2017.01.04
Deep Learningを使って音楽作成してみた
次世代システム研究室の T.N. です。
皆さん音楽は好きですか?
私はロックを中心に音楽が聞いたり、弾いたり結構楽しんでいます
でも年を取ったせいか好きなバンドが解散したり、活動休止したりも多くなってきました
一番好きなTHE YELLOW MONKEYは今年再結成したものの15年間解散してましたし、他のバンドもそういった状況になってしまうことが増えてきてしまっています
これは実に悲しいです、、、
新曲は聞けなくてもせめて人工知能がそれっぽい音楽を作って癒してはくれないものでしょうか?
というわけでちょっとDeep Learningで自動作曲を試みてみました
関連研究
Deep Learningで自動作曲という分野ではGoogle(DeepMind)社の以下の2つのプロジェクトが有名ですね
Magenta
Magentaは機械学習でアートを創作することを試すGoogleのプロジェクトになります
Tensorflowで実装され、ソースコードはGithubで公開されています
メロディを作成する基本のニューラルネットワークは以下の3つが公開されています
名前の通りRNN(LSTM)を基本としているようです
(他にもDrums RNNやコード進行から作成するImprov RNN等も存在)
- Basic RNN
- Lookback RNN(Basic RNNのInputデータに繰り返し回数などを追加)
- Attention RNN(Attentionを加え、過去の出力結果を、今回出力結果に加味する)
MIDIがあれば、4つコマンドを実行するだけで学習生成できるので、こちらを参照し、興味のある方は是非試してみてください
Wavenet
こちらはAlphaGoで有名なDeepMindが作成した音声出力技術です
公式サイトに音声サンプルがありますが、ほとんど人間の音声で区別がつかない素晴らしいものになっています
MagentaがRNNを使用しているのに対し、こちらはCNN(畳込みニューラルネットワーク)で構成されています
Wavenetは非常に素晴らしい品質の音声をOutputしてくれるのですが、反面学習・予測はMagentaと比較して非常に時間がかかるようです
音楽自動作成
処理内容
というわけで今回はコンピュータリソースも限られていることもあり、Magentaを踏襲してRNN(LSTM)でちょっと作ってみました
今回のテーマは「音程とリズムの別離」です
本来「音の高低」と「リズム」ってそこまで依存性は高くないのかなと感じています
例えば転調. この場合同じリズムですが、音の高低は変わりますよね
つまりリズムが同じでも、そこを構成する音っていうのは自由に変えれるはずなんです
というわけで音程とリズムを生成するニューラルネットワーク(LSTM)を2つに分けてみました
イメージはこんな感じです
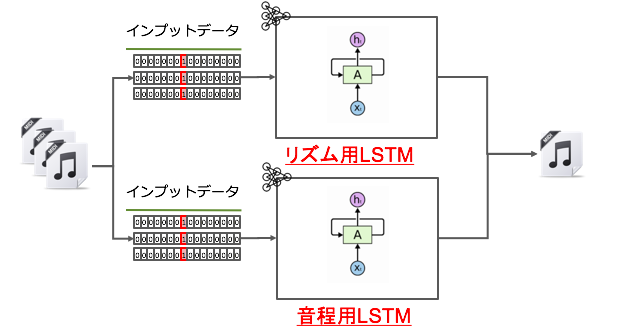
LSTM自体はBi-directionalですらない、ごくごく普通のLSTMを使っています
以下にネットワーク定義部分のコードを載せますが、本当に普通のLSTMですね
※今回はchainerを使い実装しています
class Music(Chain):
def __init__(self):
super(Music, self).__init__(
embed=L.EmbedID(num_of_input_nodes, n_units),
l1=L.LSTM(n_units, n_units),
l2=L.LSTM(n_units, n_units),
fc=L.Linear(n_units, num_of_input_nodes),
)
def reset_state(self):
self.l1.reset_state()
self.l2.reset_state()
def __call__(self, input_vector):
h = self.embed(input_vector)
h = self.l1(h)
h = self.l2(h)
y = self.fc(h)
return y
インプットデータはOne-hot vectorにしています
音程用LSTMでは取りうる音の数+休符数の長さを、リズム用は全音符〜64分音符を範囲とする長さ7のベクトルを使っています
(簡素化のため3連符や符点付きなどは全て近似値に置き換えています)
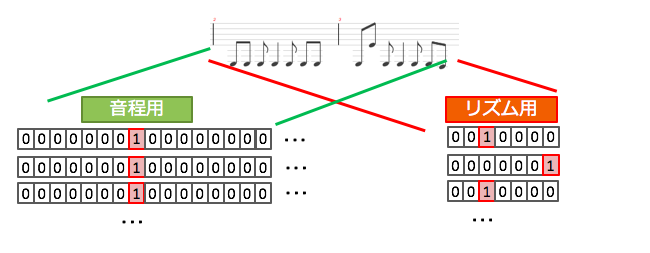
またアウトプットデータについてもちょっと加工しています
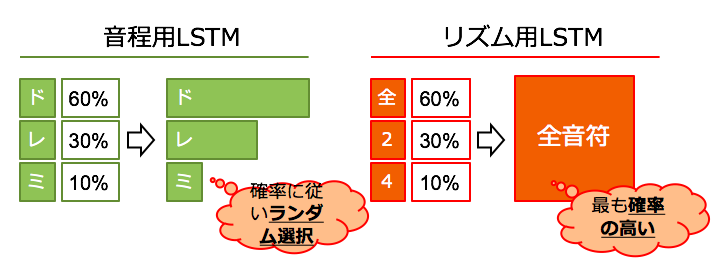
アウトプットはsoftmax関数使っているので、それぞれが取る確率(のようなもの)で出力されます
これを音程用LSTMでは確率に従いランダムに、リズム用は最も確率が高いものをとるようにして値を決定しています
音は”ルールに従っていれば”ある程度揺れても気持ちいいのですが、リズムについてはあまりぶれてしまうと気持ち悪いための処置になっています
生成結果
上記で作成した音楽作成RNNを使って作曲してみました
で、今回はとあるベーシスト2人の曲をInputにモデルを2つ作っています
生成には1小節分同じフレーズを作り、これを元に以降の音を生成しています
以下お聞きください
【モデル1】
【モデル2】
両モデルともにEがキーになっていて、外す音も無く、またリズムも統一されていて悪くないできかと思います
モデル2についてはEをベースにしながらオクターブ違いのEを混ぜたりして、直感的にも譜面的にも違和感なくできていますね
まとめ
譜面をベースにした音楽自動作成を簡単に作ってみましたが、結果はなかなかいいものになりました
ただ当初の目的の「解散してしまったバンドの音を聞きたい」というのにはまだまだ遠く及ばないですね
今後はWavenetのような革新的な技術に注目しつつ、引き続き人工知能バンドの結成を目指してみたいと思います
次世代システム研究室では、ビッグデータ解析プラットフォームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。ご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。
皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD