2024.04.08
モデル予測に自信がないときに、素直にわからないと答えConformal Predictionに助けてもらおう
こんにちは。AI研究開発室のK.S.(女性、外国人)です。
分類モデルを作成する際に、誤検知を減らすことに苦労していませんか?
具体的には、金融分野での不正検知では、偽陽性(False Positive)によって良い顧客を失う可能性があります。医療分野では、病気ではないにも関わらず病気の特徴があると見なされ、モデルによって病気と判定されてしまう可能性があります。
そういうときに、不正検知や病気の分類モデルでは、予測結果が信頼できない場合に黒と白を分けるよりも、「わからない」ことをグレーとして扱い、信頼できる結果のみを黒白で判断したい、と最近感じています。そのように感じている方は、ぜひこのブログに目を通して頂ければ幸いです。
ということで、今回のブログでは、Conformal Predictionを紹介します。
目次
1. Conformal predictionについて
1.1.Conformal predictionとは?
Conformal predictionとは何かを最近出版されたChristophさんの本をベースにして抜粋します。
Conformal predictionは、簡単に言うと、予測に「どれだけ自信があるか」を数値で示してくれる方法です。普通、何かを予測するときって、この結果になるだろうと一つの答えを出します。でも、Conformal predictionを使うと、「この予測はこんなに自信がありますよ」とか、「ここまでの範囲なら、ほぼ間違いないよ」という信頼の範囲を示してくれます。
やり方としては、まずいつも通りに機械学習モデルにデータから何かを学ぶことからスタートします。それで、新しいデータが来たときに、「これが今までのデータとどれだけ違うか」を数値で示します。これがnon-conformity scoresと呼ばれます。基本的に「この新しいデータ、ちょっと変だな」と思ったらスコアが高くなります。それで、そのスコアをもとに、「このくらいの範囲なら大丈夫」という予測の信頼区間を作ります。
例えば、下記の図のように、イメージから、ピカチュウ、ポッチャマ、チラーミィを分類します。左側の写真だと、簡単にピカチュウとポッチャマを判断できますが、右側の写真だと判断しにくいです。そうすると、conformal predictionは{ピカチュウ}を予測するより、{ピカチュウ、チラーミィ}をセットで予測します。
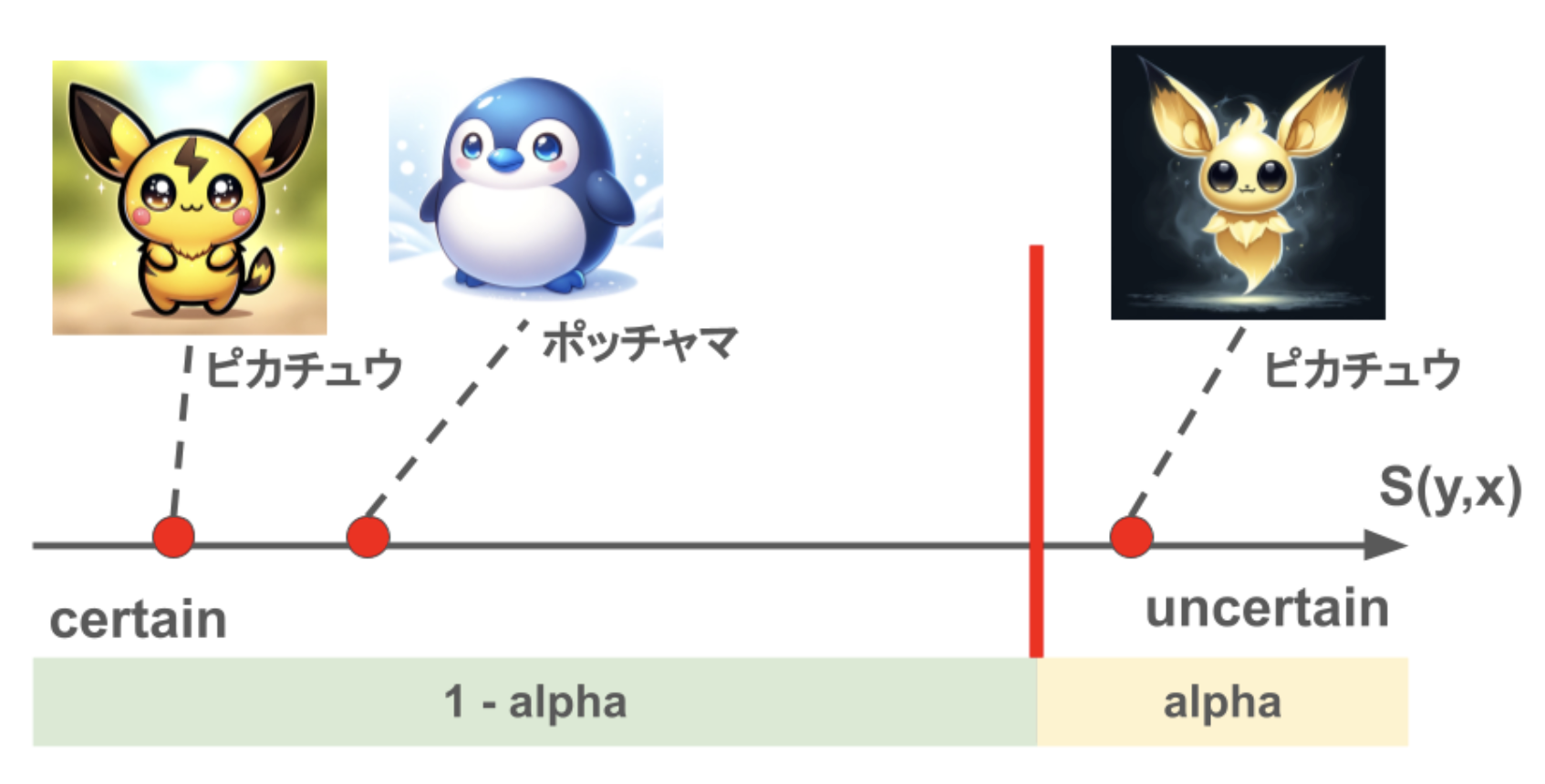
Christophさんの本が販売しているため、勝手に図を転載するのはNGで、コンセプトを真似て、イメージの図を作りました。また、ピカチュウとポッチャマの図はChatGPTのDALL-Eで作成しました。
この方法のいいところは、予測に対する自信の度合いを数値でしっかり示してくれるところです。これがあると、何か判断をするときに、どれだけその予測を信じていいかが分かるので、特に大事な決断をするときに役立ちます。医者が診断を下すときとか、お金に関する予測をするときとか、不正検知を判断するときに、使えるのではないかと期待しています。
1.2.Conformal predictionの具体的なやり方
Conformal predictionには3つのステップがあります。
- Training (トレーニング、学習)
- ここでは、トレーニングデータから、トレーニング用とキャリブレーション用を分けて、トレーニング用データでモデルを学習します
- Calibration (キャリブレーション、調整)
- キャリブレーションデータを利用し、uncertainty scores(non-conformity score)を計算します
- scoreを確実(certain)から不確実(uncertain)へ並びます
- confidence level ?(? = 0.1は90%の範囲を意味する)を決めます
- non-conformity scoreのうち 1−? より小さいquantile ?-hat を探索します
- Prediction (プリディクション、予測)
- 新しいデータ(テスト用データ)のnon-conformity scoreを計算します
- ?-hat 以下のスコアを生成するすべてのy(classificationの場合は、classification class)を選べます
- これらのyが予測セットまたは区間を形成する
2. Conformal predictionで乳がんを予測してみた
それでは、簡単に Conformal predictionを使ってみます。例として、乳がん分類を予測してみたいと思います。
2.1. 実装環境とデータセット
実装環境はGoogle Colaboratoryを利用しました。データセットはScikit-learnの提供しているToy datasetsから取得しました。
2.2. データ取得とデータ処理
簡単な例として、公開されているデータセットを利用したいので、乳がん(Breast cancer)データを取得します。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn import metrics
from sklearn.datasets import load_breast_cancer
data = load_breast_cancer()
print("\ndata.keys(): ", data.keys())
print ("\ndata.feature_names: ", data.feature_names)
print ("\ndata.target_names: ", data.target_names)
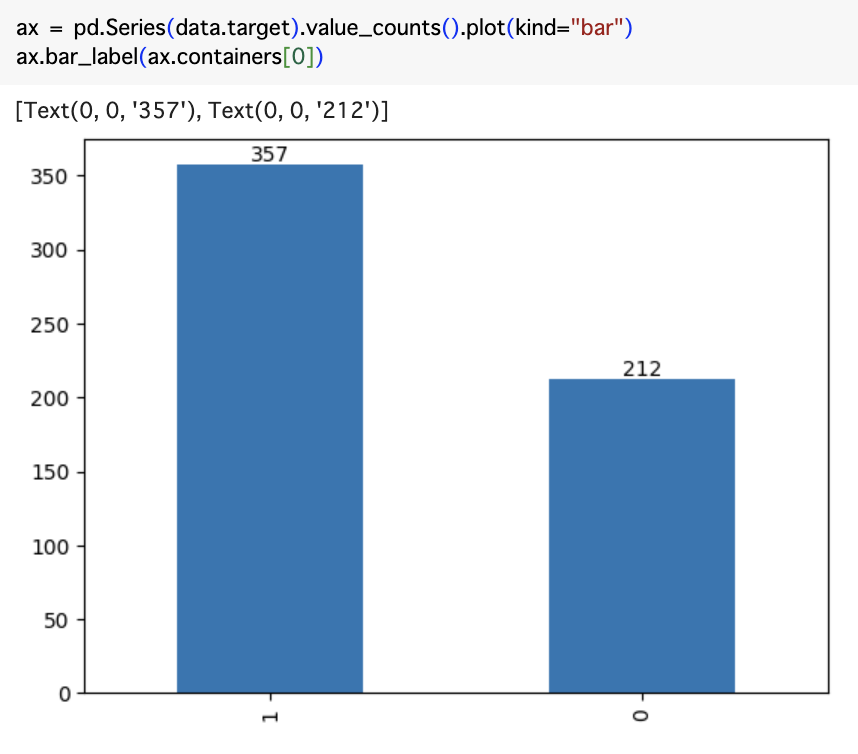
予測のターゲット(Target)はmalignant(悪性、0)とbenign(良性、1)になります。医学的な文脈、特に腫瘍や他の成長物ががんかどうかを表すために使用されます。悪性の腫瘍はがんであり、健康に害を及ぼす可能性があります。良性の腫瘍はがんではなく、通常は健康に害を及ぼすことはありません。
Targetのデータ件数を確認しておきます。
また、特徴量の相関は下記のようになります。
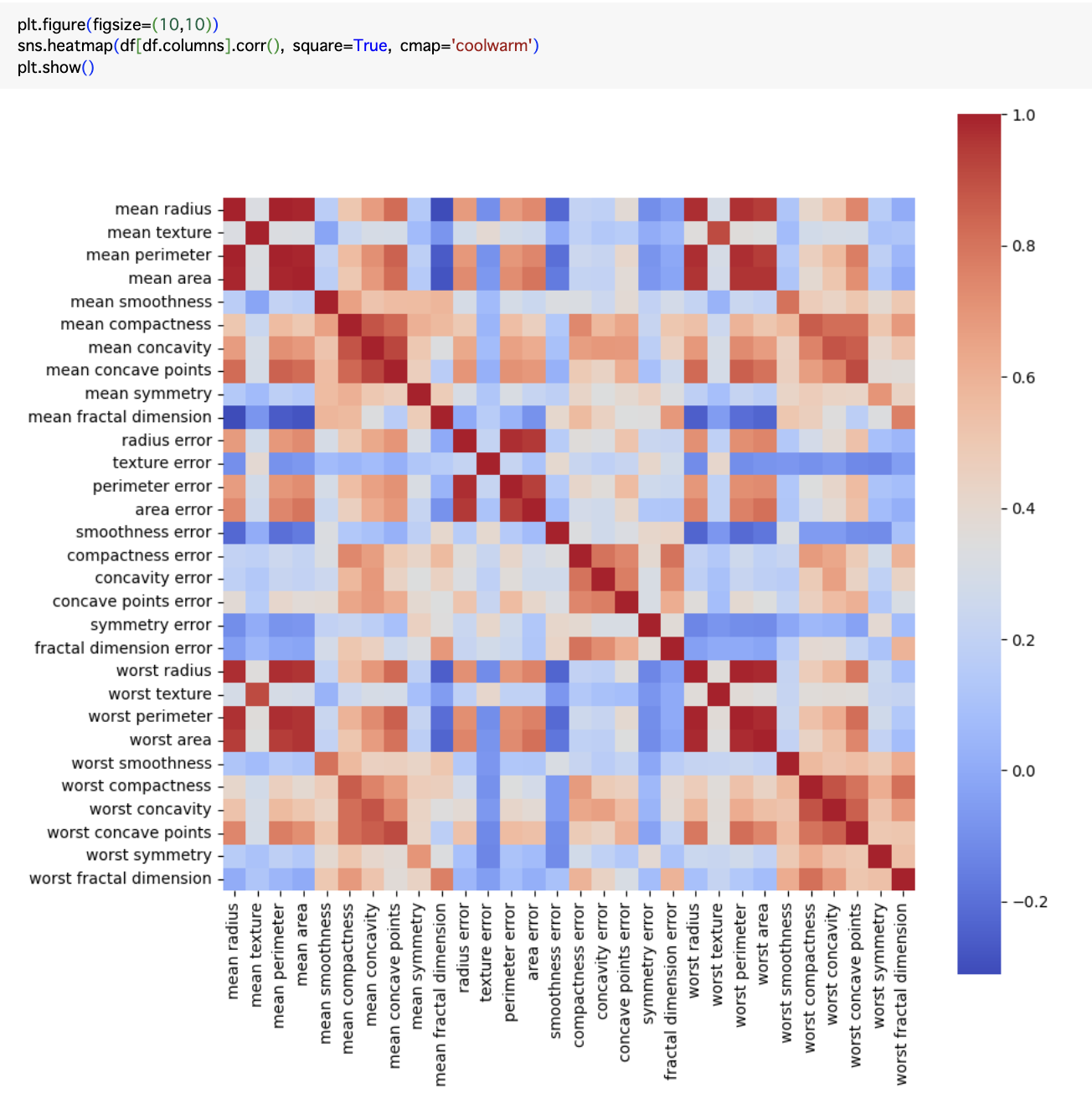
特徴量はたくさんありますが、今回は予測精度が高くないような例をしたいので、特徴量を選んで使いました。また、データセットは上記に説明したように、学習用(train)、調整用(calib)、予測用(test)、の3つに分けました。
X = data.data[:,4:6] # ここは制限しました。 y = data.target X_train, X_rest, y_train, y_rest = train_test_split(X, y, test_size = 0.5, random_state = 42) X_calib, X_test, y_calib, y_test = train_test_split(X_rest, y_rest, test_size = 0.5, random_state = 42) X.shape, y.shape, X_train.shape, y_train.shape, X_calib.shape, y_calib.shape, X_test.shape, y_test.shape
2.3. モデリング
データを用意できましたので、次は簡単なモデルを作成します。GaussianNBを使いました。
from sklearn.naive_bayes import GaussianNB
model = GaussianNB()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
y_pred_proba = model.predict_proba(X_test)
print('*'*20,'Breast cancer dataset','*'*20)
print('Accuracy (training set): {:.2f}'.format(model.score(X_train, y_train)))
print('Accuracy (test set): {:.2f}'.format(model.score(X_test, y_test)))
print("\n Classification report: model => %s: \n%s\n"
% (model, metrics.classification_report(y_test, y_pred)))
print("Confusion matrix:\n")
cm = metrics.confusion_matrix(y_test, y_pred)
metrics.ConfusionMatrixDisplay(confusion_matrix=cm
, display_labels=data.target_names
).plot(xticks_rotation='vertical')
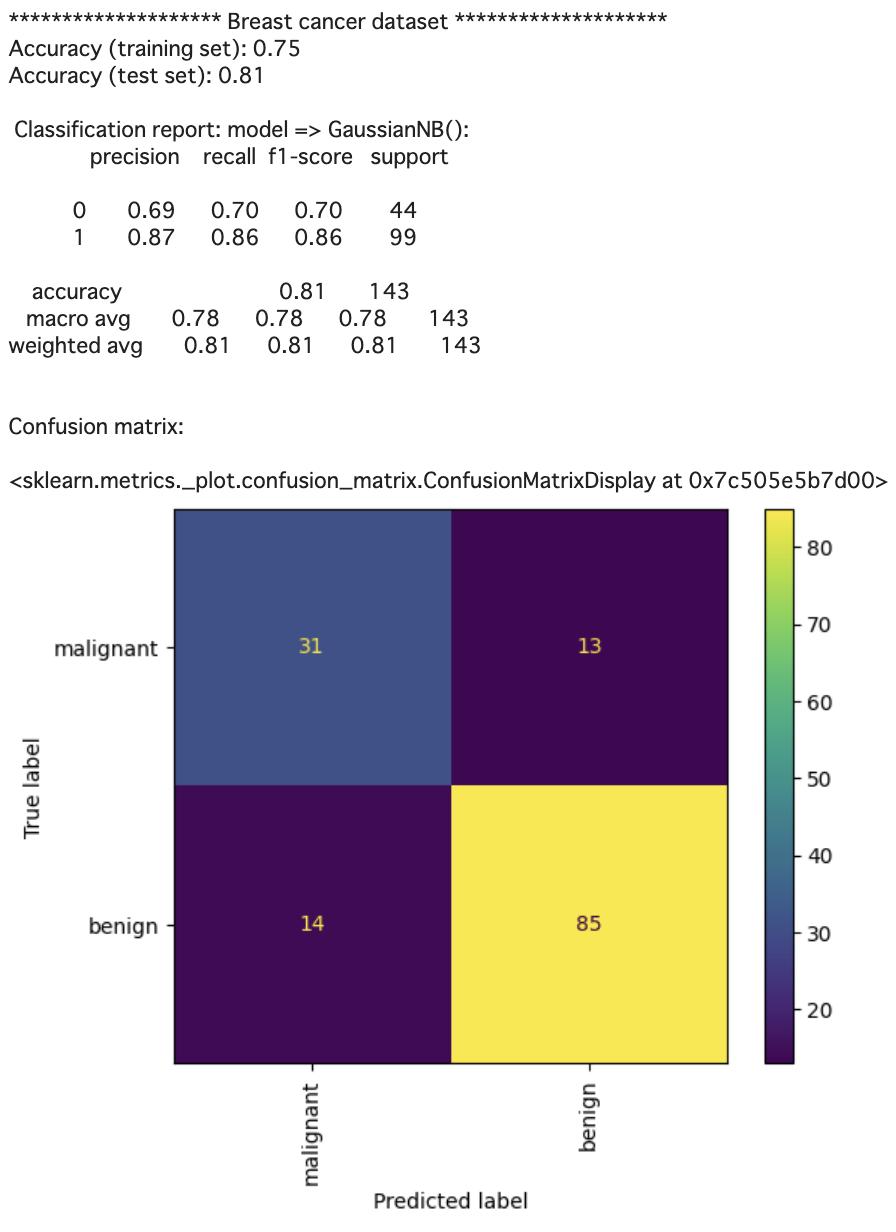
ここまでは、一般的な簡単なモデリングです。
2.4. 簡単にConformal Predictionを試してみた
次に、モデルから「確率」を取得し、uncertainty scoreを計算します。
import matplotlib.pyplot as plt
predictions = model.predict_proba(X_calib)
prob_for_true_class = predictions[np.arange(len(y_calib)),y_calib]
plt.hist(1 - prob_for_true_class, bins=30, range=(0, 1))
plt.xlabel("1 - s(y,x)")
plt.ylabel("Frequency")
plt.show()
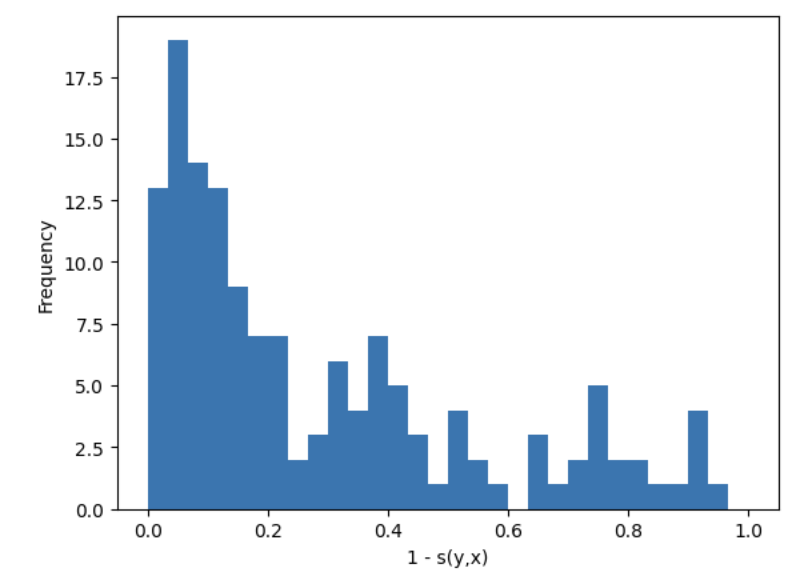
上記のプロットを見て、予測の確率を観察します。人によって、その確率分布を見て、陰性や陽性の閾値を判断してしまうのもあるのではないでしょうか。
簡単なConformal predictionでは、qhatを計算して、判断します。
prediction_sets = (1 – model.predict_proba(X_new) <= qhat)
具体的なコードは下記です。
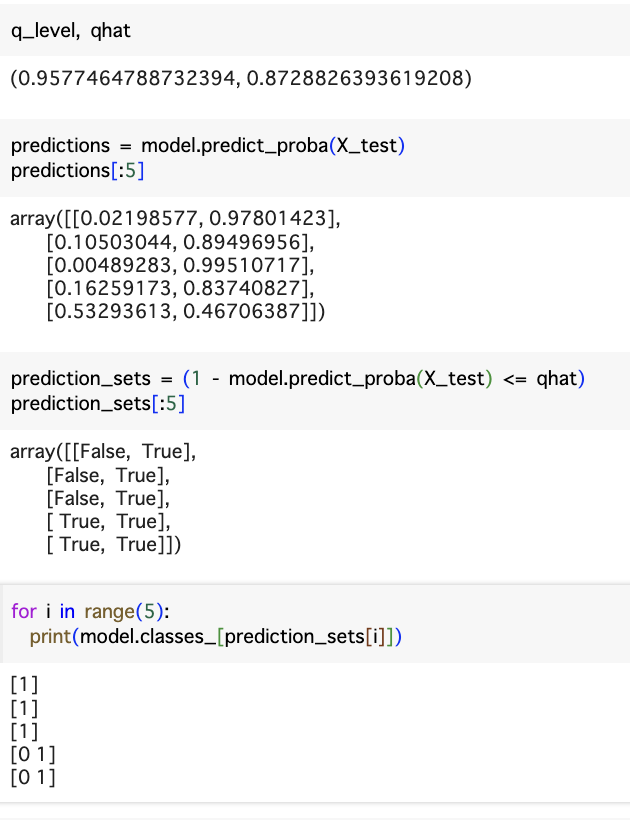
# キャリブレーションデータのサイズを計算 n = len(X_calib) # 予測確率を取得 predictions = model.predict_proba(X_calib) # True classの確率を計算 prob_true_class = predictions[np.arange(n),y_calib] # uncertainty scoreを変換 scores = 1 - prob_true_class # alpha (ここでは、95%)を設定 alpha = 0.05 # quantileを計算 q_level = np.ceil((n+1)*(1-alpha))/n qhat = np.quantile(scores, q_level, method='higher') q_level, qhat
qhat値は0.87が出てきました。それを使って、Class Setsを判断することができます。下記の順番を見ていくと、最初の三つは右のscoresは0.87以上ですので、Classは1での判断になります。一方、4と5行の左も右もscoresが0.87以下で、Classはどちらでも可能と判断になります。
2.5. MapieでConformal Predictionを試してみた
ここから、mapieというConformal PredictionのLibraryを使って試します。
上記の手動と同じですが、一行のコードで済ませることが可能になります。
from mapie.classification import MapieClassifier
from mapie.metrics import classification_coverage_score
from mapie.metrics import classification_mean_width_score
cp = MapieClassifier(estimator=model, cv="prefit", method="score")
cp.fit(X_calib, y_calib)
y_pred, y_set = cp.predict(X_test, alpha=0.05)
y_set = np.squeeze(y_set)
print(y_set[:10])
cov = classification_coverage_score(y_test, y_set)
setsize = classification_mean_width_score(y_set)
print('\nCoverage: {:.2%}'.format(cov))
print('Avg. set size: {:.2f}'.format(setsize))
結果は、Coverage: 96.50%、Avg. set size: 1.45です。
また、イメージを捕まえるため、少し結果を可視化します。
モデル予測確率は下記です。
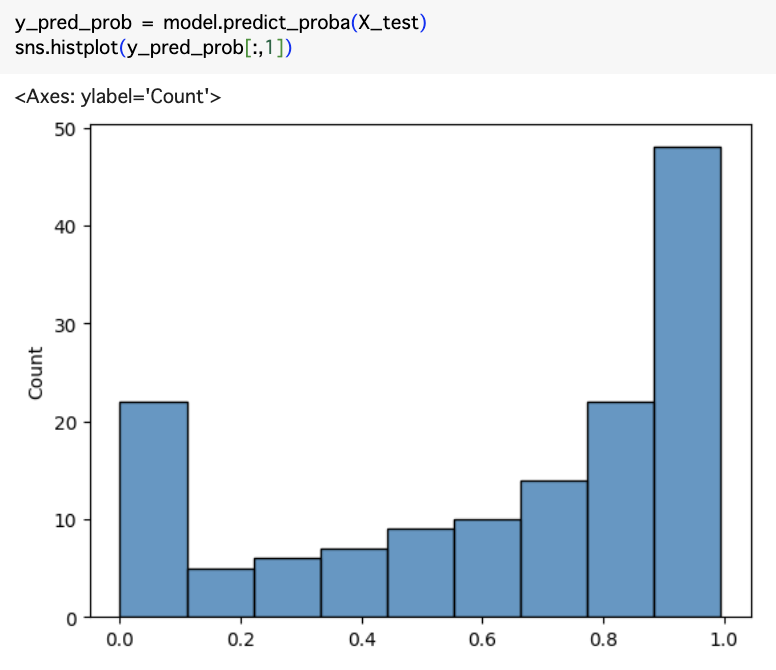
確率から、Conformal Prediction有り無しのモデル予測を見てみます。
y_pred, y_set = cp.predict(X_test, alpha=0.05)
y_set = np.squeeze(y_set)
set_sizes = y_set.sum(axis=1)
print(pd.Series(set_sizes).value_counts())
y_pred_cp = []
print("y_set", y_set.shape, y_set.shape[1])
for i in range(y_set.shape[0]):
if sum(y_set[i])==1:
for j in range(y_set.shape[1]):
if y_set[i][j] == True:
y_pred_cp.append(j)
else:
y_pred_cp.append(0.5)
fig, (ax1,ax2) = plt.subplots(2,1)
ax1.scatter(y_pred_prob[:,1], y_pred)
ax2.scatter(y_pred_prob[:,1], y_pred_cp)
下記のalpha=0.05の図から見ていきます。横軸はモデル予測確率、縦は予測Classです。多くのモデルは上のように、確率=0.5でclassを判断しますが、Conformal Predictionは信頼できる部分をClass判断し、残りはどちらでも可能性があると判断になります。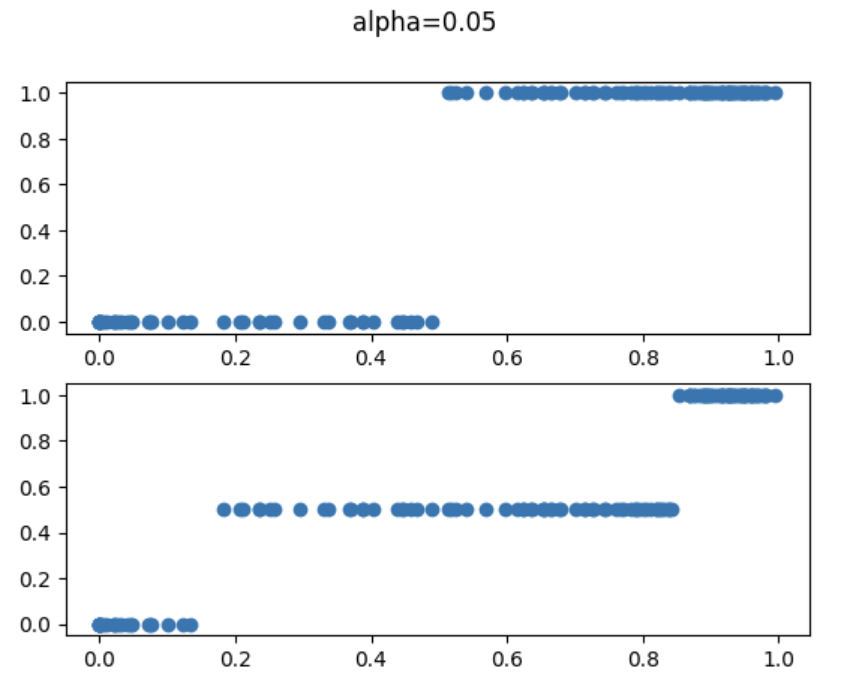
また、alphaの閾値を変更することで、信頼範囲を調整することが可能になるということがわかります。
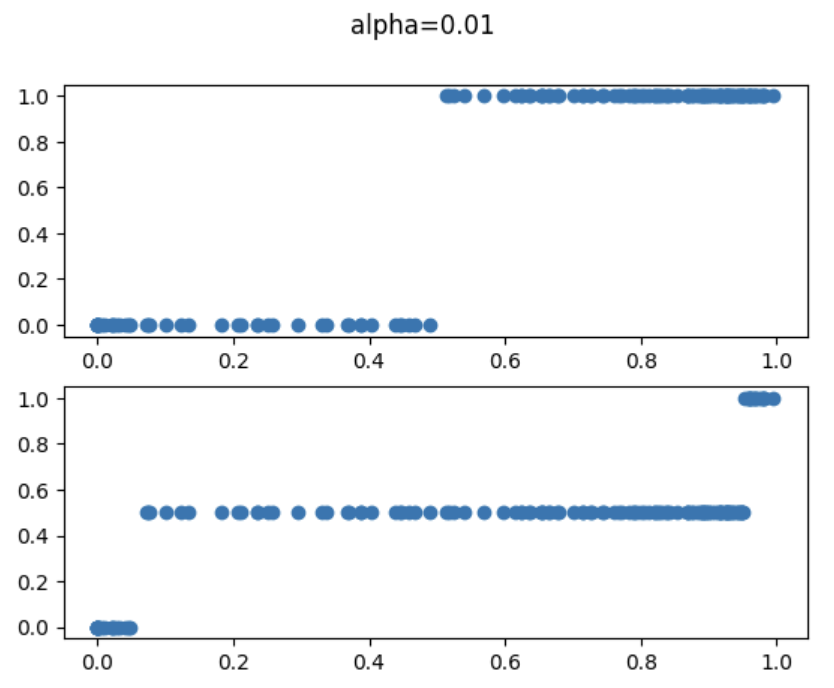
3. まとめ
Conformal Predictionを紹介しました。コンセプトは簡単ですが、個人的に実用性は感じています。今回は一番簡単なやり方を試しましたが、データサイズやClassの個数などによって、細かく様々な適切手法があります。
また、今回はClassificationのみの適用を話しましたが、Regressionに適用する手法もあります。
最後に
グループ研究開発本部 AI研究開発室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務などAI研究開発室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧からご応募をお願いします。皆さんのご応募をお待ちしています。
また、老化に興味がある方は是非、【新規プロジェクト】データサイエンティストに応募してください。
一緒に勉強しながら楽しく働きたい方のご応募をお待ちしております。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD