2019.12.27
自然言語処理モデルBERTでニュースから経済指標へのインパクトを予想してみる
こんにちは。次世代システム研究室のT.I.です。
今回は近年、発展の著しい機械学習の分野として、自然言語処理について簡単に紹介し、鍵とな技術や最近の潮流についても手短にはありますが触れたいと思います。
自然言語処理とは?
文章を他の言語に翻訳したり、文章を生成したり、文章を読んで質問に答えるなど、自然言語処理のタスクは多岐に渡ります。
機械は言葉の意味をどう学習するか?
文章を機械学習モデルに入力するためには、文章を単語に分割し、それぞれに何らかのラベル割り振って入力します。しかし、これだけでは無味乾燥なラベルに過ぎず、文脈のなかで単語の持つ意味という情報を適切に処理することが必用となります.単語の意味というものは、どのようにして抽出すればよいのでしょうか?ひとの手で、同義語や反語などの辞書を作ることにはコストや曖昧さが残ります。
近年ではインターネットの発展により利用可能となった膨大なテキストから、統計的に単語の関係性を抽出することが進められています。その際に重要となるアイデアは”分布仮説”です。これは、ある単語の意味は周囲の単語つまり文脈から決定されるという考え方です。
機械学習で単語の意味を抽出するアルゴリズムとして有名なものはword2vecです。これは大量の文章を教師データとし、ある文脈のもとで出現する単語を予測することで、単語の意味を高次元空間の点としてして抽出します。
その結果、得られる面白い結果として、
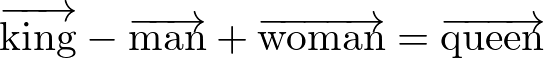
のような計算が可能となります。
このような単語の意味を捉えるためには大量の文章を元にモデルを学習する必要がありますが、既に様々な学習済みモデルがweb上で公開され簡単に利用することができます。
以下は、英語で3百万の単語を300次元へと埋め込んだ学習済みモデルによる簡単なデモです。確かに、kingからの演算でqueenが得られることが判ります。
# download pre-trained vectors
# !wget -c "https://s3.amazonaws.com/dl4j-distribution/GoogleNews-vectors-negative300.bin.gz"
import gensim
model = gensim.models.KeyedVectors.load_word2vec_format('./GoogleNews-vectors-negative300.bin.gz', binary=True)
result = model.most_similar(positive=['king', 'woman'], negative=['man'], topn=1)
print(result) # >> [(‘queen’, 0.7118192911148071)]
また、”queen”より単語の適合率は下がりますが、monarch, princess, crown_prince, prince などが候補として挙げられており、確かに類似した単語のグループをこのベクトルが抽出していることが判ります。
All You Need Is Attention — Transformer
数年前まで、自然言語処理モデルの1つの潮流として、Recurrent Neural Network (RNN) を用いた研究が進められていました。RNNとは、時系列のデータの入力に加えて、一つ前入力からの出力結果も再帰的に受け取るモデルです。この構造により、文章の記憶を保持しながら学習することができます。
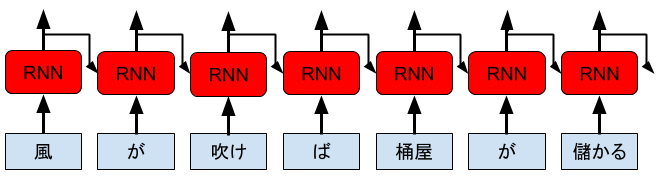
上はRNNの概念図です。例えば、文章を自動生成したいならば、次に出現する単語を順次予測しながらモデルに入力していけばよい訳です。しかし、長い文章では長時間の記憶を保持する必要があり、RNNのモデル構造のみでは対応することが難しいです。
そんな状況下で、2017年に “Attention Is All You Need” [arXiv:1706.03762] という大変挑戦的なタイトルの論文が発表されました。この論文では、Attention というNeural Network構造を用いたTransformerという機械学習モデルが導入され、これは従来のRNNを上回る性能を発揮し大きな話題となりました。それからTransformerを応用する自然言語処理モデルの発展は著しく、Transformerに基づく機械学習は最近のNLP研究の主役となっています。
Attentionとは?
Transformerの重要な構成要素であるAttention layerとは以下のようなneural networkです。(以下の図などは、Transformerの元論文より引用させて頂きました。)
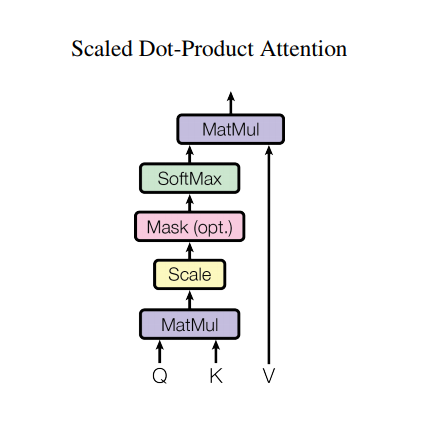
ここで、Query, Key, Value の3つのあります。概略としては、質問(Q)に対応するメモリの情報(K)を抽出して、その値(V)を取り出す操作に対応しています。もっと詳細に知りたい方は、AttentionについてのTensorFlowの実装デモ(https://www.tensorflow.org/tutorials/text/nmt_with_attention)などを参照していただければと思います。
Transformer の構造
そして、このAttentionを更に多層化したMulti-Head Attentionを組み込んだニューラル・ネットワークが「Transformer」と呼ばれるモデルになり、次の図のようになります。
![]()
まず、左側をEncoder、右側をDecoderと呼びます。このオレンジ色の部分がAttention Layerで、上で紹介したAttention Layerを多層化したものです。入力された文章はまず、Input Embeddingで分散表現に変換されます。そして、何層ものAttention & Feed Forward ネットワークを経由します。そして、正解となる出力結果(機械翻訳ならば別の言語での翻訳文)を右側のDecoderに入力し、Encoder の結果を合わせてデータが次々と処理されます。
自然言語のような単語の順番の情報を活用したRecurrent Neural Networkでは、文章を頭から(文末から)順番に処理して時系列情報を活用します。一方、Transformerでは、そのような単語間の情報はPosition Embeddingという操作で埋め込み、文章を全体を一度に処理してしまいます。RNNでは、前の単語を処理しないと次の単語の処理ができませんが、Transformerではそのような遅延はなく、一度に文章が処理できるためRNNよりも高速な計算が可能です。このTransformerにより、従来のRNNベースのモデルよりも非常に高い精度のベンチマークが叩き出されました。
BERT
Transformer発表後、Attentionを用いた自然言語処理研究が活発になり、様々な高精度のモデルが提唱されました。その1つがBERT [arXiv:1810.04805] です。BERTとは Bidrectional Encoder Representations from Transformers の略で、その名の通り、双方向性とTransformerを特徴とします。
BERTの構成は以下のようになっています(以下の図はBERTの元論文よりの引用です)。ここのTrmというのは、先ほど紹介したTransformer の Encoder 部分です。BERT-BASEモデルで12層、BERT-LARGEモデルで24層をもTransformerを重ね、LARGE版では約3億のパラメータを持つ巨大なモデルとなります。
また、通常の言語モデルでは、前から順番に単語を読み込み、次の単語を予測して文章を組み上げます。一方で、BERTの場合は、文章の情報を双方向的に同時に使用するため文脈をより精度よく処理できると期待されます。

BERTのモデルの学習は2段階に分けられます。
1.まず、文章の一部をマスクして、そこに現れる単語を予測(Masked Language Model)と、2つの文章が意味の通る順序で並んでいるか否かを判定(Next Sentence Prediction)という2種類のタスクで予備訓練します。
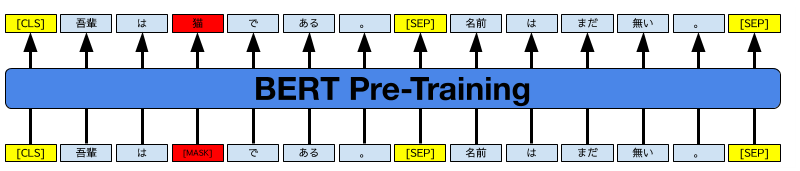
BERTのpre-trainingの概念図。[CSL]は文頭、[SEP]は文章の区切りを表す特別なトークン。[MASK]された単語を予測したり、2つの文章が論理的につながるか否かを学習する。
これらの予備訓練により、文章中の自然な単語の出現確率、そして2つの文章の繋がりを学習することができます。
2.次は、目的となる個別のタスクごとにモデルを学習します。例えば、The Stanford Question Answering Dataset (SQuAD)では、Wikipediaのパラグラフと質問を与えて、正解となる返答を返す問題です。
BERTはGLUEのベンチマークテストにおいて、当時、非常に高い精度を発揮し、一部のスコアは人を超えるなど、自然言語処理研究で大きなインパクトを与えました。つい最近では、Google検索にもBERTが導され検索精度が改善されています。
https://wired.jp/2019/11/14/google-search-advancing-grade-read
ちなみに、Transformerの様々な学習済みモデルを簡単に取り扱えるようにまとめている transformers というPyTorch(とtensorflow)のpython libraryで日本語の学習済みモデルも含まれました。
これを使うと上記のデモは実際に
#!pip install transformers
# Install MeCab for Google Colaboratory
#!apt install aptitude
#!aptitude install mecab libmecab-dev mecab-ipadic-utf8 git make curl xz-utils file -y
#!pip install mecab-python3==0.7
import MeCab
import torch
from transformers.modeling_bert import BertForMaskedLM
from transformers.tokenization_bert_japanese import BertJapaneseTokenizer
tokenizer = BertJapaneseTokenizer.from_pretrained('bert-base-japanese-whole-word-masking')
model = BertForMaskedLM.from_pretrained('bert-base-japanese-whole-word-masking')
model.eval()
input_ids = tokenizer.encode(f"""
吾輩は{tokenizer.mask_token}である。{tokenizer.sep_token}名前はまだない。""",
return_tensors='pt')
masked_index = torch.where(input_ids == tokenizer.mask_token_id)[1].tolist()[0]
result = model(input_ids)
result = result[0][:, masked_index].topk(5).indices.tolist()[0]
for r in result:
output = input_ids[0].tolist()
output[masked_index] = r
print(tokenizer.decode(output))
出力結果は以下の通りです。
[CLS] 吾輩 は 猫 で ある 。 [SEP] 名前 は まだ 無い 。 [SEP]
[CLS] 吾輩 は 犬 で ある 。 [SEP] 名前 は まだ 無い 。 [SEP]
[CLS] 吾輩 は 狼 で ある 。 [SEP] 名前 は まだ 無い 。 [SEP]
[CLS] 吾輩 は 人間 で ある 。 [SEP] 名前 は まだ 無い 。 [SEP]
[CLS] 吾輩 は 私 で ある 。 [SEP] 名前 は まだ 無い 。 [SEP]
確かに、ここで最も自然な単語(?)である「猫」が最有力候補として推奨されていることが分かります。
ニュース・トピックと学習
長い前置きとなりましたが、具体的にBERTの応用として、ニュース・トピックスによる指標予測をしたいと思います。
BERTの学習済みモデルを利用した分類問題のコードは、こちらの記事を参考にさせていただきました(http://mccormickml.com/2019/07/22/BERT-fine-tuning/)。ここでは、要点となるコードのみを紹介します。なお、今回の解析では主にGoogle Colaboratoryを用いました。実行時間などの制限はありますが、GPUやTPUを気軽に利用できる点がよいですね。
データ準備
まずは、データ・セットはUCI Machine Learning Repository (https://archive.ics.uci.edu/ml/datasets/News+Aggregator) より、2014/3/10-2014/8/10までのニュースについてのデータを以下によりダウンロードします。
import tensorflow as tf
import pandas as pd
path_to_zip = tf.keras.utils.get_file('NewsAggregatorDataset.zip', origin='http://archive.ics.uci.edu/ml/machine-learning-databases/00359/NewsAggregatorDataset.zip', extract=True)
df = pd.read_csv(os.path.join('/root/.keras/datasets', 'newsCorpora.csv'), sep='\t', header=None, names=['id', 'title', 'url', 'publisher', 'category', 'story', 'hostname', 'timestamp'])
df['timestamp'] = pd.to_datetime(df['timestamp'], unit='ms')
df = df.sort_values('timestamp')
df = df.groupby('story').first().reset_index().sort_values('timestamp')[['title', 'category', 'timestamp']]
これらはニュースが発表された時間やカテゴリなどの情報が付加されており、総数では422,937件のデータがあります。ただ、そのままでは重複する内容もあり、後のモデル学習も大変ですので、ストーリーIDでデータを7,230件に絞っておきます。また、タイムスタンプもUNIX time なので、適宜前処理をしておきます。
以下は、このデータのサンプルになります。

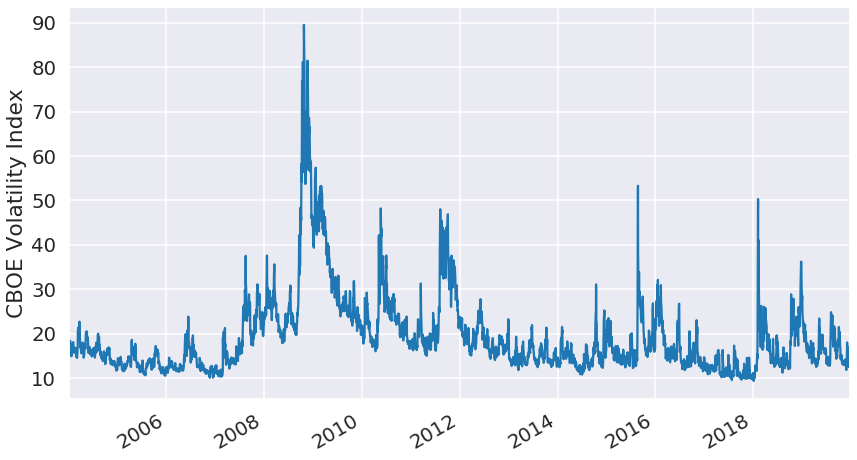
次に、経済指標として今回はCBOE Volatility Indexを使ってみようと思います。これはS&P500のオプション価格から計算されるvolatility(価格変動の大きさ)に基づく指標で、別名「恐怖指数」とも呼ばれ相場の不安定さを反映すると言われています。
このデータはCBOEのweb site より以下のように、日足のデータをダウンロードしておきます。
#!wget http://www.cboe.com/publish/scheduledtask/mktdata/datahouse/vixcurrent.csv
df_vix = pd.read_csv('vixcurrent.csv', skiprows=1)
df_vix['Date'] = pd.to_datetime(df_vix['Date'])
VIXの時系列データをプロットしてみると以下のようになります。2008年の終わり頃にひときわ際立ったピークが見えますね。これはサブプライム・ローン問題に端を発する世界金融危機の時のものです。
ここで先ほどのニュース・データ・セットとVIX Highの値を結合し、翌日にVIXが上昇するか下降するかのラベルを付加して機械学習用のデータとします。
df['Date'] = pd.to_datetime(df.timestamp.dt.date) df_vix_close = df_vix['VIX High].reset_index() df_vix_close['label'] = df_vix_close['VIX High’].diff().apply(np.sign) df_news_set = pd.merge(df, df_vix_close[['Date', 'label']], on='Date', how='left') df_news_set['label'] = (df_news_set['label'] > 0).astype(int)
BERTによるテキスト分類
次にBERTの学習済みモデルを用いて、上で準備したテキストの経済指標へのインパクトを学習させ分類したいと思います。既に紹介していますが、Hugging Face Transformers (https://huggingface.co/transformers/index.html)で、公開されている学習済みモデルを利用します。文章の分類問題を解くためのモデルは以下のようにして準備します。
from transformers import BertForSequenceClassification
model = BertForSequenceClassification.from_pretrained('bert-base-uncased',
num_labels=2, output_attentions=False, output_hidden_states=False)
そして、先ほど準備したニュース・トピックとVIXへのインパクトのデータ・セットを学習させてみました。5エポックほど学習させてみましたが、訓練データのロスは減少するものの、検証用データセットでの精度は0.6程度で、訓練を進めても殆ど改善されませんでした。

最近の発展について
Transformerは2年以上前、BERTは1年前に発表された当時最先端のモデルですが、それからの研究は飛躍的に進んでいます。BERTの学習方法を改良した、RoBERTa [https://arxiv.org/abs/1907.11692] や ALBERT[https://arxiv.org/abs/1909.11942]といったモデルの他にも、GPT-2[https://github.com/openai/gpt-2], XLNet[https://arxiv.org/abs/1906.08237], T5[https://arxiv.org/abs/1910.10683]、ERNIE[https://github.com/PaddlePaddle/ERNIE]、MT-DNN[https://github.com/namisan/mt-dnn]と自然言語処理モデルの発展は目まぐるしく、GLUEのLeaderboardのランキングも頻繁に入れ替わっています。
BERTやGPT-2 などではTransformer-EncoderやTransformer-Decoderを基礎に持ちますが、最近の研究(T5)では、Transformer Encoder-Decoder の構造を活用することも新たな流れになっているようです。また、BERTなどはpre-trainingしたモデルをそれぞれのタスクに合わせてfine tuning しますが、一つのモデルで多様なタスクを解くことができるモデルの開発も進められており、その応用はますます目が離せないです。
最後に
次世代システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧からご応募をお願いします。
一緒に勉強しながら楽しく働きたい方のご応募をお待ちしております。
参考資料
- UCI Machine Learning Repository
https://archive.ics.uci.edu/ml/index.php - Tensorflow 公式資料
- Text classification with TensorFlow Hub
https://www.tensorflow.org/tutorials/keras/text_classification_with_hub - Word embeddings
https://www.tensorflow.org/tutorials/text/word_embeddings - Neural machine translation with attention
https://www.tensorflow.org/tutorials/text/nmt_with_attention - Transformer model for language understanding
https://www.tensorflow.org/tutorials/text/transformer
- Text classification with TensorFlow Hub
- Hugging Face Transformers
https://huggingface.co/transformers/ - GLUE (The General Language Understanding Evaluation)
https://gluebenchmark.com/ - 深層学習による自然言語処理(MLP機械学習プロフェッショナルシリーズ)
- 自然言語処理のための深層学習(共立出版)
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD