2022.04.08
自作MLプロジェクトでMLOps界隈の技術を試してみる その1
こんにちはS.Y.です。
今年は機械学習プロダクトにおいて、モデル中心でPDCAサイクルを高速で回せる設計はどのようなものかを考えていきたいと思います。
機械学習プロダクトは実験的な側面が大きかったり、「正常稼働状態」を定義・担保するのが難しかったりといった特徴があるため、一般的なシステムにおけるDevOpsのようなやり方では、十分に継続的・安定的に運用することはできません。下記の図のように、MLシステムを構成する要素は膨大です。
ご存知の方も多いとは思いますが、このような機械学習プロダクトやモデルを管理するための技術領域として、MLOpsがここ数年でを注目を集めています。よく話に出る機械学習パイプラインをはじめ、学習データを作成するETLの部分や、モデルの可視化・分析など、プロダクトを成功に導くためのファクターがあります。
本ブログでは擬似的な機械学習プロダクトを作成し、数回にわたってMLOpsの技術を適用・検証していきます。
時代はクラウドということで、クラウドサービス(GCP)で構築していきます。学習データの検証、取り込み、モデルの学習、モニタリング等を自動で行い、モデル更新や異常への対応を自動・低コストで実現できるようなMLOpsプロダクトを目指します。
初回である今回は、データ作成からモデルサービングまでの最低限の流れを構築し、プロダクトのプロトタイプを作ります。
- データソースから学習データを作成するETL
- データ取り込みからサービングまでの機械学習パイプライン
- 作成されたモデルの可視化・分析
の部分をそれぞれ作り、下記のような構成を目指します。
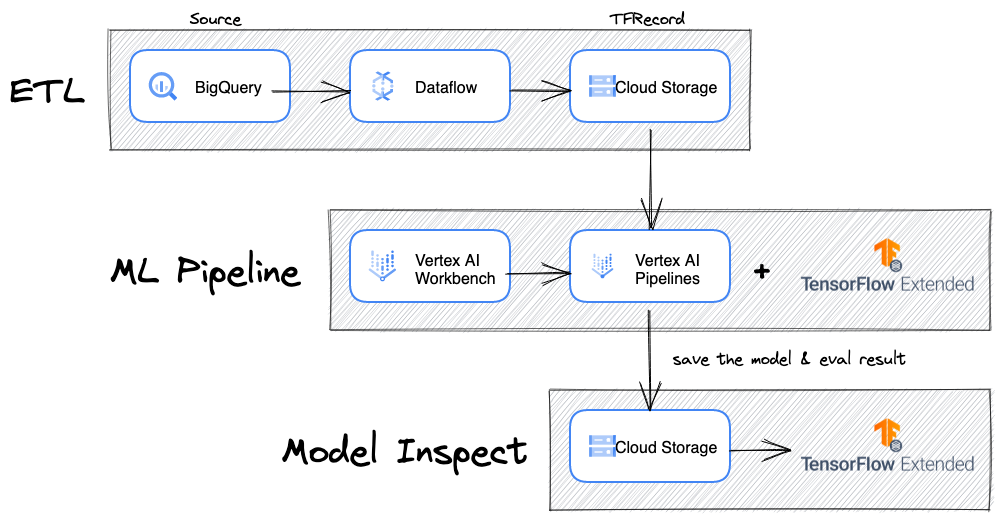
ETL部分はGoogle Dataflow、機械学習モデルはTensorflow、機械学習パイプラインはTensorflow Extended + VertexAI、モデル可視化・分析はTensorflow Model Analysis(TFMA)を使用します。
プロダクト概要
タクシーの乗車履歴データからある乗車のチップの金額を予測するようなモデルを作成し、それを継続的に学習・更新できるような構成を目指します。
学習データはBigqueryのオープンデータセットであるbigquery-public-data.chicago_taxi_trips.taxi_tripsを使用します。このデータセットには2020年までのシカゴタクシーの乗車履歴が保存されています。乗車エリア、乗車時間、支払い料金、チップ金額などの情報が入っています。
特にEDAは行わず、とりあえず以下の7つの情報を特徴として使用することにします。
- 乗車時刻 (hr)
- タクシーの平均チップ金額
- タクシーの平均料金
- タクシーで発生したチップの回数
- エリアの平均チップ金額
- エリアの平均料金
- エリアで発生したチップの回数
乗車時間帯(よるの方が飲み会後とかでチップを弾んでくれそう)、タクシーの質(良い運転手かどうか)、乗車エリア(裕福な人が多いエリアの方がチップが多そう)あたりがチップと関係ありそうだなと思ったのですが、私はチップ文化に明るくないのでこれは完全な妄想です笑
乗車時刻はレコードのデータをhrにフォーマットします。それ以外の特徴は過去の期間からタクシー毎、エリア毎でそれぞれ値を集計して使用します。
ETL部分
ETLでは、生データを加工してモデル学習の入力となる学習データに変換します。現場ではテキストデータなどのより非整形なデータを変換する場面も多いと思いますが、今回はGoogle Bigqueryのtableデータを入力とし、Google Cloud Storageにtfrecordを出力するデータ処理パイプラインを作成します。ある程度形式化されてはいますが、データは単純な乗車履歴なので、機械学習の特徴を作るには色々と加工・集計をする必要があります。
データ処理にはApache BeamをGoogle Dataflowエンジンで使います。今回はBQからBeamのパイプラインにロードするSQLで集計やJOINは済ませてしまい、読み込んだデータをtfrecordで保存する処理だけをBeamで行います。ロードはテーブルをそのまま読み込むだけにして、以降の処理はBeamのパイプライン上で関数として実行した方がTestabilityの観点からより良い構成になります。これは次回以降に実践しようと思います。
BQをソースにGCSのTFRecordを作成する他の方法としては、Apache Spark on Google Dataprocがあります。DataflowはDataprocに比べて、ノードの詳細なスペック等を設定せずにオートスケーリングしてくれるという点が強みだと個人的に感じています。
以下がDataflowのデータ処理パイプラインのコードです。DirectRunnerを指定するとローカル実行、DataflowRunnerを指定するとDataflowにジョブを投げての実行になります。
import logging
import os
import tensorflow as tf
from tensorflow_transform.tf_metadata import dataset_metadata
from tensorflow_transform.tf_metadata import schema_utils
import tensorflow_transform.beam as tft_beam
from tensorflow_transform.coders import example_proto_coder
import apache_beam as beam
from apache_beam.options.pipeline_options import PipelineOptions
CATEGORICAL_FEATURE_NAMES = []
NUMERIC_FEATURE_NAMES = ["area_avg_tips", "area_avg_fare", "area_n_tips", "taxi_avg_tips", "taxi_avg_fare",
"taxi_n_tips"]
TARGET_FEATURE_NAME = "label_tips"
def create_raw_metadata():
raw_data_schema = {}
raw_data_schema[TARGET_FEATURE_NAME] = tf.io.FixedLenFeature([], tf.float32)
raw_data_schema.update(
{column_name: tf.io.FixedLenFeature([], tf.string) for column_name in CATEGORICAL_FEATURE_NAMES})
raw_data_schema.update(
{column_name: tf.io.FixedLenFeature([], tf.float32) for column_name in NUMERIC_FEATURE_NAMES})
raw_metadata = dataset_metadata.DatasetMetadata(
schema_utils.schema_from_feature_spec(raw_data_schema))
return raw_metadata
def run(argv=None, save_main_session=True):
p_options = {
"project": "MY_PROJECT_ID",
"region": "us-east1",
"staging_location": "gs://MY_MLOPS_PRODUCT_BUCKET/staging/",
"temp_location": "gs://MY_MLOPS_PRODUCT_BUCKET/tmp/",
"runner": "DataflowRunner",
# "runner": "DirectRunner",
"setup_file": "./setup.py",
"save_main_session": True
}
pipeline_options = PipelineOptions(flags=[], **p_options)
file_dir = os.path.dirname(os.path.abspath(__file__))
stat_query_path = os.path.abspath(os.path.join(file_dir, "sql/training_dataset.sql"))
with open(stat_query_path, "r") as f:
training_dataset_query = f.read()
input_metadata = create_raw_metadata()
with tft_beam.Context(temp_dir="gs://MY_MLOPS_PRODUCT_BUCKET/tmp"):
with beam.Pipeline(options=pipeline_options) as p:
dataset = (
p | 'QueryTable' >> beam.io.ReadFromBigQuery(query=training_dataset_query, use_standard_sql=True)
)
coder = example_proto_coder.ExampleProtoCoder(input_metadata.schema)
dataset = (
dataset | 'Serialize to tfrecord' >> beam.Map(coder.encode)
)
dataset | "Write" >> beam.io.tfrecordio.WriteToTFRecord(
os.path.join("gs://MY_MLOPS_PRODUCT_BUCKET/read_bq_tests/tfrecords_outputs", 'taxi_train_tfrecord-'))#, coder)
if __name__ == '__main__':
logging.getLogger().setLevel(logging.INFO)
run()
以下は学習データを作成するSQLです。最終的なカラムの型を明示しないとBeamのパイプラインにloadする際に型の不一致でエラーになる可能性があるので注意が必要です。
CREATE TEMPORARY FUNCTION OFFLINE_START_DATE() AS ("2022-01-01 00:00:00");
CREATE TEMPORARY FUNCTION OFFLINE_END_DATE() AS ("2022-01-14 00:00:00");
CREATE TEMPORARY FUNCTION ONLINE_START_DATE() AS ("2022-01-15 00:00:00");
CREATE TEMPORARY FUNCTION ONLINE_END_DATE() AS ("2022-01-31 00:00:00");
WITH offline_features_taxi AS (
SELECT taxi_id
, AVG(tips) taxi_avg_tips
, AVG(fare) taxi_avg_fare
, SUM(IF(tips != 0.0,1,0)) taxi_n_tips
FROM `bigquery-public-data.chicago_taxi_trips.taxi_trips`
WHERE trip_start_timestamp BETWEEN TIMESTAMP(OFFLINE_START_DATE()) AND TIMESTAMP(OFFLINE_END_DATE())
GROUP BY taxi_id
)
, offline_features_area AS (
SELECT pickup_community_area
, AVG(tips) area_avg_tips
, AVG(fare) area_avg_fare
, SUM(IF(tips != 0.0,1,0)) area_n_tips
FROM `bigquery-public-data.chicago_taxi_trips.taxi_trips`
WHERE trip_start_timestamp BETWEEN TIMESTAMP(OFFLINE_START_DATE()) AND TIMESTAMP(OFFLINE_END_DATE())
GROUP BY pickup_community_area
)
, online_features AS (
SELECT taxi_id
, FORMAT_TIMESTAMP("%H", trip_start_timestamp) as start_hour
, pickup_community_area
, tips label_tips
FROM `bigquery-public-data.chicago_taxi_trips.taxi_trips`
WHERE trip_start_timestamp BETWEEN TIMESTAMP(ONLINE_START_DATE()) AND TIMESTAMP(ONLINE_END_DATE())
)
, training_data AS (
SELECT t1.taxi_id
, CAST(t1.start_hour AS string) start_hour
, CAST(t1.pickup_community_area AS string) pickup_community_area
, CAST(area_avg_tips AS float64) area_avg_tips
, CAST(area_avg_fare AS float64) area_avg_fare
, CAST(area_n_tips AS float64) area_n_tips
, CAST(taxi_avg_tips AS float64) taxi_avg_tips
, CAST(taxi_avg_fare AS float64) taxi_avg_fare
, CAST(taxi_n_tips AS float64) taxi_n_tips
, CAST(t1.label_tips AS float64) label_tips
FROM (
SELECT t1.*
, area_avg_tips
, area_avg_fare
, area_n_tips
FROM online_features t1 JOIN offline_features_area t2 ON t1.pickup_community_area = t2.pickup_community_area
) t1 JOIN offline_features_taxi t2 ON t1.taxi_id = t2.taxi_id
)
SELECT *
FROM training_data
WHERE label_tips IS NOT NULL
機械学習パイプライン
Vertex AI + Tensorflow Extendedで、学習データの取り込みからモデルサービングまでを一気通貫で行うような機械学習パイプラインを構築します。
Tensorflow Extendedでは下記の図のように、パイプラインを構成する様々なコンポーネントが用意されています。
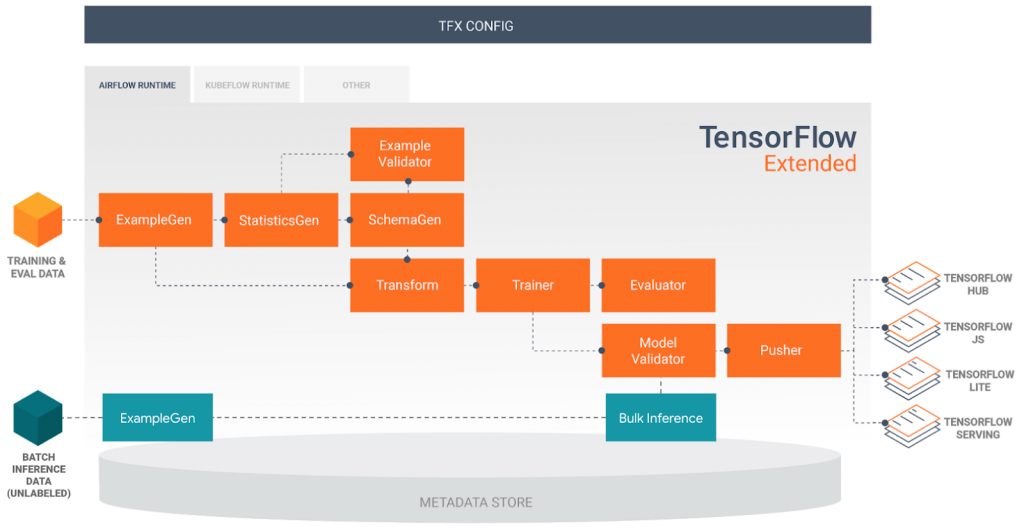
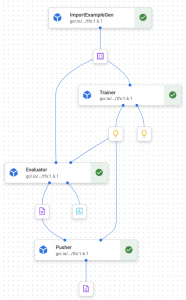
今回は学習データ取り込み (ExampleGen)・モデル学習 (Trainer)・モデル評価 (Model Validator)・サービング (Pusher)の4つを繋ぎ、パイプラインとして最低限動くものを作ります。
TFXパイプラインでは各コンポーネントのoutputを出力したり、Trainerの入力となるモデルの定義ファイルを置いておいたりするのにファイルストレージを使用します。GCP上で動かすのであれば、GCSにパイプライン用のバケットを用意して使用しましょう。
コードはこちらのチュートリアルをベースにしています。tfx[kfp]==1.6.1で動作確認済みです。最近リリースされたtfx==1.7.0だと構成がだいぶ変わっているので、バージョン指定しないと動きませんでした。(2022年3月時点)
開発環境はVertex AI Workbenchを使用しました。
パッケージのインストール
!pip install --upgrade pip !pip install --upgrade "tfx[kfp]==1.6.1" import tensorflow as tf from tensorflow import keras from tfx import v1 as tfx from tfx.components.example_gen.import_example_gen.component import ImportExampleGen
ExampleGen
ExampleGenはデータソースをtrain/evalに分割し、パイプラインにデータを取り込みます。
現在はデータソースとして
- CSV ファイル
- TF Example フォーマットの TFRecord ファイル
- BigQuery のクエリ結果
の3つがサポートされています。
今回はImportExampleGenでGCS上のTFRecordを読み込みます。data_rootにはTFRecordが保存されているGCSディレクトリのパスを指定します。
example_gen = ImportExampleGen(input_base=data_root)
オプションでoutput_configを与えることで、train/validの比率を変えたり、既にtrain/validでディレクトリ が分かれている場合はそれぞれを指定したりできます。また、正規表現を使ってprefixが最新のディレクトリから読み取る、というようなこともできます。
Trainer
ExampleGenが分割したtrain/validデータを使い、名前の通りモデルのトレーニングを行います。モデルを定義した.pyファイルを予めGCSに置いておき、module_fileでそのパスを指定します。custom_configで学習ステップ数や、学習に使用するGCEインスタンスやコンテナのスペック等を指定します。
vertex_job_spec = {
'project': project_id,
'worker_pool_specs': [{
'machine_spec': {
'machine_type': 'n1-standard-4',
},
'replica_count': 1,
'container_spec': {
'image_uri': 'gcr.io/tfx-oss-public/tfx:{}'.format(tfx.__version__),
},
}],
}
if use_gpu:
vertex_job_spec['worker_pool_specs'][0]['machine_spec'].update({
'accelerator_type': 'NVIDIA_TESLA_K80',
'accelerator_count': 1
})
trainer = tfx.extensions.google_cloud_ai_platform.Trainer(
module_file=module_file,
examples=example_gen.outputs['examples'],
train_args=tfx.proto.TrainArgs(num_steps=10),
eval_args=tfx.proto.EvalArgs(num_steps=5),
custom_config={
tfx.extensions.google_cloud_ai_platform.ENABLE_UCAIP_KEY:
True,
tfx.extensions.google_cloud_ai_platform.UCAIP_REGION_KEY:
region,
tfx.extensions.google_cloud_ai_platform.TRAINING_ARGS_KEY:
vertex_job_spec,
'use_gpu':
use_gpu,
})
モデル定義のpyファイル
Trainerで読み込む.pyファイルは一般的なモデル定義以外にも、パイプライン上のコンポーネントとして動作するための記述が色々必要です。チュートリアルで用意されているテンプレートをベースに、_make_keras_model()や_FEATURE_KEYSを適宜書き換えて使うやり方が、エラーが少なくて済むかと思います。
また、この.pyファイルにエラーがあるとパイプラインがThe DAG failed because some tasks failed.というようなエラーで失敗しますが、現状ログからそれ以上原因を深掘ることができないようなので、予めモデル定義が動くかを別で検証しておく必要があります。(仮にパイプラインのエラーを深堀りできたとしても、一回のパイプライン実行に時間がかかるので、事前にモデル定義検証をしておくのは必須ですね)
一点気をつける必要があるのが、kerasモデルの入力層はkeras.layers.Input(shape=(n_features,))ではなく、keras.layers.Input(shape=(1,))をn_features個分concatenateした形にする点です。これもチュートリアルのコードをベースにしていれば問題は起きないと思います。
from typing import List
from absl import logging
import tensorflow as tf
from tensorflow import keras
from tensorflow_metadata.proto.v0 import schema_pb2
from tensorflow_transform.tf_metadata import schema_utils
from tfx import v1 as tfx
from tfx_bsl.public import tfxio
_FEATURE_KEYS = [
'area_avg_tips', 'area_avg_fare', 'area_n_tips', 'taxi_avg_tips', 'taxi_avg_fare', 'taxi_n_tips'
]
_LABEL_KEY = 'label_tips'
_TRAIN_BATCH_SIZE = 20
_EVAL_BATCH_SIZE = 10
_FEATURE_SPEC = {
**{
feature: tf.io.FixedLenFeature(shape=[1], dtype=tf.float32)
for feature in _FEATURE_KEYS
}, _LABEL_KEY: tf.io.FixedLenFeature(shape=[1], dtype=tf.float32)
}
def _input_fn(file_pattern: List[str],
data_accessor: tfx.components.DataAccessor,
schema: schema_pb2.Schema,
batch_size: int) -> tf.data.Dataset:
return data_accessor.tf_dataset_factory(
file_pattern,
tfxio.TensorFlowDatasetOptions(
batch_size=batch_size, label_key=_LABEL_KEY),
schema=schema).repeat()
def _make_keras_model() -> tf.keras.Model:
inputs = [keras.layers.Input(shape=(1,), name=f) for f in _FEATURE_KEYS]
d = keras.layers.concatenate(inputs)
for _ in range(2):
d = keras.layers.Dense(8, activation='relu')(d)
outputs = keras.layers.Dense(1)(d)
model = keras.Model(inputs=inputs, outputs=outputs)
model.compile(loss=tf.keras.losses.MeanSquaredError(),
optimizer=keras.optimizers.Adam(1e-2),
metrics=[tf.keras.metrics.MeanSquaredError()])
model.summary(print_fn=logging.info)
return model
def _get_distribution_strategy(fn_args: tfx.components.FnArgs):
if fn_args.custom_config.get('use_gpu', False):
logging.info('Using MirroredStrategy with one GPU.')
return tf.distribute.MirroredStrategy(devices=['device:GPU:0'])
return None
# TFX Trainer will call this function.
def run_fn(fn_args: tfx.components.FnArgs):
schema = schema_utils.schema_from_feature_spec(_FEATURE_SPEC)
train_dataset = _input_fn(
fn_args.train_files,
fn_args.data_accessor,
schema,
batch_size=_TRAIN_BATCH_SIZE)
eval_dataset = _input_fn(
fn_args.eval_files,
fn_args.data_accessor,
schema,
batch_size=_EVAL_BATCH_SIZE)
strategy = _get_distribution_strategy(fn_args)
if strategy is None:
model = _make_keras_model()
else:
with strategy.scope():
model = _make_keras_model()
model.fit(
train_dataset,
steps_per_epoch=fn_args.train_steps,
validation_data=eval_dataset,
validation_steps=fn_args.eval_steps)
model.save(fn_args.serving_model_dir, save_format='tf')
Model Evaluation
Model Evaluationでは、作成されたモデルがデプロイするに足りるかを評価します。デプロイに足りると判断されることをblessing(祝福)と呼び、モデルがblessされた場合に後続のPusherを呼び出します。
EvalConfigで設定するmetricsはモデルがblessされる条件です。accuracyやMSEが基準値を満たしているかや、現在blessされた最新のモデルより精度が高いかなどを複数指定できます。
sliceを指定することでデータセットをあるカテゴリに分割して評価できます。例えば、tfma.SlicingSpec(feature_keys=['area'])を指定するとarea毎にmetricsを満たしているかが評価されます。tfma.SlicingSpec()はデータセット全体について評価します。
eval_config = tfma.EvalConfig(
model_specs=[
tfma.ModelSpec(label_key="label_tips")
],
metrics_specs=[
tfma.MetricsSpec(
metrics=[
tfma.MetricConfig(class_name='ExampleCount'),
tfma.MetricConfig(class_name='MeanSquaredError',
threshold=tfma.MetricThreshold(
value_threshold=tfma.GenericValueThreshold(
upper_bound={'value': 0.5}))
)
]
)
],
slicing_specs=[
tfma.SlicingSpec(),
tfma.SlicingSpec(feature_keys=['area_avg_tips'])
])
evaluator = tfx.components.Evaluator(
examples=example_gen.outputs['examples'],
model=trainer.outputs['model'],
eval_config=eval_config)
Pusher
PusherのconfigではTrainerと同様に、GCEインスタンスやコンテナのスペックを指定できます。
実行が完了すると、VertexAIにモデルがデプロイされ、そのモデルが紐づいたエンドポイントが作成されます。
vertex_serving_spec = {
'project_id': project_id,
'endpoint_name': endpoint_name,
'machine_type': 'n1-standard-4',
}
serving_image = 'us-docker.pkg.dev/vertex-ai/prediction/tf2-cpu.2-6:latest'
if use_gpu:
vertex_serving_spec.update({
'accelerator_type': 'NVIDIA_TESLA_K80',
'accelerator_count': 1
})
serving_image = 'us-docker.pkg.dev/vertex-ai/prediction/tf2-gpu.2-6:latest'
pusher = tfx.extensions.google_cloud_ai_platform.Pusher(
model=trainer.outputs['model'],
model_blessing=evaluator.outputs['blessing'],
custom_config={
tfx.extensions.google_cloud_ai_platform.ENABLE_VERTEX_KEY:
True,
tfx.extensions.google_cloud_ai_platform.VERTEX_REGION_KEY:
region,
tfx.extensions.google_cloud_ai_platform.VERTEX_CONTAINER_IMAGE_URI_KEY:
serving_image,
tfx.extensions.google_cloud_ai_platform.SERVING_ARGS_KEY:
vertex_serving_spec,
})
パイプライン作成
今までに定義した各コンポーネントをリストにして、パイプラインのインスタンスを作成する_create_pipeline()関数を定義します。
def _create_pipeline(pipeline_name: str, pipeline_root: str, data_root: str,
module_file: str, endpoint_name: str, project_id: str,
region: str, use_gpu: bool) -> tfx.dsl.Pipeline:
components = [
example_gen,
trainer,
evaluator,
pusher,
]
return tfx.dsl.Pipeline(
pipeline_name=pipeline_name,
pipeline_root=pipeline_root,
components=components)
パイプライン定義ファイルの作成とVertexAIへのデプロイ
定義したパイプラインをVertexAIにデプロイするには、まずパイプライン定義ファイルを作成し、それを元にAIPlatformのPipelineジョブをsubmitします。
定義ファイルは、TFXのDagRunnerで_create_pipeline()関数を実行することで、Workbenchのローカルファイルストレージ上に作成されます。
定義ファイルが作成されたら、あとはそれを指定して作成したjobをsubmitするだけです。
import os
PIPELINE_DEFINITION_FILE = PIPELINE_NAME + '_pipeline.json'
runner = tfx.orchestration.experimental.KubeflowV2DagRunner(
config=tfx.orchestration.experimental.KubeflowV2DagRunnerConfig(),
output_filename=PIPELINE_DEFINITION_FILE)
_ = runner.run(
_create_pipeline(
pipeline_name=PIPELINE_NAME,
pipeline_root=PIPELINE_ROOT,
data_root=DATA_ROOT,
module_file=os.path.join(MODULE_ROOT, _trainer_module_file),
endpoint_name=ENDPOINT_NAME,
project_id=GOOGLE_CLOUD_PROJECT,
region=GOOGLE_CLOUD_REGION,
# We will use CPUs only for now.
use_gpu=False))
from google.cloud import aiplatform
from google.cloud.aiplatform import pipeline_jobs
import logging
logging.getLogger().setLevel(logging.INFO)
aiplatform.init(project=GOOGLE_CLOUD_PROJECT, location=GOOGLE_CLOUD_REGION)
job = pipeline_jobs.PipelineJob(template_path=PIPELINE_DEFINITION_FILE,
display_name=PIPELINE_NAME)
job.submit()
submitされたジョブはVertex Pipelineで確認できます。
モデル可視化・分析
モデルの可視化は、Tensorflow Model Analysis(TFMA)で実現します。パイプラインのモデル評価部分で作成された評価結果を元に、Google ColaboratoryやJupyterNotebook上で可視化・分析できます。
Evaluatorの評価結果をTensorflow Model Analysis(TFMA)で可視化してみましょう。Evaluatorは実行後GCS上にEvaluator-XXXXXXというディレクトリ を作成します。その中のevaluationディレクトリに可視化で使うデータがTFRecord形式で保存されています。Google Colaboratory上でこれを読み込んで、グラフを描画してみます。
最初に必要なライブラリをインストールしたり、google認証したりします。
!pip install -U pip !pip install "tensorflow-model-analysis" mport sys # Confirm that we're using Python 3 assert sys.version_info.major==3, 'This notebook must be run using Python 3.' import tensorflow as tf import apache_beam as beam import tensorflow_model_analysis as tfma from google.colab import auth auth.authenticate_user() project_id = 'my_project_id'
gcsのディレクトリ をcolabのローカルストレージにマウントします。
!echo "deb http://packages.cloud.google.com/apt gcsfuse-`lsb_release -c -s` main" | sudo tee /etc/apt/sources.list.d/gcsfuse.list !curl https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add - !apt-get -y -q update !apt-get -y -q install gcsfuse !gcsfuse --implicit-dirs --limit-bytes-per-sec -1 --limit-ops-per-sec -1 GCP_DIR ./tmp
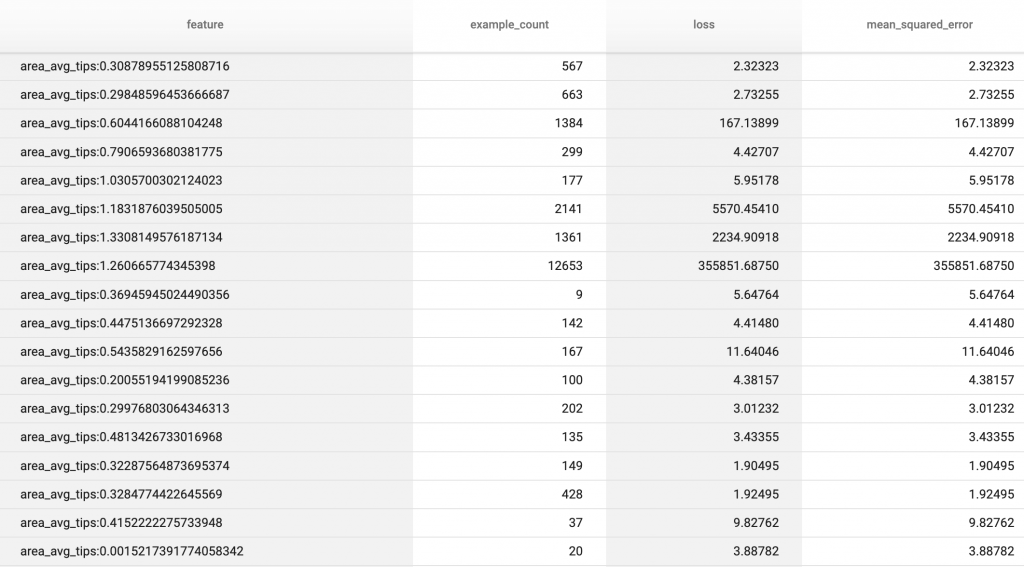
あとはマウントしたevaluationディレクトリを指定してloadしたtfma_resutlを描画するだけです。sliceの例としてはあまり良くない(意味がない)のですが、area_avg_tips毎のsample_countやMSEなどを可視化しています。
tfma_result = tfma.load_eval_result("./tmp/PATH_TO_EVALUATION")
tfma.view.render_slicing_metrics(tfma_result, slicing_column='area_avg_tips')

コスト
今回作成した構成で、GCPコストがかかる部分は以下の通りです。GCEインスタンスを消費するものはコストが大きくなるので、使わない時は停止するなどしてコストを抑える必要があります。
- ETL
- GCS
- 保存されているデータ量
- BigQuery
- 処理したデータ量
- DataFlow (バッチ処理)
- 消費したDataFlowワーカー (DataFlowワーカーはCompute Engine(GCE)を消費しますが、ここで消費されるGCEインスタンスの料金はDataFlowの料金に含まれています)
- 処理したデータ量
- GCS
- 機械学習パイプライン
- VertexAI Workbench
- 起動中のノートブックインスタンス
- 開発時以外は停止するようにしましょう。
- 起動中のノートブックインスタンス
- VertexAI Pipelines
- 呼び出されるGCPリソースについて課金されます。今回はカスタムトレーニングで使用したマシンについてコストがかかります。
- パイプラインの実行についても若干の料金($0.03/回)がかかります。
- VertexAI Model
- 保存されているモデル
- VertexAI Prediction (オンライン予測)
- 予測ノードがリクエスト処理に要した時間と、待機状態になっていた時間
- VertexAI Workbench
最後に
今回はDataflow、VertexAI、Tensorflow Extendedを使って、簡単な機械学習プロダクトを作成してみました。DataflowでBQテーブルから学習データを作成し、VertexAI+TFXで学習データ取り込みからモデルサービングまでの最低限のパイプラインを作成できました。
今後は、Dataflowでのデータ処理をテスト可能な実装にしたり、機械学習パイプラインに取り込むデータのバリデーションを追加したりと、より安定して運用していけるような実装・構成にしたり、DataflowやVertex Pipelinesをスケジュールしたりと、いろいろと試していきたいです。
次世代システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。興味を持って頂ける方がいらっしゃいましたら、ぜひ募集職種一覧からご応募をお願いします。
一緒に勉強しながら楽しく働きたい方のご応募をお待ちしております。
参考
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD