2021.10.02
KubernetesベースのSparkクラスターを検証するーアッドホック分析環境構築編
こんにちは。次世代システム研究室のT.D.Qです。
前回のブログよりConoha VPSで構築したSpark on Kubernetesクラスターが既存HDFSクラスターと連携してpySparkバッチ実行環境構築について書きました。今回の記事でこのKubernetesクラスター上にDelta Lakeを対応するPySparkのアッドホック分析環境構築及び検証内容について紹介したいと思います。
アッドホック分析の実行環境構築
アドホック分析とは、データ調査、集計、分析やビックデータ処理の際に用いられる分析手法であり、定期的に行われるデータ分析や、項目も内容も決まっているデータ分析と違って、その都度単発的に行われるというのが特徴です。
今回やりたいこと
今回構築するアッドホック分析環境で実現したいことは以下の4項目です。
- 構築したKubernetesクラスター上にpySparkアッドホック分析環境を構築したい
- NotebookからSpark Sessionを起動時にリソースを調整できるようにしたい
- 構築したHDFSクラスター・Delta Lakeから抽出・永続化できるようにしたい
- ビッグデータを対応するKoalas DataFrameを軽く検証したい
アッドホック分析環境Dockerfileの実装
今回アッドホック分析のpySpark実行環境は必要なライブラリを用意する必要があり、Kubernetesクラスターで稼働するため、専用のDockerfileを実装する必要があります。
HDFSクラスターとの連携、Deltalakeとの連携を対応するため、今回は以下のイメージでDocker Imageを構築していきたいと思います。
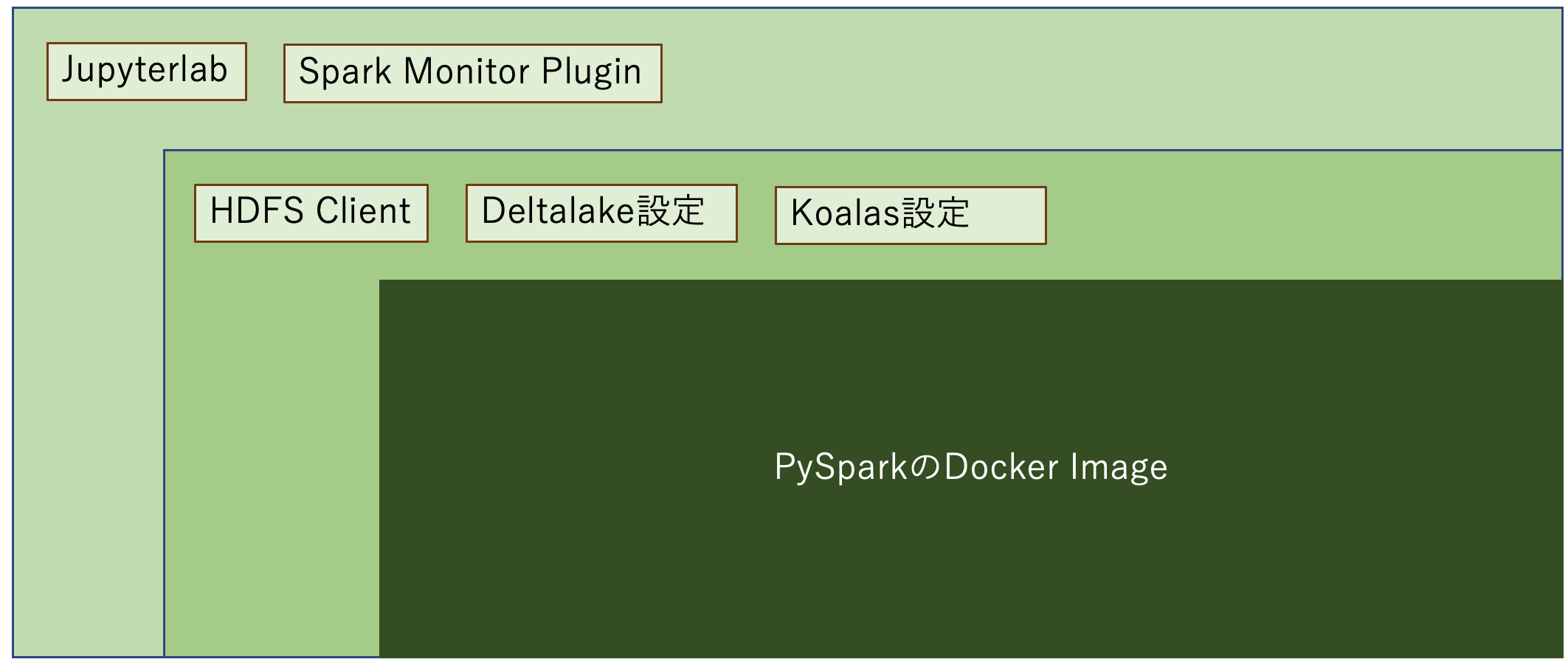
今回実装するDockerfileは基本的に前回のDocker Imageの上にJupyterlab及び関連するプラグインをインストールすることになりますので、これから変更箇所のみ説明します。
Jupyterlabのインストール
今回、Kubernetesクラスター上にアッドホック分析のGUI兼IDEはデータ分析者に愛されているJupyter Labで構築したいと思います。
既存Dockerfileに以下のコマンドを追加することでjupyter Labをインストールすることができます。
# Install jupyterlab & extentions
RUN pip3 install \
notebook==6.2.0 \
ipynb==0.5.1 \
jupyterlab==3.1.12
次にデータ解析時に作ったNotebookの保存場所(今回は/home/spark/notebookにしました)を設定します。また、Docker Containerを起動時にJupyterlabも起動するためDockerfileの後尾に以下のコマンドを追加しましょう。
USER ${spark_uid}
VOLUME /home/spark/notebook
CMD jupyter lab --port=8888 --ip=0.0.0.0 --no-browser --allow-root --NotebookApp.token='' --notebook-dir=/home/spark/notebook
WORKDIR /opt/spark/work-dir
ここでJupyer Labのインストールは基本的に完了しました。
Spark Monitorプラグインの導入
Sparkジョブを実行時に実行状況を確認するため、Spark UIがよく使われていますが、Kubernetes上にSpark History UIでジョブの実行状況の確認に少し複雑です。
自分がSpark Historyを確認方法について調査した時にJupyterlabならSpark Monitorという無料プラグインを見つけました。このプラグインを使うことで以下のイメージのようにJupyter lab上に直接Spark UI画面を見ることができるし、コマンド実行するときに実行状況がわかりやすく可視化してくれるのでとても便利です。 Spark monitor plugin Spark MonitorをインストールするためDockerfileに以下のコマンドを追加しました。
RUN pip3 install jupyterlab-sparkmonitor
JupyterlabのExtensionを使うため、Nodejsをインストールする必要があるので、以下のコマンドをDockerfileに追加しました。
# Install Node.js RUN curl -sL https://deb.nodesource.com/setup_14.x | bash RUN apt-get install --yes nodejs RUN node -v RUN npm -v RUN npm i -g nodemon RUN nodemon -v
次に、Spark monitorプラグインの手順書の通りにipythonの設定を行います。
# run with root permission
USER 0
RUN ln -s /usr/local/lib/python3.8/site-packages/sparkmonitor/listener_2.12.jar /opt/spark/jars/listener_2.12.jar \
&& chown -R spark:hadoop /opt/spark/jars \
&& mkdir /home/spark/notebook && chown -R spark:hadoop /home/spark/notebook
# Switch to spark user
USER ${spark_uid}
ENV PATH=/home/spark/.local/bin:$PATH
RUN ipython profile create && \
echo "c.InteractiveShellApp.extensions.append('sparkmonitor.kernelextension')" >> /home/spark/.ipython/profile_default/ipython_config.py
ここまで一旦Spark monitorプラグインの設定が完了しました。
Delta lakeと連携するための設定
今回のDeltalakeはHive Metastoreを使うので、連携するためのhive-site.xmlファイルをSPARK_HOME直下のconfディレクトリに配置する必要があります。
また、Hive Metastoreに接続するためJDBCを事前準備しました。
pip3 install delta-spark COPY kubernetes/dockerfiles/spark8s/hadoop-3.2.2/etc/hadoop/hive-site.xml /opt/spark/conf/hive-site.xml # Install Postgresql JDBC for Hive metastore WORKDIR /opt/spark/jars RUN curl https://jdbc.postgresql.org/download/postgresql-42.2.23.jar -o postgresql-42.2.23.jar RUN chmod +x /opt/spark/jars/postgresql-42.2.23.jar
その他:Koalasのインストール
KoalasがPySparkのDataFrame APIを拡張してpandasと互換性を持たせる新しいオープンソースプロジェクトです。PandasはPython データサイエンスの標準表現ですが、単一のマシンで扱えるスモールデータ用に設計されています。なので、膨大なデータセットを扱うためにSparkを活用するには、PySparkに移行するか、pandasで扱えるようにデータをダウンサンプリングしなければなりません。Koalasを使用することで、データサイエンティストは新しいフレームワークを覚えなくとも、単一のマシンから分散環境へ移行することが可能です。Spark Dataset/DataFrameと呼ばれるPandasのDataFrameに近い概念が存在しますが各種APIが異なるためpandasとSpark Dataset/DataFrame間でオブジェクト変換した際に混乱します。それを解決するアプローチがKoalasになります。
Koalasはpipから直接インストールできますのでDockerfileに以下のコマンドを追加しました。
RUN pip3 install koalas plotly ENV PYARROW_IGNORE_TIMEZONE 1
Koalasデータフレームのデータ可視化にデフォルトはplotlyを使うのでplotlyをインストールしておきました。
また、Koalasはpyarrowを使っていて、PYARROW_IGNORE_TIMEZONE環境変数を1にしないと怒られるので設定しておきました。
Docker ImageをビルドしてDockerHubにPush
ここまで必要なライブラリのインストールや設定をDockerfileに実装しましたのでKubernetesクラスターに展開するためDocker ImageをビルドしてDocker RepositoryにPushしておきたいと思います。
k8sadmin@quytd-spark-tool:~$ cd /usr/local/spark k8sadmin@quytd-spark-tool:~$ sudo ./bin/docker-image-tool.sh -n -r quytd -t pyspark-3.1.1-hadoop-3.2.0-jupyterhub -p /usr/local/spark/kubernetes/dockerfiles/jupyterhub/Dockerfile build k8sadmin@quytd-spark-tool:~$ sudo bin/docker-image-tool.sh -r quytd -t pyspark-3.1.1-hadoop-3.2.0-jupyterhub push
アッドホック分析環境のConfigファイル実装
アッドホック分析環境のDocker Imageを準備できましたので、以下の内容で「jupyterlab-config.yaml」ファイルを作成します。
内容がやや長いですが主にjupyterというサービスアカウントを生成して、sparkの命名空間に管理権限を設定します。次にクラスターの外からアクセスするためjupyterというServiceを定義します。このサービスはJupyter Labの標準ポート番号が「8888」を定義します。また、headless(固定IPが不要)のServiceがSpark driverとして使うのでSpark executorからアクセスするためポート番号を「2222」、Sparkのblock managerのポート番号を「7777」として明確に定義しました。最後に、データ分析時に作ったNotebookがクラスターが壊れてもちゃんと残るためにStatefulSetとして定義しました。
apiVersion: v1
kind: ServiceAccount
metadata:
name: jupyter
labels:
release: jupyter
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: jupyter
labels:
release: jupyter
namespace: spark
rules:
- apiGroups:
- ""
resources:
- pods
verbs:
- create
- get
- delete
- list
- watch
- apiGroups:
- ""
resources:
- services
verbs:
- get
- create
- apiGroups:
- ""
resources:
- pods/log
verbs:
- get
- list
- apiGroups:
- ""
resources:
- pods/exec
verbs:
- create
- get
- apiGroups:
- ""
resources:
- configmaps
verbs:
- get
- create
- list
- watch
- delete
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: jupyter
labels:
release: jupyter
namespace: spark
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: jupyter
subjects:
- kind: ServiceAccount
name: jupyter
namespace: spark
---
apiVersion: v1
kind: Service
metadata:
name: jupyter
labels:
release: jupyter
spec:
type: ClusterIP
selector:
release: jupyter
ports:
- name: http
port: 8888
protocol: TCP
- name: blockmanager
port: 7777
protocol: TCP
- name: driver
port: 2222
protocol: TCP
---
apiVersion: v1
kind: Service
metadata:
name: jupyter-headless
labels:
release: jupyter
spec:
type: ClusterIP
clusterIP: None
publishNotReadyAddresses: false
selector:
release: jupyter
ports:
- name: http
port: 8888
protocol: TCP
- name: blockmanager
port: 7777
protocol: TCP
- name: driver
port: 2222
protocol: TCP
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: jupyter
labels:
release: jupyter
spec:
replicas:
updateStrategy:
type: RollingUpdate
serviceName: jupyter-headless
podManagementPolicy: Parallel
volumeClaimTemplates:
- metadata:
name: notebook-data
labels:
release: jupyter
spec:
accessModes:
- ReadWriteOnce
# volumeMode: Filesystem
resources:
requests:
storage: 1Gi
storageClassName: local-storage
selector:
matchLabels:
release: jupyter
template:
metadata:
labels:
release: jupyter
annotations:
spec:
restartPolicy: Always
terminationGracePeriodSeconds: 30
serviceAccountName: jupyter
dnsConfig:
options:
- name: ndots
value: "1"
containers:
- name: jupyter
image: "quytd/spark-py:pyspark-3.1.1-hadoop-3.2.0-deltalake-jupyterhub"
imagePullPolicy: IfNotPresent
ports:
- name: http
containerPort: 8888
protocol: TCP
- name: blockmanager
containerPort: 7777
protocol: TCP
- name: driver
containerPort: 2222
protocol: TCP
volumeMounts:
- name: notebook-data
mountPath: /home/spark/notebook
resources:
limits:
cpu: 8000m
memory: 16Gi
requests:
cpu: 1000m
memory: 1Gi
Notebookファイルを保持するため永続ボリュームを作成しておく
Kubernetesに永続ボリュームを作成するためPersistentVolume (PV)とPersistentVolumeClaim (PVC)を定義する必要があります。
まずは以下の定義でクラスターのストレージの一部を使ってNotebook専用のPVを定義しました。特定ノードのLocal Storageを使いたいのでストレージクラスはlocal-storageにしました。
ファイル名が「local_persistent_volume_jupyterhub_pyspark_slave2.yaml」にしました。
apiVersion: v1
kind: PersistentVolume
metadata:
name: notebook-data-jupyter-0
spec:
capacity:
storage: 1Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
storageClassName: local-storage
local:
path: /mnt/data/jupyterhub_pyspark
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- quytd-spark-s2
次にPersistentVolumeClaim (PVC)を以下のように定義しました。
ファイル名が「local_persistent_volume_claim_jupyterhub_pyspark_s2.yaml」にしました。少し長いですが。
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: notebook-data-jupyter-0
spec:
accessModes:
- ReadWriteOnce
storageClassName: local-storage
resources:
requests:
storage: 512Mi
LensのConsoleを使って上記のファイルの内容を適用しましょう。
jupyterhub-pyspark % kubectl apply -f volume-mount/local_persistent_volume_jupyterhub_pyspark_slave2.yaml persistentvolume/notebook-data-jupyter-0 created upyterhub-pyspark % kubectl apply -f volume-mount/local_persistent_volume_claim_jupyterhub_pyspark_s2.yaml persistentvolumeclaim/notebook-data-jupyter-0 created
PySparkのアッドホック分析環境を立ち上がる
jupyterhub-pyspark % kubectl create ns spark namespace/spark created jupyterhub-pyspark % kubectl apply -n spark -f jupyterhub-config.yaml serviceaccount/jupyter created role.rbac.authorization.k8s.io/jupyter created rolebinding.rbac.authorization.k8s.io/jupyter created service/jupyter created service/jupyter-headless created statefulset.apps/jupyter created
Lensで起動したServiceが問題なく稼働していること確認しました。
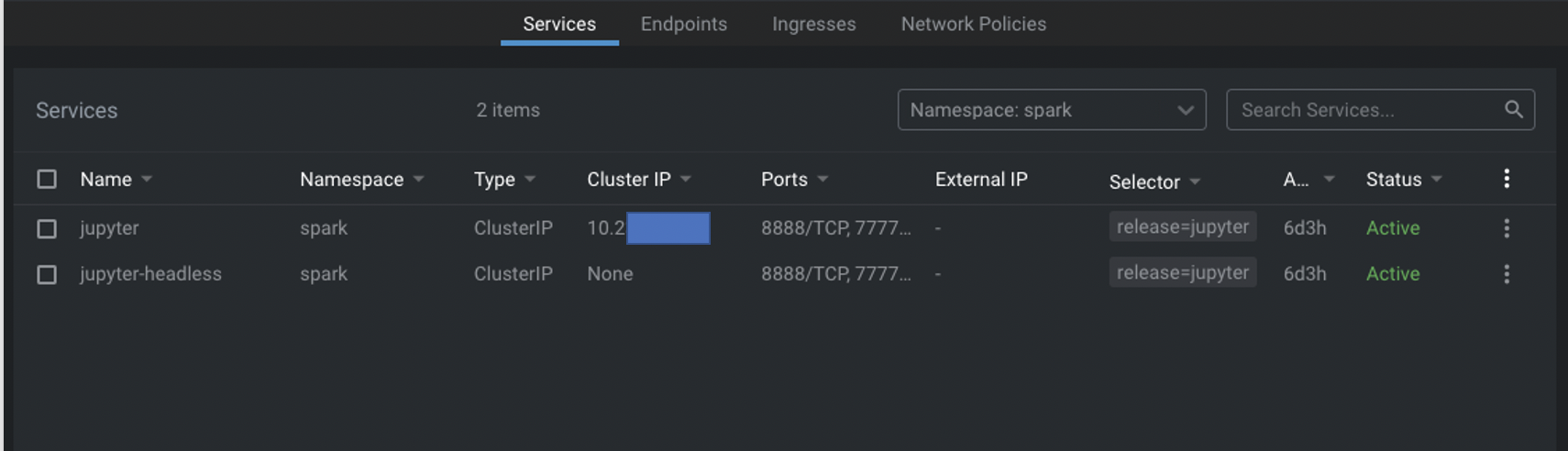
クラスターの外から起動したJupyterlabにアクセスするため、まずport-forwardをしましょう。
jupyterhub-pyspark % kubectl port-forward -n spark service/jupyter 8888:8888 Forwarding from 127.0.0.1:8888 -> 8888 Forwarding from [::1]:8888 -> 8888
jupyterのServiceIPを確認できましたが、今回はインターネットから直接アクセスできないように設定しましたので、Local PCからそのIPに接続するためPort-forwardを設定することでアクセスできまるようになりました。

HDFS及びDelta Lakeと連携の検証
起動したJupyterlabにアクセスできましたので早速pySparkでHDFSやDeltalakeに連携できるか検証を行いましょう。
SparkConfigでアッドホック分析Notebookのリソースを設定する
NotebookからSparkのリソースを定義することでSpark Sessionを起動する時にKubernetesクラスターにリソースを要求できます。
今回の検証はデータ量がやや多いので以下の内容でSparkConfigを定義しました。
・ pySpark及び既存HDFSクラスター、Deltalakeと連携するので、構築したDocker Imageを使う
・ Spark executorのインスタンス数が8個で、1個にメモリ2GB、CPU 1 coreを設定
・ Sparkの実行状況に応じてリソースが動的に調整することを可能にする
・ Deltalakeを対応する
・ Spark monitorを有効にする
・ Koalasを使うので必要な設定を行う
Spark Driverの設定
まず構築したDocker Imageを使うため、configに以下の内容で指定しました。
config = {
"spark.kubernetes.namespace": "spark",
"spark.kubernetes.container.image": "quytd/spark-py:pyspark-3.1.1-hadoop-3.2.0-jupyterhub"
}
Spark Driverの設定になりますが、Spark executorのPodからアクセスするため、IPとポートを明確に指定する必要があります。
driver.hostがjupyterのServiceを起動したときのIPアドレスまたはホスト名を指定します。上記のconfigに以下の内容を追加しましょう。
"spark.driver.blockManager.port": "7777",
"spark.driver.port": "2222",
"spark.driver.host": "10.233.xx.xx",
"spark.driver.bindAddress": "0.0.0.0",
"spark.ui.port": "4040",
"spark.network.timeout": "240"
Spark Executorのインスタンス数とリソース設定
今回のデータ処理のニーズでSpark executorのインスタンス数が6個で、1個にメモリ2GB、CPU 1 coreを調整したいので、configに以下の内容を追加しました。
"spark.executor.instances": "6",
"spark.executor.memory": "2g",
"spark.executor.cores": "1",
Dynamic Resource Allocation設定
Sparkの実行状況に応じてリソースが6個以上に動的に増加することを可能にするため、SparkのDynamic Allocation機能を利用します。
今回はexecutorの最大数が12個まで制限したいので以下の設定を追加しました。
"spark.dynamicAllocation.executorIdleTimeout":"60s", "spark.dynamicAllocation.executorAllocationRatio": "0.2", "spark.dynamicAllocation.schedulerBacklogTimeout":"1s", "spark.dynamicAllocation.shuffleTracking.timeout": "10s" , "spark.dynamicAllocation.shuffleTracking.enabled": "true", "spark.dynamicAllocation.minExecutors": "6", "spark.dynamicAllocation.maxExecutors": "12",
Delta Lakeと連携するための設定
Hive Catalogを対応するDeltalakeを使うため、以下の設定内容をconfigに追加しました。
"spark.sql.extensions":"io.delta.sql.DeltaSparkSessionExtension", "spark.sql.catalog.spark_catalog": "org.apache.spark.sql.delta.catalog.DeltaCatalog", "spark.delta.logStore.class":"org.apache.spark.sql.delta.storage.HDFSLogStore", "spark.sql.catalogImplementation": "hive"
その他の設定
次の1行〜2行目はSpark Monitorプラグインの設定になります。最後の3行目はKoalasがArrowを使えるようになるための設定です。
"spark.driver.extraClassPath":"/usr/local/lib/python3.9/dist-packages/sparkmonitor/listener.jar", "spark.extraListeners": "sparkmonitor.listener.JupyterSparkMonitorListener", "spark.sql.execution.arrow.pyspark.enabled": True
SparkSessionを起動
最終的にSparkConfigの内容は以下のようになります。このConfig内容でSparkSessionを生成しましょう。
config = {
"spark.kubernetes.namespace": "spark",
"spark.kubernetes.container.image": "quytd/spark-py:pyspark-3.1.1-hadoop-3.2.0-jupyterhub",
"spark.executor.instances": "6",
"spark.executor.memory": "2g",
"spark.executor.cores": "1",
"spark.driver.blockManager.port": "7777",
"spark.driver.port": "2222",
"spark.driver.host": "10.233.xx.xx",
"spark.driver.bindAddress": "0.0.0.0",
"spark.ui.port": "4040",
"spark.network.timeout": "240",
"spark.dynamicAllocation.executorIdleTimeout":"60s",
"spark.dynamicAllocation.executorAllocationRatio": "0.2",
"spark.dynamicAllocation.schedulerBacklogTimeout":"1s",
"spark.dynamicAllocation.shuffleTracking.timeout": "10s" ,
"spark.dynamicAllocation.shuffleTracking.enabled": "true",
"spark.dynamicAllocation.minExecutors": "6",
"spark.dynamicAllocation.maxExecutors": "12",
"spark.sql.extensions":"io.delta.sql.DeltaSparkSessionExtension",
"spark.sql.catalog.spark_catalog": "org.apache.spark.sql.delta.catalog.DeltaCatalog",
"spark.delta.logStore.class":"org.apache.spark.sql.delta.storage.HDFSLogStore",
"spark.sql.catalogImplementation": "hive",
"spark.driver.extraClassPath":"/usr/local/lib/python3.9/dist-packages/sparkmonitor/listener.jar",
"spark.extraListeners": "sparkmonitor.listener.JupyterSparkMonitorListener",
"spark.sql.execution.arrow.pyspark.enabled": True
}
上記のConfigをSparkConfigに適用しましょう。SparkConfにKubernetesクラスターのIP:portを指定する必要があります。
def get_spark_session(app_name: str, conf: SparkConf):
conf.setMaster("k8s://https://192.168.1.14:6443")
for key, value in config.items():
conf.set(key, value)
builder = SparkSession.builder.appName(app_name).config(conf=conf)
return configure_spark_with_delta_pip(builder).getOrCreate()
spark_config = SparkConf()
spark = get_spark_session("my_deltalake_pyspark_app", spark_config)
上記のコマンドを実行するとSparkSessionのインスタンスが生成されます。
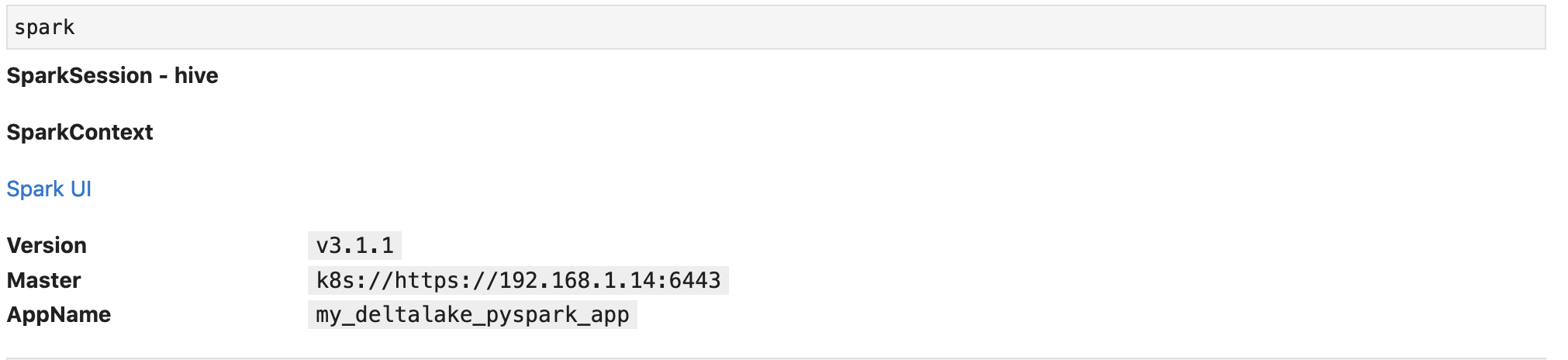
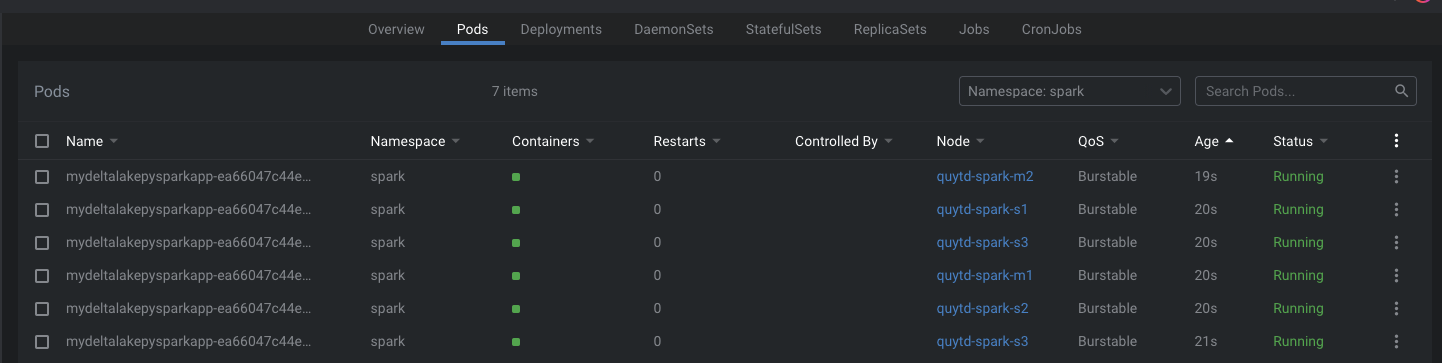
HDFSに準備したForexデータの確認
今回の検証データはHistData.comから各クロス円通貨ペアの直近3年間のCSVデータをダウンロードしてHDFSに事前に格納しました。Jupyterlabからこのデータを閲覧できるか確認したいと思います。
!hdfs dfs -ls /tmp/spark8s/HISTDATA/
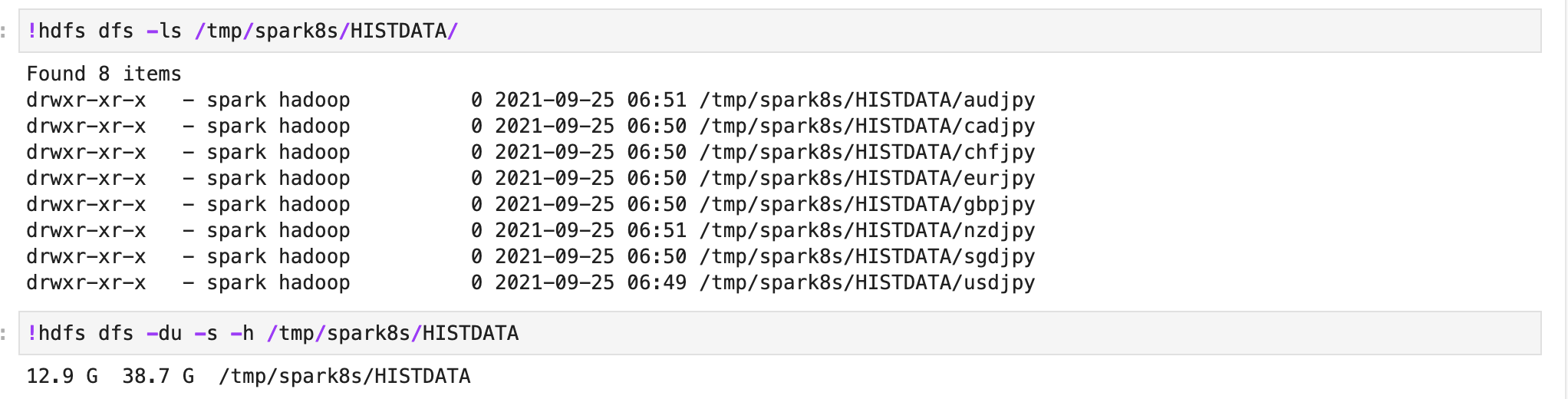
ご覧の通り、HDFS上にフォルダー一覧を見ることができました。データサイズは38.7GB前後です。無事にHDFSクラスターと連携できることを確認できました。
Delta lakeに新しいスキーマを作成
次にDelta lakeとの連携について検証したいと思います。Delta lakeに既にあるスキーマ一覧をリストするコマンドを実施します。
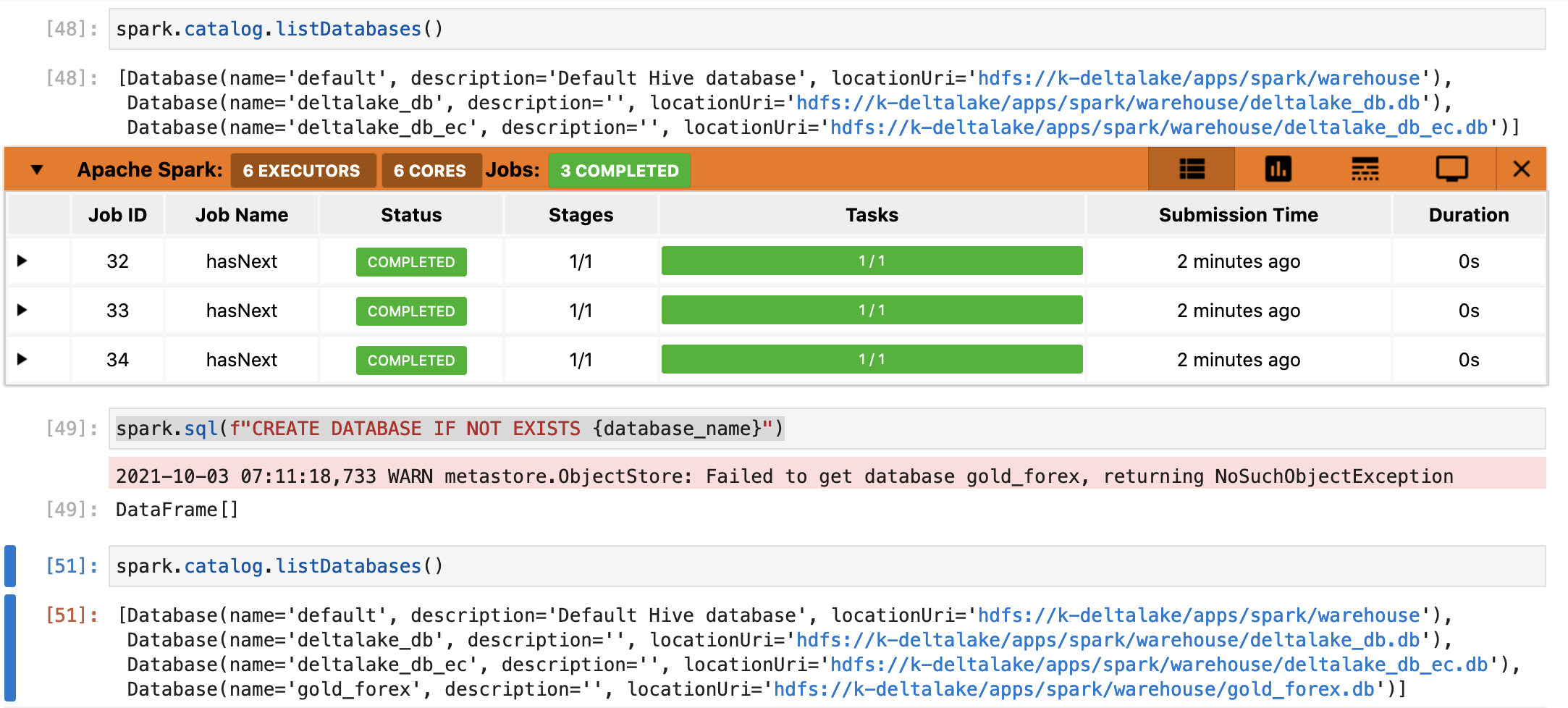
スキーマ一覧を見ることができましたので、Delta lakeとの連携ができるようになっていますね。
次に、以下の関数で検証用のスキーマを作成してデータの永続化を検証したいと思います。
database_name = "gold_forex"
spark.sql(f"DROP DATABASE IF EXISTS {database_name}")
spark.catalog.listDatabases()
spark.sql(f"CREATE DATABASE IF NOT EXISTS {database_name}")
spark.catalog.listDatabases()
spark.sql(f"USE {database_name}")
ForexデータをDelta Lakeに取り込む
まず、以下の関数でSpark Dataframeに用意した銘柄別のCSVファイルを一括ロードして、その後に適切なクラム名変更やデータ型変更などを実施しました。
from pyspark.sql.functions import col, lit
from pyspark.sql.types import StructType,StructField, StringType, FloatType, IntegerType
def get_df_from_csv_paths(commodity):
file_path="/tmp/spark8s/HISTDATA/{0}/*.csv".format(commodity)
read_schema = StructType([ \
StructField("tick_timestamp",StringType(),True), \
StructField("bid",FloatType(),True), \
StructField("ask",FloatType(),True), \
StructField("volume", StringType(), True)
])
df = spark.read.format("csv"). \
option("header", "false"). \
option('delimiter', ','). \
option('mode', 'DROPMALFORMED'). \
schema(read_schema). \
load(file_path)
# volumeカラムは使わないのでforex_pairに変更。
new_df = df.withColumn("volume", lit(commodity)).withColumnRenamed("volume", "forex_pair")
# 検索時間を短縮する目的でレート日付でテーブルのPartitionを作るため、quote_dateカラムを作成する。
new_df = new_df.withColumn("business_date", new_df.tick_timestamp[0:7])
new_df = new_df.withColumn("business_date", new_df.business_date.cast(IntegerType()))
# Midプライスを計算する
new_df = new_df.withColumn("mid", (new_df.bid + new_df.ask)/2)
new_df = new_df.withColumn("mid", new_df.mid.cast(FloatType()))
return new_df
次は、今回構築したアッドホック環境はデータサイズの大きいDataFrameを対応できるか確認するため、以下の関数で今回用意した通貨ペア全部のデータをSpark Dataframeのunionメソッドで巨大なデータフレームにしておきます。
def load_all_rates_data():
forex_pairs=["audjpy","cadjpy","chfjpy","eurjpy","gbpjpy","nzdjpy","sgdjpy","usdjpy"]
all_quote_df = None
for forex_pair in forex_pairs:
quote_df=get_df_from_csv_paths(forex_pair)
if all_quote_df is None:
all_quote_df = quote_df
else:
all_quote_df = all_quote_df.union(quote_df)
return all_quote_df
以下は連携したDelta lakeにデータを永続化できるか確認するための関数です。
def save_rates_data(df, table_name, table_location, partitions, checkpoint_location):
df.write \
.format("delta") \
.partitionBy(partitions) \
.option("mergeSchema", "true") \
.option("overwriteSchema", "true") \
.option("checkpointLocation", checkpoint_location) \
.mode('overwrite') \
.saveAsTable(table_name)
上記でデータ操作関数を用意で来ましたので、早速HDFSとDelta lakeと連携できるか検証を行いましょう!
table_name = "commodity_rates"
table_location = f"/apps/spark/warehouse/{database_name}.db/{table_name}"
partitions = ["business_date", "forex_pair"]
checkpoint_location = table_location + "/_checkpoints/streaming_ckp"
table_schema = StructType([
StructField("business_date", IntegerType(), False),
StructField("forex_pair", StringType(), False),
StructField("tick_timestamp", StringType(), False),
StructField("bid", FloatType(), False),
StructField("ask", FloatType(), False),
StructField("mid", FloatType(), False)
])
forex_data_df = load_all_rates_data()
save_rates_data(df=forex_data_df, table_name=table_name, table_location=table_location, partitions=partitions, checkpoint_location=checkpoint_location)
用意したCSVデータをSpark Dataframeにロードできました!
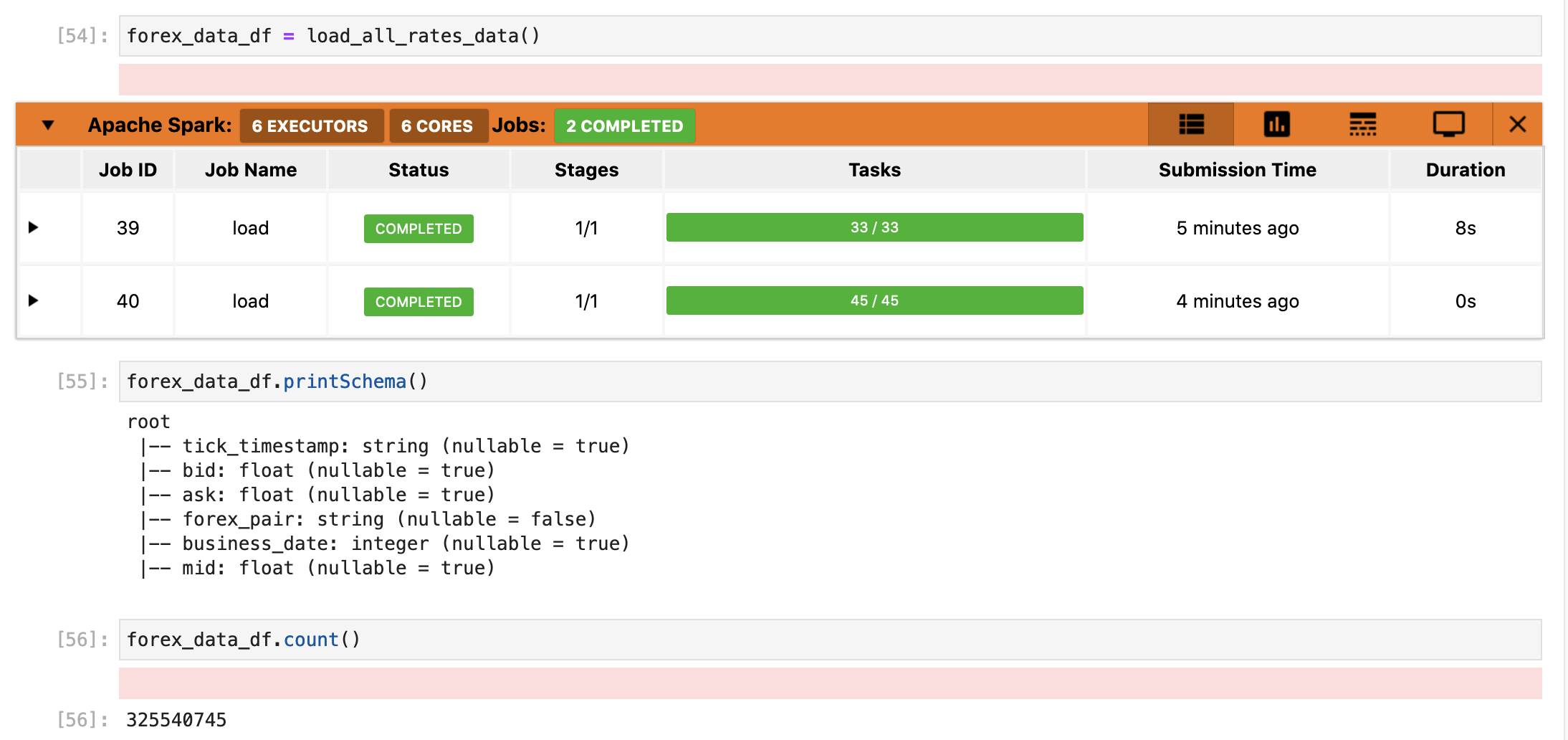
約8秒でFXのCSVデータが325,540,745件をロードできました。まあ、SparkはLazy load仕組みを使っているので実際のデータを操作しないと時間がかからないはずですね。
無事にサイズの大きなDataframeを準備できたのでこのDataframeを使ってDelta Lakeに永続化しましょう!ちなみに、テーブル名が「commodity_rates」にしました。

やや件数が多かったのでデータ永続化の実行時間が4分47秒かかりました。チューニングすると実行時間を短縮できると思いますが別の機会で。
KoalasでDelta Lakeからデータを抽出して確認する
最後に、インストールしたKoalas Dataframeを軽く確認しましょう。Notebookに以下のようにkoalasをimportして使います。関連するArrowも設定しておきました。
import databricks.koalas as ks
ks.set_option("compute.default_index_type", "distributed") # Use default index prevent overhead.
import warnings
warnings.filterwarnings("ignore") # Ignore warnings coming from Arrow optimization
直接DeltalakeからKoalas Dataframeにデータをロードできないので、以下のようにSpark Dataframeを経由してデータをロードしました。
kdf_usdjpy_rates = spark.sql(f"SELECT * FROM {table_name} WHERE forex_pair='usdjpy'").to_koalas()
Koalas Dataframe内にtick_timestampカラムをindexカラムとして設定しましょう。
kdf_usdjpy_rates.set_index('tick_timestamp', inplace=True, drop=True)
Dataframeの最初の5件を確認しましょう。Spark Dataframeより綺麗に表示されています。

次に、Pandasと同じ感じでKoalas DataframeからUSDJPYのレートデータを可視化してましょう。
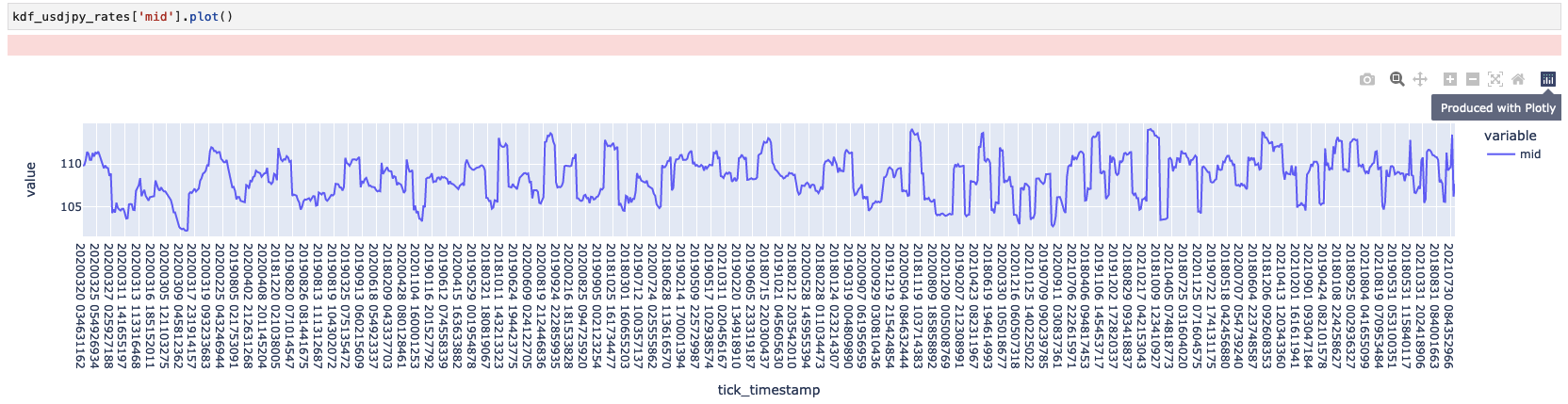
綺麗にPlotlyのグラフが出力してくれました。良さそうですね。記事が長くなりましたのでKoalasの検証はここで以上です。
まとめ
前回HDFS・Delta lakeクラスターと連携してpySparkバッチ実行環境構築を続いて、今回はKubernetesクラスター上にDelta Lakeを対応するPySparkのアッドホック分析環境構築及び検証内容について紹介しました。このアッドホック分析環境でPySparkを用いるデータ解析ライブラリを揃っているのでJupyter Labでデータ収集・データ分析・可視化及び分析結果の永続化も可能になりましたので便利ですね。また、分析データのサイズによってクラスターのリソースを理由に調整できるのと、分析終わったらリソースを解放することで無駄なくクラスターのリソースを効率的に利用することができると思います。最後にビッグデータを対応するKoalas Dataframeを使うことでPandasに慣れたデータサイエンスティストも早くpySparkでデータ分析に集中できると思います。
最後に
次世代システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。
皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD



