2022.07.08
非構造データから知識グラフを構築するための自然言語処理
はじめに
こんにちは、グループ研究開発本部 AI研究開発室のC.Wです。
前回の記事ではニュースデータから知識グラフの構築まで一通り作成しましたが、出力した知識グラフがノイズまみれでクオリティが悪く、知識まで至るようなグラフではなかったです。原因としては自然言語処理のところに工夫をしていなく、Garbage in, garbage outだからだと思っています。知識グラフ作成のそもそもの目的としては「知識がわかる」ことなので、今回は前回の延長線として色んな自然言語処理の手法を使って知識の精製(purification)をしていきたいと思います。
問題点(おさらい)
前回の結論では有意義な知識グラフになっていないということですが、具体的に何故有意義になってないのかをグラフで見ながら考察したところ、以下の数点の問題点を発見しました。
- 個体に繋がらない代名詞が認識されていて、グラフ上のHubとなっている
- 例:Minister, President
- 同じ名前の個体でも違うEntityに認識されている
- 例:Ukrainian(ORG: 組織), Ukrainian(PER: 人物)
- 抽出された単語の中で類似しているものが多い
- 例:Russia, Russias
- 長文だと推論モデルに入らない
- モデルの入力制限が512トークン(≒単語)
- 意味深い繋がりがなかった
データの増加
上記の第5点の「意味深い繋がりがなかった」から取り上げますが、こちらについては自然言語処理の問題よりデータ自体の問題が大きいと思っています。主な原因としては、前回はnewsAPIからのレスポンスを直接使っていて、記事データとして使っているのはレスポンスの中のcontentコラムです。ただ、こちらのcontent内では記事の前文の数100文字しか掲載されていなく、newsAPIの公式ドキュメントではこちらのように明記していて、記事のfull contentは実はレスポンスとしては送ってこないです。
なので、今回はnewsAPI公式ドキュメントで紹介されているやり方でクローリングしてfull contentを取得しています。しかしニュースのソースごとに文章抽出のcss selectorの設計が必要なのと、クローリング禁止や有料コンテンツとなっているところも多いので、幾つかのソースに絞ってfull contentの取得をしています。この結果を使って前回の結果と見比べるために、取得しているデータが元データと大きなバイアスが出てるかどうかについて軽くEDAして検証しました。
なお、文章が長くなることにより、モデルに一発入らない問題
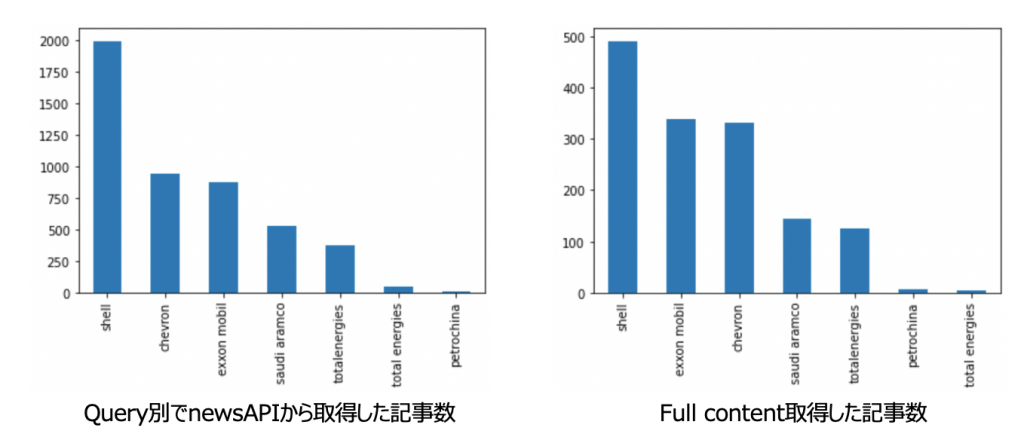
キーワード(Query)ごとの記事数
newsAPIから取得しているキーワード( Exxon Mobil, Saudi Aramco, Chevron, Shell, Petrochina, Total Energies)のキーワードごとの記事数については、以下の画像が示している通りです。全体の割合としてShellから取得している記事の割合が減っているのを見えますが、全体を影響するような結果ではなく大きな変化は見えていないです。
記事内単語のワードクラウド
newsAPIから取得しているcontentと実際にニュースサイトで掲載されているcontentのワードクラウドも作って比較をしました。以下の画像が示している通りです。左がAPIのレスポンスcontentで右がニュースサイトから取得したcontentとなりますが、内容的に結構違う傾向が見れています。左の画像では記事の前文の数100文字とのことなので見出しに近い存在かと思って、キャッチーなキーワード(i.e. invasion Ukaraine , Russia)とかが見えますが、右の方は叙述的なキーワード(i.e. company, said, well)が出ています。見出しに近い前文と全文の違いを考えるこの違いは想定内の違いかと思っています。

非構造データから知識抽出の問題点
上記の他の問題点については、データを増加した後更に問題になりうる可能性が大きいと思うので、問題を再度整理して今での自然言語処理のプロセスについて考え直していきたいと思います。考察が始まる前に、大前提として今回使う自然言語処理のタスク:Named Entity Recognition、Relation Extractionの現状を2つ先に同期します。
- ある単語に物理的距離が近いほど関係性が理解しやすい
- これは例えばAttention系のモデルによってある程度解消される問題ではありますが、unsupervisedの事前学習モデルはのモデルは影響されなくても、タスクに特化する時のFine-tuningの時は大きく学習データに左右される。こちらで使うNER(Named Entity Recognition)やRE(Relation Extraction)では正しくannotateされているデータはほぼ分かりやすい短文。
- 代名詞の扱いが得意ではない
- 長文になると人が書く文章には代名詞を使って前の句のある物を指している場合が多いが、機械ではこういう処理は得意ではない。前記1の物理的距離の原因も一つだが、もう一つは同じく学習データの問題です。代名詞が多く出てくる場面としては、Twitterのツイートや会話の様な生活感が強く文法もあまり気にする必要がない場面です。今のNERとREのタスクではそういう学習データがオープンデータとしてよく整備されているものはないです。
問題点1:個体に繋がらない代名詞が認識されていて、グラフ上のHubとなっている
これはNER(Named Entity Recognition)の困難点でもあり、人が書いている文章を機械が認識をするための問題だと思っています。NERとは、概念的に言うと文章全体を理解しながら単語にEntityがあるかどうかを判断しつつ抽出するプロセスです。それでEntityを判断する作業ですが、今回のタスクでは語句ではなく文章となると語句の間を跨ぐ認識が上手くできなく、例えば: “That is my house. I lived in there. “の2句だとthereが場所と判断されがちな状況になっています。
そこを解決するために今回試したものはCoreference Resolutionという手法です。Coreferenceとは2つ以上の表現が同じ人または物を参照している状況を指しています。Coreference ResolutionとはCoreferenceを文章内から探し出す様な自然言語処理タスクです。
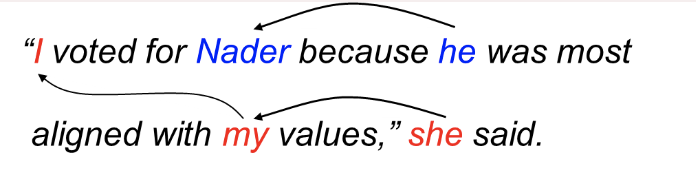
Coreference resolutionのイメージ (Standford NLP Lab)
問題点2:同じ名前の個体でも違うEntityに認識されている
これは間違いとは言えない状況ですが、知識抽出の視点としては望ましくない状況です。文章や文法によって確かにEntityは変化しますが、それは全知識グラフとして残すのかというと違うのかと思っています。なので今回の解決法としてはVoting的なやり方で、全文章から抽出した同じ名前を持つEntityに対して、認識されたEntityの回数が一番多いEntityを該当名前のEntityとして扱います。
問題点3:抽出された単語の中で類似しているものが多い
自然言語処理でよくある問題ですが、時制(tense)や複数形(plurals)などの単語を同じく認識するために、今回はStemminの手法を使ってstem wordをEntityとして抽出します。ここで注意すべき点としては、学習のデータでは生データを使っていてstem wordではないため、NER/REモデルで推論する時も生文章のままで推論して、後処理でEntityをstem wordに変換する処理をしています。
問題点4:長文だと推論モデルに入らない
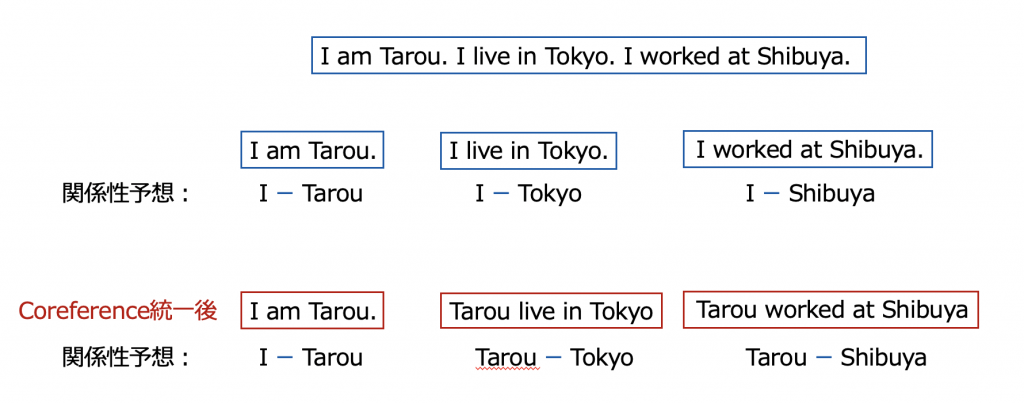
今回使っているモデルのPFNはEncoder – Decoder形式で、ALBERTをEncoderとして使っています。なので入力文字数は512トークンと制限されています。これを解決するために文章を分割されざるを得なくなりますが、如何に分割後でも意味を保つのが工夫点となります。自然言語処理のタスクによって分割していいかどうかに分かれています。例えば会話やQAなどのタスクでは長文の情報は必要性が低く、文章を分割しても大きな影響は出ないですが、例えば文章要約などのタスクでは文章の分割をすると全く意味のない結果を出してしまうこととなります。そこで今回のタスクを考えると、関係性を抽出するに辺り文章分割する問題とは何かというと、問題点1と同じく代名詞など語句外の情報を取り込んでいる様なことです。
少し理想すぎな話になりますが、この現象はモデル推論をする前にCoreference Resolutionで単語の統一をすれば下記の様に解消できるのかと思います。
コード
さて、それぞれの解決方法を加えると全体的にどの様なプロセスになるかを整理しと、一つ一つ紹介して行こうかと思います。全体の流れは以下の様になります。下記の内容の内、文章(データ)の取得とNER/REモデル(PFN)は前回の記事で詳細を記載しているため、今回は割愛とさせてください。
文章(データ) → 1. Coreference ResolutionでCoreference統一 → 2. NER/REモデル(PFN) → 3. Entity Voting → 4. Stemming
Coreference ResolutionでCoreference統一
from allennlp.predictors.predictor import Predictor
def correference_transform(result, longest_represent_len=3):
for cluster in result['clusters']:
standard_idx = cluster[np.array([(x[1] - x[0]) for x in cluster]).argmax()]
if (standard_idx[1] - standard_idx[0])>(longest_represent_len - 1):
continue
standard = ''.join([result['document'][x].capitalize() for x in range(standard_idx[0], standard_idx[1]+1)])
for corref_idx in cluster:
result['document'][corref_idx[0]] = standard
if corref_idx[1]==corref_idx[0]:
continue
for other in range(corref_idx[0]+1,corref_idx[1]+1):
result['document'][other] = ''
return ' '.join([x for x in result['document'] if x])
predictor = Predictor.from_path("https://storage.googleapis.com/allennlp-public-models/coref-spanbert-large-2021.03.10.tar.gz")
correferenced_sentence = []
for sentence in tqdm(sentences):
res = predictor.predict(document=sentence)
correferenced_sentence.append(correference_transform(res, longest_represent_len=3))
今回のCoreference Resolutionで使っているのはAllenNLPが提供しているものです。流れとしてはまずCoreferenceを探し出して、一番長い単語を代表単語として全ての単語の使っています。しかい実際にモデルで出す出力ではすごく長いcoreferenceも存在しているため、マジックナンバーとなりますが、連続3単語以上からcorreferenceと認定されたものは排除しています。
Entity Voting
df_entity = pd.DataFrame(entity_list, columns=['name','entity'])\
.groupby(['name'], as_index=False)\
.apply(lambda x: pd.Series({
'entity': x['entity'].value_counts().index[0]
,'count': len(x)
})
)\
Stem nameに対してEntityの種類の集計を行い、一番多く認識されたEntityを代表Entityにします。
Stemming
from nltk.stem.porter import PorterStemmer
ps = PorterStemmer()
df_entity = df_entity.assign(stem_name = lambda x: x['n_name'].apply(lambda y: ps.stem(y)))\
.assign(stem_entity = lambda x: x['entity'])
こちらではnltkのPorterStemmerを使ってStemmingをしています。One linerでできる使い勝手のいいStemmingツールです。
結果
同じくneo4jに落とし込み可視化を見てみました。ざっくりなところ前回と比べそんなに違いがない感じがしていますが、細かい内容を見てみましょう。

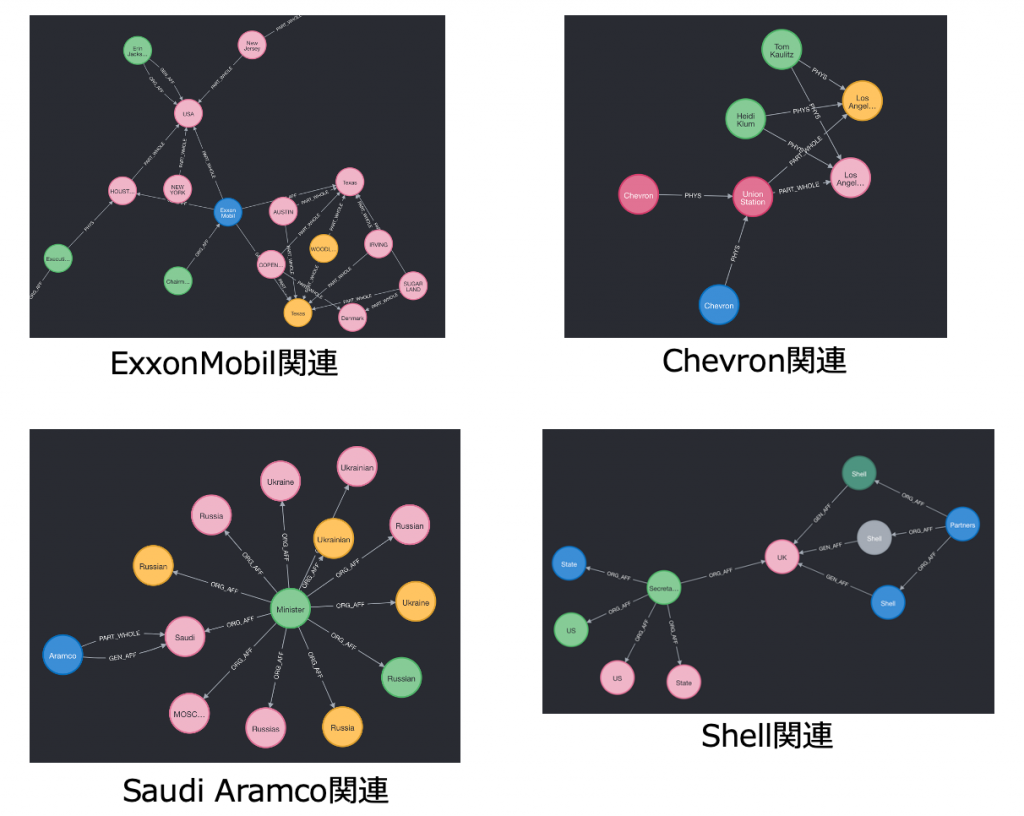
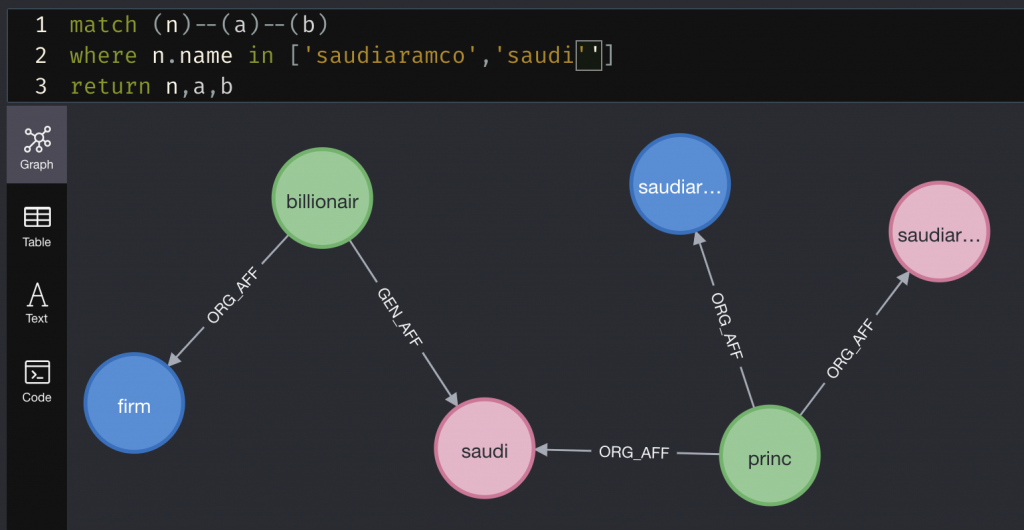
まずキーワードとなった企業を見ていくと、すごい(誰もが知っている)事実を発見しました。SaudiAramcoはサウジアラビアの王子の企業で、彼は億万長者です。これを見るとなんとなく抽出してそうな気がしていて、前回の結果より少し解釈性が多くなっているのが分かります。
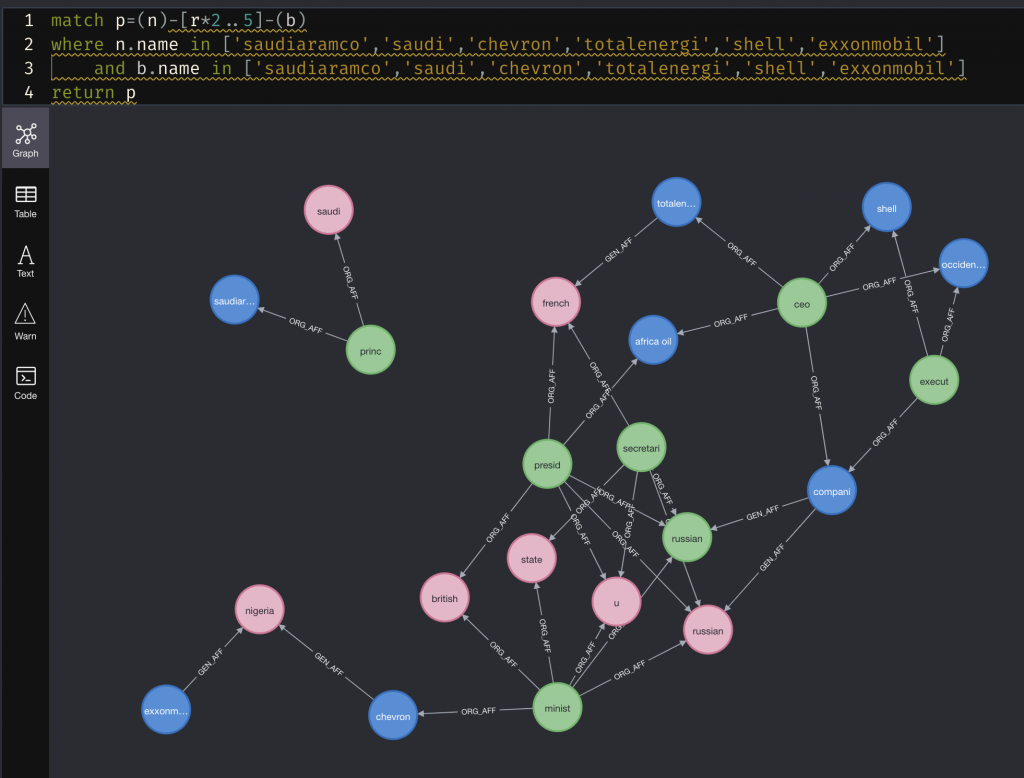
更にキーワードに入っている企業をノードとして、企業間の関連を3step(3ノード経由)で表す全体図を見ると、以下の様な感じとなります。お馴染のceoやpresident (stem word: presi)はやはり入っていますが、ノードが純化されていることによって可読性はだいぶよくなっています。あと面白かった話としてはchevronとexxon mobil(画像内左下)が同じくナイジェリアに関係していることが分かりました。単純にGoogle検索で検索しても中々出てこない関係性なので、ある程度の知識が内包されていると感じ始めています。
まとめ
今回は非構造データから知識グラフ構築のための自然言語処理を問題の洗い出しから解決方法の設計までもう少し突き詰めました。有意義な知識グラフの構築はやはり難しいタスクだと改めて感じています。ただ普段見えない様な情報も実際に見え始めてきて、この領域の専門家らしき挙動を出し始めたので個人的にはすごくワクワクしています。次回ももう少し違う角度で深めていきたいです!
最後に
グループ研究開発本部 AI研究開発室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務などAI研究開発室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD