2025.04.08
Building a Terminal LLM Chat App with Python & Asyncio
こんにちは、次世代システム研究室のN.M.です。
Ever wished you could chat with powerful Large Language Models (LLMs) like OpenAI’s GPT series without leaving the comfort and efficiency of your terminal? I found myself wanting exactly that – minimizing context switching and keeping my workflow contained.
That sparked the idea for TermTalk, a terminal-based chat application, I built in Python. Today, I want to take you on a tour of its source code. We won’t just talk concepts; we’ll look at the actual implementation using libraries like asyncio, prompt-toolkit, and openai. My hope is that by seeing how TermTalk is built, you’ll feel empowered to create your own, similar command-line tools.
The Core Features
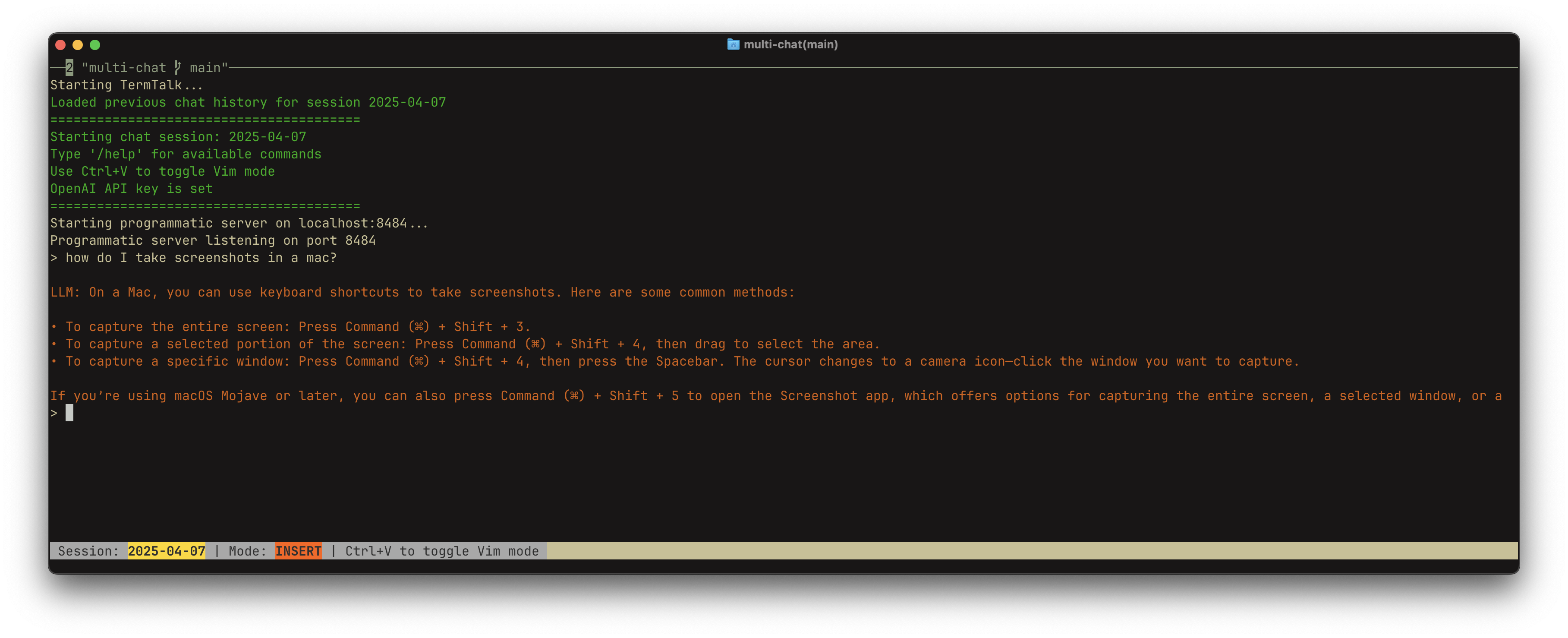
TermTalk, as shown in the code below, provides:
-
Interactive Terminal Chat: A rich interface using prompt-toolkit for a smooth chat experience, including command history, slash commands, multiline input, and even Vim/Emacs mode toggling.
-
Persistent Chat Sessions: Conversations are grouped by session ID (defaulting to the current date). History is maintained for context and automatically saved/loaded from JSON files.
-
LLM Integration: Connects asynchronously to the OpenAI API using the official openai library.
-
Programmatic TCP Server: Optionally runs a TCP server allowing other clients (or scripts) to connect and interact with the same chat session via a simple length-prefixed JSON protocol.
-
Graceful Shutdown: Handles signals (like Ctrl+C) to save history and shut down cleanly.
Let’s Dive into the Code!
1. Talking to the LLM: send_to_llm
This asynchronous function is the bridge to OpenAI.
# Snippet from send_to_llm
async def send_to_llm(model: str, message: str, session_id: str = None) -> str:
# ... (session ID handling, API key check) ...
# Initialize conversation history for this session if it doesn't exist
if session_id not in chat_history:
logger.info(f"Creating new conversation history for session {session_id}")
chat_history[session_id] = []
# Add user message to history
chat_history[session_id].append({"role": "user", "content": message})
# Use the global OpenAI async client (initialized elsewhere)
if not hasattr(openai, 'async_client'):
openai.async_client = openai.AsyncOpenAI(api_key=openai.api_key)
try:
logger.info(f"Calling OpenAI API with model={model}, messages={len(chat_history[session_id])}")
response = await openai.async_client.chat.completions.create(
model=model,
messages=chat_history[session_id] # Crucial: Sends the history
)
# ... (logging) ...
# Extract the response and add it to history
if response.choices:
assistant_response = response.choices[0].message.content
chat_history[session_id].append({"role": "assistant", "content": assistant_response})
logger.info(f"Added assistant response to history for session {session_id}")
return assistant_response
return ""
except Exception as e:
# ... (error handling) ...
-
Key Concepts:
-
async def and await: Essential for non-blocking I/O. The API call won’t freeze the rest of the application.
-
openai.AsyncOpenAI(): The modern way to use the OpenAI library asynchronously.
-
chat_history: A dictionary holding lists of messages ({“role”: “user/assistant”, “content”: “…”}) for each session ID. This is the context sent to the API with every request.
-
Appending User & Assistant Messages: The function carefully adds both the user’s prompt and the LLM’s subsequent response to the chat_history list for that session.
-
2. The Interactive Terminal UI: interactiveinput
This is where prompt-toolkit shines, creating a rich TUI experience.
# Snippet from interactiveinput - Setup
from prompt_toolkit import PromptSession, print_formatted_text
from prompt_toolkit.history import InMemoryHistory
from prompt_toolkit.key_binding import KeyBindings
# ... other imports
async def interactiveinput(model: str, shutdown_event: asyncio.Event, session_id: str = None):
# ... (session ID handling, history loading) ...
# Setup completer, keybindings, styles (see full code)
# ... CommandCompleter, key_bindings (Ctrl+J, Ctrl+V toggle), STYLES ...
session = PromptSession(
history=input_history,
completer=command_completer,
key_bindings=key_bindings,
multiline=True, # Allow multiline input
vi_mode=True, # Enable VI mode support (toggle with Ctrl+V)
bottom_toolbar=get_bottom_toolbar, # Show session/mode status
style=STYLES, # Apply custom colors
# ... other options like mouse_support, complete_while_typing
)
global global_app_instance # To allow programmatic server to print
if hasattr(session, 'app'):
global_app_instance = session.app
# Main input loop
while not shutdown_event.is_set():
try:
message = await session.prompt_async("> ", refresh_interval=0.05) # Async prompt
if not message or not message.strip(): continue
# Handle slash commands
if message.startswith('/'):
if message.lower() in ("/exit", "/quit"):
shutdown_event.set()
break
elif message.lower() == "/help": # Display help
# ... print help text ...
continue
elif message.lower() == "/history": # Show history
# ... print chat_history[session_id] ...
continue
elif message.lower() == "/save": # Save history
save_chat_history(session_id)
# ... update completer ...
continue
elif message.lower() == "/sessions": # List saved sessions
# ... print list_available_sessions() ...
continue
elif message.lower().startswith("/load "): # Load session
# ... save current, update session_id, load_chat_history(), update completer ...
continue
# Add other commands here
# If not a command, send to LLM
output = await send_to_llm(model, message, session_id)
print_formatted_text(FormattedText([('class:assistant', f"LLM: {output}")]), style=STYLES)
except Exception as e:
# ... (error handling) ...
-
Key Concepts:
-
prompt_toolkit.PromptSession: The core object managing the interactive prompt.
-
async prompt_async: Gets user input without blocking the event loop.
-
multiline=True: Allows typing multi-line messages before submitting (often with Meta+Enter or Esc -> Enter).
-
KeyBindings: Customizes keyboard shortcuts (e.g., Ctrl+J for newline, Ctrl+V to toggle Vim/Emacs editing modes).
-
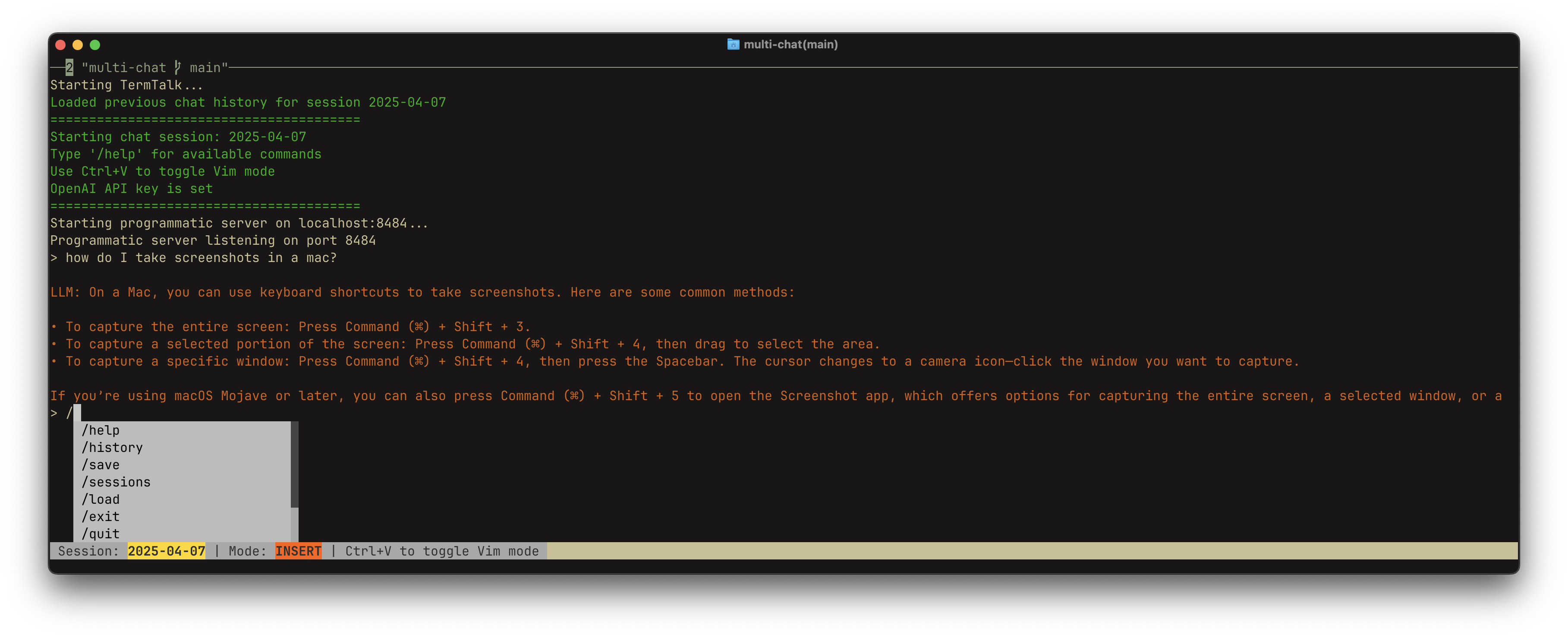
Completer: Provides tab-completion for slash commands (CommandCompleter).
-
bottom_toolbar: Displays useful info like the current session ID and editing mode.
-
Style: Defines custom colors for different message types (info, user, assistant, etc.).
-
print_formatted_text: Used to print output with the defined styles, ensuring it integrates nicely with the prompt.
-
Slash Commands: Simple if/elif logic parses commands like /history, /save, /load.
-
3. The TCP Server: start_programmatic_server & handle_programmatic_input
This allows external scripts/apps to interact.
# Snippet from handle_programmatic_input
import struct
from pydantic import BaseModel
class MyMessage(BaseModel): # Using Pydantic for validation
payload: str
async def handle_programmatic_input(reader: asyncio.StreamReader, writer: asyncio.StreamWriter, model: str, session_id: str = None):
# ... (logging, session ID handling, history loading) ...
try:
while True:
# Read 4 bytes for length prefix
length_bytes = await reader.readexactly(4)
length = struct.unpack('>I', length_bytes)[0] # Big-endian unsigned integer
# Read the JSON payload
data = await reader.readexactly(length)
# Deserialize and validate using Pydantic
message = MyMessage.model_validate_json(data.decode('utf-8')).payload
# ... (skip empty messages) ...
output = await send_to_llm(model, message, session_id) # Use same LLM function
# Optional: Echo to the interactive terminal if running
if global_app_instance:
# ... print_formatted_text(...) ...
# Send response back to TCP client (append newline for simple clients)
writer.write((output + "\n").encode())
await writer.drain()
# ... (logging) ...
# ... (error/disconnect handling) ...
finally:
writer.close()
await writer.wait_closed()
# Snippet from start_programmatic_server
async def start_programmatic_server(model: str, host: str, port: int, shutdown_event: asyncio.Event, session_id: str = None):
# ... (port conflict handling loop) ...
server = await asyncio.start_server(
lambda r, w: handle_programmatic_input(r, w, model, session_id), # Pass handler
host, current_port
)
async with server:
await shutdown_event.wait() # Keep server running until shutdown
# ... (server closing logic) ...
-
Key Concepts:
-
asyncio.start_server: Creates the TCP server using asyncio’s high-level streams API.
-
asyncio.StreamReader, asyncio.StreamWriter: Used within the handler to read from and write to the client socket asynchronously.
-
Length Prefixing (struct.pack/unpack): A common pattern in TCP to know how many bytes to read for the actual message payload. Here, it reads 4 bytes to get the length, then reads exactly that many bytes.
-
JSON Payload: The actual message is sent as a JSON string.
-
Pydantic (BaseModel): Provides data validation for the incoming JSON, ensuring it has the expected structure ({“payload”: “…”}).
-
Sharing Session: Crucially, handle_programmatic_input calls the same send_to_llm function using the same session_id, meaning TCP clients interact with the exact same conversation context as the interactive user (if the session IDs match).
-
4. Session Management: Saving & Loading History
Persistence is handled via simple JSON files.
import pathlib
import json
HISTORY_DIR = pathlib.Path.home() / '.local' / 'share' / 'term-talk'
def get_history_file_path(session_id: str) -> pathlib.Path:
return HISTORY_DIR / f"{session_id}.json"
def list_available_sessions() -> list:
HISTORY_DIR.mkdir(parents=True, exist_ok=True)
return sorted([p.stem for p in HISTORY_DIR.glob('*.json')])
def load_chat_history(session_id: str) -> bool:
file_path = get_history_file_path(session_id)
if not file_path.exists(): return False
try:
with open(file_path, 'r') as f:
history = json.load(f)
chat_history[session_id] = history # Load into memory
return True
except Exception as e: # Handle errors
# ... (logging) ...
return False
def save_chat_history(session_id: str):
HISTORY_DIR.mkdir(parents=True, exist_ok=True)
if session_id not in chat_history: return
file_path = get_history_file_path(session_id)
try:
with open(file_path, 'w') as f:
json.dump(chat_history[session_id], f, indent=2) # Save history list
except Exception as e:
# ... (logging) ...
-
Key Concepts:
-
pathlib: Modern way to handle file paths.
-
JSON: Simple, human-readable format for storing the list of chat messages.
-
~/.local/share/term-talk: Standard location for user-specific application data on Linux/macOS.
-
Session ID as Filename: Each session’s history is stored in a file named [session_id].json.
-
Load/Save Logic: Functions handle reading/writing the JSON data and populating/saving the in-memory chat_history dictionary.
-
5. Orchestration & Shutdown: main and asyncio
The main function sets everything up and manages the asynchronous tasks.
import argparse
import signal
import asyncio
def main():
# ... (argparse setup) ...
args = parser.parse_args()
shutdown_event = asyncio.Event() # Event to signal shutdown
loop = asyncio.get_event_loop()
# Handle Ctrl+C (SIGINT) and SIGTERM for graceful shutdown
for sig in (signal.SIGINT, signal.SIGTERM):
loop.add_signal_handler(sig, shutdown_event.set)
try:
async def main_runner():
# Create tasks for interactive input and the TCP server
interactive_task = asyncio.create_task(interactiveinput(args.model, shutdown_event, args.session))
tasks = [interactive_task]
if True: # Assuming server is always attempted
server_task = asyncio.create_task(start_programmatic_server(...))
tasks.append(server_task)
# Wait for any task to finish OR the shutdown event
shutdown_wait_task = asyncio.create_task(shutdown_event.wait())
tasks.append(shutdown_wait_task)
done, pending = await asyncio.wait(tasks, return_when=asyncio.FIRST_COMPLETED)
# Trigger shutdown for all if not already set
if not shutdown_event.is_set():
shutdown_event.set()
# Cancel pending tasks and run the cleanup handler
# ... (cancel logic) ...
await shutdown_handler(shutdown_event) # Saves history etc.
loop.run_until_complete(main_runner())
# ... (exception handling, loop closing) ...
# shutdown_handler also defined to save history, cancel tasks gracefully
async def shutdown_handler(shutdown_event: asyncio.Event):
# ... save history for all sessions in chat_history ...
# ... cancel remaining tasks ...
# ... close resources ...
6. Beyond Interactive: The Power of the TCP Server (ft. ask.sh)
While the interactive terminal chat is great for conversations, the real power of the TermTalk architecture comes from its optional TCP server. This allows other programs and scripts to interact with the same persistent LLM sessions programmatically.
To illustrate this, I wrote a simple Bash client script called ask.sh. Its goal is to perform quick, predefined actions (like summarizing text, translating, or checking grammar) on text sourced either from the clipboard or direct input, all triggered from the command line or, even better, via keyboard shortcuts.
Meet ask.sh – A Bash Client for TermTalk
#!/bin/bash
# ask.sh - Client for TermTalk server
# Usage: ask.sh <pattern> | ask.sh --prompt <pattern>
export LC_ALL=en_US.UTF-8
export LANG=en_US.UTF-8
LOG_FILE="/tmp/ask.log"
log() { echo "$(date): $1" >> "$LOG_FILE"; }
PROMPT_FLAG=false
PATTERN="$1"
if [ "$1" == "--prompt" ]; then
PROMPT_FLAG=true
PATTERN="$2"
log "Prompt mode, pattern: $PATTERN"
else
log "Clipboard mode, pattern: $PATTERN"
fi
# Get source text
if [ "$PROMPT_FLAG" = true ]; then
echo "Enter text (Ctrl+D to finish):"
SOURCE=$(cat)
log "User input: ${SOURCE:0:50}..."
else
sleep 0.2 # Small delay for clipboard
SOURCE=$(pbpaste) # Assumes macOS pbpaste, use xclip/xsel on Linux
log "Clipboard: ${SOURCE:0:50}..."
fi
# Construct the actual prompt based on the pattern
case "$PATTERN" in
summarize) PROMPT="Summarize: $SOURCE" ;;
translate-from-japanese) PROMPT="Translate from Japanese to English, provide furigana for non-basic kanji (keep format): ${SOURCE}" ;;
translate-from-english) PROMPT="Translate from English into Japanese: $SOURCE" ;;
check-japanese) PROMPT="Check Japanese text for errors, explain in English: ${SOURCE}" ;;
check-errors) PROMPT="Check for any errors: ${SOURCE}" ;;
error-cause) PROMPT="Explain the error cause: ${SOURCE}" ;;
*) PROMPT="$SOURCE" ;; # Default: send source as prompt
esac
log "Constructed prompt: ${PROMPT:0:50}..."
# --- TCP Protocol Implementation ---
# 1. Create JSON payload: {"payload": "Your prompt here"}
# Using jq for safe JSON string escaping.
msg=$(printf '{"payload": %s}' "$(jq -n --arg p "$PROMPT" '$p')")
# 2. Calculate payload length in bytes.
len=$(echo -n "$msg" | wc -c)
# 3. Convert length to a 4-byte unsigned integer (Big Endian hex).
# The Python server expects struct.unpack('>I') - 4 bytes, big-endian.
hex_len=$(printf "%08x" "$len")
# 4. Convert the hex length to raw binary bytes using xxd.
# Create a temporary file to hold the binary length + JSON payload.
temp_file=$(mktemp)
printf "%s" "$hex_len" | xxd -r -p > "$temp_file"
# 5. Append the JSON message payload to the binary length.
echo -n "$msg" >> "$temp_file"
log "Sending $len bytes message."
# 6. Send the complete binary message (length + payload) via netcat.
nc localhost 8484 < "$temp_file" # Assumes server on localhost:8484
# 7. Clean up.
rm "$temp_file"
log "Done."
How ask.sh Works:
-
Input: It takes a pattern argument (like summarize) and optionally a –prompt flag. It reads text from pbpaste (macOS clipboard utility; use xclip or xsel on Linux) or waits for user input via cat.
-
Prompt Crafting: A case statement constructs the final prompt sent to the LLM based on the pattern, prepending instructions to the source text.
-
TCP Protocol: This is the crucial part mirroring what the Python server expects:
-
It formats the final prompt into a JSON string: {“payload”: “Your constructed prompt…”} using jq for safety.
-
It calculates the exact byte length of this JSON string using wc -c.
-
It converts this length into a 4-byte, big-endian binary representation. printf “%08x” creates the hex, and xxd -r -p converts hex back to raw bytes.
-
It writes these 4 binary length bytes, followed immediately by the JSON payload bytes, into a temporary file.
-
Finally, it uses nc (netcat) to send the entire content of this temporary file to the TermTalk server listening on localhost:8484.
-
Integrating with Your Workflow (e.g., skhd)
The beauty of ask.sh is its simplicity and command-line nature. This makes it trivial to integrate with tools like skhd (a hotkey daemon for macOS) or similar tools on other platforms. You can map keyboard shortcuts directly to specific LLM actions:
# Example skhd configuration snippet alt + cmd - t : /path/to/ask.sh translate-from-japanese alt + cmd - e : /path/to/ask.sh translate-from-english alt + cmd - a : /path/to/ask.sh check-errors alt + cmd - d : /path/to/ask.sh # Send clipboard content directly
Now, simply selecting text and pressing Alt+Cmd+T instantly sends that text to your running TermTalk server via ask.sh, asking the LLM to translate it from Japanese, with the result appearing back in your terminal where the TermTalk server is running!
This client-server model unlocks powerful workflow automations, turning complex LLM interactions into simple keystrokes.
Takeaways & How to Learn More
Building TermTalk involved combining several powerful Python libraries and concepts:
-
Asyncio: For concurrent handling of user input, network requests (API, TCP server), and timers without blocking. Understanding async/await, asyncio.Event, asyncio.create_task, and asyncio.start_server is key.
-
Prompt Toolkit: For creating sophisticated, interactive terminal user interfaces far beyond basic input(). Explore its documentation for widgets, layouts, key bindings, styles, and more.
-
OpenAI API Client: Using the official openai library (specifically the async client) to interact with the LLM.
-
Networking (TCP): Using asyncio‘s streams (StreamReader/StreamWriter) for the programmatic server, including handling message framing (length prefixing).
-
File I/O & Data Handling: Using pathlib for path manipulation and json for serializing/deserializing chat history. pydantic adds robustness to the TCP server by validating incoming data.
-
Error Handling & Graceful Shutdown: Using try…except blocks, logging, signal handling, and asyncio.Event to make the application robust and ensure data (like history) is saved on exit.
- SKHD: This hotkey daemon for MacOS, makes it easy to configure your hotkeys in a simple text file to invoke any command.
Conclusion
While TermTalk is just one implementation, I hope walking through some of its code gives you some idea of how different pieces can fit together to create useful command-line applications that interact with modern AI services. The combination of Python’s rich ecosystem, particularly libraries like asyncio and prompt-toolkit, makes building such tools surprisingly accessible.
次世代システム研究室では、グループ全体のインテグレーションを支援してくれるアーキテクトを募集しています。インフラ設計、構築経験者の方、次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ募集職種一覧からご応募をお願いします。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD




