2021.10.08
BigQuery解説 ~テーブル定義からデータ登録まで~
次世代システム研究室の Y.I です。 Google Cloud Platform (GCP) の BigQueryについてまとめます。今回は主にテーブル定義やデータ登録クエリを中心としてご紹介します。改めて調べてみると以前は使えなかったクエリーが使えるようになっていたり日々機能が拡充されていてますます使いやすいマネージドデーウエアハウスに進化しています。2021年に多数のDDLに対応してくれているため、他RDBMSで使うDMLがほぼそのまま動作するような印象を受けました。
BigQueryについて
データ構造
BigQueryは [プロジェクト] -> [データセット(スキーマ)] -> [テーブル] -> [カラム] 階層で構成されています。 プロジェクトはGCP契約単位で決めるIDで固定となります。データセット以下はBigQuery内で都度定義出来ます。 データセットはRDBMSのスキーマやデータベースが該当します。 その下にテーブルがあり、テーブル内にカラムが定義されます。
データ構造
- プロジェクト
- データセット
- テーブル
- カラム
データセット
データセットや配下のテーブルに関する各種オプションを設定できます。
- どこのRegionに作成するか (location)
- 配下のテーブルの有効期限 (default_table_expiration_days)
- 配下のテーブルパーティションの有効期限 (default_partition_expiration_days)
- 説明 (description)
配下のテーブルに関する設定は初期値として利用されます。テーブル毎に作成時に値を指定すれば変更することが可能です。
テーブル
テーブルは主に通常のテーブル、一次テーブル、保存領域が分かれるパーティションテーブル、クラスタリングテーブル、テーブル名によるシャーディングテーブルなどがあります。またテーブルに近いものでVIEWやマテリアライズドVIEWもあります。
- 通常テーブル
- パーティションテーブル (内部的にレコードを分けて持つテーブル/パフォーマンスが向上/クエリ費用を抑えられる)
- クラスタリングテーブル (指定カラム編成して持つテーブル/パフォーマンスが向上/クエリ費用を抑えられる)
- 一次テーブル (同一セッション内だけで有効なテンポラリーテーブル)
カラム
主なカラムタイプについてまとめます。
- STRING (可変長文字列/Unicode)
- INT64 (整数型/エイリアスとしてINT, SMALLINT, INTEGERなどがある)
- NUMERIC (小数型/固定の小数点以下の精度とスケールを持つ数値/財務処理に向いている)
- BIGNUMERIC (小数型/固定の小数点以下の精度とスケールを持つ数値/財務処理に向いている)
- FLOAT64 (浮動小数点型/必要とするデータ量が少ない)
- DATETIME (日時型/タイムゾーンを持たない日時)
- TIMESTAMP (タイムスタンプ型/タイムゾーンを持った日時)
- BYTES (可変長文字バイナリデータ)
- ARRAY (配列型/INT64やSTRINGやBYTESなどの配列)
- STRUCT (構造体型/ネスト構造のデータ)
- GEOGRAPHY (地理型/座標データ)
クエリの実行方法
手動でのクエリの実行は主にGCP WebConsoleとbqコマンドで実行できます。オススメはWebConsoleです。クエリを記述すると自動でdry_runされてシンタックスチェックが行われ、実行時に読み込むデータ量が表示されます。
WebConsoleでのクエリー実行
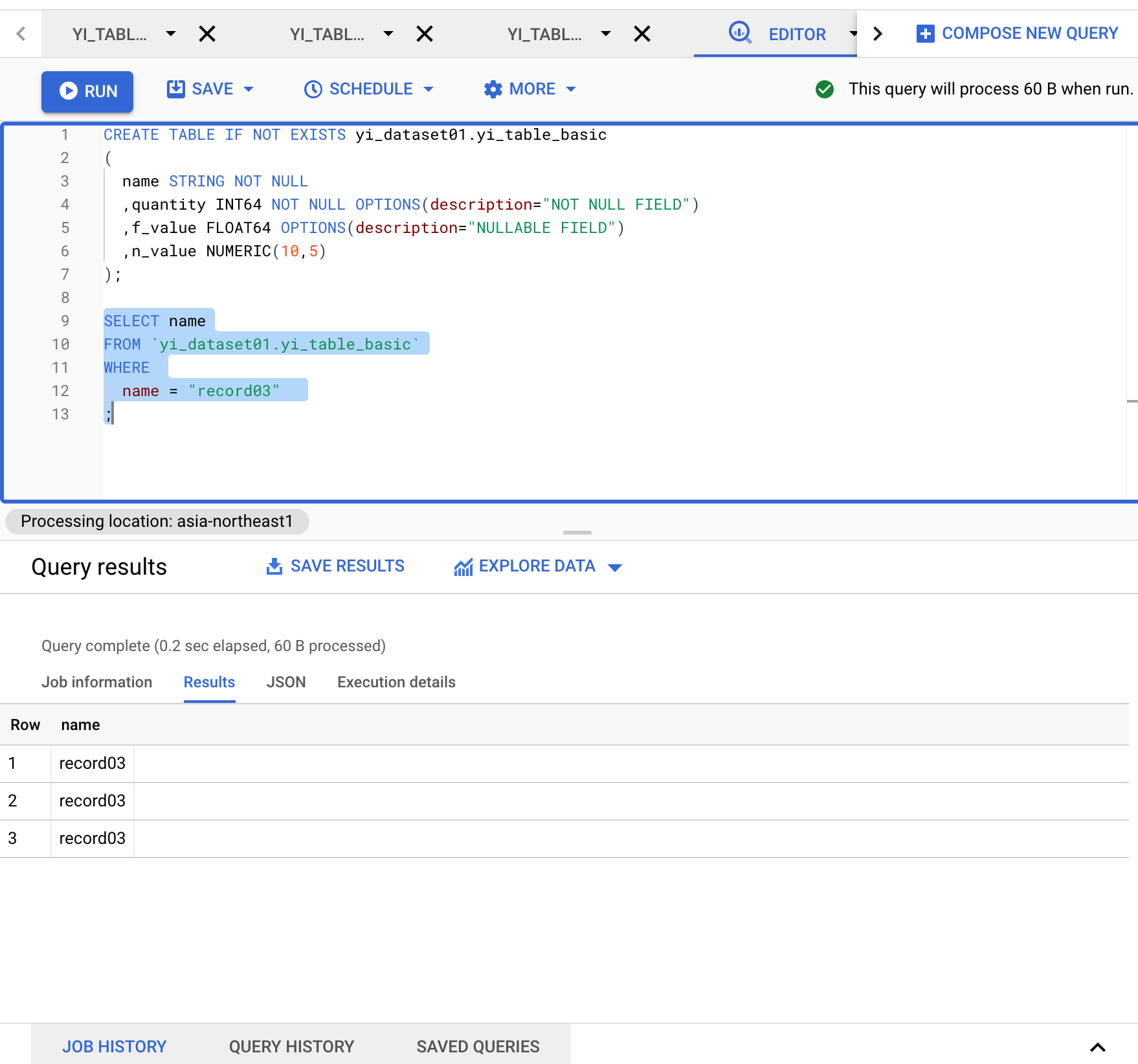
BigQuery WebConsole
クエリdry_run結果が画面の右上に表示されます。今回は実行すると約60byteのデータを読み込むと表示されています。複数のクエリを記述でき、選択したクエリーがdry_runおよび実行されます。
bqコマンドでのクエリー実行
ターミナル上でbqコマンドで各種クエリーが実行できます。実行するクエリーはシングルコーテーションで囲みます。クエリーはWebConsoleで実行する同じクエリーを実行できます。 –dry_runオプションを指定することでシンタックスチェックと読み込みバイト予測が可能です。
$ bq query --use_legacy_sql=false --dry_run \ > 'SELECT name > FROM `yi_dataset01.yi_table_basic` > WHERE > name = "reocrd01" > ' Query successfully validated. Assuming the tables are not modified, running this query will process 60 bytes of data.
Dataset (Schema)
データセットとは、RDBMSでのSchemaやDatabaseに該当します。
データセット作成クエリ/Create Schema
Schema名とオプションを設定できます
CREATE SCHEMA yi_dataset01
OPTIONS(
location="asia-northeast1", /* region */
default_table_expiration_days=3650, /* テーブル有効期限日数 */
default_partition_expiration_days=365, /* パーティション有効期限日数 */
labels=[("label1","value1");
INSERT INTO `wp_posts` VALUES ("label2","value2")] /* ラベル */
)
テーブル
通常テーブル
通常テーブルの作成クエリー/CREATE TABLE
カラム毎に説明(RDBMSでのコメント)を設定可能です。
CREATE TABLE IF NOT EXISTS yi_dataset01.yi_table_basic ( name STRING NOT NULL ,quantity INT64 NOT NULL OPTIONS(description="NOT NULL FIELD") ,f_value FLOAT64 OPTIONS(description="NULLABLE FIELD") ,n_value NUMERIC(10,5) )
INSERT
上記テーブルへの登録サンプルです。文字列型はダブルコーテーションやシングルコーテーションで囲みます。BULK INSERTも可能でVALUESのレコードをカンマ区切りで指定可能です。
INSERT INTO `yi_dataset01.yi_table_basic` (name, quantity, f_value, n_value)
VALUES
("record01", 1, 0.1, 99999.99999)
,("record02", 2, 0.1, 99999.99999)
,("record03", 3, 0.1, 99999.99999)
ARRAY型カラムがある通常テーブル作成クエリー/CREATE TABLE
ARRAY型は
CREATE TABLE IF NOT EXISTS yi_dataset01.yi_table_array ( name STRING NOT NULL ,a_value ARRAY<STRING> /* STRING型の配列型 */ )
INSERT
上記テーブルへの登録サンプルです。ARRAY型の登録は、 [{value}, {value}] と指定します。
INSERT INTO `yi_dataset01.yi_table_array` (name, a_value)
VALUES
("record01", ["array01", "array02", "array03"])
,("record02", ["array01", "array02", "array03"])
,("record03", ["array01", "array02", "array03"])
STRUCT型カラムがある通常テーブル作成クエリー
STRUCT型は <> で指定します。
CREATE TABLE IF NOT EXISTS yi_dataset01.yi_table_struct
(
name STRING NOT NULL
,st_value STRUCT<
st01 STRING
,st02 INT64
,st03 NUMERIC(10,5)
>
)
INSERT
上記テーブルへの登録サンプルです。STRUCT型の登録は、 ({value}, {value}) と指定します。 JSONのNEST構造を登録するのに適しています。
INSERT INTO `yi_dataset01.yi_table_struct` (name, st_value)
VALUES
("record01", ("struct01", 1, 99999.99999))
,("record02", ("struct02", 2, 99999.99999))
,("record03", ("struct03", 3, 99999.99999))
パーティションテーブル
パーティションテーブルの作成クエリー/CREATE TABLE
指定した分割ルールでデータを分けて保存することで、参照範囲が狭まりパフォーマンスの向上や料金コストの削減を期待できます。PARTITION BY で分割ルールを指定できます。 _PARTITIONDATE を指定するとBigQueryへの登録時点の日付で分割します。
CREATE TABLE IF NOT EXISTS yi_dataset01.yi_table_partition
(
name STRING NOT NULL
,quantity INT64 NOT NULL OPTIONS(description="NOT NULL FIELD")
)
PARTITION BY _PARTITIONDATE
OPTIONS(
expiration_timestamp=TIMESTAMP "2025-01-01 00:00:00 UTC",
partition_expiration_days=30,
description="a table that expires in 2025, with each partition living for 30 days",
labels=[("org_unit", "development")]
)
INSERT
上記テーブルへの登録サンプルです。
INSERT INTO `yi_dataset01.yi_table_partition` (name, quantity)
VALUES
("record01", 1)
,("record02", 2)
,("record03", 3)
パーティションテーブルの作成クエリー/CREATE TABLE
TIMESTAMPカラムによるパーティショニング
CREATE TABLE IF NOT EXISTS yi_dataset01.yi_table_partition_dt
(
name STRING NOT NULL
,dt TIMESTAMP NOT NULL
)
PARTITION BY TIMESTAMP_TRUNC(dt, DAY)
OPTIONS(
expiration_timestamp=TIMESTAMP "2025-01-01 00:00:00 UTC",
partition_expiration_days=30,
description="a table that expires in 2025, with each partition living for 30 days",
labels=[("org_unit", "development")]
)
INSERT
上記テーブルへの登録サンプルです。指定JST日時のTIMESTAMP値を登録
INSERT INTO `yi_dataset01.yi_table_partition_dt` (name, dt)
VALUES
("record01", TIMESTAMP("2021-10-01 00:00:00", "Asia/Tokyo"))
,("record02", TIMESTAMP("2021-10-02 00:00:00", "Asia/Tokyo"))
,("record03", TIMESTAMP("2021-10-03 00:00:00", "Asia/Tokyo"))
クラスタリングテーブル
クラスタリング指定された最大4カラムの内容に基づいてデータが自動で編成されます。指定したカラムは関連するデータが同じ場所に配置されます。そのためサーチ範囲が狭まりクエリーパフォーマンスが向上すること、料金コスト削減が期待できます。
クラスタリングテーブル作成/CLUSTER BY
CREATE TABLE IF NOT EXISTS yi_dataset01.yi_table_partition_dt_cluster
(
name STRING NOT NULL
,quantity INT64 NOT NULL OPTIONS(description="NOT NULL FIELD")
,n_value NUMERIC(10,5)
,dt TIMESTAMP NOT NULL
)
PARTITION BY TIMESTAMP_TRUNC(dt, DAY)
CLUSTER BY name
OPTIONS(
expiration_timestamp=TIMESTAMP "2025-01-01 00:00:00 UTC",
partition_expiration_days=30,
description="a table that expires in 2025, with each partition living for 30 days",
labels=[("org_unit", "development")]
)
INSERT
INSERT INTO `yi_dataset01.yi_table_partition_dt_cluster` (name, quantity, n_value, dt)
VALUES
("record01", 1, 99999.99999, TIMESTAMP("2021-10-01 00:00:00", "Asia/Tokyo"))
,("record02", 1, 99999.99999, TIMESTAMP("2021-10-02 00:00:00", "Asia/Tokyo"))
,("record03", 1, 99999.99999, TIMESTAMP("2021-10-03 00:00:00", "Asia/Tokyo"))
参照
WHEREやGROUP BYなどの指定にクラスタリング列を指定するとパフォーマンス向上および参照範囲の削減による料金コストの削減が見込めます。参照範囲が1/1000になったとの情報も見られました。
SELECT * FROM yi_dataset01.yi_table_partition_dt_cluster WHERE name = "record03"
テーブル名によるシャーディング
パーティションテーブルではなく、テーブル名を一部変更することによりシャーディングすることも可能です。公式ではパーティションテーブルやクラスタリングテーブルを推奨していますが、使い勝手が良いので紹介します。テーブル名末尾に日付をつけたテーブルを複数作成します。 yi_table10_20211001, yi_table10_20211002. そしてワイルドカードを利用してテーブルをまたいだSELECTクエリーを実行します。
CREATE TABLE
TABLE SUFFIXが20211001のテーブルを作成
CREATE TABLE IF NOT EXISTS yi_dataset01.yi_table10_20211001 ( name STRING NOT NULL ,quantity INT64 NOT NULL OPTIONS(description="NOT NULL FIELD") )
INSERT
INSERT INTO yi_dataset01.yi_table_20211001 (name, quantity) VALUES ("20211001", 1)
TABLE SUFFIXが20211002のテーブルを作成
CREATE TABLE IF NOT EXISTS yi_dataset01.yi_table_20211002 ( name STRING NOT NULL ,quantity INT64 NOT NULL OPTIONS(description="NOT NULL FIELD") )
INSERT
INSERT INTO yi_dataset01.yi_table_20211002 (name, quantity) VALUES ("20211002", 2)
_TABLE_SUFFIX擬似列のワイルドカード指定
_TABLE_SUFFIXを使って複数のシャーディングテーブルを参照することができます。上記20211001および20211002テーブルの合計2レコードを参照できます。一月や年などを柔軟に指定できます。
SELECT _TABLE_SUFFIX AS tbl_date, name FROM `yi_dataset01.yi_table_202110*` /* 日付箇所をアスタリスクで指定 */ WHERE _TABLE_SUFFIX BETWEEN '01' AND '02' /* SUFFIXのアスタリスク箇所が01から02のテーブルからSELECTする */ ORDER BY tbl_date ASC
テーブル作成/CREATE TABLE AS SELECT
テーブル定義と登録されているレコードをコピーして新しいテーブルを作成します。
CREATE TABLE yi_dataset01.yi_table_partition_dt_copy AS SELECT * FROM yi_dataset01.yi_table_partition_dt
テーブル作成~あとから通常テーブルをパーティションテーブルへ変更~/CREATE TABLE AS SELECT
CREATE TABLE AS SELECT を使ってあとから通常テーブルをパーティションテーブルへ変更できます。正確には通常テーブルのコピーを作る際にパーティション定義を追加したテーブルとして作成します。その後元のテーブルと作成したテーブルをRenameして入れ替えます。注意としてはパーティションキーにテーブルにあるカラムを指定する事です。 _PARTITIONDATE を使ったパーティションテーブルの作成はできませんでした。列が存在しないエラーとなります。
/* 通常テーブルからパーティションテーブルを作成(コピー) */
CREATE TABLE `yi_dataset01.yi_table_trans_partition`
PARTITION BY TIMESTAMP_TRUNC(dt, hour)
OPTIONS(
expiration_timestamp=TIMESTAMP "2025-01-01 00:00:00 UTC",
partition_expiration_days=30,
description="a table that expires in 2025, with each partition living for 30 days",
labels=[("org_unit", "development")]
)
AS SELECT * FROM yi_dataset01.yi_table_basic_dt
;
/* 元の通常テーブルをリネーム */
ALTER TABLE `yi_dataset01.yi_table_basic_dt` RENAME TO `yi_table_basic_dt_bk`
;
/* 作成したテーブルを元の通常テーブルと同じ名前へリネーム */
ALTER TABLE `yi_dataset01.yi_table_trans_partition` RENAME TO `yi_table_basic_dt`
;
/* 元の通常テーブルを削除 */
DROP TABLE IF EXISTS `yi_table_basic_dt_bk`
;
テーブル作成/CREATE TABLE LIKE
テーブル定義のみコピーしてテーブルを作成します。レコードはコピーされません。
CREATE TABLE yi_dataset01.yi_table_partition_dt_like LIKE yi_dataset01.yi_table_partition_dt
その他クエリー
テーブル定義参照/SHOW CREATE TABLE
bq showコマンドでテーブル定義を参照することができます。
bq show \
--schema \
--format=prettyjson \
yi_dataset01.yi_table_basic
- 結果
[
{
"mode": "REQUIRED",
"name": "name",
"type": "STRING"
},
{
"description": "NOT NULL FIELD",
"mode": "REQUIRED",
"name": "quantity",
"type": "INTEGER"
},
{
"description": "NULLABLE FIELD",
"name": "f_value",
"type": "FLOAT"
},
{
"name": "n_value",
"precision": "10",
"scale": "5",
"type": "NUMERIC"
}
]
料金節約について
BigQuery料金節約方法について、意識するのは可能な限り参照するデータ量を減らすことになります。例として
- [参照対象を減らす] カラムナーデータストアなので可能な限り参照するカラムを指定して SELECT する
- [参照範囲を減らす] SELECT時に参照範囲を減らすためにパーティションテーブルやクラスタリングテーブルやテーブル名シャーディングを使う
- [参照データの削減] 不要なデータを削除するためにテーブルの有効期限を設定する
などが効果が高いです。
最後に
次世代システム研究室では、グループ全体のインテグレーションを支援してくれるアーキテクトを募集しています。アプリケーション開発の方、次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ募集職種一覧からご応募をお願いします。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD




