2025.04.07
RPAは時代遅れ?AIエージェントがLLMでPCを自動操作する時代
D.M.です。LLM で PC を自動操作する手法が提案されはじめています。これは従来のRPAを駆逐する可能性があります。その代表例を整理し、その中身の仕組みを解説していきます。
結論ファースト
・各社AIエージェントはRPAとして動作するポテンシャルが充分にある。
・性能面、セキュリティ面の課題は多数あり。
・将来性は極大。
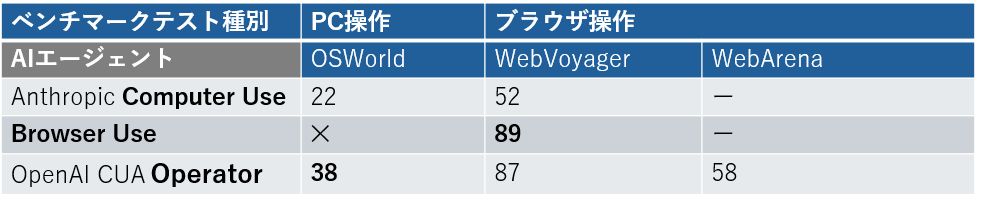
ベンチマークテスト比較表
アジェンダ
LLM以前のRPA
RPAとは
既存のRPAはどのようにAIを活用していたか
LLM以降のRPA
Computer Use
Browser Use
Operator
LLM以前のRPA
(この導入パートは、既存のRPA関連技術に関する振り返りです)
RPAとは
RPAとは、Robotic Process Automation ロボティックプロセスオートメーションのことで、ここでは特に人間に代わってプログラムが自動的なPC操作を行うことを意味します。
具体的には、「ブラウザ」や「Excel」の自動操作ができればRPAと言えると思います。
用途として、ウェブサイトなどから公式のAPIの公開されていないときにこのRPAが選択肢になるというのがあります。
実現方法としては以下があります。
・専用ツール
ノーコード、ローコードで提供されている専用のソフトウェアがあります。MS の Power Automate, UI Path などが弊社内の利用実績もあります。これらは非エンジニアの方でも開発可能というメリットがあり、一般的にも普及しました。
・プログラミング
システム開発者の立場からするとプログラミングでの自動化はよく知られた手法と思います。例えばブラウザは Python の playwright で操作できます。Excel は Office Scripts(≒ TypeScript )や VBA, PowerShell からコマンドラインにより自動操作が可能です。
このアプローチのメリットは、GUI を極力経由しないため精度が圧倒的に安定する点です。ある程度精度が求められるケースでは可能な限りプログラミングの選択肢を取った方がいいと考えられています。
既存のRPAはどのようにAIを活用していたか
従来 RPA の中で AI を呼ぶことで連携していました。
これは AI OCR や AI 翻訳、感情分析などのように AI の API を処理中に実行しているようなケースがあります。( LLM 以前の AI API )
例えば、請求情報の登録自動化をRPAで実装するケースを考えてみます。
以下の3つのプロセスを取ります。
1. Outlook で請求書の PDF のメールを受信してファイル保存をする
2. そのファイルを Google の OCR の AI に飛ばしてその内容を読み取る
3. 読み取った結果を Chrome で管理画面を開き申請を行う
このような流れで自動化の補助としてAIを活用していました、というのがLLM登場以前のRPAでした。
LLM 以降の RPA – 変わる世界
(ここからが今日の本題であるAIエージェントです)
LLMが出てきてから、突然世界が変わりました。
従来のRPA専用ツールやスクリプトを記述するアプローチから、「プロンプト」を投げたら自動的に全部動いてくれる世界が現れました。
代表的なAIエージェントとして以下3つのプロダクトがあります。
・Computer Use
・Browser Use
・Operator
Computer Use
Anthropic の Computer Use が2024年10月に発表したAIエージェントです。
最も初期に発表されたAIによるPC自動操作になると思います。
ベータ版です。(2025年4月段階)
Computer Use にできること
AIの主にClaudeのAPIがPCでGUI操作しているので、人間がプロンプトを書いてあげると、その通りに動いてくれます。
ブラウザからデータを読み取ってExcelに記載するといったような、まさにRPA的なことができています。
公式ページにベンチマークのテストの結果が記載されています。
OS World PC操作 22%
Web Voyager Webブラウザ操作 52%
(この点数はちょっとこの後も出てきます)
Computer Useを使ってみた
インストール
インストールは公式ページを参照するとすぐにわかります。
詳細は以下の GitHub を読んでみてください。
https://github.com/anthropics/anthropic-quickstarts/tree/main/computer-use-demo
Pythonの実装は不要です。
あとは以下のようにプロンプトを投げてみましょう。
(私の環境では英語のみで動作しました。理由は後述)
[課題]
1.Google検索をさせて1週間のドル円相場のデータを取ってみます。
プロンプト
「Google 検索で “ドル円” の1週間の値動きを読み取ってください。」
Plsease search “US Dollar/Japanese Yen” on Google. Observe the price movements over the week.
2.上の1で取得した「1週間のドル円相場」の内容をOfficeでグラフに書いてもらいます。(10分かかります)
プロンプト
「結果を Libra で表とグラフにしてほしいです。」
I would like the results to be displayed in a table and graph in Libre.
Computer Use はどうやって動いているのか
このAIエージェントはGitHub上のOSSなので意外と簡単に中身を把握することができます。
https://github.com/anthropics/anthropic-quickstarts/tree/main/computer-use-demo
Q. このチャットUIは何で作られているの?
A. python の Streamlit サーバをDockerコンテナのUbuntuデスクトップ環境内で立ち上げてチャットの画面をブラウザで使えるようにしています。
Ubuntu には Firefox と LibreOffice が入っています。
Q. AIのモデルは何を使っているの?
A. 内部では API で Claude 3.7 Sonnet (または 3.5 Sonnet)を実行しています。
大変ありがたいことに、 Anthropic API, AWS Bedrock, Google Cloud Vertex AI に対応しています。
API を利用するためのキーは、自分で発行したものを環境変数として Docker に与えています。
Q. どうやって画面の状態を把握してるの?
A. Ubuntu のデスクトップ GUI 環境に対してスクリーンショットを取得し、LLMがマルチモーダルとして読んでいます。
1操作ごとに1つのScreenshotを実行して状態を判定しているようです。
Q. どうやって画面を操作しているの?
A. マウスを xdotool で操作しています。
LLM マルチモーダルでスクリーンショットを読み、座標情報を生成。
そのあと Function Calling でコマンドラインとして xdotool でマウスの移動とクリックを実行しています。
Computer Use が抱える現状の課題
動画を見ると、これもう動いてるじゃん、合格レベルじゃん、ということになると思います。(私はそう思いました)
実際には明確な課題があります。
ベータ版には警告の文章が書いてあって、Claude はユーザーの指示と矛盾する場合でもコンテンツ内のコマンドに従いますっていうちょっと恐ろしい文章書いてあります。
In some circumstances, Claude will follow commands found in content even if it conflicts with the user’s instructions. For example, Claude instructions on webpages or contained in images may override instructions or cause Claude to make mistakes. We suggest taking precautions to isolate Claude from sensitive data and actions to avoid risks related to prompt injection.
https://docs.anthropic.com/en/docs/build-with-claude/computer-use
日本語訳
—
状況によっては、ユーザーの指示と矛盾する場合でも、クロードはコンテンツ内にあるコマンドに従います。たとえば、Web ページ上のクロードの指示や画像に含まれるクロードの指示が指示を上書きしたり、クロードが間違いを犯したりする可能性があります。クロードを機密データから隔離するための予防措置を講じ、即時注入に関連するリスクを回避するための措置を講じることをお勧めします。
—
つまり
・画面からプロンプトインジェクションがありえる
・そのリスクを回避するために機密データから隔離した環境で実行することが必要
いうのが公式には書いてあります。
実際Anthropic側で開発中に起きた誤動作の例が2つありました。
・Claude自身がデモの録画を勝手に止めてしまう。
・途中で全然関係ないイエローストーン国立公園の写真をGoogle検索してそこで固まって終わる。
※この気持ち悪い挙動が Twitter X 上に動画で残っています。
https://x.com/AnthropicAI/status/1848742761278611504
Computer Use の安全な実行方法
公式のGithubに出ている方法が、Docker上に隔離された環境を構築するというものです。そのため Ubuntu 環境にデスクトップGUIをつけて起動させてメインのOSとは別の環境でAIを動作させているというわけです。
Computer Use のまとめ
・RPAとしての評価は悪くない(ベンチマークテストとしてはまだまだだけど)
・ただちょっとセキュリティ課題が明示的にある
※Computer Use は日本語での入力を指示すると大失敗します。
例えばこの動画では、日本語プロンプト「Google 検索で “ドル円” の1週間の値動きを読み取り、結果をLibreで表とグラフにしてほしいです。」で指示したあと、Google検索ボックスへ日本語入力がなぜかうまくいきません。
失敗原因ですが、上述の通りこの操作部分は LLM が xdotool コマンドを使って行っており、AIが日本語に対応していないというわけではなく、単に Ubuntu と xdotool で日本語を扱うのがうまくいってないように感じます。操作的には単純にみえるので、ちょっと改修したら日本語も問題ないのではと思っています。
Browser Use
2024年10月に出てきた OSS のライブラリです。(Anthropic の Computer Use と同月)
当初はMagnasさんとGregorさんが友達同士で開発をはじめたようです。
動作には自分でPythonを書いてライブラリを読み込む必要があります。
現状はクラウドでのSaaS提供もはじまっています。
OSS なので GitHub で読むことができます。
https://github.com/browser-use/browser-use
内部的には LangChain を使ったシンプルな Python コードのため、理解できるレベルのものです。
AI は OpenAI API GPT-4o を使っていますが、内部が LangChainであるので Gemini も Claude も組み込むことができる仕組みになっています。
Browser Use にできること
・プロンプトから「ブラウザ操作」ができる。(上述の Computer use と同じ)
・一方、「PC全体の操作」は対応していない。
ベンチマーク
WebVoyager のテストでは、他のツールを差し置いて圧倒的ナンバーワンの結果を出しています。
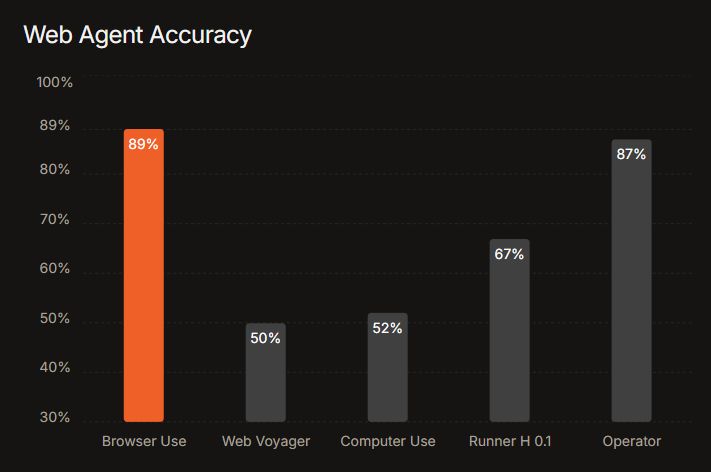
https://browser-use.com/posts/sota-technical-report
専用にトレーニングされたモデルではなく、この OSS の AI エージェント (+ 汎用的な LLM である GPT-4o )が唯一89点 SOTA を取っているという点が興味深いですね。
Browser Use を使ってみた
[課題]
私はこれを Redmine のデモサイトで1回試してみました。
https://my.redmine.jp/demo/
(※ Redmine はプロジェクト管理ツールで、チケット単位でタスクやバグを登録し管理できるOSSツールです)
実際に、この画面にアクセスしてIDパスワードでログインして、プロジェクトをクリックしてバグを登録するというのをプロンプトで書いてみたわけですね。
なぜこのサイトを課題にしたのかというと、既存で動いている RPA として Python の Playwright が同様の処理を社内ツールの自動操作を行っています。これを Browser Use で日本語プロンプトで書いても同じような動作ができますよっていうのが今回のポイントです。
Browser Use はどうやって動作しているのか
Browser Use は視覚的な情報を活用し、要素の配置やデザインも認識してから実際の HTML 操作をしています。
(従来のRPAやスクレイピングは、サイトのHTMLのコードのみから情報を得ていました)
Browser Use の特徴として、動作開始してブラウザが立ち上がってきてから、なんか枠が出るんですよ、こういう色づけされた枠が。
スクリーンショットでどういうところがクリッカブルなのかを AI がマルチモーダル認識している状態を可視化してくれるんですね。
これに加えて、 Javascript を実行し HTML DOM ツリーを把握しています。 JS で把握した HTML 構造に基づいて Python Playwright が動いているようです。
例)ログインボタンを押す動作
1.プロンプト「ログインボタンをクリックしてください」とAIエージェントに指示。
2.AIエージェントはスクリーンショットを分析し、「ログイン」というテキストを持つボタンを視覚的に識別します。
3.同時に、 Javascript buildDomTree.js で HTML DOM ツリーを取得。その情報から「ログイン」テキストを含むボタン要素を探し、そのインデックス番号(例:要素番号5)を特定します。
4.AIエージェントは servive.py の click_element_by_selector などの関数を呼び出し、インデックス5の要素をクリック。
こちら1回ごとに画面全部を画像として認識し直すんですよ。1項目入力するごとに毎回スクリーンショットをマルチモータルで認識した上で操作しているので、動作はのろのろしています。ただ結構精度高く動いてくれます。
実装したコードです。
from browser_use import Agent
from langchain_openai import ChatOpenAI
import asyncio
#from playwright.sync_api import Playwright, sync_playwright, Browser, BrowserConfig
from browser_use.browser.browser import Browser, BrowserConfig
from dotenv import load_dotenv
load_dotenv(verbose=True)
dotenv_path = '.env'
load_dotenv(dotenv_path)
llm = ChatOpenAI(model='gpt-4o')
task='search_google をしない。\
以下のURLへ直接移動。\
https://my.redmine.jp/demo/\
ログインへ移動。\
id=developer, password=developer を入力\
ヘッダーのプロジェクトに移動。\
デモ用プロジェクトに移動。\
概要をクリック。\
新しいチケットに移動。\
トラッカー=機能 を選択。\
以下を入力。\
題名=バグ2025-04\
説明=AIの登録したバグです。\\r\\n\
改行バグ。\
担当者=自分に割り当てをクリック\
以下を入力。\
開始日=04/01/2025\
作成クリック\
'
agent = Agent(
task=task,
llm=llm,
# browser=br,
)
async def main():
await agent.run()
asyncio.run(main())
Pythonのコードは20行くらい。プロンプトも20行ぐらい。5回ぐらい一応実行しました。
そのAPIの金銭コストが100円でした。
GBT-4oで40リクエストくらいで26万トークンぐらいを流していました。
マルチモーダルを連発するとそこそこのトークンを使うなという印象です。
Browser Use 内部のイニシャルのプロンプト
You are a planning agent that helps break down tasks into smaller steps and reason about the current state.
Your role is to:
1. Analyze the current state and history
2. Evaluate progress towards the ultimate goal
3. Identify potential challenges or roadblocks
4. Suggest the next high-level steps to takeInside your messages, there will be AI messages from different agents with different formats.
Your output format should be always a JSON object with the following fields:
{
“state_analysis”: “Brief analysis of the current state and what has been done so far”,
“progress_evaluation”: “Evaluation of progress towards the ultimate goal (as percentage and description)”,
“challenges”: “List any potential challenges or roadblocks”,
“next_steps”: “List 2-3 concrete next steps to take”,
“reasoning”: “Explain your reasoning for the suggested next steps”
}Ignore the other AI messages output structures.
Keep your responses concise and focused on actionable insights.
日本語訳
—
あなたは、タスクを小さなステップに分割し、現在の状態について推論するのを支援する計画エージェントです。
あなたの役割は次のとおりです。
1. 現状と履歴を分析する
2. 最終目標に向けた進捗状況を評価する
3. 潜在的な課題や障害を特定する
4. 次に取るべき大まかなステップを提案する
メッセージ内には、さまざまなエージェントからのさまざまな形式の AI メッセージが含まれます。
出力形式は常に、次のフィールドを含む JSON オブジェクトである必要があります。
{
“state_analysis”: “現在の状態とこれまでに行われたことの簡単な分析”,
“progress_evaluation”: “最終目標に向けた進捗状況の評価 (パーセンテージと説明)”,
“challenges”: “潜在的な課題や障害を列挙します”,
“next_steps”: “次に取るべき具体的なステップを 2 ~ 3 つリストします”,
“reasoning”: “提案された次のステップの理由を説明してください”
}
他の AI メッセージ出力構造は無視します。
回答は簡潔にし、実用的な洞察に焦点を当ててください。
—
出力形式をJSONに指定というのが次の処理につなげるためのポイントになると思います。
スクリーンショットのマルチモーダル + DOMツリー の認識をした後に Function Calling で関数を読んで、最後は Python Playwight で実際の操作をしているわけですね。
OSSで読めるで、似たAIエージェントを開発したいと思っている方はぜひ自分で読んだり、LLMに読ませて説明してもらってみてください。
Browser use のセキュリティ課題
Computer Use で警告されていたプロンプトインジェクション等のセキュリティ課題は、Brower Use 公式のページには書いてありませんでした。
ただ結局まだ発展途上のため Computer Use と同じ問題のリスクは絶対あると考えています。
Computer Use は OS 全体を操作できてしまうため完全な隔離環境を構築していました。一方 Browser Use はブラウザ操作のみのため、そこまでの危険性はないとは思えるものの、最悪データが抜き取られるリスクがあるという認識を持って実行環境を限定する必要があると思います。
心配事項がありますが、以下のような対策もしっかり用意されています。
・Sensitive Data
パスワード等の機密情報は、 LLM へ送らなくてもいい仕組みが整っています。
https://docs.browser-use.com/customize/sensitive-data
・Custom Functions
処理が難しい箇所や機密情報を含む箇所は、 LLM に頼らず自分で Python で実装して組み込むという手段も取れます。
https://docs.browser-use.com/customize/custom-functions
まだまだ注意しながら使わないといけないフェーズと思います。
Brower Use まとめ
・ベンチマークは SOTA のため、ブラウザ操作は実は他のツールよりも高い精度があります。
(ただまだ80何点なので人間に比べるとどうかという課題は残る)
・セキュリティ課題は残っているので、安全第一で利用することが必要。
OpenAI CUA Operator
2025年1月にOpenAIから新しい Computer Using Agent (CUA) というのが出ました。
Computer Using Agent という名前が Anthropic 側と似ていて紛らわしいですが、これがGPT-4oの視覚と強化学習でやっているというところでほとんど同じコンセプトになっていると思います。
上述の Anthropic の Computer Use と OSS の Browser Use が合体したような仕組みという印象です。
現状利用できるのは、ブラウザを操作する Operator という機能のみです。
これは ChatGPT Pro プランのみで提供されていて、よく読んでいくと、性能面・セキュリティ面で、上で紹介した競合よりも全然有利だなという印象を受けました。
実際の動作を見てもらうと、公式で出ている動画がわかりやすいです。
https://openai.com/index/introducing-operator/
家族向けのキャンプサイトを探してくれというプロンプトを入力すると、自分のブラウザの向こう側のクラウド上でブラウザが立ち上がってきて、目的のものを探してくれます。そのキャンプサイトで予約してくれっていうのを最後お願いするとなんかいい感じに予約をしてくれるっていうデモになっています。
特徴としていえるのが、ユーザのOSを使ってるのではなくて、OpenAI側の環境内部でブラウザが立ち上がって動作しているという点です。
ベンチマーク
公式ページから点数を抜粋して記載しておきます。
https://openai.com/index/computer-using-agent/
OSWorld (PC操作) : 38点 ⇔ これは人間が72点なんでちょっとまだ差はあります。
WebArena (ブラウザ) : 58点
WebVoyager : 87点。上述の Browser Use の 89 には負けています。
OSSではないため、中身がどうなっているかをこれ以上掘り下げることができませんでした。
OpenAI Operator の圧倒的強み – 独自のセキュリティ対策
これすごいなと思ったのは、このセキュリティ対策をしっかり書いてるところがあります。
1.重要な箇所をユーザーに操作を引き継ぐ
例えばログインや支払いなど、AIは途中で止まるので続きを人間がやってくださいということになる。AIが全部やるわけじゃない、あくまで途中までの補助ですよっていうことです。メール送信に関しては承認を求めます。
2.銀行取引については拒否するようなトレーニングもされている
3.クラウド上で実行されている
ローカルPC上ではあくまでブラウザ操作に完結。ローカルへの影響はなく、隔離環境での実行のため安全性が高い。
Athropic Computer Use や Browser Use のセキュリティ課題をすでにクリアしているような印象を受けます。
ただこれもまだ初期の現状でこういうことをやっていますよというだけなので、もしかしたら今後に別の動きがあるかもしれません。
将来の展望
近い未来に出せる成果としては、業務効率化が真っ先にあると思います。RPAのようにスクリプトを組まなくてもその場のプロンプトでほぼほぼ操作ができてします。
加えて、幅広いお年寄りとかに対しても複雑なサイトを利用訴求できるというのは非常に感じました。さっきデモであったように、家族向けのキャンプサイトを探して予約するのが全部プロンプトベースでできちゃうので、操作が分からない人でもサイトを使えますし、CSのお問い合わせ対応とかもだいぶコストを落とせるんじゃないかなと。
夢が広がりますね!
全体のまとめ
各社独自のアプローチでAIエージェントをリリースしています。
Anthropic Computer Use がまず一番初めに出てきました。ただ現状では点数的には一番下になっています。
OSS の Browser use が鳴り物入りで SOTA を出しています。
OpenAI CUA Operator が高得点+セキュリティ上の利点で良い位置につけています。
一番の課題はセキュリティです。これが最も大きな懸念であり、解決できれば大きな普及が見込めるのではと思っています。
次はスピード面の課題が共通して存在しています。
今後の進捗が楽しみな状況です。
おまけ
Microsoft 365 Copilot
(正直使いこなせていないので、概要まとめだけです)
これは開発者の皆さんがよく使っているGitHub Copilot とは異なる、Microsoft 365 が出している Copilot 。
2023年の11月に登場しました。
できることは、プロンプトを書くと、MicrosoftのOffice系のツールがChatGPTと連携して自動操作をしてくれるという、まさにRPAっぽい機能です。
例
・WordでAI要約
・Outlookのメールドラフトを自動作成
・Excelで関数を自動に作る
2025年1月、 Copilot Chat というまた新しい機能が出てきました。
これが社内のシェアポイントみたいにクローズドな環境にある情報を自在に検索して、FAQを回答できるボットを作れるというようなサービスになっています。
(有料で、 MS365のライセンスにアドオンする形で購入します。すでに契約済みの月当たり5000円ぐらいかかる。)
RPAとしての評価
2025年4月の現状ではこれは私がRPAに期待するものとはちょっと異なっているのではと思います。
機能が限定的で、ブラウザの自動操作とかはできません。
逆に MS RPA である Power Automate で自動的に一部のスクリプトを生成できるんですけど、ちょっとまだ使いづらい印象がありました。今回はこれ以上突っ込まず終わります。
採用に力を入れています。鋭意募集中
次世代システム研究室では、最新のテクノロジーを調査・検証しながらインターネットのいろんなアプリケーションの開発を行うアーキテクトを募集しています。募集職種一覧 からご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD




