2018.10.10
Presto on YARN を試す、そしてハマる
こんにちは。次世代システム研究室のデータベース と Hadoop を担当している M.K. です。
また今回も Hadoop ネタなんですが、今まで触ってこなかった Presto を試してみることにしました。
Presto は MPP (Massively Parallel Processing = 大規模並列処理) のクエリエンジンの一つです。
Hadoop 関連の MPP クエリエンジンの一つに、Cloudera 社が開発した Impala があり、こちらは実践投入したことがあります。
今回 Presto を試してみたかったのは、Presto を Hadoop のリソース管理の仕組みの YARN 上で動かす、Presto on YARN を使いたかったからです。
YARN はHadoopクラスタにおいてメモリや CPU コア数などのリソース管理を統合的にやってくれるものですが、Impala は基本的には YARN 上では動かないため、Hadoop クラスタのリソース管理が YARN とそれ以外 (Linuxではcgroupsなど) の管理で分けないといけなくなります。
それではあまり嬉しくないため、YARN 上で動く MPP クエリエンジンとして Presto on YARN に目を付けました。
今回の検証内容
今回も前々回のブログで構築した環境を利用しました。毎度お馴染みの GMO アプリクラウドのサーバーです。
アジェンダは次のとおりです。
- Presto on YARN の仕組み
- Presto on YARN を構築してみる ~うまく動かない・・~
- Presto on YARN を動かすまで ~解決策~
- Hive on Tez と Presto on YARN でクエリを比較検証する
- まとめ
Presto on YARN の仕組み
Presto on YARN は Presto とは全く別のプロダクトではなく、Hadoop 関連技術の Apache Slider を利用して Presto を動かすというものです。
Slider は YARN を利用したい分散アプリケーションが、YARN に対してリソースをやり取りするといったコードを書かなくても YARN 上で利用できるようにする仕組みです。
ただし、Slider は常時起動のプロセス向けのものなので、処理中に YARN のリソースを確保し処理が終わったらリソースを解放、というものではありません。
YARN 上では常に起動中のプロセス分のリソースが使用中の状態になります。
Presto は、COORDINATOR と WORKER のプロセスに別れており、ユーザーは COORDINATOR とやり取りをします。あとは COORDINATOR が WORKER に分散処理をさせるという仕組みです。
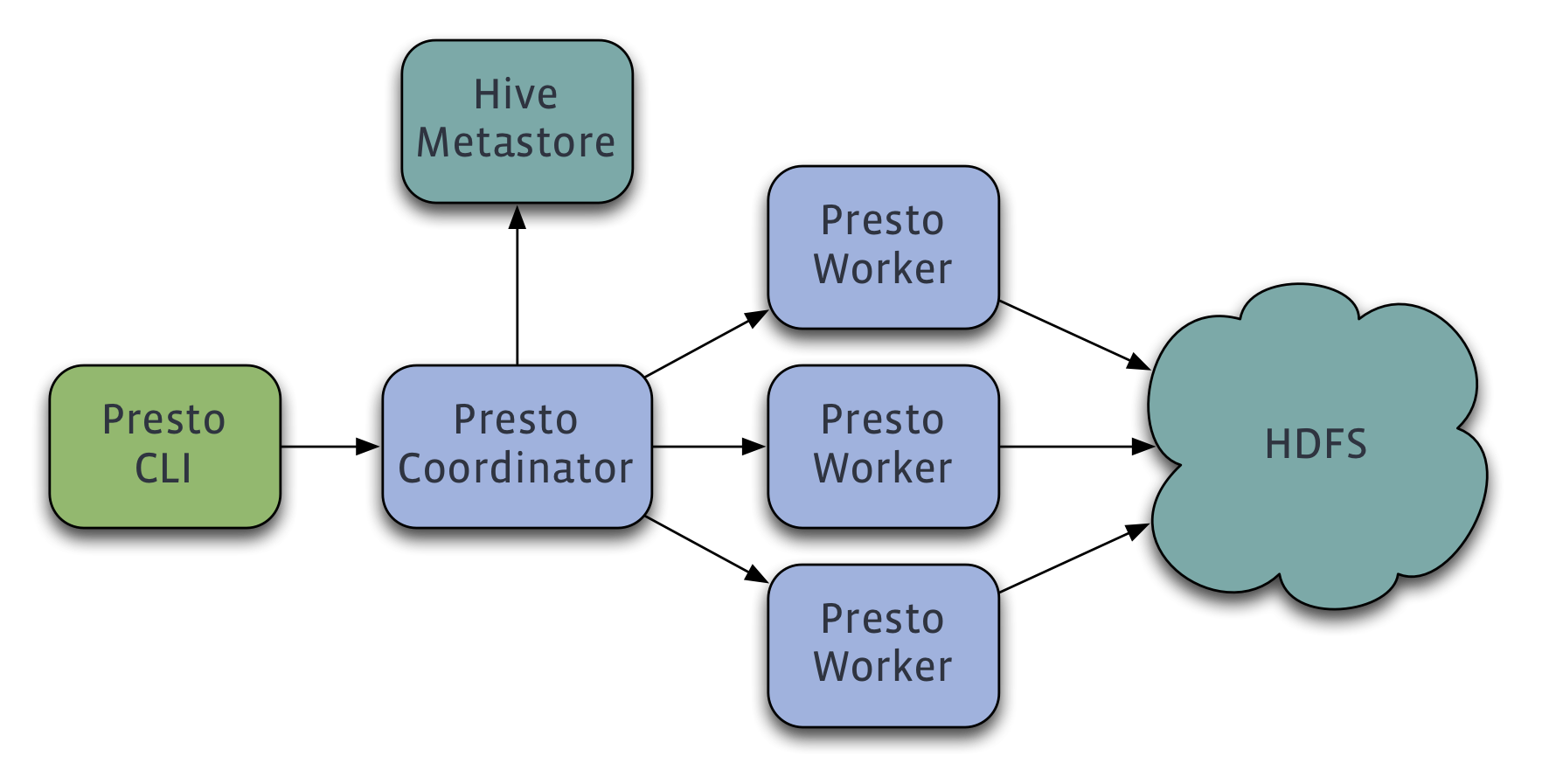
From https://prestodb.io/overview.html
Presto on YARN を構築してみる ~うまく動かない・・~
今回の Hadoop クラスタは Hortonworks 社の HDP で Ambari を利用しているので、Ambari を使って構築してみます。Presto on YARN のインストールに関するドキュメントを参考にしました。
環境要件の確認
このドキュメントにインストール時の環境要件が書いてあります。
今回の Hadoop クラスタのバージョンは以下のとおりで、環境要件は満たせていました。
- HDP 2.6.4
- Ambari 2.6.1
- Slider 0.92.0
- Zookeeper 3.6.4
- jdk1.8.0_112
OpenSSL のバージョンについても大事な環境要件になるんですが、後回しにしておいたら忘れてしまい、バージョンが古いままで構築してエラーの原因究明に時間かかってしまったので、最初に確認することをオススメします。
OS周りのセットアップ
既に出来上がっている Hadoop クラスタ環境を使うので割愛します。
詳細をご覧になりたい方は前々回のブログをお読みください。
追加でOpenSSLのバージョンアップなどを行います。散々エラーを出し、以下の yum update が足りないことがわかったので、それを Hadoop クラスタの全ホストで先にやっておきます。
※ yum レポジトリによっては当然、環境要件に満たさないバージョンまでしか更新できなかったりしますので注意してください。
yum update nss curl libcurl yum update openssl
Presto on YARN をビルド
まず、GitHub の prestodb/presto-yarn ページから Presto on YARN をダウンロードして、maven でビルドします。
Hadoop クラスタ環境に git や maven が入っていなかったため、ビルド用のサーバーを別途用意してやりました。
maven はパッケージの依存関係が激しいので Hadoop クラスタ環境ではあえてやってません。
ビルド用のサーバーで以下を実施します。
yum update nss curl libcurl yum install git yum install maven cd /var/tmp git clone https://github.com/prestodb/presto-yarn.git cd presto-yarn mvn clean package
ビルドして出来上がったファイルを Ambari Server に配置
presto-yarn ディレクトリに以下のファイルが出来上がります。
- presto-yarn-package/target/presto-yarn-package-1.6-SNAPSHOT-0.167.zip
これを Ambari Server を立てたホストの以下の場所にコピーします。
- /var/lib/ambari-server/resources/apps/
この場所に配置し Ambari Server を再起動したら、Ambari の View を新設してそこからに Presto on YARN を Slider に登録できるようになる・・はずだったんですが、どうしても上手くいかず。。
結局、Slider への登録は Slider Client のコマンドから行いました。その場合は、この場所になくても大丈夫と思います。
Ambari に Slider View を新設
Ambari に管理者権限アカウントでログインしたら、画面上のメニューバーの右端にある「admin」プルダウンで「Manage Ambari」を選択します。
次の画面で左のメニュー列の真ん中あたりにある「Views」リンクを押します。
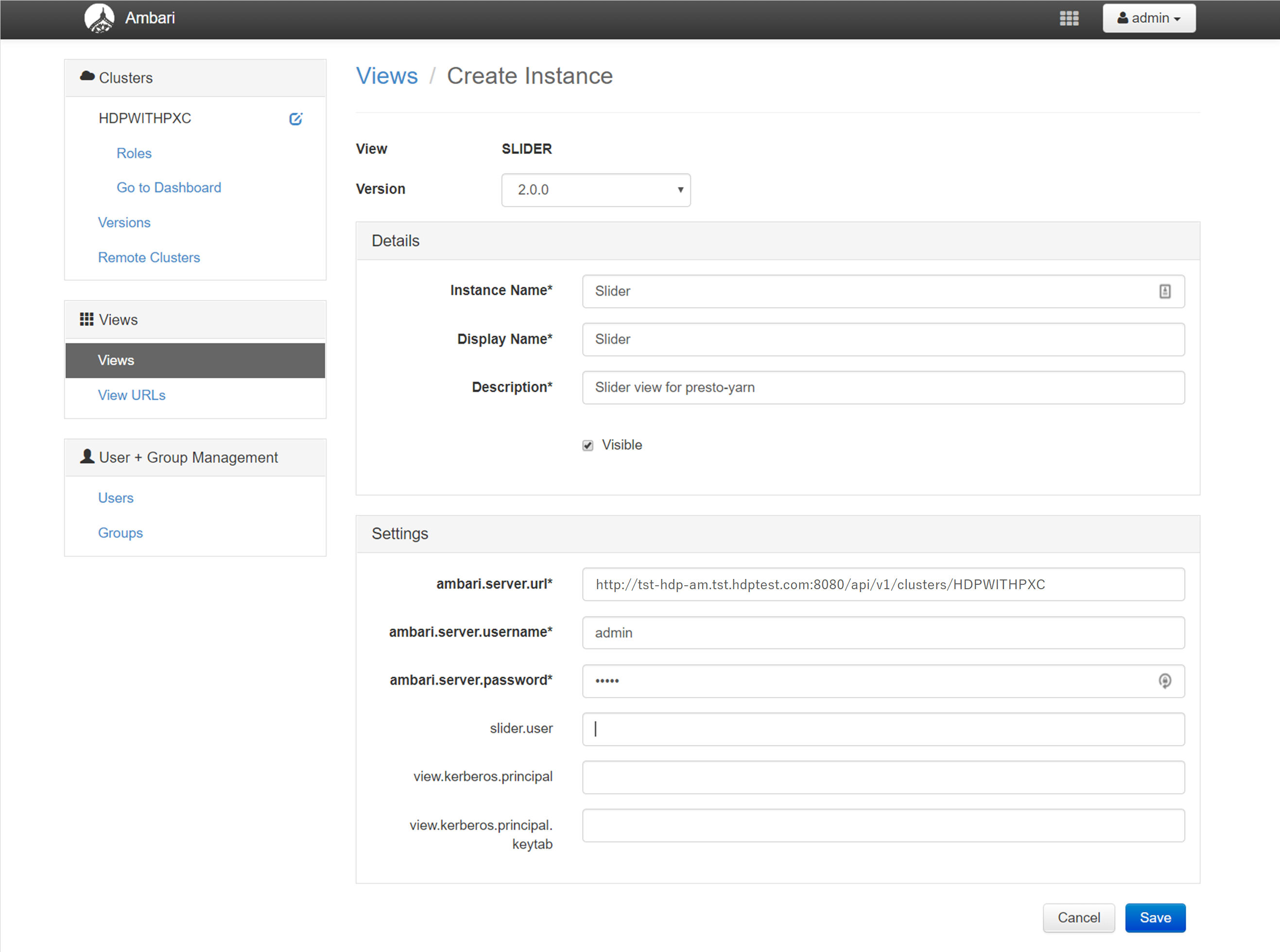
そうすると View の一覧が出てくるので、「> SLIDER」を開いて「+Create Instance」ボタンを押します。
「ambari.server.url」には以下のような内容を設定し、
- http://<Ambari Server ホスト(FQDN)>:8080/api/v1/clusters/<Hadoop クラスタ名>
「ambari.server.username」「ambari.server.password」には Ambari の管理者権限アカウントの情報を設定します。
その他の必須項目も以下の画像のように設定したら、「Save」ボタンを押して完了です。
Slider 用の HDFS ディレクトリ作成
今回 Presto on YARN はそのまま yarn ユーザーで稼働させることにします。
Slider は HDFS 上の /user 配下に色々アップロードするので、ディレクトリがない場合は予め HDFS ディレクトリを作っておきます。
パーミッションも忘れずに確認します。今回は yarn:hadoop の所有者にあわせました。
※Apache Ranger などを利用している場合は、Ranger 側でパーミッションの設定を予めしておく必要があります。
sudo - yarn hdfs dfs -mkdir -p /user/yarn
Slider に Presto on YARN をインストール
Ambari に新設した Slider View から「+Create App」ボタンで一通りの登録をしようとしたものの、なぜか真っ黒の画面になって埒が明かなかったので、結局、Slider Client の以下の登録コマンドで行いました。
初めに、ビルドして出来上がった presto-yarn-package-1.6-SNAPSHOT-0.167.zip を以下のように Slider にインストールします。必ず Slider を利用するユーザー (今回は yarn ユーザー) で実施します。
slider install-package \ --name PRESTO \ --replacepkg \ --package presto-yarn-package-1.6-SNAPSHOT-0.167.zip
上記は presto-yarn-package-1.6-SNAPSHOT-0.167.zip を配置した場所で実施しました。
name は今回 PRESTO としましたが何でも良いはずです。
Presto on YARN の設定ファイルを編集
次に、Presto on YARN の設定ファイル、appConfig.json と resources.json を編集します。
最初何をどこまで設定するのかわからないのですが、presto-yarn-package-1.6-SNAPSHOT-0.167.zip の中に appConfig-default.json と resources-defalut.json があるので、別の場所に解凍&コピーして使います。
編集した設定ファイルを今回は /var/tmp 配下に置きました。
色々な情報を参考にひとまず以下の設定にしました。Presto の各パラメータの意味はこちらのページを参考にしてください。
appConfig.json (※実は上手くいかなかった設定の例)
{
"schema": "http://example.org/specification/v2.0.0",
"metadata": {
},
"global": {
"site.global.app_user": "yarn",
"site.global.user_group": "hadoop",
"site.global.data_dir": "/var/lib/presto/data",
"site.global.config_dir": "/var/lib/presto/etc",
"site.global.app_name": "presto-server-0.167",
"site.global.app_pkg_plugin": "${AGENT_WORK_ROOT}/app/definition/package/plugins/",
"site.global.singlenode": "false",
"site.global.coordinator_host": "${COORDINATOR_HOST}",
"site.global.presto_query_max_memory": "16GB",
"site.global.presto_query_max_memory_per_node": "4GB",
"site.global.presto_server_port": "9090",
"site.global.catalog": "{'hive': ['connector.name=hive-hadoop2', 'hive.config.resources=/etc/hadoop/conf/core-site.xml,/etc/hadoop/conf/hdfs-site.xml', 'hive.metastore.uri=thrift://tst-hdp-m2.tst.hdptest.com:9083,thrift://tst-hdp-m3.tst.hdptest.com:9083'],'tpch': ['connector.name=tpch']}",
"site.global.jvm_args": "['-server', '-Xmx5120M', '-XX:+UseG1GC', '-XX:G1HeapRegionSize=32M', '-XX:+UseGCOverheadLimit', '-XX:+ExplicitGCInvokesConcurrent', '-XX:+HeapDumpOnOutOfMemoryError', '-XX:OnOutOfMemoryError=kill -9 %p']",
"site.global.log_properties": "['com.facebook.presto=INFO']",
"application.def": ".slider/package/PRESTO/presto-yarn-package-1.6-SNAPSHOT-0.167.zip",
"java_home": "/usr/jdk64/jdk1.8.0_112"
},
"components": {
"slider-appmaster": {
"jvm.heapsize": "256M"
}
}
}
resources.json (※実は上手くいかなかった設定の例)
{
"schema": "http://example.org/specification/v2.0.0",
"metadata": {
},
"global": {
"yarn.container.failure.threshold": "1"
},
"components": {
"slider-appmaster": {
},
"COORDINATOR": {
"yarn.role.priority": "1",
"yarn.component.instances": "1",
"yarn.component.placement.policy": "1",
"yarn.vcores": "3",
"yarn.memory": "4096",
"yarn.label.expression": "coordinator"
},
"WORKER": {
"yarn.role.priority": "1",
"yarn.component.instances": "5",
"yarn.component.placement.policy": "1",
"yarn.vcores": "2",
"yarn.memory": "2048"
"yarn.label.expression": "worker"
}
}
}
Presto 用のディレクトリを作成
site.global.data_dir と site.global.config_dir に設定したディレクトリを作成します。
これらのディレクトリはPresto on YARN で Presto が立ち上がった後、Presto が実際に使うディレクトリです。
Presto on YARN を実行するユーザーを yarn ユーザーにしたので、yarn ユーザーが書き込めるようにしておく必要があります。
mkdir -p /var/lib/presto/data /var/lib/presto/etc chown -R yarn:hadoop /var/lib/presto
Slider Client のパラメータを設定
Presto on YARN は ZooKeeper を使うので、以下の項目の設定を Ambari から行います。
Ambari にログイン、Slider > Configs > Custom slider-client から以下のパラメータを設定し、Refresh Configs を実行します。
- zk.home = /usr/hdp/current/zookeeper-server
- slider.zookeeper.quorum = tst-hdp-m1.tst.hdptest.com:2181,tst-hdp-m2.tst.hdptest.com:2181,tst-hdp-m3.tst.hdptest.com:2181
Slider に Presto on YARN をアプリケーション登録
いよいよ Presto on YARN を Slider にアプリケーション登録をして Presto を起動させます。
アプリケーション名は今回は presto-yarn としました。
インストールの時と同様の理由で、yarn ユーザーで実施します。
slider create presto-yarn \ --template /var/tmp/appConfig.json \ --resources /var/tmp/resources.json
さあこれから、と思ったらここからが大変で・・・
何度試しても Slider から Presto が起動せず、もしくは起動してもすぐに落ちたりして、ドツボにハマりました。。
Presto on YARN を動かすまで ~解決策~
まずもって困ることは、うまくいってないことがすぐにわからず、Presto、Slider (Presto on YARN)、YARN のどこで何のエラーが出ているかが非常にわかりずらいことです。
そもそもどこでエラーを見るのか
最初よくわからなかったものの、以下の3つのログに何かしら情報が出ています。
- Presto のサーバーログ
- Slider (Presto on YARN) のログ
- YARN のアプリケーションログ
Presto のサーバーログは、設定ファイルの site.global.data_dir に設定したデータディレクトリ配下にできます。今回の設定では /var/lib/presto/data/var/log/server.log になります。
Presto が起動できないときに、Presto のサーバーログにその原因を吐いてくれたら良かったんですが、Presto が起動できないときはサーバーログを作りません。それで非常に困りました。
Slider (Presto on YARN) のログは、YARN のコンテナが作る以下のような一時的なディレクトリに格納されています。
- /var/hadoop/yarn/log/application_1538294223644_0005/container_e06_1538294223644_0005_01_000005/slider-agent.log
Presto on YARN がうまくいかず YARN コンテナが落ちてしまうと、そのディレクトリごと消えてしまい、ログが見れないということになります。これも非常に困りました。
YARN のアプリケーションログは、Hadoop 界隈ではお馴染みのものですね。
slider create コマンドを発行すると、YARN のアプリケーションIDが表示されるので、それを以下のように指定して yarn logs コマンドを実行すると、分散環境においてログをまとめて出してくれます。
yarn logs -applicationId application_1538294223644_0005
ただ、膨大な行数のログを吐くことが多いので、エラーの原因を見つけ出すのはちょっと大変です。
Presto 起動失敗の原因
失敗し続けこれらのログと闘うこと数十回・・、いろんな原因がありましたが、大きく分けると以下のようなものでした。
- Linux のパッケージが合っていない
- appConfig.json と resources.json の設定のどこかがおかしい
- 実はPresto on YARN が COORDINATOR と WORKER をうまいこと分散して起動してくれない
1.の Linux パッケージの問題については、上述してきたものに加えて、Python 問題もありました。
SSL の CERTIFICATE VERIFY のエラーが出ていて、Python のバージョンを 2.7.5 未満にダウングレードすることが解決策の一つでしたが、HDP や Ambari は Python を使っていて安易に Python をダウングレードするのは危険なので、今回は検証ということもあり、cert verification を無効化しました。
Hadoop クラスタの全ホストで、/etc/python/cert-verification.cfg の中身を以下のように編集します。
[https] #verify=platform_default verify=disable
2.の設定の問題は、設定項目が多いため、何がどういけなくて失敗しているのか理解するのが困難でした。
結局、主な原因は、Presto と YARN のメモリ設定の辻褄が合っていなかったことでした。
少なくとも今回の Presto on YARN の Presto のバージョン 1.67 では、メモリに関わる設定が下記のような関係になっていないと怒られるようです。
- yarn.memory > jvm_args [ -Xmx ] > presto_query_max_memory_per_node
- presto_query_max_memory_per_node <= jvm_args [ -Xmx ] の 40% ~ 50%
- presto_query_max_memory_per_node * yarn.component.instances <= presto_query_max_memory
3.の分離問題は、COORDINATOR と WORKER は違う設定なので設定ファイルを別々にしないといけないんですが、共通の site.global.data_dir および site.global.config_dir のパスを設定するにもかかわらず COORDINATOR とWORKER が同じノードに立ち上がってしまうということです。
常に COORDINATOR と WORKER が別のノードに制御してくれれば良かったんですが、そうはならないことが多く、同じノードで起動されてどっちも落ちるということが一番ハマった原因でした。
恐らく同じ理屈で、全部 WORKER だったとしても、1ノードに2つの WORKER が立ち上がるとお互いのデータディレクトリを上書きするため、上手くいかないと思います。
その場合、YARN コンテナの一時的なパスをデータディレクトリに指定するなど工夫したらやれるかもしれませんが、未検証です。
他にも WORKER から COORDINATOR が見つからないとか、COORDINATOR で queue.json という設定ファイルがないとかのエラーも出ましたが、まずはこの分離問題が一番の原因でした。
Presto を起動させる解決策
それでどうしたのかですが、結局 COORDINATOR だけ Presto on YARN を使わずに構築し、WORKER のみ Presto on YARN を使うことにしました。
こちらのスライド資料を参考にさせて頂きました。Presto on YARN って一体・・?という話ですね。。
COORDINATOR を構築するにあたって、いつも最新の Hadoop の各種設定ファイルを見られると都合が良いため、今回はマスターノードの一つ (tst-hdp-m2) に1台構成で構築することにしました。
以下の図のような構成になります。
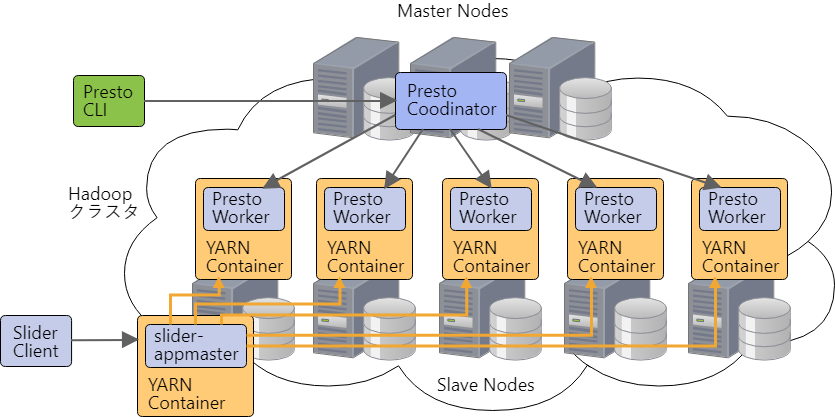
マスターノードに COORDINATOR の構築
今回の Presto on YARN と同じ Presto のバージョンのバイナリを落としてきて展開します。
データディレクトリは他と同じように /var/lib/presto/data で作成します。
Presto のバイナリは今回 /var/lib/presto-server として配置しました。
cd /var/tmp wget https://repo1.maven.org/maven2/com/facebook/presto/presto-server/0.167/presto-server-0.167.tar.gz tar zxvf presto-server-0.167.tar.gz mkdir -p /var/lib/presto/data chown -R yarn:hadoop /var/lib/presto mv presto-server-0.167 /var/lib/presto-server mkdir -p /var/lib/presto-server/etc chown -R yarn:hadoop /var/lib/presto-server
続いて COORDINATOR 用の各種設定ファイルを用意します。
起動は上手くいかなかったものの、Presto on YARN が COORDINATOR の /var/lib/presto/etc 配下に自動生成した設定ファイルを残していたので、それをベースにしました。
以下が設定ファイルです。
- catalog/hive.properties
- catalog/tpch.properties
- config.properties
- jvm.config
- log.properties
- node.properties
- queues.json
- resource-groups.properties
- resource_groups.json
これらの設定ファイルを /var/lib/presto-server/etc に配置します。それぞれの設定内容は以下のようにしました。
catalog/hive.properties
connector.name=hive-hadoop2 hive.config.resources=/etc/hadoop/conf/core-site.xml,/etc/hadoop/conf/hdfs-site.xml hive.metastore.uri=thrift://tst-hdp-m2.tst.hdptest.com:9083,thrift://tst-hdp-m3.tst.hdptest.com:9083
catalog/tpch.properties
connector.name=tpch
config.properties
coordinator=true node-scheduler.include-coordinator=False discovery-server.enabled=true http-server.http.port=9090 query.max-memory=20GB query.max-memory-per-node=4GB query.queue-config-file=/var/lib/presto-server/etc/queues.json discovery.uri=http://tst-hdp-m2.tst.hdptest.com:9090
jvm.config
-server -Xmx8192M
log.properties
com.facebook.presto=INFO
node.properties
node.environment=test node.id=zz-0123456789 node.data-dir=/var/lib/presto/data plugin.config-dir=/var/lib/presto-server/etc/catalog
queue.json
{
"queues": {
"user.${USER}": {
"maxConcurrent": 100,
"maxQueued": 1000
}
},
"rules": [
{
"queues": ["user.${USER}"]
}
]
}
resource-groups.properties
resource-groups.configuration-manager=file resource-groups.config-file=/var/lib/presto-server/etc/resource_groups.json
resource_groups.json
{
"rootGroups": [
{
"name": "global",
"softMemoryLimit": "80%",
"hardConcurrencyLimit": 100,
"maxQueued": 1000,
"schedulingPolicy": "weighted",
"jmxExport": true,
"subGroups": [
{
"name": "adhoc_${USER}",
"softMemoryLimit": "10%",
"hardConcurrencyLimit": 2,
"maxQueued": 1,
"schedulingWeight": 9,
"schedulingPolicy": "query_priority"
}
]
}
],
"selectors": [
{
"group": "global.adhoc_${USER}"
}
]
}
Presto on YARN の起動失敗において COORDINATOR に queue.json という設定ファイルがないと怒られていたので、予め queue.json ファイルを配置しました。
設定ファイルの用意が終わったら、yarn ユーザー PATH を通します。
.bash_profile などを編集し以下のように PATH に JDK と presto-server を追加しておきます。
# PATH=$PATH:$HOME/.local/bin:$HOME/bin PATH=$PATH:/usr/jdk64/jdk1.8.0_112/bin:/var/lib/presto-server/bin:$HOME/.local/bin:$HOME/bin
最後に PATH を通したら yarn ユーザーで Presto を起動します。
最初に launcher run するとフォアグラウンドで実行されるので問題なく起動できることを確かめたら、launcher start でバックグラウンドで起動します。
launcher run launcher start
これで COORDINATOR の起動が完了です。
スレーブノードに WORKER のみ Presto on YARN で立ち上げる
COORDINATOR を自分で構築したら、今度は Presto on YARN の設定で問題のあった箇所を修正し、WORKER のみ立ち上がるようにします。
appConfig.json と resouces.json を以下のように編集し直します。
appConfig.json (※上手くいった WORKER のみの設定の例)
{
"schema": "http://example.org/specification/v2.0.0",
"metadata": {
},
"global": {
"site.global.app_user": "yarn",
"site.global.user_group": "hadoop",
"site.global.data_dir": "/var/lib/presto/data",
"site.global.config_dir": "/var/lib/presto/etc",
"site.global.app_name": "presto-server-0.167",
"site.global.app_pkg_plugin": "${AGENT_WORK_ROOT}/package/plugins/",
"site.global.singlenode": "false",
"site.global.coordinator_host": "tst-hdp-m2.tst.hdptest.com",
"site.global.presto_query_max_memory": "20GB",
"site.global.presto_query_max_memory_per_node": "3GB",
"site.global.presto_server_port": "9090",
"site.global.catalog": "{'hive': ['connector.name=hive-hadoop2', 'hive.config.resources=/etc/hadoop/conf/core-site.xml,/etc/hadoop/conf/hdfs-site.xml', 'hive.metastore.uri=thrift://tst-hdp-m2.tst.hdptest.com:9083,thrift://tst-hdp-m3.tst.hdptest.com:9083'],'tpch': ['connector.name=tpch']}",
"site.global.jvm_args": "['-server', '-Xmx8192M', '-XX:+UseG1GC', '-XX:G1HeapRegionSize=32M', '-XX:+UseGCOverheadLimit', '-XX:+ExplicitGCInvokesConcurrent', '-XX:+HeapDumpOnOutOfMemoryError', '-XX:OnOutOfMemoryError=kill -9 %p']",
"site.global.log_properties": "['com.facebook.presto=INFO']",
"application.def": ".slider/package/PRESTO/presto-yarn-package-1.6-SNAPSHOT-0.167.zip",
"java_home": "/usr/jdk64/jdk1.8.0_112"
},
"components": {
"slider-appmaster": {
"jvm.heapsize": "256M"
}
}
}
resources.json (※上手くいった WORKER のみの設定の例)
{
"schema": "http://example.org/specification/v2.0.0",
"metadata": {
},
"global": {
"yarn.container.failure.threshold": "1"
},
"components": {
"slider-appmaster": {
},
"WORKER": {
"yarn.role.priority": "1",
"yarn.component.instances": "5",
"yarn.component.placement.policy": "1",
"yarn.vcores": "2",
"yarn.memory": "9216"
}
}
}
編集が終わったら、改めて slider create コマンドを実施します。
アプリケーション名を presto-yarn-worker としました。
必ず yarn ユーザーで行います。
slider create presto-yarn-worker \ --template /var/tmp/appConfig.json \ --resources /var/tmp/resources.json
Ambari に新設した Slider View をみて、以下の図のように立ち上がっていれば無事に Presto on YARN 起動です。
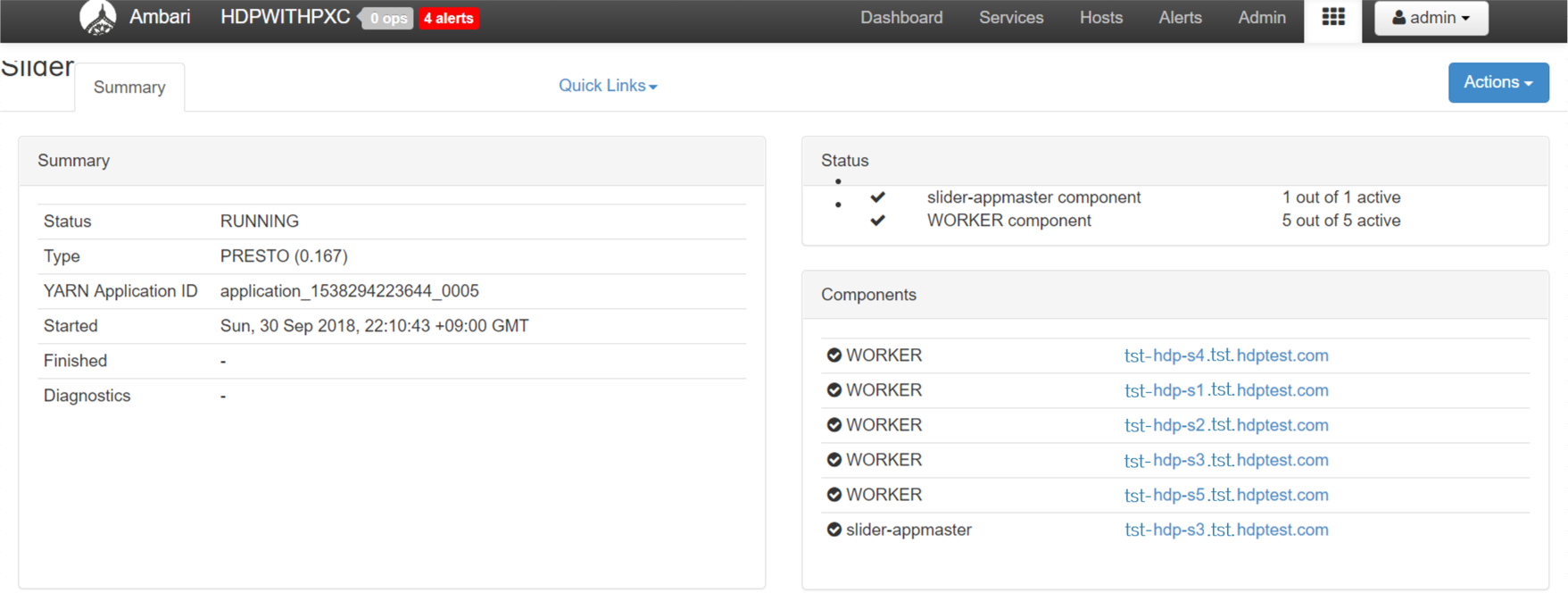
Presto CLI を構築
ようやく Prest が一通り起動したところで、接続するためのクライアントを準備します。
Presto のクライアントを配置したいホストで以下を実施します。バージョンを指定してダウンロードしてきて好きなところに置くのみです。
今回は /usr/bin 配下に置きました。
cd /var/tmp wget https://repo1.maven.org/maven2/com/facebook/presto/presto-cli/0.167/presto-cli-0.167-executable.jar chmod 755 presto-cli-0.167-executable.jar mv presto-cli-0.167-executable.jar /usr/bin/presto
今回は yarn ユーザーでクエリを投げるつもりなので、yarn ユーザーの .bash_profile などに JDK の PATH だけは通しておきます。
Hive on Tez と Presto on YARN でクエリを比較検証する
なんとか Presto on YARN を構築できましたが、それだけではその真価がわからないので、
「GreenplumDB と Hive on tez でデータのロードとクエリを試してみました」を書いたときに使用したサンプルデータ page_views.csv を利用しました。
このデータを格納した Hive の ORC フォーマットテーブル page_views_orc を準備して、以下のクエリの実行時間を計ってみました。
select document_id, platform, count(*) from page_views_orc where geo_location like 'US%' group by document_id, platform having count(*) > 200;
Hive on Tez と Prest on YARN で比較します。
なお、page_views.csv は zip 圧縮済みでも 30GB ほどあり大きなデータです。
Hive on Tez で計測
page_views_orc テーブルを hivedb というデータベース (スキーマ) に準備したので、Hive クライアントで hivedb に接続し、上記クエリを2回実行しました。
- 1回目:236秒
- 2回目:21秒
Presto on YARN で計測
Presto クライアントから COORDINATOR に以下のように繋ぎます。
presto --server tst-hdp-m2.tst.hdptest.com:9090 --catalog hive --schema hivedb
そして上記クエリを2回実行しました。
- 1回目:126秒
- 2回目:111秒
libhadoop を参照できるようにして Presto on YARN で計測
おまけで、Presto on YARN を起動する際に必ず出ていた short-circuit local reads が使えないという以下のワーニングを回避したらより速くなるかなと思い、
The short-circuit local reads feature cannot be used because libhadoop cannot be loaded
yarn ユーザー に下記のように LD_LIBRARY_PATH を通してから再度やってみました。
export LD_LIBRARY_PATH=/usr/hdp/current/hadoop-client/lib/native
その結果、どうやら返ってちょっと遅くなってしまったようにみえます。どうやらもっと調査が必要そうですが今回はここまで。
- 1回目:142秒
- 2回目:172秒
まとめ
今回 Presto へのメモリ割り当ては1ノードあたり 3GB (JVM は8GB) ×5台とそこまで多くない中で、簡単なクエリの検証において Presto が Hive on Tez より大体 100秒近く速いという結果になりました。
とは言っても何十倍もの差が出ているわけではないので、メモリ設定などをチューニングしたらどれくらいまで速くなるかは今後の検証課題です。
あと、Presto on YARN は Slider を通して YARN キューのリソースを事前に一定割合確保する仕組みなので、Hive の LLAP と似ているところがあります。
メモリ消費とクエリ速度の兼ね合いによって、HDP に統合されている Hive LLAP の方が使い勝手が良いことも考えられますので、Presto on YARN を本番環境で使うかどうかの1つの判断として Hive LLAP との比較検証は行った方が良さそうです。
以下に Presto on YARN のメリット・デメリットをまとめてみました。Presto on YARN を使うか使わないかはなんとも微妙なところです。
Presto on YARN のメリット・デメリット
- メリット
- Hive や Spark などの他の分散処理とのリソース調整を YARN ですべて行える
- スレーブノードをどんどん追加しても、WORKER の構築・運用が 簡単
- Presto のバージョンアップなども Presto on YARN を使うとビルドし直したものを用意すればあとは Slider コマンドを叩くだけ
- プロセスが落ちても自動再起動をしてくれる (リトライ)
- デメリット
- 今のところ COORDINATOR と WORKER を上手いこと分離してくれない ⇒COORDINATOR だけ自分で管理するという残念なことに
- Slider と Presto 両方にある程度精通していないといけない ⇒エラーが起きたときの原因追究が大変
- Linux の cgroups を設定して Presto と Hadoop を住み分ける運用より大きく上回っているとは言い難い
- Hadoop の各種クライアントだけインストールしたホストを何台もすぐに準備できるのなら、そこに 自分で Presto を構築すれば (つまり、データを持たない Presto 処理専用ホストを構築)、スレーブノードのメモリを消費せずに Presto を使えるのでそれはそれで良いのかも。
- Linux の cgroups を設定する運用なら、Impala も選択肢。
最後に
次世代システム研究室では、データ分析エンジニアやアーキテクトを募集しています。ビッグデータの解析業務など次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。
皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD

