2024.01.10
Cloud Run jobsへの移行検討
こんにちは。次世代システム研究室のM.Mです。
バッチを定期的に実行したい場合、古いシステムであれば、バッチサーバーを用意して、cronを利用して定期的にバッチを実行させるケースが多いのではないでしょうか?
私が担当しているサービスのバッチも全てではありませんが、バッチサーバー上でcronを利用して定期的にバッチを実行しています。
ただサービスが大きくなるにつれ、バッチの数も増え、また負荷の高いバッチも動いている状況になってきます。
そのような状況の中、さらに新しいバッチを追加したいとなった場合、他の既存バッチに影響がでないように、バッチサーバーが高負荷にならないか?メモリ不足にならないか?そのためにはいつバッチを実行すればよいか?
などの検討も必要になってきます。
さらに新しいバッチは短時間で終わらせる要件があった場合、バッチサーバーのリソースを多く使って、短時間で終わらせるといった選択もしにくいです。
バッチサーバーを増やしていけば対応できると思いますが、担当しているプロジェクトがGoogle Cloud Platformを使っていることもあり、また、以前、プレビュー段階でしたがGCP BatchとCloud Run jobsを少し試したこともあったため、今回はCloud Run jobsでバッチを動かすことを検討しました。
■条件
- 今まで通り、バッチサーバー上のcronを使ってバッチ実行を行う
- ただし、バッチ処理自体はバッチサーバー上で動くのではなく、Cloud Run jobsで動くようにする
- 既存バッチに影響を及ぼさないように、バッチサーバーへの新たなインストールやアップデートは行わないこととする
以下、バッチプログラム、ジョブといった記載がでてきてややこしいですが、Cloud Run jobsではバッチという言い方はしません。
Cloud Runにジョブを作成する、ジョブを実行するといった言い方となります。
なので実際に業務ロジックが書かれたプログラム(今回はPythonのプログラム)をバッチプログラムと言うようにします。
Cloud Runに作成したジョブを実行すると、ジョブに設定したバッチプログラムが動くと思ってもらえればよいかと思います。
1. Cloud Runにジョブを作成する
前回のブログでは、GCPのWEB管理コンソールを利用して理解を深めていきましたが、今回は実用に向けての対応をしていきたいので、ジョブの作成や実行を行うのにGCPのWEB管理コンソールは使いません。
■やること
- バッチプログラムごとにDockerイメージを作るのではなく、1つのDockerイメージ内に複数のバッチプログラムを配置し、引数を指定することで実行するバッチプログラムを選択できるようにする
- gcloudコマンドでCloud Runのジョブ作成を行う
■バッチプログラムの構成について
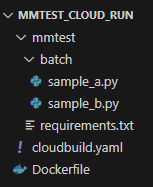
バッチプログラムとしてsample_a.py、sample_b.pyの2つ用意しています。
■各種ファイルについて
・Dockerfile
FROM python:3.11-slim COPY ./mmtest /mmtest WORKDIR /mmtest RUN pip install --no-cache-dir -r requirements.txt ENTRYPOINT ["python"] CMD ["sample_a.py"]
デフォルトでsample_a.pyが実行されるようになっていますが、Cloud RunのジョブはCMDを変更して実行することができるので、CMDの設定次第で、異なるバッチプログラムを実行できるようになります。
・cloudbuild.yaml
steps:
- name: "gcr.io/cloud-builders/docker"
args:
[
"build",
"-t",
"asia-northeast1-docker.pkg.dev/PROJECT_ID/mmtest-cloud-run/mmtest-${_ENV}:latest",
".",
]
env:
images:
[
"asia-northeast1-docker.pkg.dev/PROJECT_ID/mmtest-cloud-run/mmtest-${_ENV}:latest",
]
Cloud Buildを使って、ビルド及びリポジトリにプッシュするための設定ファイルです。
STG環境用、本番環境用とで分ける程度のことはするようにしています。
・requirements.txt
click==8.1.7
バッチプログラムで使うモジュールです。
今回はサンプルのバッチプログラムなので、clickモジュールしか入れていません。
・sample_a.py
import click
@click.command()
def sample_a():
print('SAMPLE A')
if __name__ == '__main__':
sample_a()
SAMPLE Aと出力するだけです。
・sample_b.py
import click
import time
@click.command()
@click.argument('sleep_time', type=int)
@click.argument('message', type=str)
def sample_b(sleep_time: int, message: str):
print('SAMPLE B')
if message == 'error':
raise Exception('Error Test')
time.sleep(sleep_time)
if __name__ == '__main__':
sample_b()
引数にsleep_time, messageを受け取るバッチプログラムです。
■Dockerイメージの作成およびリポジトリにプッシュします
export env=staging
gcloud builds submit --config=cloudbuild.yaml --substitutions="_ENV=${env}" .
■Cloud Runにジョブを作成する
上記にて作成したDockerイメージをもとにCloud Runにジョブを作成します。
・バッチプログラム(sample_a.py)を実行するジョブを作成する
export env=staging
gcloud run jobs create sample-a-${env}
--image asia-northeast1-docker.pkg.dev/PROJECT_ID/mmtest-cloud-run/mmtest-${env}:latest
--labels "mmtest_batch_name=sample-a-${env}"
--args batch/sample_a.py
--cpu 1
--memory 1Gi
--max-retries 3
--parallelism 1
--tasks 1
--task-timeout 10m
--region asia-northeast1
--set-env-vars "APP_MODE=${env},PYTHONPATH=/mmtest"
・バッチプログラム(sample_b.py)を実行するジョブを作成する
export env=staging
gcloud run jobs create sample-b-${env}
--image asia-northeast1-docker.pkg.dev/PROJECT_ID/mmtest-cloud-run/mmtest-${env}:latest
--labels "mmtest_batch_name=sample-b-${env}"
--args batch/sample_b.py,120,hogehoge
--cpu 1
--memory 1Gi
--max-retries 3
--parallelism 1
--tasks 1
--task-timeout 10m
--region asia-northeast1
--set-env-vars "APP_MODE=${env},PYTHONPATH=/mmtest"
大きな違いは、–argsの箇所です。sample_b.pyは引数を受け取るバッチプログラムにしているので、カンマ区切りで引数を設定できます。
また、今回は120, hogehogeと引数を設定しているので、sample_b.pyのsleep_timeに120、messageにhogehogeと値が設定されることになります。
とはいえ、あくまでもデフォルトの引数であり、実際にCloud Runに作成したジョブを実行する際は、異なる引数の値で実行することになります。
また、後述しますが、–labelsを指定することも重要になってきます。
また、今回はサンプルプログラムなので、省略していますが、実際にはCloud SQLと連携し、そのパスワードをシークレットマネージャーで管理しているバッチプログラムも存在しています。
シークレットマネージャーやVPCコネクトの設定はしている前提ではありますが、以下のようなパラメータをつけてジョブを作成すればよいです。
--set-secrets "MMTEST_DB_PASS=mmtest-db-pass-${env}:1"
--set-cloudsql-instances mmtest-db-${env}
--vpc-connector mmtest-connector
--service-account mmtest@PROJECT_ID.iam.gserviceaccount.com
利用するサービスアカウントに、Cloud SQL クライアント、Secret Manager のシークレット アクセサーのロールを与えれば接続可能となります。
これで、Cloud Runへのジョブ作成が完了しました。
引数で実行するバッチプログラムを指定できるようにしているので、バッチプログラムごとにCloud Runのジョブを作成する必要はないのですが、バッチプログラムごとに必要となるCPUやメモリは異なってくるので、バッチプログラムごとにCloud Runのジョブを作ることにしました。
バッチプログラムごとにCloud Runのジョブを作成するのは面倒に思えますが、バッチプログラムの変更があるたびに、Cloud Runのジョブを作り直す必要はありません。
Cloud Runに作成したジョブはDockerイメージのlatestを利用するようにしているので、Dockerイメージの作成およびリポジトリにプッシュを行うだけで、次回Cloud Runのジョブが実行されるタイミングで最新のDockerイメージで実行されるようになります。
(もちろん、CPUやメモリ、Cloud Runのジョブ実行環境の構成を変える場合は、Cloud Runに作成したジョブの設定を変更する必要はあります。)
では、バッチサーバーからCloud Runに作成したジョブを実行していきます。
2. バッチサーバーからCloud Runに作成したジョブを実行する
バッチサーバーからジョブを実行するには、
- gcloud run jobsコマンド
- クライアントライブラリ
- API
のいずれかを利用することになります。
コマンドラインによる実行が楽そうではありますが、利用しているバッチサーバーにインストールされているGoogle Cloud SDKのバージョンが低く、gcloud run jobsコマンドが使えませんでした。
Google Cloud SDKのアップデートをして既存のバッチプログラムがエラーになったこともあるので、アップデートも気軽にできない。
またバッチサーバー上で利用しているプログラミング言語のバージョンも低く、クライアントライブラリが対応していないという。
既存のバッチプログラムが動いているバッチサーバーでバージョンアップ作業はしたくなかったので、Cloud RunのジョブをバッチサーバーからAPI経由で実行させるだけのCloud Runジョブ実行用プログラムを作ることにしました。
Cloud Runに作成したジョブを実行させるプログラム(API実行部分のみ)
def run_job(self, job_name, cmd_args):
endpoint = 'https://{}-run.googleapis.com/apis/run.googleapis.com/v1/namespaces/{}/jobs/{}:run'.format(self.REGION, self.PROJECT_ID, job_name)
id_token = self._get_token()
headers = {
"Authorization": "Bearer {}".format(id_token)
}
body = None
if len(cmd_args) > 0:
params = {
"overrides": {
"containerOverrides": {
"args": cmd_args
}
}
}
body = json.dumps(params)
res = requests.post(endpoint, body, headers=headers)
if res.status_code != 200:
raise Exception(
'Failed to execute cloud run jobs({}), status code: {}, res: {}'.format(job_name, res.status_code, res.content)
)
else:
result = json.loads(res.content.decode('utf-8'))
return result['metadata']
APIはこちらを利用しています。
認証処理部分は省略していますが、3行目のself._get_token()でid_tokenを取得しています。
また、既存のバッチプログラムで利用しているサービスアカウントもありましたが、極力変更したくなかったので、Cloud Runのジョブ実行用のCloud Run 管理者のロールのみをもったサービスアカウントを作って、そのサービスアカウントの鍵を利用してAPIを実行することにしました。
注目箇所としては、10~14行目のargsをオーバーライドしている設定になります。
Cloud Runのジョブ作成時に、以下のパラメータをつけて作成したかと思います。
--args batch/sample_b.py,120,hogehoge
この値は上記12行目のargsに新たな値を設定することで、バッチ実行のたびに書き換えることができるので、日次バッチプログラムなど、実行する日によって引数が変わるようなバッチプログラムだったとしても、Cloud Runに作成したジョブを変更することなく実行することができます。
Cloud RunのジョブをAPI経由で実行させるプログラムを作り、バッチサーバー上で実行することで、Cloud Runに作成したジョブを実行することができました。
ただ連続して実行すると、Cloud Runのジョブは多重で実行されていきます。(特にキューにたまって順次実行されていくということはありませんでした。)
cronで実行することを想定しているので、短い間隔で定期実行されるようなバッチプログラムの場合、多重で実行されてしまうことも想定されます。
そのため、ジョブを実行する前に、実行中のジョブがないか確認する制御をいれていきます。
3. Cloud Runに作成したジョブが多重実行されないようにする
Cloud Run jobsの実行履歴を確認できるAPIが存在しています。
APIはこちらを利用しています。
ただ、このAPIのパラメータでうまくフィルターをかけないとすべてのジョブに対する実行履歴が取得されてしまいます。
そこで活躍するのが、Cloud Runのジョブ作成時に以下のように指定したラベルになります。
--labels "mmtest_batch_name=sample-b-${env}"
指定したジョブが実行中であるか確認するプログラム(API実行部分のみ)
def check_running_job(self, job_name):
params = {
'limit': 3,
'labelSelector': 'mmtest_batch_name={}'.format(job_name)
}
endpoint = 'https://{}-run.googleapis.com/apis/run.googleapis.com/v1/namespaces/{}/executions'.format(self.REGION, self.PROJECT_ID)
id_token = self._get_token()
headers = {
"Authorization": "Bearer {}".format(id_token)
}
res = requests.get(endpoint, headers=headers, params=params)
if res.status_code != 200:
raise Exception(
'Failed to get cloud run jobs({}), status code: {}, res: {}'.format(job_name, res.status_code, res.content)
)
else:
result = json.loads(res.content.decode('utf-8'))
for item in result.get('items', []):
for cond in item['status']['conditions']:
if cond['type'] == 'Completed':
if cond['status'] in ["True", "False"]:
print('{}: finished'.format(item['metadata']['name']))
else:
raise Exception('{} is currently in progress. Multiple executions are not allowed.'.format(item['metadata']['name']))
注目箇所は4行目のlabelSelectorにCloud Runのジョブ作成時に設定したラベル名を設定しているところです。
そうすることで、確認したいジョブの実行履歴だけに絞ることができます。
また、3行目のlimitにて、最新3件の履歴だけ確認するようにしています。
後は、APIのレスポンスにある、typeがCompletedになっているデータのstatusを確認することで、実行中のジョブがあるかどうか確認することができます。
Cloud Runのジョブを実行する前にこの処理を追加しておくことで、実行中のジョブがあると例外が発生するので、ジョブが多重に実行されないように制御することができました。
(cronで定期実行を想定しているので、同時実行するとどうなるのかなどの確認はしていません。)
ただ、APIでジョブを実行すると、実行が完了するまで待ってくれないため、いつ完了するかよく分かりません。
cronではなくワークフローなどで依存関係を維持しつつバッチプログラムを実行したいといった場合に使えません。
続いて、ジョブを実行後、定期的に実行状況を確認し、完了するまで待つような処理を追加したいと思います。
4. 実行したジョブが完了するまで待つようにする
gcloud run jobs executeコマンドでジョブを実行する場合、–waitオプションをつけることで、ジョブが完了するまでコマンドを待機させることができますが、API経由でジョブを実行する場合、ジョブの完了を待つことはできません。
そのため、今回もAPIを使って、実行状況を確認するようにします。
APIはこちらを利用しています。
API経由でジョブを実行するとレスポンスから実行したジョブの実行IDを取得することができます。
その実行IDを利用して、実行状況の確認を行います。
指定した実行IDのジョブが実行中であるか確認するプログラム(API実行部分のみ)
def is_completed(self, execution_id):
endpoint = 'https://{}-run.googleapis.com/apis/run.googleapis.com/v1/namespaces/{}/executions/{}'.format(self.REGION, self.PROJECT_ID, execution_id)
id_token = self._get_token()
headers = {
"Authorization": "Bearer {}".format(id_token)
}
res = requests.get(endpoint, headers=headers)
if res.status_code != 200:
raise Exception(
'Failed to get cloud run jobs({}) result, status code: {}, res: {}'.format(execution_id, res.status_code, res.content)
)
else:
result = json.loads(res.content.decode('utf-8'))
for cond in result.get('conditions', []):
if cond['type'] == 'Completed':
if cond['status'] == 'True':
return True
elif cond['status'] == 'False':
raise Exception('cloud run jobs({}) failed'.format(execution_id))
else:
return False
実行が完了しているかどうかは、typeがCompletedになっているデータのstatusを確認することで判断ができます。
この処理をCompletedのstatusがTrueかFalseになるまで繰り返せば、実行したジョブが完了したかどうかの判断はできます。
ただ、繰り返すといっても、無限ループで、APIを実行しまくるのもどうかと思うので、数分間隔でAPIを実行し実行結果を確認、ある程度の時間が経過してもジョブが完了しない場合は、エラーとして扱うなどの検討は必要になりそうです。
5. まとめ
APIでCloud Runのジョブを実行できるので、バッチサーバーのcronによる定期実行にこだわる必要はまったくないですが、既存のバッチサーバーの利用方法(cronでバッチプログラムを動かす)は変えず、バッチプログラムの実行環境だけCloud Run jobsに移行することができそうなことは分かりました。
実際に、既存のバッチプログラムをCloud Run jobsに移行して運用するとなるとCloud Run jobs特有の問題が発生するかもしれませんし、既存のバッチプログラムを冪等性を意識したものに変える必要があったり、永続ディスクを利用しているバッチプログラムは見直しが必要になるかもしれません。
そのため既存バッチプログラムの移行には多くの工数がかかってしまうかもしれませんが、新しいバッチプログラムを追加するような場合、既存のバッチサーバーのリソースを意識する必要なく追加することができるのは、大きなメリットだと感じます。
また、利用するDockerのイメージを変えることで、ジョブごとにバッチプログラムの実行環境を変えることができるため、利用するプログラミング言語やモジュールのバージョンアップもやりやすいとも思えました。
最後に、次世代システム研究室では、グループ全体のインテグレーションを支援してくれるアーキテクトを募集しています。アプリケーション開発の方、次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ募集職種一覧からご応募をお願いします。
皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD