2025.06.29
BigQueryストレージコスト:論理バイト課金 vs 物理バイト課金 vs 外部テーブル
皆様、こんにちは!AI研究のY.Tです。データ分析をやっていてBigQueryなど分析基盤のコストは常に頭を悩ませるテーマですよね。
特にBigQueryのような強力なDWHを使うと、その便利さゆえに気づけば費用が膨らんでいた、なんて経験がある方もいらっしゃるかもしれません。
今回は、BigQueryのストレージコストに焦点を当て、特に最近注目されている「物理バイト課金」と、以前からコスト削減策として知られる「GCS外部テーブル」について、具体的なシナリオに基づいて比較検討してみようと思います。
最近、ちょっと自分の関わっているところで「どっちがいいんだ、、、?」と悩ましい場面があって調べたことを備忘録も兼ねて記します。「どんな時に、どの選択肢が最適なのか」という実践的な視点で掘り下げていきますので、誰かの役に立てばと思います。
はじめに結論
長く細かい話が続くので、先に結論だけ書いておきます。
- TBスケールいかないならあまり変わらない。
- 物理バイト課金は圧縮率が5~10倍など高ければとりあえず入れてみても良いかも。詳細はコスト計算クエリを使って確認
- 更新があまり無く、読み出すだけなら外部テーブルも管理が難しくなく安い
- 上記の方法は当然、確認項目や管理コストが増えるので、あまり変わらないならデフォルトにしとくのが楽
前提
本記事では、解析用の時系列データの保存を想定して書きます。具体的には、次のような前提条件にします。
- 月間クエリ量: 約50TiBのスキャンを想定
- ストレージタイプ: 全てStandardクラス
- データ形式: Parquet + zstd圧縮の時系列データ
- クエリタイプ: 時系列フィルタや列指定が中心
- データ規模: 数TBオーダー(試算では論理10TB、物理/圧縮後2TBを想定)
ストレージタイプをStandardクラスとしているのは、解析のため読み出しでは高頻度でアクセスのある想定のためです。
アーカイブ系は保管は安いですが、読み出しなどの操作に追加コストがかかりますので、結局は頻繁に見ないログに使うぐらいですね。
追加コストの計算もだいぶ面倒です。
BigQuery コストモデルのおさらいと、見落としがちなポイント
BigQueryの料金は、大きく分けて「ストレージ料金」と「分析料金(クエリ実行料金)」の2つです。今回はこのうち、ストレージ料金に着目します、というのも、
分析料金は意外と同じでは?
はい。まずクエリ実行にかかる「分析料金」についてですが、今回の前提条件(オンデマンド、時系列フィルタ、列指定あり)では、実はBigQueryの論理バイト課金、物理バイト課金、GCS外部テーブルのどれを選んでも、スキャンされるデータ量(論理バイト換算)に基づく費用はほぼ変わらないと考えられます。当然、BiqQueryテーブルのクラスタやパーティションの切り方や、GCS上のファイルの分割には影響を受けます。BigQueryはParquetなどの列指向フォーマットを効率的に読み込み、必要な列やパーティション(またはHiveパーティショニングされたファイル)のみをスキャン対象とするためです。しかし、適切なデータの分割がされれば、どの方法でも同じクエリで大きくスキャン量が変わることはないでしょう。
月間100TBのクエリスキャンであれば、BigQueryの無料枠1TiBを超過する分が課金対象となり、約$306/月(1TBあたり約$6.25換算)と試算されます。外部テーブルの場合でも課金は同様のようです。
これはどのケースでも共通で発生する費用となります。
ストレージコストの比較
分析料金に大きな差がなければ、大きく差が出るのは「ストレージ(保管)コスト」ということです。それぞれの料金モデルを見ていきましょう。なお、コストの計算はregeonがusの想定でやります。東京リージョンでは若干高くなると思ってください。(例えば、BigQueryの通常ストレージコストが、$0.020 per month -> $0.023 per month)
ケース1: BigQueryオンデマンド(論理バイト課金)
従来のモデルで、データセットの「非圧縮時のサイズ」に基づいて課金されます。Standardクラスで常にアクティブなデータを保持する場合、1TiBあたり約$20/月。もし論理サイズ10TBのデータを保持し続けると、月額ストレージ費用は約$200(約2.9万円)となります。時系列データで新規データが常に追記される場合、長期保存割引(90日以上更新なしで半額)が適用される部分は限られる傾向があります。
ケース2: BigQueryオンデマンド(物理バイト課金)
新しく登場したこのモデルは、データの「圧縮後の物理サイズ」に基づいて課金されます。BigQueryはデータを自動的に効率よく圧縮してくれるため、物理サイズは論理サイズよりもかなり小さくなることが期待できます(例: 5〜10倍以上圧縮されるケースも)。単位料金は論理課金の2倍($0.04/GiB)ですが、**圧縮率が2倍を超えれば論理課金よりも安価になります**。
例えば、論理10TBのデータが物理2TBに圧縮された場合、月額ストレージ費用は約$80(約1.2万円)と、論理課金の半分以下に抑えられます。パフォーマンスはBigQueryネイティブの恩恵を受けられるため、かなり丸い選択肢です。
ケース3: GCS外部テーブル(Parquet+zstd圧縮)
データをBigQuery内部にはロードせず、Google Cloud Storage (GCS) 上に直接Parquet(zstd圧縮)形式で保存し、BigQueryからは外部テーブルとして参照する方式です。この場合、BigQueryのストレージ料金はゼロになります。
代わりにGCSのストレージ費用が発生します。
GCSのStandardクラスストレージは1TiBあたり約$20/月。Parquet+zstd圧縮は非常に高効率で、BigQuery内部ストレージと同等かそれ以上の圧縮率が期待できます。もし論理10TBのデータが圧縮後2TiBになったとすると、GCS保管料は月額約$40〜$50(約6千円〜7千円)に収まる試算です。最もストレージコストを抑えられるかもしれません。
で、結局どれがいいんですか?
上記の前提と各モデルの特性を踏まえ、月間100TBのクエリスキャンと論理10TB(圧縮後2TB)のデータ保持というシナリオでの概算コストを見てみましょう。
- ケース1 (論理バイト課金):
- クエリ費用: 約$306
- ストレージ費用: 約$200
- 合計: 約5062/月 (約7.3万円)
- ケース2 (物理バイト課金):
- クエリ費用: 約$306
- ストレージ費用: 約$80(圧縮率5倍を想定)
- 合計: 約$386/月 (約5.6万円)
- ケース3 (GCS外部テーブル):
- クエリ費用: 約$306
- ストレージ費用: 約$40(圧縮後2TiBを想定)
- 合計: 約$346/月 (約5万円)
まず一言。ドルが高い。(1USD = 144JPY)
思ったより差が出ないですが、ストレージコストが大きいようなら検討して良いのではないでしょうか?ドルが高いので日本円だと数万円ぐらい変わってくるようなケースもありそうです。
そのほかの検討事項
これが多い。単純計算のコストは、ここまで書いた通りです。しかし、考えないといけないことは他にも結構あります。
データの上書きや追記の考慮
単純な追記であればあまり問題ないです。しかし、上書きや削除が多いとなるとGCSに置く方針では管理が手間です。
物理課金であれば、上書きや削除の際の手間はあまり考慮しなくてよさそうですが、タイムトラベルには注意です。
タイムトラベルというのは自動バックアップのようなものです。削除や更新をテーブルにかけると作成され、一定の期間で破棄されます。削除や更新のクエリの頻度とタイムトラベルの有効期間によっては、タイムトラベルの容量の課金が大きくなるケースがあります。なお、論理課金ではタイムトラベルにかかるコストはゼロです。
クエリ性能
BigQuery内部テーブル(ケース1・2)だと、BigQueryの強力な分散列ストレージ上でフルパワーでクエリ実行が可能できるので、性能はさすがに強いです。データ型変換も取り込み時に行われ、クラスタリングやパーティション分割によるデータ配置最適化も活用できるため、大規模データにヤバめの結合を書いてもサクッと処理してくれたりします。
GCS外部テーブル(ケース3)の場合、クエリ実行時にGCSからファイルを読み込み、その場でParquetの解析(デコードや型変換)を行う必要があるため、**処理時間が長くなる傾向**があります。ネットワーク遅延やファイルI/Oオーバーヘッドも無視できません。複雑なクエリや大規模な結合では、ネイティブテーブルが有利です。
機能と運用
BigQuery内部テーブル(ケース1・2)の場合は完全マネージドなサービスとして、SQLでのデータ更新・削除(DML)、マテリアライズドビュー、BI Engineによる高速キャッシュなど、豊富な機能を利用できます。また、テーブルやパーティションにexpireを設定して自動削除することも可能です。
GCS外部テーブル(ケース3)は、基本的に読み取り専用であり、BigQuery上で直接データの更新やインデックス付与はできません。ネイティブなパーティション分割やクラスタリング機能は使えませんが、Hiveパーティショニング形式でファイルを配置することで代替可能です。また、ファイル数が極端に多い場合、メタデータ管理がボトルネックとなりクエリ性能が著しく低下する可能性があるため、適切なファイル構成の工夫が求められます。
まあ、適切なパーティションを切っておけば、クエリ性能の差は気にするほどでもないと思いますが、DMLとかBigQueryの機能面では困る時があるかもしれないです。
データ圧縮効率
物理バイト課金モデルとGCS外部テーブルは、いずれもデータ圧縮の恩恵を最大限に受けられます。BigQuery内部の列指向圧縮もParquet+zstdも、非常に高い圧縮率を誇り、非圧縮サイズから大幅な縮小が期待できます。当然ながら、圧縮率が高いほど、これら2つのストレージ費用優位性が増します。ここらで、実際どのくらいの圧縮がかかるか見てみることにします。
検証用なのでデータのサイズが小さいのは許してください。
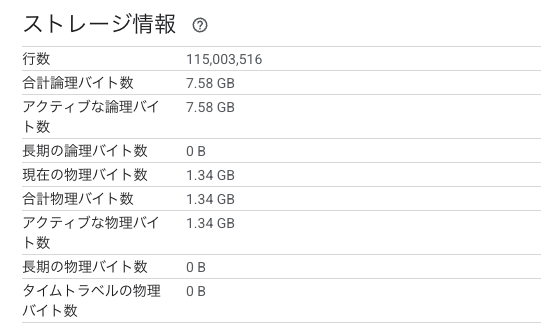
GCSに置いたものはこのくらい
%%configure -f
{
gcloud storage du -s -r gs://research/download/data/daily/
2.24GiB gs://research/download/data/daily/
}
大体同じ、ですかね?? BigQueryの圧縮つっよ
物理バイト課金プランへの切り替え
タイムトラベルについても確認したし、なんかBigQueryの圧縮も強そうだし、物理バイトに切り替えてみましょうか。
CLIでもクエリでも変えられるのですが、GUIでも変えられます。データセットの詳細を開いて、詳細を編集、料金プランを選択、です。
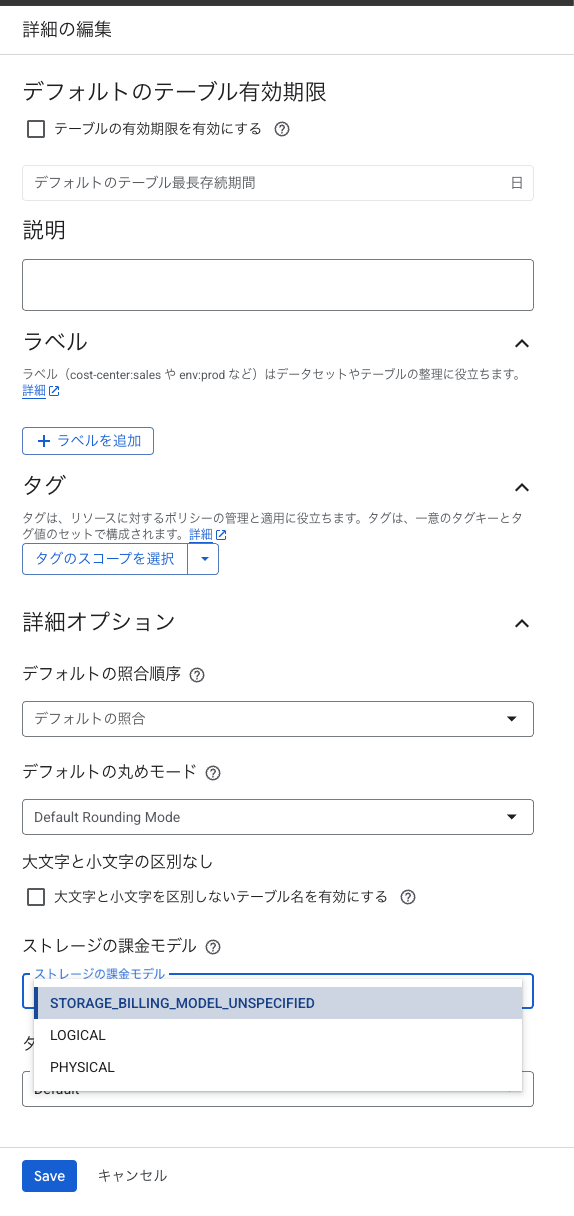
ちなみに、変更すると、再度課金モデルを変更するにに14日間かかります。変更の反映には24時間かかります。
テーブル単位では変えられず、データセット単位で変更なので、よく考えて変えましょう。
で、結局どれがいいんですか?(2回目)
ケースによるとしか言えないんですけど、、、
データセットごと切り替えてよくて、物理プラント論理プランで迷っているのなら下記のクエリを試してみましょう。
%%configure -f
{
DECLARE active_logical_gib_price FLOAT64 DEFAULT 0.02;
DECLARE long_term_logical_gib_price FLOAT64 DEFAULT 0.01;
DECLARE active_physical_gib_price FLOAT64 DEFAULT 0.04;
DECLARE long_term_physical_gib_price FLOAT64 DEFAULT 0.02;
WITH
storage_sizes AS (
SELECT
table_schema AS dataset_name,
-- Logical
SUM(IF(deleted=false, active_logical_bytes, 0)) / power(1024, 3) AS active_logical_gib,
SUM(IF(deleted=false, long_term_logical_bytes, 0)) / power(1024, 3) AS long_term_logical_gib,
-- Physical
SUM(active_physical_bytes) / power(1024, 3) AS active_physical_gib,
SUM(active_physical_bytes - time_travel_physical_bytes) / power(1024, 3) AS active_no_tt_physical_gib,
SUM(long_term_physical_bytes) / power(1024, 3) AS long_term_physical_gib,
-- Restorable previously deleted physical
SUM(time_travel_physical_bytes) / power(1024, 3) AS time_travel_physical_gib,
SUM(fail_safe_physical_bytes) / power(1024, 3) AS fail_safe_physical_gib,
FROM
`region-REGION`.INFORMATION_SCHEMA.TABLE_STORAGE_BY_PROJECT
WHERE total_physical_bytes + fail_safe_physical_bytes > 0
-- Base the forecast on base tables only for highest precision results
AND table_type = 'BASE TABLE'
GROUP BY 1
)
SELECT
dataset_name,
-- Logical
ROUND(active_logical_gib, 2) AS active_logical_gib,
ROUND(long_term_logical_gib, 2) AS long_term_logical_gib,
-- Physical
ROUND(active_physical_gib, 2) AS active_physical_gib,
ROUND(long_term_physical_gib, 2) AS long_term_physical_gib,
ROUND(time_travel_physical_gib, 2) AS time_travel_physical_gib,
ROUND(fail_safe_physical_gib, 2) AS fail_safe_physical_gib,
-- Compression ratio
ROUND(SAFE_DIVIDE(active_logical_gib, active_no_tt_physical_gib), 2) AS active_compression_ratio,
ROUND(SAFE_DIVIDE(long_term_logical_gib, long_term_physical_gib), 2) AS long_term_compression_ratio,
-- Forecast costs logical
ROUND(active_logical_gib * active_logical_gib_price, 2) AS forecast_active_logical_cost,
ROUND(long_term_logical_gib * long_term_logical_gib_price, 2) AS forecast_long_term_logical_cost,
-- Forecast costs physical
ROUND((active_no_tt_physical_gib + time_travel_physical_gib + fail_safe_physical_gib) * active_physical_gib_price, 2) AS forecast_active_physical_cost,
ROUND(long_term_physical_gib * long_term_physical_gib_price, 2) AS forecast_long_term_physical_cost,
-- Forecast costs total
ROUND(((active_logical_gib * active_logical_gib_price) + (long_term_logical_gib * long_term_logical_gib_price)) -
(((active_no_tt_physical_gib + time_travel_physical_gib + fail_safe_physical_gib) * active_physical_gib_price) + (long_term_physical_gib * long_term_physical_gib_price)), 2) AS forecast_total_cost_difference
FROM
storage_sizes
ORDER BY
(forecast_active_logical_cost + forecast_active_physical_cost) DESC;
}
課金プランの切り替えは特に他に影響ないので、安そうならとりあえず切り替えてみてコストを観察するのはよい手です。
実は巨大なのは一部のテーブルだけ、というケースでは、一部のテーブルだけはGCSに置いて、他は全部デフォルトというのもよくある方法です。管理やクエリ性能がーーーと色々書きましたが、置いておく分には大きな手間ではなく、課金はGCSのストレージコストぐらいでシンプルなので悪くないですよ。自分のところでも結局このやり方にしました。
TB級のデータを置いてあるなら、皆さんも一度見直しをされてはいかがでしょうか?
参考
GCS外部テーブルについて
TABLE_STORAGEビュー
BigQueryの料金
タイムトラベルとフェイルセーフによるデータの保持
BigQuery のストレージ料金を 1/10 に抑える裏技 外部テーブルのストレージプラン別の喧騒が詳しく参考にしました。
BigQuery解説 ~上手にコスト削減しながらBigQueryを活用する~ クエリのコストについてはこちらの記事が参考になりました。
宣伝
グループ研究開発本部 AI研究開発室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務などAI研究開発室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD