2024.10.07
Google Cloud Pub/Sub利用時の失敗談
こんにちは。次世代システム研究室のM.Mです。
前回、前々回のブログでは、「BigQueryへWEBアプリケーションのログを登録してみる」ということで、Pub/Subのサブスクリプションの配信タイプである「BigQueryへの書き込み」や「Cloud Storageへの書き込み」を利用して、WEBアプリケーションのログをBigQueryへ登録しました。
その後、ちょうどよいタイミングで分析のためBigQueryへログを登録したいという案件があり、Pub/Subの配信タイプである「BigQueryへの書き込み」を使って実装、本番リリースしました。
そして、恥ずかしい実装ミスをしていたことに気づきました。
1. 案件概要
案件としては、WEB APIにパラメータをつけてリクエストするから、そのパラメータの値をBigQueryに登録してほしい。
例えば、
https://my-service-domain/log?key1=xxxxx&key2=yyyyy&...
というリクエストが来たら、key1、key2の値をBigQueryに登録するといった内容です。
担当しているプロジェクトでは、すでに何台かのCompute Engine上でPython, Flaskで稼働しているWEB APIが存在しているので、新たなサーバーは用意せず、既存のWEB APIに、新たにBigQueryにログ登録するためのエンドポイントを追加することにしました。
2. 問題のあったソースコード
パラメータを受け取って処理する部分など、実際の案件で実装したソースコードとは違いますが、10行目~17行目のPub/Subを利用してる部分は同じです。
import datetime
import random
import json
from flask import Flask
from google.cloud import pubsub_v1
app = Flask(__name__)
@app.route('/', methods=['GET'])
def publish():
publisher = pubsub_v1.PublisherClient()
topic_name = 'projects/{project_id}/topics/{topic}'.format(
project_id='xxxxxxxxxxxxxxxxxxxxxxxxxxx',
topic='mmtest-topic',
)
log_data = _get_log_data()
publisher.publish(topic_name, json.dumps(log_data).encode('utf-8'))
return 'OK'
def _get_log_data():
user_id = random.randint(1, 1000000)
message = f"test_{user_id}"
logged_at = int(datetime.datetime.now().timestamp() * 1_000_000)
return {
"user_id": user_id,
"message": message,
"logged_at": logged_at
}
if __name__ == "__main__":
app.run(debug=True, host="0.0.0.0", port=8080)
どこが問題だったのでしょうか?
3. どのような問題が起きたのか?
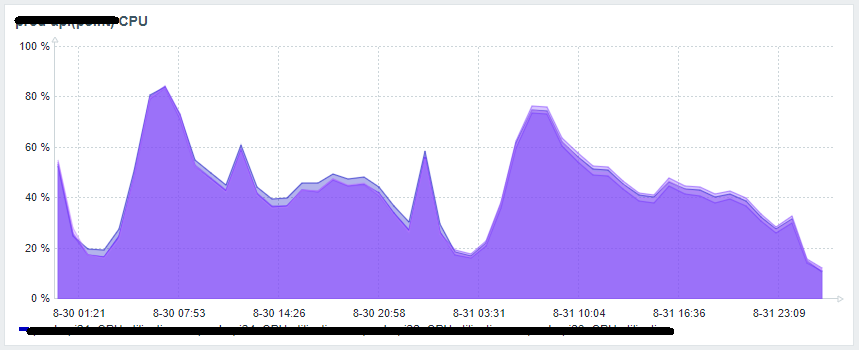
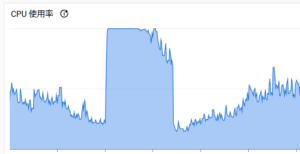
100rpsでCPUが80%になるという。。
(実績として同じスペック、同じ設定のマシン上で動いている他のAPIは、300rpsでもCPUが30-40%程度で稼働しております)
ソースコードを見ただけで、何が問題だったか分かった方も多いと思います。
問題は、上記ソースコードの10行目、以下の部分でリクエストの度に毎回クライアント(publisher)を作っているからですね。
publisher = pubsub_v1.PublisherClient()
それだけでそこまで負荷が高くなるのか?
ということで比較検証してみました。
4. 比較検証
■ 変更前ソースコード(上記ソースコードと同じです)
import datetime
import random
import json
from flask import Flask
from google.cloud import pubsub_v1
app = Flask(__name__)
@app.route('/', methods=['GET'])
def publish():
publisher = pubsub_v1.PublisherClient()
topic_name = 'projects/{project_id}/topics/{topic}'.format(
project_id='xxxxxxxxxxxxxxxxxxxxxxxxxxx',
topic='mmtest-topic',
)
log_data = _get_log_data()
publisher.publish(topic_name, json.dumps(log_data).encode('utf-8'))
return 'OK'
def _get_log_data():
user_id = random.randint(1, 1000000)
message = f"test_{user_id}"
logged_at = int(datetime.datetime.now().timestamp() * 1_000_000)
return {
"user_id": user_id,
"message": message,
"logged_at": logged_at
}
if __name__ == "__main__":
app.run(debug=True, host="0.0.0.0", port=8080)
■ 変更後ソースコード
import datetime
import random
import json
from flask import Flask
from google.cloud import pubsub_v1
app = Flask(__name__)
publisher = pubsub_v1.PublisherClient()
@app.route('/', methods=['GET'])
def publish():
topic_name = 'projects/{project_id}/topics/{topic}'.format(
project_id='xxxxxxxxxxxxxxxxxxxxxxxxxxx',
topic='mmtest-topic',
)
log_data = _get_log_data()
publisher.publish(topic_name, json.dumps(log_data).encode('utf-8'))
return 'OK'
def _get_log_data():
user_id = random.randint(1, 1000000)
message = f"test_{user_id}"
logged_at = int(datetime.datetime.now().timestamp() * 1_000_000)
return {
"user_id": user_id,
"message": message,
"logged_at": logged_at
}
if __name__ == "__main__":
app.run(debug=True, host="0.0.0.0", port=8080)
違いは、変更前ソースソードの10行目、以下の部分が、変更後ソースコードの8行目に移動しただけです。
publisher = pubsub_v1.PublisherClient()
リクエストの度にクライアント(publisher)を生成しないようにしただけです。
■ 比較検証内容
変更前ソースコードと変更後ソースコードでCPUやメモリなど負荷状況の違いを比較検証します。
実行環境
・WEB API部分はCloud Runにて作成(cpu 2, memory 4Gi)
・Python3.11、比較しやすいようにワーカー1、スレッド1のシングル設定にする(Dockerfile)
FROM python:3.11-slim ... CMD exec gunicorn --bind :$PORT --workers 1 --threads 1 --timeout 0 main:app
・利用モジュール
Flask==2.3.3 gunicorn==20.1.0 requests==2.27.1 google-cloud-pubsub==2.23.0
・インスタンス数は最小1、最大1に設定し、オートスケールしない設定にする(Cloud Runデプロイ時オプションに指定)
--min-instances=1 --max-instances=1
実行時間
変更前ソースコードにて
・9:25~9:35 20rps/10分間
・9:55~10:05 40rps/10分間
変更後ソースコードにて
・10:45~10:55 20rps/10分間
・11:08~10:18 40rps/10分間
■ 実行結果
リクエスト数グラフ
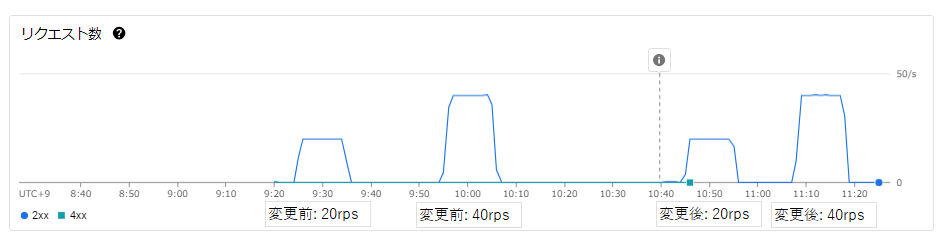
変更前・変更後で意図したリクエスト数(20rps, 40rps)になっています。
インスタンス数グラフ
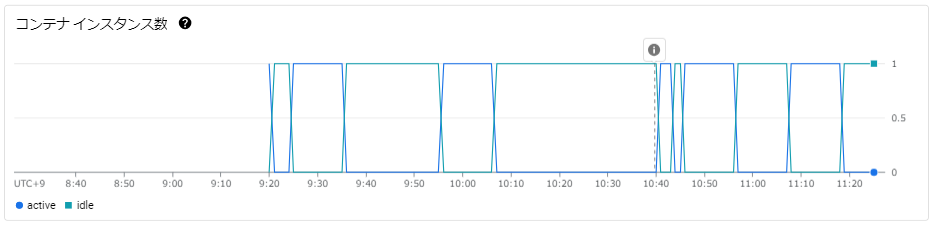
インスタンス数は最小1、最大1に設定したので、意図したとおりオートスケールしないでインスタンス数は1で保たれていることが分かります。
コンテナCPU使用率グラフ
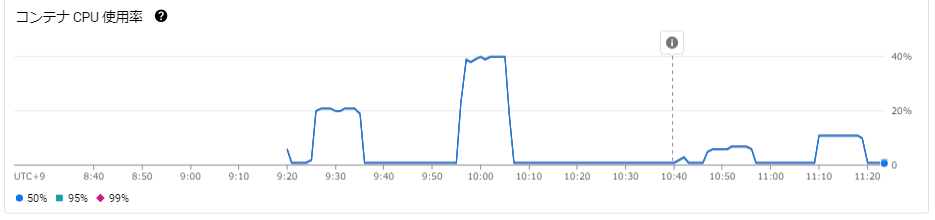
・変更前:20rpsだと20%
・変更前:40rpsだと40%
・変更後:20qpsだと5%
・変更後:40qpsだと10%
大きな違いがでました。
クライアントオブジェクト生成は負荷がかかる処理であり、リクエスト毎に生成していたことで大きな負荷がかかっていたことが分かりました。
コンテナメモリ使用率グラフ
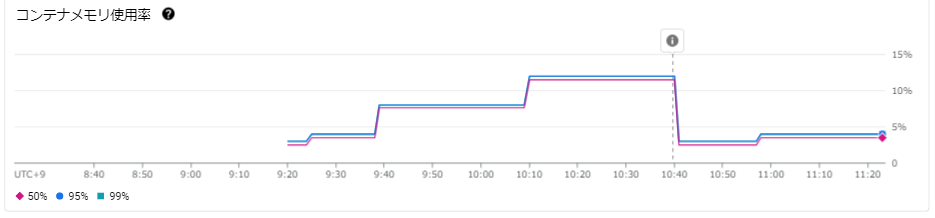
CPU使用率だけでなく、メモリ使用率についても変更前、変更後とでは大きく違うことが分かります。
なお、BigQueryに登録されるデータは、変更前、変更後で違いはありませんでした。
5. まとめ
リクエスト毎にクライアントオブジェクトを生成する場合と起動時にクライアントオブジェクトを生成してリクエスト毎に使いまわすのとでは大きく負荷が異なることが分かりました。
今回の比較検証では、ワーカー1のスレッド1のシングルスレッドで比較しているので気にしませんでしたが、マルチスレッドにした場合は、オブジェクト取得部分に考慮が必要になるかも知れません。
外部システムと連携するようなクライアントオブジェクトの生成部分はもっと注意深く実装するべきでした。
また、変更前も問題なくBigQueryに登録されており、エラーになるわけではないので、気づきにくい問題でもあります。
リリース後アラートがなかったとしても、新しい機能をリリースする際は、想定している負荷の増加量なのか確認することも忘れてはいけないですね。
また、担当した案件のサービスは、古いシステムでオートスケールせず、高負荷になったとアラートが来るので気づきましたが、オートスケールするようなシステムの場合、インスタンスの増減を監視するようなモニタリングをしておかないと、気づかず無駄にリソース使って課金対象になっていたかも知れません。
最後に、次世代システム研究室では、グループ全体のインテグレーションを支援してくれるアーキテクトを募集しています。アプリケーション開発の方、次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ募集職種一覧からご応募をお願いします。
皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD