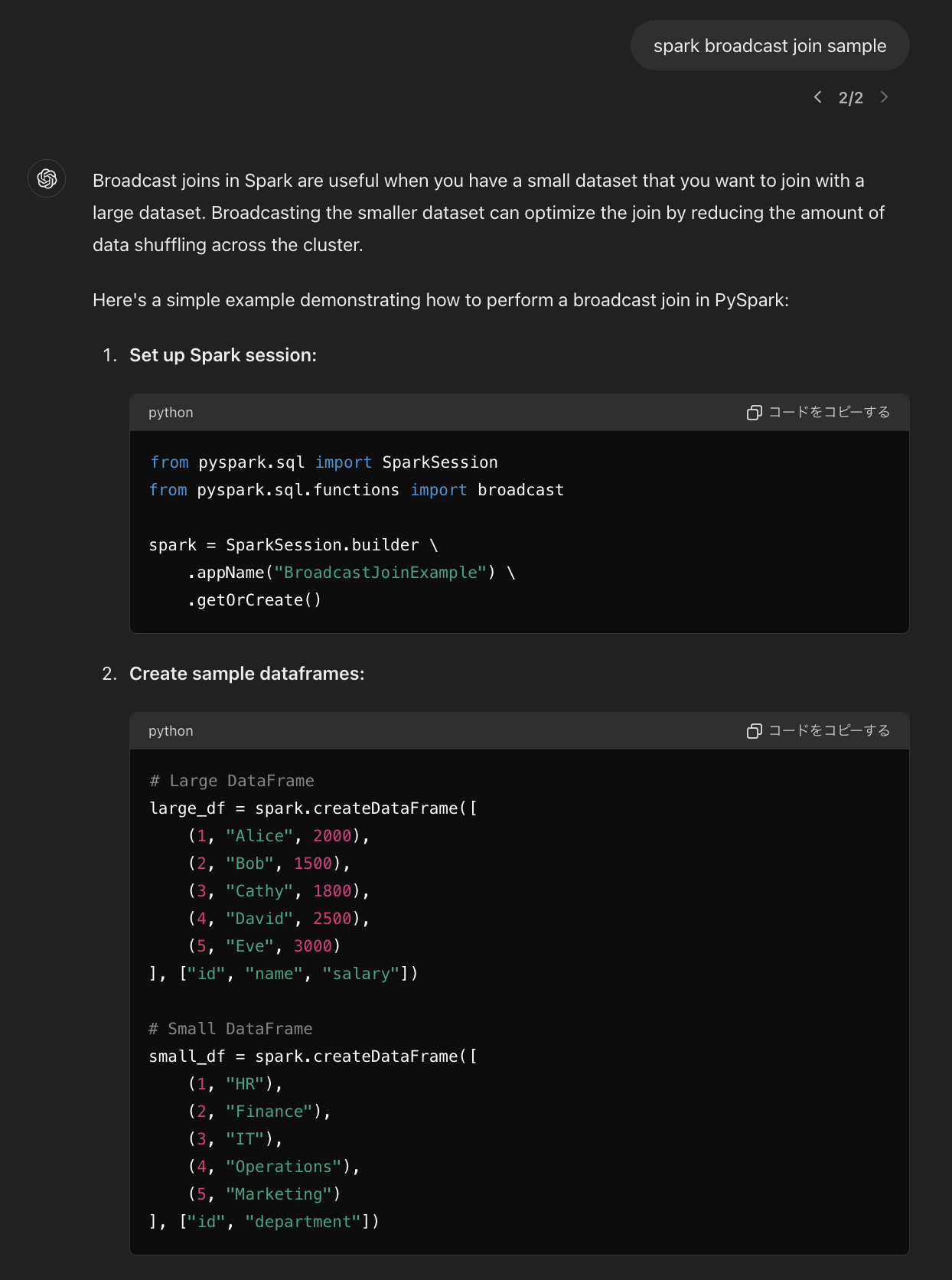
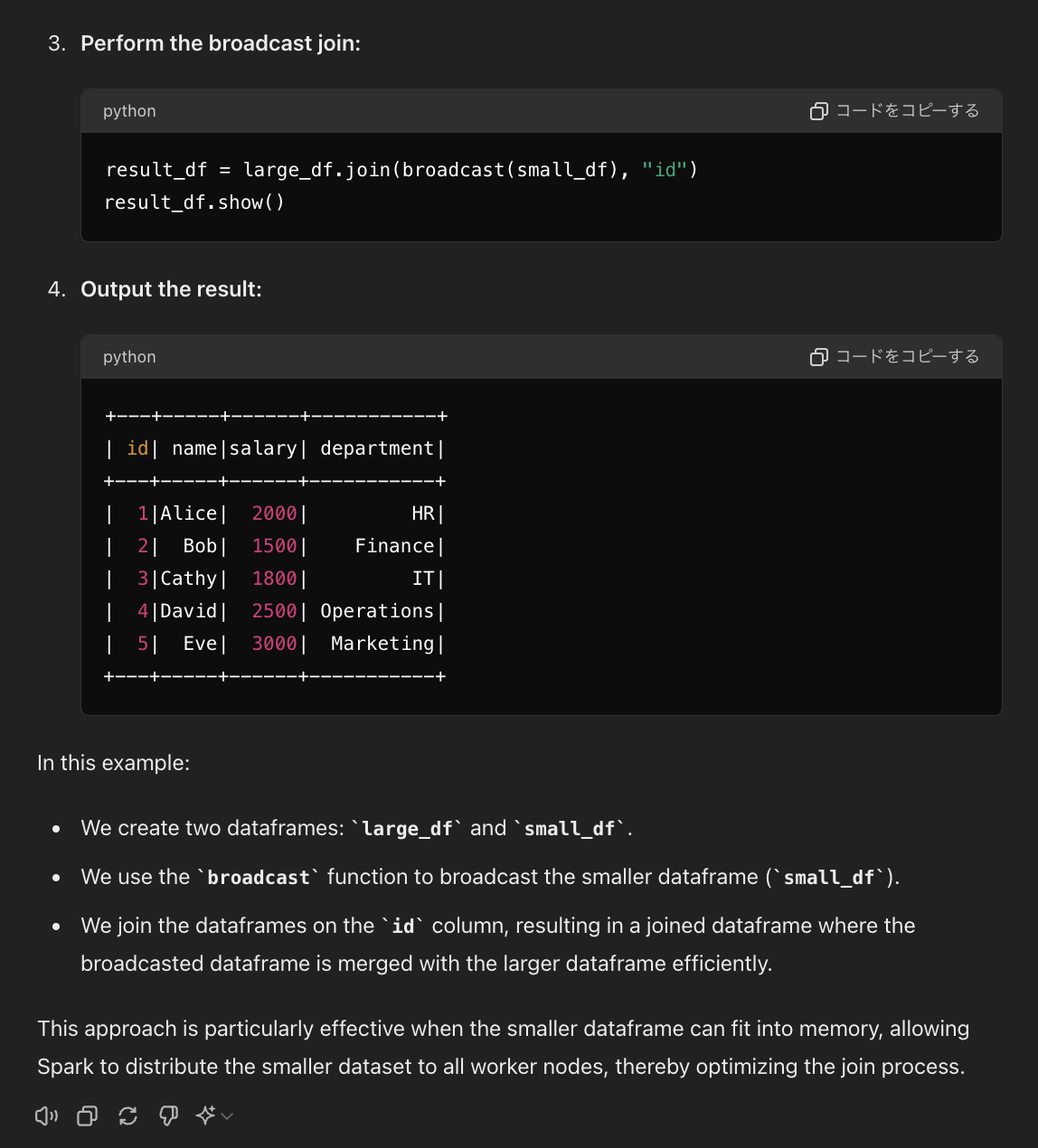
律儀にテーブルを作るので、ローカルでテストケースを書くときとかは便利です! ただ、エラーを吐かれると解決できないケースがほとんどです、、、
信じられるのは公式ドキュメントと実装だけ。Sparkを書く皆様方に幸あれ。
宣伝
グループ研究開発本部 AI研究開発室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務などAI研究開発室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。皆さんのご応募をお待ちしています。
参考
Apache Spark
Amazon EMR
Handling Data Skew in Apache Spark: Techniques, Tips and Tricks to Improve Performance
Spark パフォーマンスの最適化
[AWS Black Belt Online Seminar] 猫でもわかる、AWS Glue ETLパフォーマンス・チューニング 資料公開
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD