2023.04.07
Spark NLPでTransformerモデルをスケールする
目次
- Summary
- クラスタ構成
- Spark Rapids
- XGBoost4j-Spark-GPU
- Spark NLP
- ChatGPTとテストしてみる
- Fine-tuningについて
- Sample Model
- Spark NLP Displayによる可視化
- Synapse ML
- 最後に
1. Summary
- Spark Rapidsを使用することでSparkジョブをGPU上で実行できる
- Spark NLPによりSpark上でTransformerモデルの転移学習や推論ができる
- SparkとGPUでXGBoostやLightGBMの学習や推論を高速に並列分散処理できる
2. クラスタ構成
まずSparkクラスタを準備します。今回は以下の構成で環境をセットアップしました。
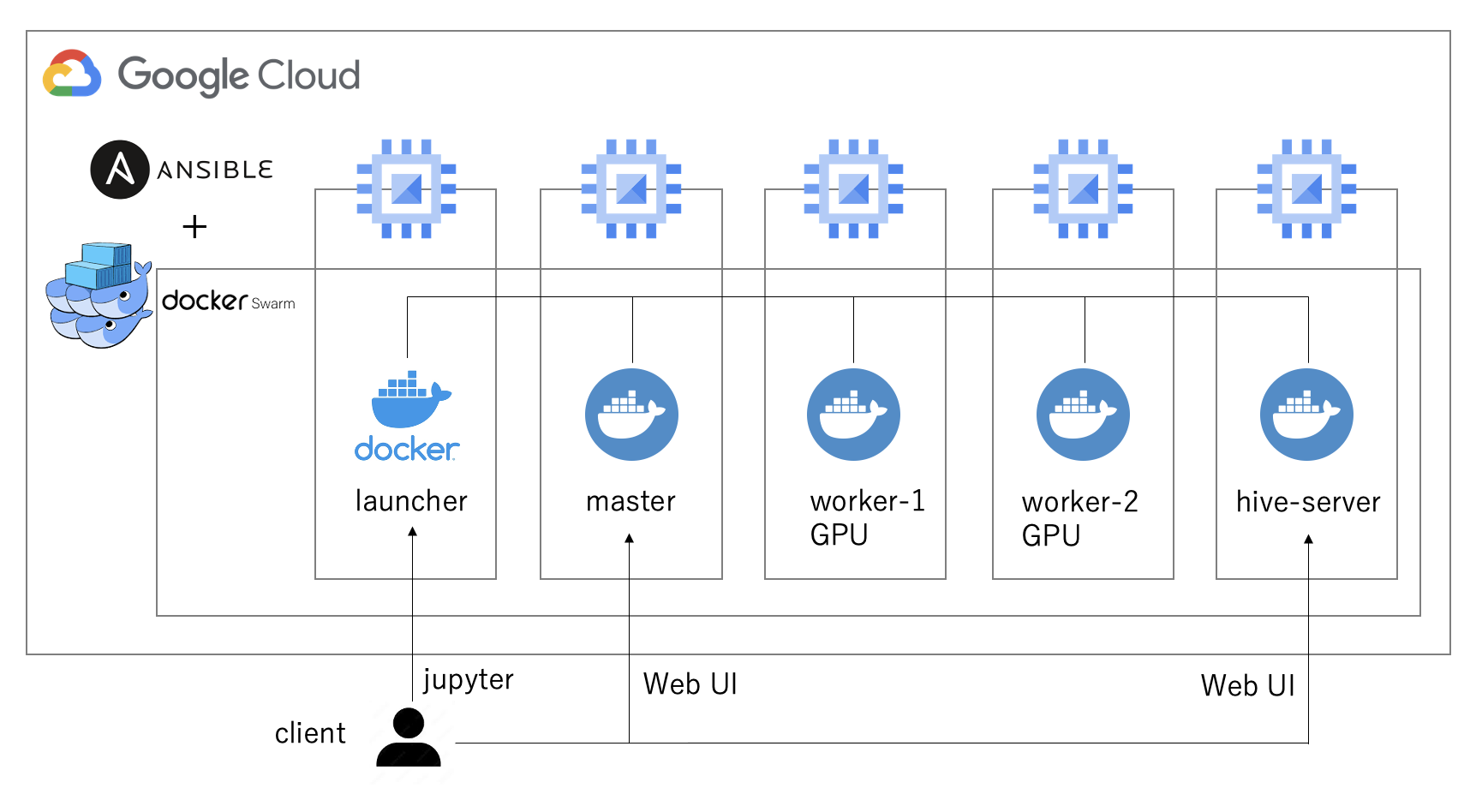
Sparkクラスタ間のデータのI/OやDB操作を効率的に行うため、Apache HadoopとApache Hiveもインストールしています。なお、今回はStandaloneモードでSparkを実行しますが、SparkでGPUのジョブを実行する際の分散処理エンジンとしてKubernetesを使用することもできます。
主要なコンポーネントは以下の通りです。
- VM: Google Compute Engineのn1-highmemシリーズ
- GPU: NVidia Tesla V100(Pascalアーキテクチャ以降のGPUであれば可)/li>
- Ansible: 2.13.5
- Docker image: nvidia/cuda:11.3.1-devel-ubuntu20.04
- Apache Spark: 3.3.1
- Apache Hadoop: 3.3.4
- Apache Hive: 3.1.3
- Spark Rapids: 22.12.0-cuda11
- Spark NLP: 4.0.2
- Horovod: 0.27.0
- Synapse ML: 0.11.0
各種ソフトウェアにはそれぞれ依存関係があるのですが、それぞれのビルド方法を調べるとわかるので省略しています。また、以降の解析の途中で用いる別途追加パッケージやライブラリもありますが、簡単に推察できる部分はここでは割愛しています。
3. Spark Rapids
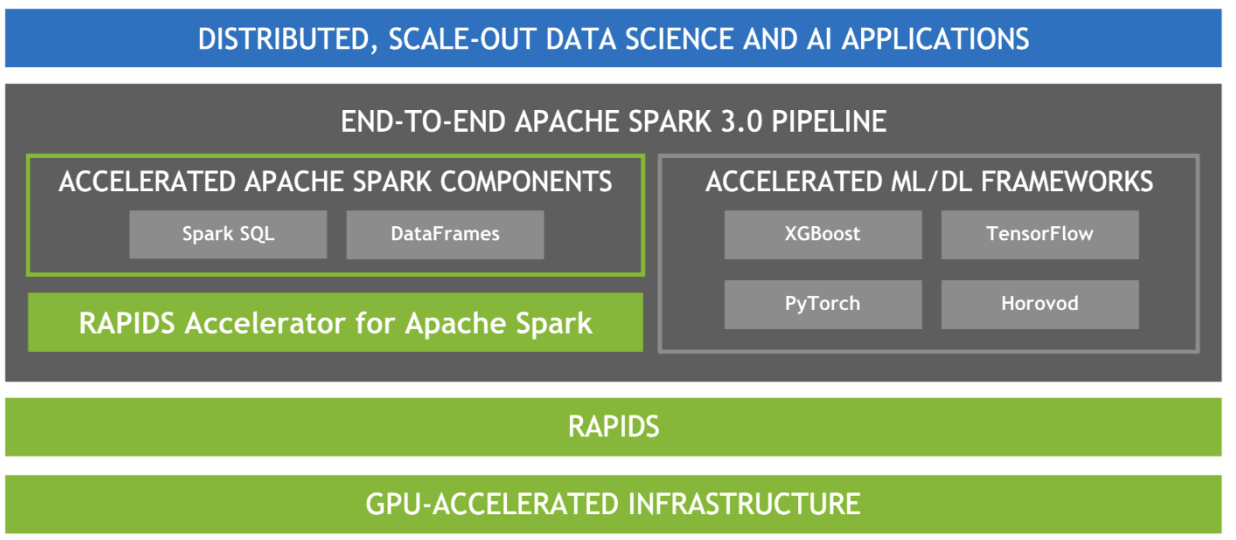
Spark GPUのジョブを実行する際に使用するのがSpark Rapidsです。こちらはRapids(https://rapids.ai/)というNVidia GPU上でデータサイエンス関連のデータ処理を実行のためのライブラリ群の一部であり、インストールすることでSparkジョブをGPU上で実行することができるようになります。SparkをCPUで実行する際のコードをほぼそのまま実行できるので、Spark Rapidsのセットアップが出来ればCPUからの移行は非常にスムーズです。手順としてはjarファイルの準備とSparkのconfigファイルの設定を行います。
以下では/opt/sparkRapidsPluginに保存して利用します。セットアップの手順の詳細はSpark RapidsのWebサイトを確認してください。
# Dockerfile: Spark Rapids
RUN mkdir /opt/sparkRapidsPlugin && \
cd /opt/sparkRapidsPlugin && \
wget --quiet https://repo1.maven.org/maven2/com/nvidia/rapids-4-spark_2.12/22.12.0/rapids-4-spark_2.12-22.12.0-cuda11.jar && \
wget --quiet https://repo1.maven.org/maven2/ai/rapids/cudf/22.12.0/cudf-22.12.0-cuda11.jar && \
wget --quiet https://github.com/apache/spark/raw/master/examples/src/main/scripts/getGpusResources.sh && \
chmod -R 777 /opt/sparkRapidsPlugin
# Configuration: spark-env.sh
SPARK_WORKER_OPTS="-Dspark.worker.resource.gpu.amount=1 -Dspark.worker.resource.gpu.discoveryScript=/opt/sparkRapidsPlugin/getGpusResources.sh"
なお、Sparkのセッション開始時にspark-submitの引数やSparkConfでGPUのための設定値を指定して実行する必要があります。Sparkジョブ一般に言えることですが、実行時の計算量に応じて引数を指定しないとOOM等のエラーの原因となるため、関連するパタメータについては丁寧に確認すると良いと思います。
以下は、spark-shellとSparkContextでGPUジョブを実行する際のサンプルコードです。なお、SPARK_RAPIDS_DIRは先ほどjarファイルを保存したディレクトリのパスで、SPARK_RAPIDS_PLUGIN_JAR, SPARK_CUDF_JARはRapidsのjarファイルのパスを表す環境変数となっています。
# spark-shell
${SPARK_HOME}/bin/spark-shell \
--master spark://master:7077 \
--num-executors 1 \
--executor-memory 12g \
--driver-memory 8g \
--files ${SPARK_RAPIDS_DIR}/getGpusResources.sh \
--conf spark.executor.extraClassPath=${SPARK_RAPIDS_PLUGIN_JAR} \
--conf spark.driver.extraClassPath=${SPARK_RAPIDS_PLUGIN_JAR} \
--conf spark.executor.cores=1 \
--conf spark.executor.resource.gpu.amount=1 \
--conf spark.rapids.sql.concurrentGpuTasks=1 \
--conf spark.task.cpus=1 \
--conf spark.task.resource.gpu.amount=1 \
--conf spark.executor.resource.gpu.discoveryScript=${SPARK_RAPIDS_DIR}/getGpusResources.sh \
--conf spark.rapids.memory.pinnedPool.size=4G \
--conf spark.sql.files.maxPartitionBytes=512m \
--conf spark.plugins=com.nvidia.spark.SQLPlugin \
--jars ${SPARK_RAPIDS_PLUGIN_JAR},${SPARK_CUDF_JAR}
# SparkContextの定義
from os import getenv
from pyspark import SparkConf, SparkContext
from pyspark.sql import SparkSession
SPARK_RAPIDS_JAR = "/opt/sparkRapidsPlugin/rapids-4-spark_2.12-22.12.0-cuda11.jar"
CUDF_JAR = "/opt/sparkRapidsPlugin/cudf-22.12.0-cuda11.jar"
RAPIDS_MLD_JAR = "/opt/sparkRapidsPlugin/rapids-4-spark-ml_2.12-22.02.0-cuda11.jar"
RAPIDS_JAR = getenv("RAPIDS_JAR", "{0},{1},{2}".format(SPARK_RAPIDS_JAR, CUDF_JAR, RAPIDS_MLD_JAR))
GPU_DISCOVERY_SCRIPT = "/opt/sparkRapidsPlugin/getGpusResources.sh"
SPARK_MASTER_URL = getenv("SPARK_MASTER_URL", "spark://master:7077")
driverMem = getenv("DRIVER_MEM", "10g")
executorMem = getenv("EXECUTOR_MEM", "10g")
# Common spark settings
conf = SparkConf()
conf.setMaster(SPARK_MASTER_URL)
conf.setAppName("PysparkTest")
conf.set("spark.driver.memory", driverMem)
conf.set("spark.executor.memory", executorMem)
conf.set("spark.executor.instances", 2)
conf.set("spark.executor.cores", 2)
conf.set("spark.rapids.sql.concurrentGpuTasks", 1)
conf.set("spark.task.cpus", 1)
conf.set("spark.task.resource.gpu.amount", 1)
conf.set("spark.executor.resource.gpu.discoveryScript", GPU_DISCOVERY_SCRIPT)
conf.set("spark.rapids.memory.pinnedPool.size", "4G")
conf.set("spark.sql.files.maxPartitionBytes", "512m")
conf.set("spark.executor.extraClassPath", SPARK_RAPIDS_JAR)
conf.set("spark.driver.extraClassPath", SPARK_RAPIDS_JAR)
conf.set("spark.executor.rapids.sql.concurrentGpuTasks", 1)
conf.set("spark.plugins", "com.nvidia.spark.SQLPlugin")
conf.set("spark.executor.resource.gpu.amount", "1")
conf.set("spark.files", GPU_DISCOVERY_SCRIPT)
conf.set("spark.jars", RAPIDS_JAR)
# Create spark session
spark = SparkSession.builder.config(conf=conf).getOrCreate()
sc = SparkContext.getOrCreate()
セットアップ出来たので、試しにGaussian Mixture Modelのサンプルコードを実行してみます。
from pyspark.ml.clustering import GaussianMixture
dataset = spark.read.format("libsvm") \
.load("data/mllib/sample_kmeans_data.txt")
gmm = GaussianMixture().setK(2).setSeed(538009335)
model = gmm.fit(dataset)
print("Gaussians shown as a DataFrame: ")
model.gaussiansDF.show(truncate=False)
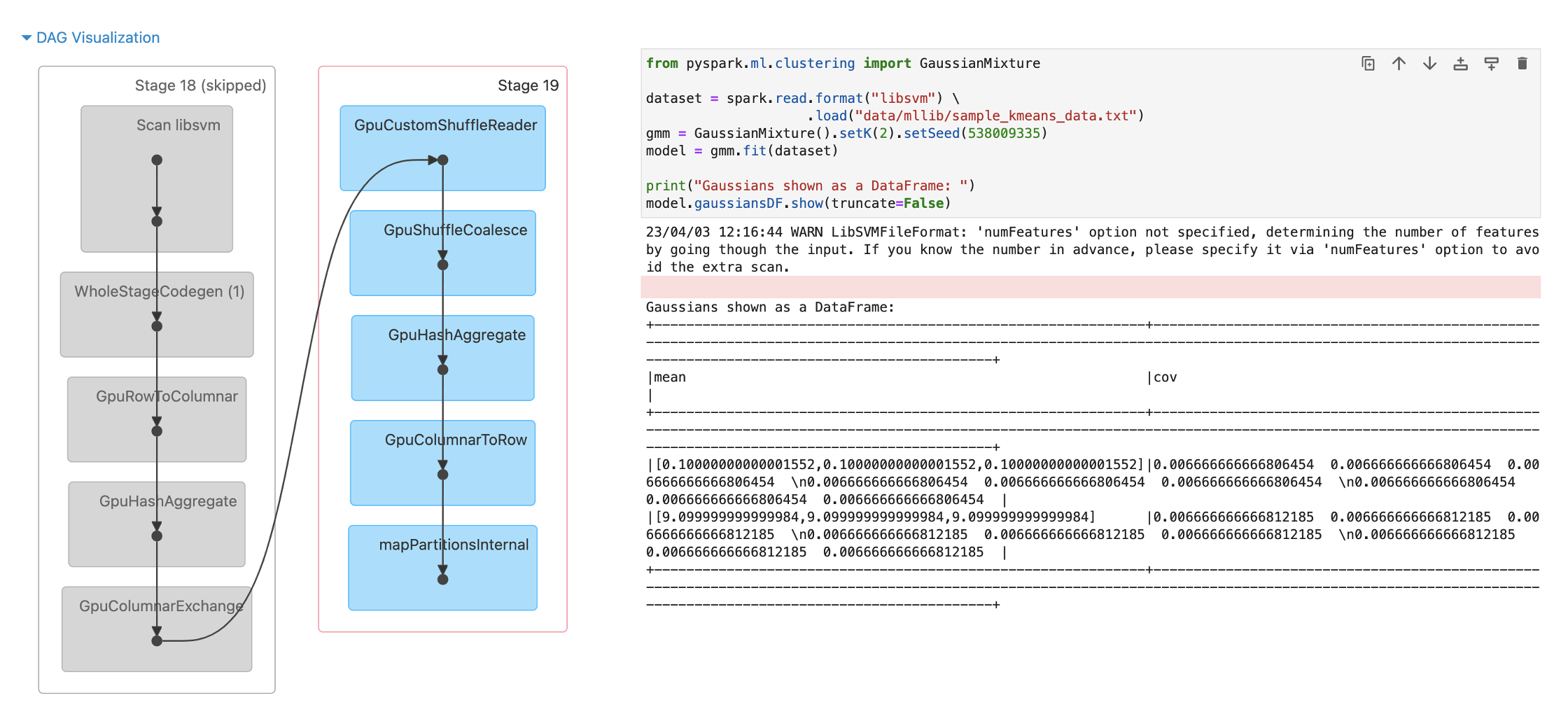
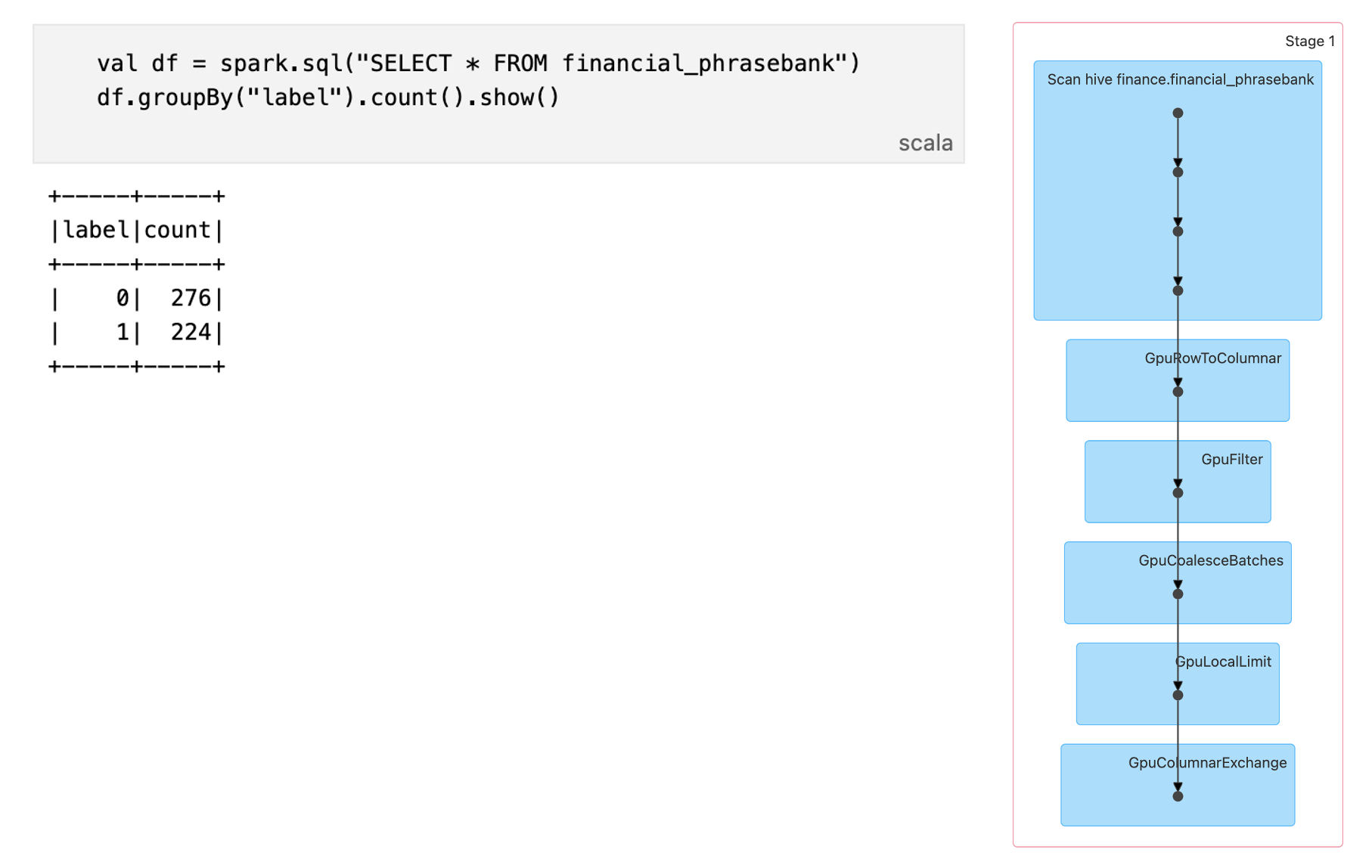
無事にGPUタスクとして実行できていることが確認できました。以降のNLPタスクで使用するデータセットをHiveテーブルとして作成します。
from datasets import load_dataset
spark.sql("CREATE TABLE IF NOT EXISTS financial_phrasebank (agreement STRING, label LONG, sentence STRING) USING hive")
for agreement in ['sentences_50agree', 'sentences_66agree', 'sentences_75agree', 'sentences_allagree']:
dataset = load_dataset("financial_phrasebank", agreement, data_dir='data')
dataset.set_format(type="pandas")
#Create PySpark DataFrame from Pandas
tmp_df = dataset['train'][:]
tmp_df['agreement'] = agreement
sparkDF = spark.createDataFrame(tmp_df)
sparkDF.createOrReplaceTempView('tmp_financial_phrasebank')
spark.sql("""
INSERT INTO financial_phrasebank
select
agreement,
label,
translate(translate(sentence, "\n", ""), "\r", "") as sentence
from
tmp_financial_phrasebank
""")
DAGを見ると、SparkSQLによるデータ抽出もGPU上で実行されています。
一旦、Spark RapidsをインストールしてGPU関連の環境を作っておけば、追加でSparkとGPUを使用するライブラリをセットアップすることは容易です。例として、XGBoostモデルをSpark GPU上で学習・推論する際のサンプルコードを紹介します。
4. XGBoost4j Spark GPU
JVM上でXGBoostを試したい場合はXGBoost4jがおすすめです。以下は、ScalaでXGBoost4j-Spark-GPUを使用するためのサンプルコードです。
Install
export MVN_XGB_GPU=ml.dmlc:xgboost4j-gpu_2.12:1.7.3
export MVN_XGB_SPARK_GPU=ml.dmlc:xgboost4j-spark-gpu_2.12:1.7.3
${SPARK_HOME}/bin/spark-shell \
--packages ${MVN_XGB_GPU},${MVN_XGB_SPARK_GPU}
Sample Model
import org.apache.spark.sql.types.{DoubleType, StringType, StructField, StructType}
import org.apache.spark.sql.expressions.Window
import org.apache.spark.sql.functions._
import ml.dmlc.xgboost4j.scala.spark.XGBoostClassifier
val labelName = "class"
val schema = new StructType(Array(
StructField("sepal length", DoubleType, true),
StructField("sepal width", DoubleType, true),
StructField("petal length", DoubleType, true),
StructField("petal width", DoubleType, true),
StructField(labelName, StringType, true)))
val xgbInput = spark.read
.option("header", "false")
.schema(schema)
.csv("data/iris.csv")
val spec = Window.orderBy(labelName)
val Array(train, test) = xgbInput
.withColumn("tmpClassName", dense_rank().over(spec) - 1)
.drop(labelName)
.withColumnRenamed("tmpClassName", labelName)
.randomSplit(Array(0.7, 0.3), seed = 1)
val xgbParam = Map(
"objective" -> "multi:softprob",
"num_class" -> 3,
"num_round" -> 100,
// "tree_method" -> "gpu_hist",
"num_workers" -> 1)
val featuresNames = schema.fieldNames.filter(name => name != labelName)
val xgbClassifier = new XGBoostClassifier(xgbParam)
.setFeaturesCol(featuresNames)
.setLabelCol(labelName)
val xgbClassificationModel = xgbClassifier.fit(train)
val results = xgbClassificationModel.transform(test)
results.show()
5. Spark NLP
SparkとGPUのセットアップが出来たので、Spark NLPでTransformerモデルを動かしてみましょう。Spark NLPはJohn Snow Labs社をコア開発チームとするオープンソースソフトウェアです。
Spark NLPの開発言語はScalaですが、Python向けのライブラリも公開されており、NLPモデルをパイプラインとして便利に利用できるnluというラッパーライブラリも開発されています。後で紹介する可視化ツールもあるので合わせて利用すると良いでしょう。様々なTransformerモデルがモデルハブに登録されており、ダウンロードして使うことができます。
Mavenレポジトリからダウンロードしてインストールします。Sparkから利用する際は以下のようにpackagesの引数で指定する方法が簡単です。
export MVN_SPARKNLP=com.johnsnowlabs.nlp:spark-nlp-gpu_2.12:4.0.2
export MVN_TENSORFLOW=com.johnsnowlabs.nlp:tensorflow-gpu_2.12:0.4.4
${SPARK_HOME}/bin/spark-submit \
--packages ${MVN_SPARKNLP},${MVN_TENSORFLOW}
6. ChatGPTとテストしてみる
実行環境をビルドできたのでテストしてみます。せっかくなのでChatGPTにテストコードを生成してもらいました。
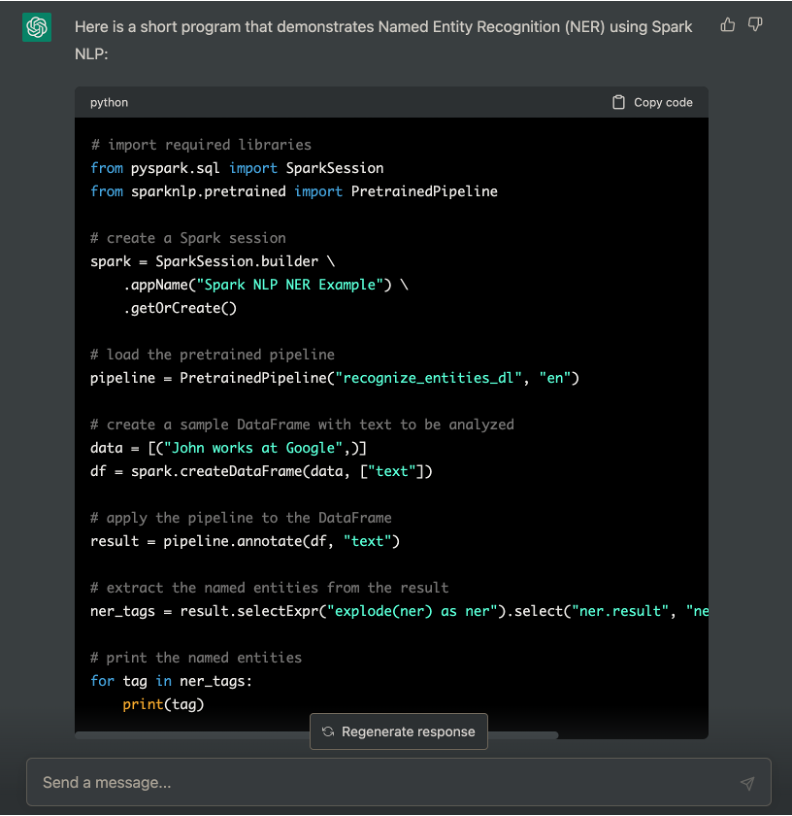
SparkSessionのところはGPU上で実行されるようconfigを追記するとして、その他の部分はきれいにコーディングしてくれています。言語を指定していませんでしたが、ChatGPTがよしなにPythonを選んでくれています。せっかくなので同等のScalaコードに変換してもらいました。
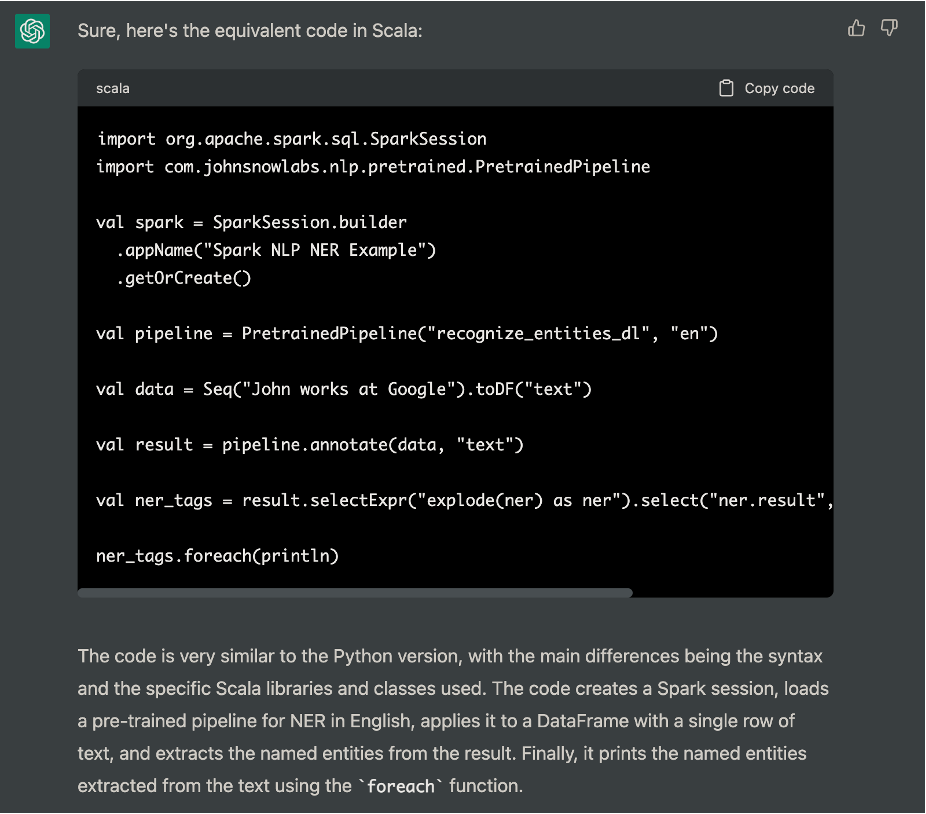
難なくPythonからScalaにリファクタしてくれました。上のコードを実行した結果、次の通り問題なくNERタスクのPretrained Pipelineを実行できました。

DAGを見ると、GPUも問題なく動作しています。

7. Fine-tuningについて
現在の4.x系のSpark NLPライブラリでは学習済みモデルをダウンロードしてNLPパイプラインを構築するという設計になっており、各モデルの事前学習をこのライブラリ内で行うことはできないようです。各モデルはTensorflowベースの学習済みモデルの重みを利用する形になっており、様々なタスクでトレーニングした時のチェックポイントがJohb Snow Labsのモデルハブに保存されています。このため、Transformerモデルの重みを微調整したり、一から事前学習したい場合はTensorflowやHorovodなどの別のフレームワークで学習して取り込む必要があります。以下は、Universal Sentence Encoderを微調整してSpark NLPモデルとしてロードする際のサンプルコードです。USEについて詳しく知りたい方は、こちらのお堅そうなタイトルのブログを合わせてお読みください。
import horovod
import horovod.tensorflow as hvd
def main():
import numpy as np
import tensorflow as tf
import tensorflow_hub as hub
from tensorflow.keras import utils
from datasets import load_dataset
from sklearn.model_selection import train_test_split
# Horovod: initialize Horovod.
hvd.init()
# Horovod: pin GPU to be used to process local rank (one GPU per process)
gpus = tf.config.experimental.list_physical_devices('GPU')
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
if gpus:
tf.config.experimental.set_visible_devices(gpus[hvd.local_rank()], 'GPU')
# Load Dataset
datasets = load_dataset("financial_phrasebank", 'sentences_50agree', data_dir='data')
datasets.set_format(type="pandas")
df = datasets['train'][:]
train_examples = df['sentence'].to_numpy()
train_labels = df['label'].to_numpy()
train_dataset = tf.data.Dataset.from_tensor_slices(
(tf.cast(train_examples, tf.string),
tf.cast(train_labels, tf.int64))) \
.repeat().shuffle(10000).batch(512)
# Build Model
hub_layer = hub.KerasLayer("https://tfhub.dev/google/universal-sentence-encoder/4",
input_shape=[], dtype=tf.string, trainable=False)
bin_model = tf.keras.Sequential()
bin_model.add(hub_layer)
bin_model.add(tf.keras.layers.Dense(64, activation='relu'))
bin_model.add(tf.keras.layers.Dense(3))
# Horovod: adjust learning rate based on number of GPUs.
loss = tf.losses.SparseCategoricalCrossentropy(from_logits=True)
optimizer = tf.optimizers.Adam(0.001 * hvd.size())
metrics = tf.metrics.CategoricalAccuracy(name='categorical_accuracy')
checkpoint = tf.train.Checkpoint(model=bin_model, optimizer=optimizer)
@tf.function
@tf.autograph.experimental.do_not_convert
def training_step(examples, labels, first_batch):
with tf.GradientTape() as tape:
probs = bin_model(examples, training=True)
loss_value = loss(labels, probs)
# Horovod: add Horovod Distributed GradientTape.
tape = hvd.DistributedGradientTape(tape)
grads = tape.gradient(loss_value, bin_model.trainable_variables)
optimizer.apply_gradients(zip(grads, bin_model.trainable_variables))
# Horovod: broadcast initial variable states from rank 0 to all other processes.
if first_batch:
hvd.broadcast_variables(bin_model.variables, root_rank=0)
hvd.broadcast_variables(optimizer.variables(), root_rank=0)
return loss_value
# Horovod: adjust number of steps based on number of GPUs.
for batch, (examples, labels) in enumerate(train_dataset.take(200 // hvd.size())):
loss_value = training_step(examples, labels, batch == 0)
if batch % 10 == 0 and hvd.rank() == 0:
print('Step #%d\tLoss: %.6f' % (batch, loss_value))
# Horovod: save checkpoints only on worker 0 to prevent other workers from corrupting it.
checkpoint_dir = './checkpoints'
if hvd.rank() == 0:
checkpoint.save(checkpoint_dir)
# run training through horovod.run
np = 3
hosts = 'master:1,worker-1:1,worker-2:1'
print('Running training through horovod.run & gloo')
horovod.run(main, np=np, hosts=hosts, use_gloo=True)
Horovodでトレーニングしたモデルは次のようにロードしてSpark NLPで使用します。
import com.johnsnowlabs.nlp.embeddings.UniversalSentenceEncoder
val embeddings = UniversalSentenceEncoder.loadSavedModel('./checkpoints', spark)
8. Sample Model
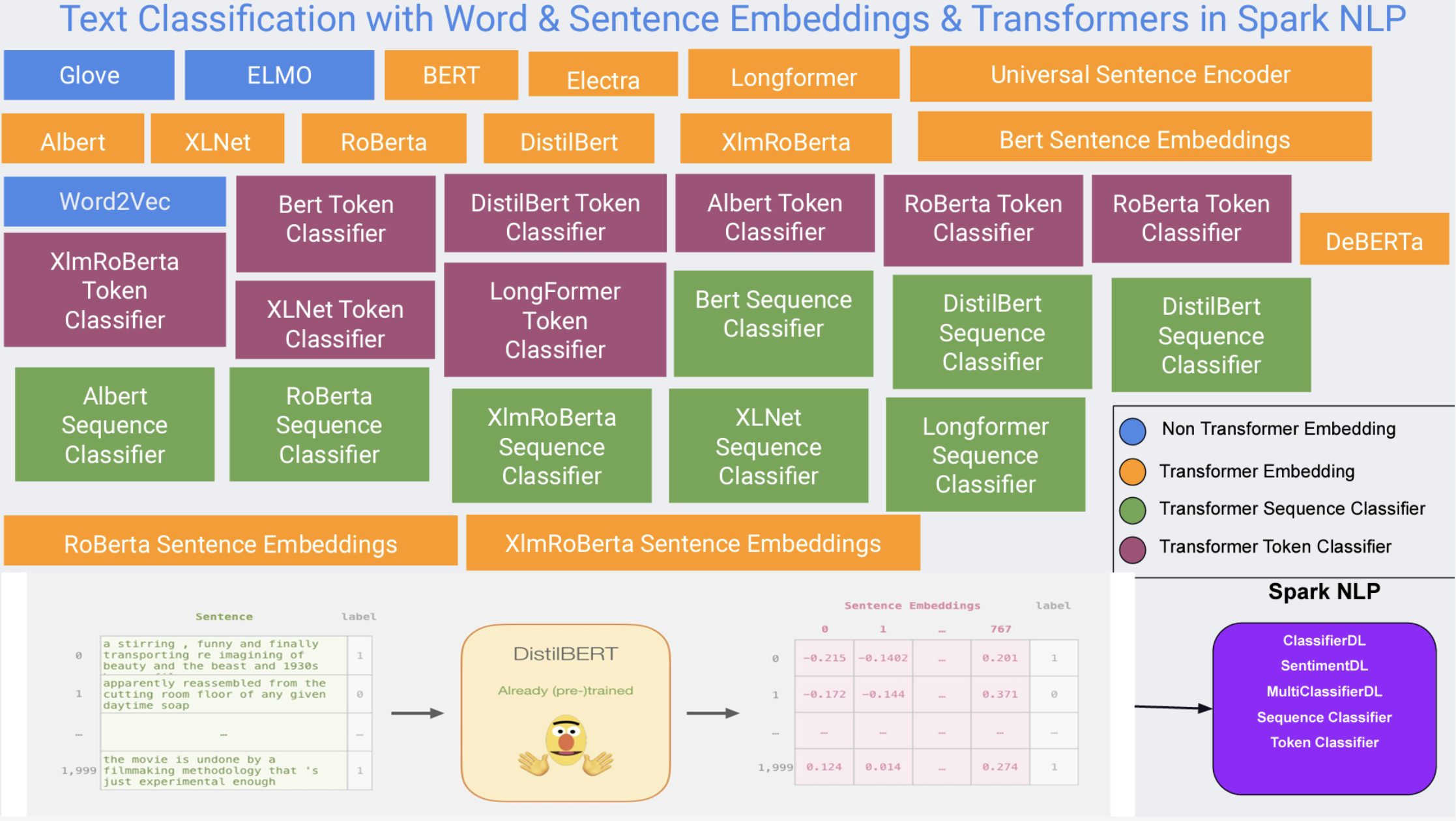
構築したクラスタコンピューティング環境でTransformerモデルの転移学習するモデルを作ります。データセットはFinancial Phrasebankという金融感情分析のためのデータセットを使用し、モデルはSmall BERTを使用しました。
import org.apache.spark.ml.Pipeline
import com.johnsnowlabs.nlp.base.DocumentAssembler
import com.johnsnowlabs.nlp.embeddings.BertSentenceEmbeddings
import com.johnsnowlabs.nlp.annotators.classifier.dl.ClassifierDLApproach
// BERT Sentence Embedding
val documentAssembler = new DocumentAssembler()
.setInputCol("sentence")
.setOutputCol("document")
val embeddings = BertSentenceEmbeddings.pretrained()
.setInputCols("document")
.setOutputCol("sentence_embeddings")
val docClassifier = new ClassifierDLApproach()
.setInputCols("sentence_embeddings")
.setLabelColumn("label")
.setOutputCol("preds")
.setBatchSize(4)
.setMaxEpochs(30)
.setLr(1e-3f)
.setDropout(0.5f)
val pipeline = new Pipeline().setStages(
Array(
documentAssembler,
embeddings,
docClassifier
))
val Array(train, test) = df.randomSplit(Array(0.5, 0.5))
train.cache()
test.cache()
val pipelineModel = pipeline.fit(train)
val result_df = pipelineModel.transform(test)
result_df.select($"label", $"preds.result"(0) as "preds")
.selectExpr("label", "preds", "label == preds")
.select($"(label = preds)" as "accuracy")
.groupBy("accuracy")
.count()
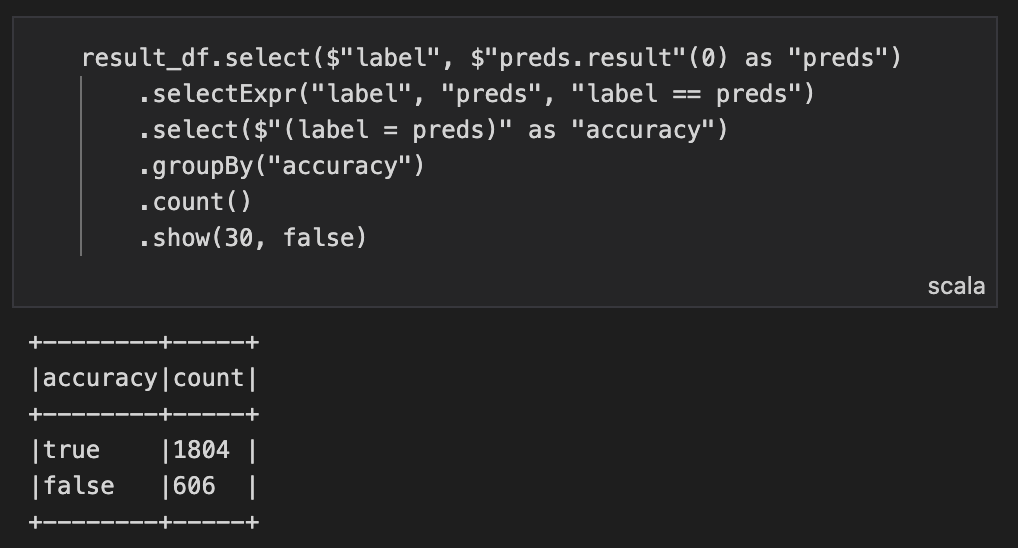
.show(30, false)
Testデータの精度はAccuracy 74.85%となりました。
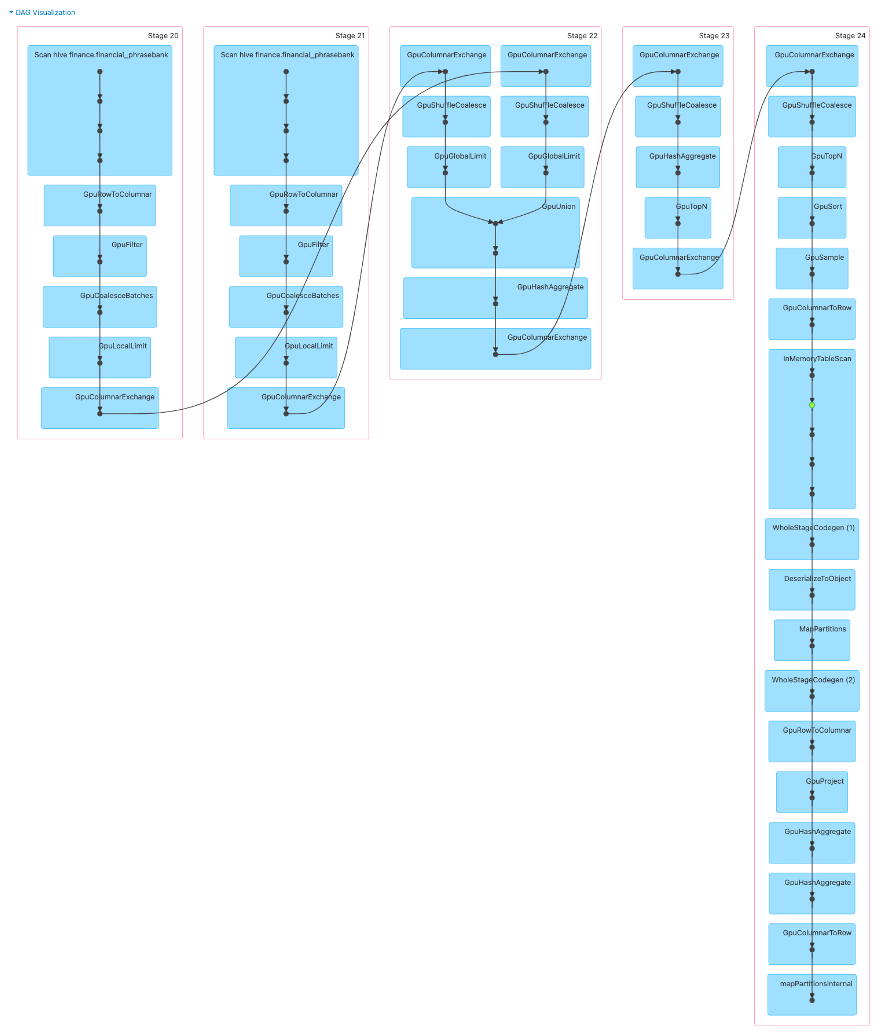
学習時のDAGは以下のようになっています。Spark MLのPipelineベースの実装となっているので各工程をつないだ分、グラフが縦に長く表示されます。
なお、HadoopをインストールしておくことでHDFSにダウンロードしたモデルのチェックポイントを保存することができます。
9. Spark-NLP-Displayによる可視化
spark-nlp-displayを使うことでいくつかのタスクの結果を視覚的にわかりやすく表示することができます。python向けの可視化ツールとなっており、インストールも簡単です。nluというSpark NLPのラッパーライブラリとあわせて使うと便利でしょう。
pip install -q nlu sparknlp-display
以下は構文解析とNERタスクの例です。
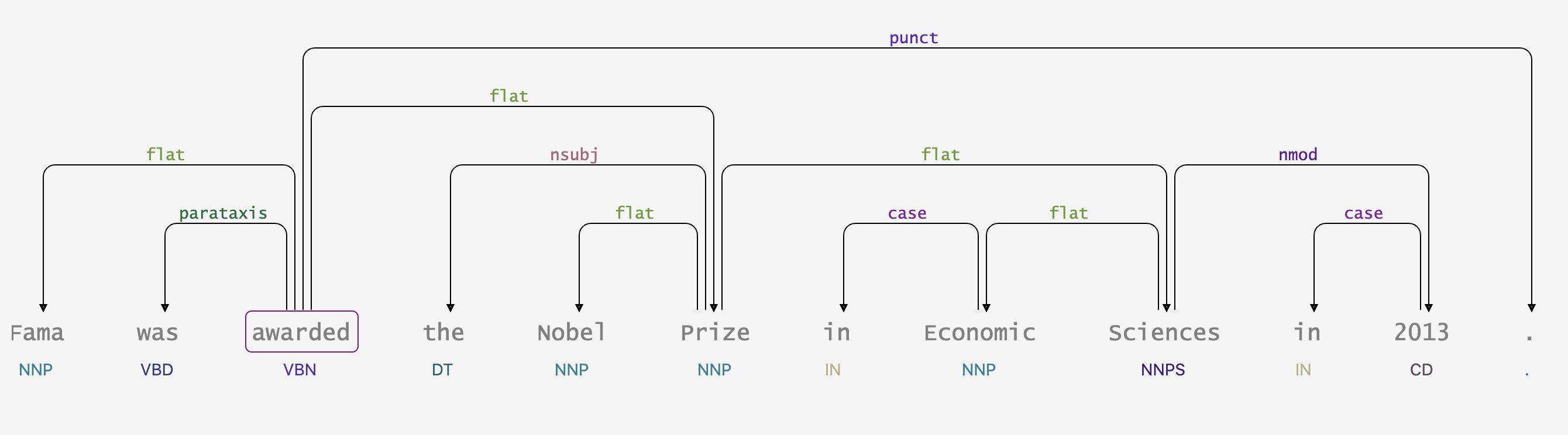
構文解析結果の可視化とコード
documentAssembler = DocumentAssembler()\
.setInputCol("text")\
.setOutputCol("document")
tokenizer = Tokenizer() \
.setInputCols(["document"]) \
.setOutputCol("token")
pos = PerceptronModel.pretrained("pos_anc", 'en')\
.setInputCols("document", "token")\
.setOutputCol("pos")
chunker = Chunker()\
.setInputCols(["document", "pos"])\
.setOutputCol("chunk")\
.setRegexParsers(["<NNP>+", "<DT>?<JJ>*<NN>"])
dep_parser = DependencyParserModel.pretrained('dependency_conllu')\
.setInputCols(["document", "pos", "token"])\
.setOutputCol("dependency")
typed_dep_parser = TypedDependencyParserModel.pretrained('dependency_typed_conllu')\
.setInputCols(["token", "pos", "dependency"])\
.setOutputCol("dependency_type")
nlpPipeline = Pipeline(
stages = [
documentAssembler,
tokenizer,
pos,
dep_parser,
typed_dep_parser
])
empty_df = spark.createDataFrame([['']]).toDF("text")
pipelineModel = nlpPipeline.fit(empty_df)
lmodel = LightPipeline(pipelineModel)
from sparknlp_display import DependencyParserVisualizer
text = ['Fama was awarded the Nobel Prize in Economic Sciences in 2013.']
res = lmodel.fullAnnotate(text)[0]
dependency_vis = DependencyParserVisualizer()
dependency_vis.display(res, 'pos', 'dependency', 'dependency_type', return_html=False)
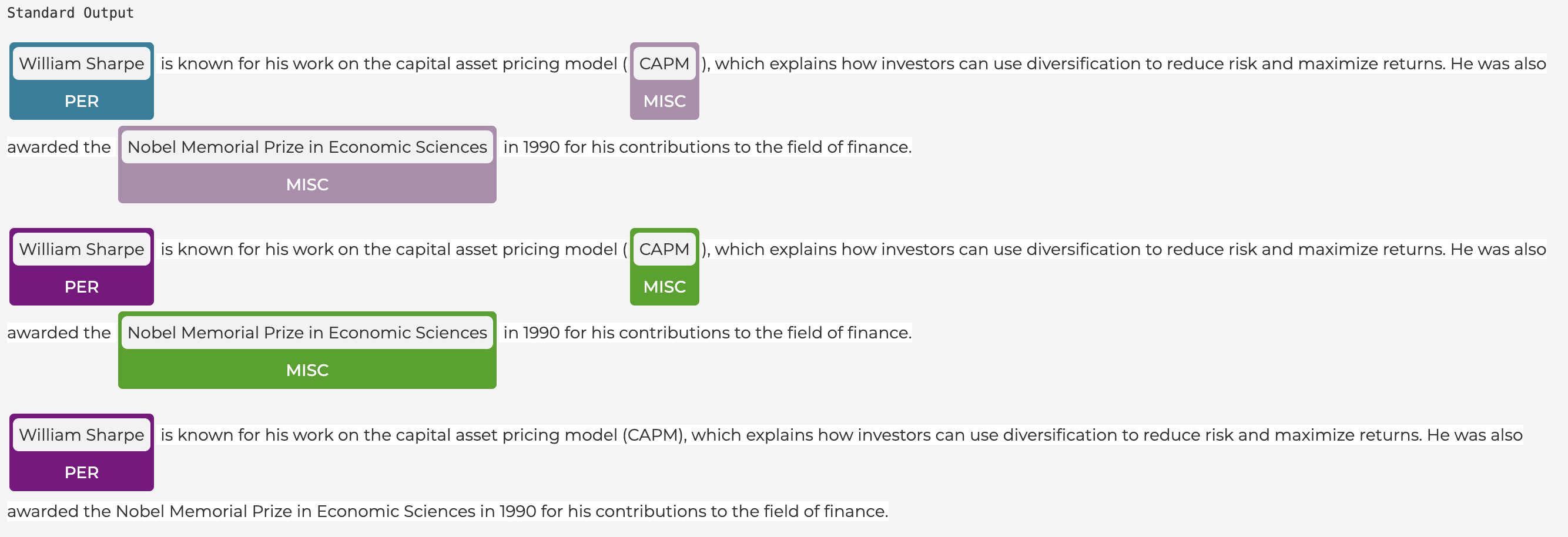
NERの結果の可視化とコード
documentAssembler = DocumentAssembler()\
.setInputCol("text")\
.setOutputCol("document")
tokenizer = Tokenizer() \
.setInputCols(["document"]) \
.setOutputCol("token")
bert_embeddings = BertEmbeddings.pretrained('bert_base_cased')\
.setInputCols(["document", "token"])\
.setOutputCol("embeddings")
onto_ner_bert = NerDLModel.pretrained("ner_dl_bert", 'en') \
.setInputCols(["document", "token", "embeddings"]) \
.setOutputCol("ner")
ner_converter = NerConverter() \
.setInputCols(["document", "token", "ner"]) \
.setOutputCol("entities")
nlpPipeline = Pipeline(stages=[
documentAssembler,
tokenizer,
bert_embeddings,
onto_ner_bert,
ner_converter])
empty_df = spark.createDataFrame([['']]).toDF("text")
pipelineModel = nlpPipeline.fit(empty_df)
lmodel = LightPipeline(pipelineModel)
example = ["William Sharpe is known for his work on the capital asset pricing model (CAPM), which explains how investors can use diversification to reduce risk and maximize returns. He was also awarded the Nobel Memorial Prize in Economic Sciences in 1990 for his contributions to the field of finance."]
cpres = lmodel.fullAnnotate(example)[0]
from sparknlp_display import NerVisualizer
visualiser = NerVisualizer()
print ('Standard Output')
visualiser.display(cpres, label_col='entities', document_col='document')
# Change color of an entity label
visualiser.set_label_colors({'LOC':'#008080', 'PER':'#800080'})
visualiser.display(cpres, label_col='entities')
# Set label filter
visualiser.display(cpres, label_col='entities', document_col='document',
labels=['PER'])
10. Synapse ML
セットアップしたSparkとGPU環境を活用して他の機械学習ライブラリも試してみたいと思います。Synapse MLはSpark上で機械学習を行うためのフレームワークです。Microsoft社によって開発され、公開されています。機能全体を使用するにはAPIサービスキーを構成する必要があるのですが、一部のモデルやデータ処理機能は他のOSSと同様に、インストールするだけで使用することができます。以下のようにLightGBMモデルをSparkで並列分散し、GPU上で高速に実行することができます。
import synapse.ml
from synapse.ml.core.platform import *
from synapse.ml.core.platform import materializing_display as display
from pyspark.ml.feature import StringIndexer
from pyspark import SparkConf, SparkContext
from pyspark.sql import SparkSession
from pyspark.ml import Pipeline
from synapse.ml.featurize.text import TextFeaturizer
from synapse.ml.lightgbm import LightGBMClassifier
from sklearn.metrics import classification_report
# Note: without common spark settings
conf = SparkConf()
conf.set("spark.jars.packages", "com.microsoft.azure:synapseml_2.12:0.11.0")
conf.set("spark.jars.repositories", "https://mmlspark.azureedge.net/maven")
# Create spark session
spark = SparkSession.builder.config(conf=conf) \
.enableHiveSupport() \
.getOrCreate()
sc = SparkContext.getOrCreate()
df = spark.sql("""
select
label as category,
sentence as description
from finance.financial_phrasebank
where agreement = 'sentences_50agree'
""")
indexer = StringIndexer(inputCol="category", outputCol="categoryIndex")
df_indexed = indexer.fit(df).transform(df)
train, test = (
df_indexed
.cache()
.randomSplit([0.5, 0.5])
)
model = Pipeline(
stages=[
TextFeaturizer(inputCol="description", outputCol="features"),
LightGBMClassifier(featuresCol="features", labelCol="categoryIndex"),
]
).fit(train)
pred = model.transform(test)
preds_df = pred.select('categoryIndex','description',"prediction").toPandas()
print(classification_report(preds_df['prediction'], preds_df['categoryIndex']))
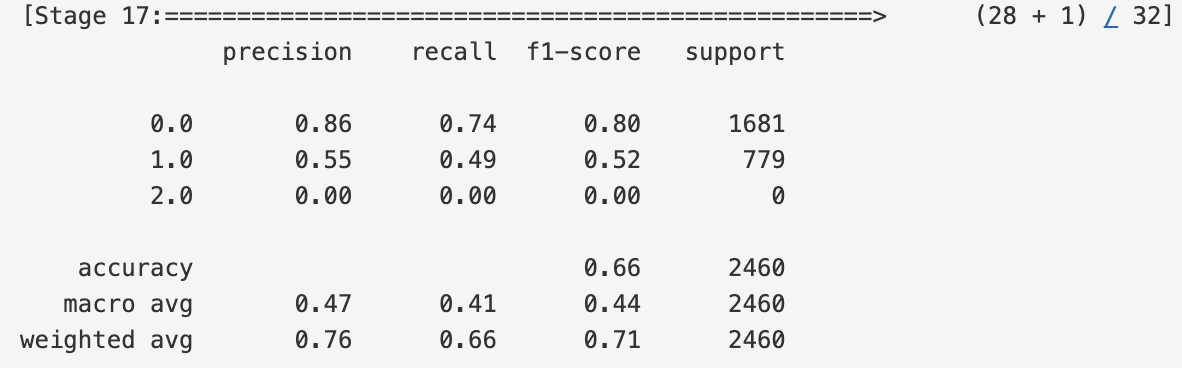
SynapseMLのLightGBMによるfinancial phrasebankの分類精度は以下のようになり、先ほどのBERTの転移学習の方が精度が高い結果となりました。
最後に
config周りが少し難しい印象がありますが、今回はSparkとGPUによりNLPタスクの計算規模をスケールする方法を確認しました。今後はより大規模なデータセットにも活用してみたいと思います。
グループ研究開発本部 AI研究開発室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務などAI研究開発室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD