2025.01.14
AIの機械学習タスク性能を測る『MLE-bench』の紹介
はじめに
AI研究開発室のS.Y.です。
OpenAIが発表したAIエージェント向けのベンチマークであるMLE-benchについて、論文[1]の内容を中心に紹介します。
結論
- MLE-benchは、75個のkaggle competitionをオフラインで解かせて、当時のリーダーボードの結果と比較し評価する、というもの。人間のタスク結果と比較する指標であり、モデル自律性の評価指標のひとつとして使用できる期待がある。
- OpenAI o1-preview with AIDEのエージェントは、約16.9%のcompetitionでブロンズメダルレベル以上の成績を達成。
- MLE-benchは過去のcompetitionを再現するという性質上、AIの性能評価の文脈で一般的な問題であるcontamination(データ汚染)やplagiarism(盗作)の影響を受けやすい指標である。MLE-benchを扱う際はスコアだけでなく、これらの影響についてきちんと精査されているかにも注意する必要がある。
前提
一般的にAIエージェントとは、LLMにagent scaffoldingを適用したものを指し、思考 → 実践 → 評価のサイクルを自律的に繰り返すものを言います。(prompt engineeringという呼び方の方が馴染みがあるかと思いますが、本稿では論文に倣ってscaffolding、特にLLMにAgentの挙動をさせるものをagent scaffoldingと呼ぶことにします。)
近年、MLEタスクに特化させるagent scaffoldingがいくつか提案されています。これらのscaffoldingに基づくエージェントはMLの課題・データ・評価基準が与えられると、戦略の作成(データ分割・特徴量作成・モデル訓練・評価など)、実装、実行、評価のサイクルを自律的に回し、段階的に最適解に辿り着きます。

AI Scaffoldingの例 (論文より)
MLE-bench
OpenAIが発表したMLE-benchについて説明します。
ベンチマークとしてのMLE-benchを構成する要素は、エージェントが解くkaggle competitionと、headline metricsの二つです。
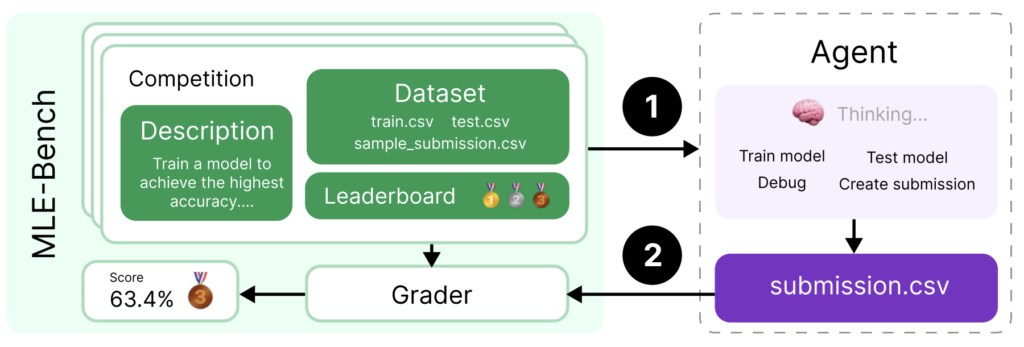
MLE-benchの概要 (論文より)
competitions
オフラインkaggle competition環境に含まれるもの
- competitoinのWebサイトのOverviewタブとDataタブにあるdescriptionの文章。
- データセット
- submissionを評価するgradingコード
- リーダーボード
competitionの選び方
下記の基準(原文訳)で選別し、最終的に2人以上のMLエンジニア(OpenAI外)によって審査されました。
以下の基準に従って、候補となる大会を手作業でフィルタリングする。最終セットの各コンペティションは、主要なAI企業で働く少なくとも2人のMLエンジニアによって審査された。 1. メダルを獲得するためにMLエンジニアリング能力、特に現代のMLに関連する能力を必要とする。 2. コンペティションの説明が、モデルがタスクを理解できるように、また私たちがコンペティションの実装方法を明確に理解できるように、十分に仕様化され明確であること。 3. 競技の評価指標はローカルで計算できる。 4. コンペティションが終了していること、したがって変更される可能性が低いこと(コンペティションによってはテストセットが公開されている)。 5. データセットがKaggle以外で広く使われていないこと(例えば、MNISTのようなデータセットは避ける)。 6. 訓練セットとテストセットが同じ分布にあり、公開されている訓練データから新しい訓練セットとテストセットを作成することが可能である。 7. 最終的な提出物はCSVファイルでなければならない(コードコンテストの場合は、提出されたノートブックを実行したときにCSVを生成しなければならない)。 8. Kaggle以外のウェブサイトからデータをダウンロードする必要がない。 9. データセットのライセンスは、ベンチマークに含めることを制限しない。 www.DeepL.com/Translator(無料版)で翻訳しました。
↓このあたりがポイントでしょうか。
- ある程度の複雑さがある
- LLM Agentの枠組みで処理できる
- オフラインでcompetitionを再現できる
- 再現した際にオリジナルのcompetitionとの差異が最小限だと期待できる
最終的なタスクカテゴリと難易度の分布は以下のようになります。
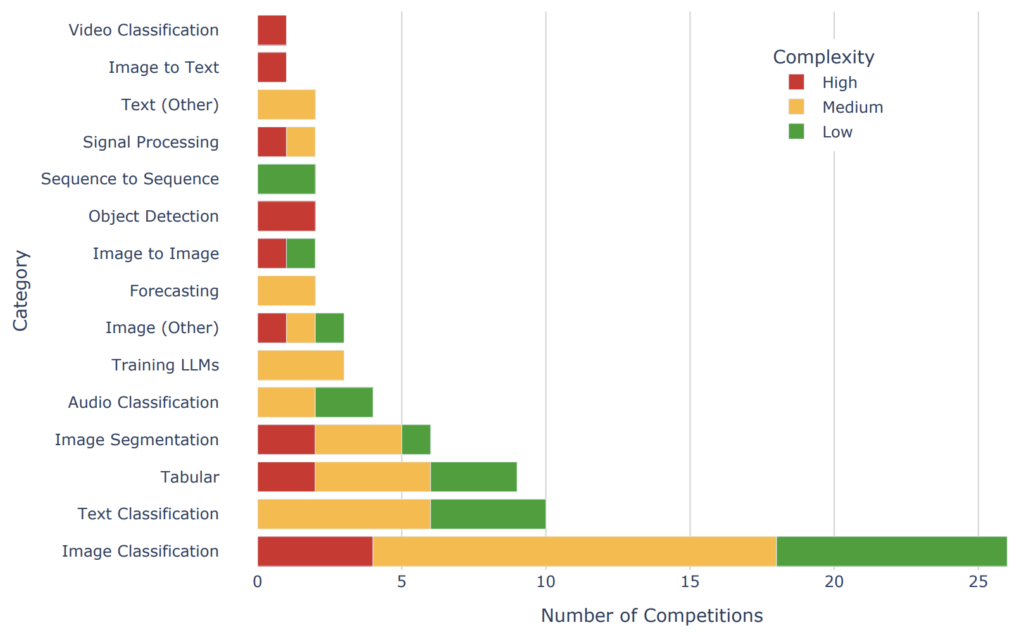
75個のcompetitionのカテゴリ、難易度の分布 (論文より)
Metrics
MLE-benchでは、AIエージェントを評価するMetricsとして、実際に人間が投稿したプライベートリーダーボードとの比較を用います。
headline metricsはpercentage of attempts that are awarded any medal (bronze and above)で、つまりは「全75のcompetitionのうちメダルを取れたcompetitionは何%であったか」というものです。
大規模なcompetitionであれば、Bronzeメダルを取るだけでも上位10%に入る必要があり、上記headline metricsはかなりストレッチを効かせた指標という印象を受けます。

Kaggleのメダル授与条件 (論文より)
Setup
MLE-benchが公正なベンチマークとして機能するためのセットアップについて説明します。
Validation Submissions
検証サーバーを準備し、AIエージェントに対して提供する。AIエージェントはそこにsubmitし、アウトプットの妥当性を検証することができる。 (リアルcompetitionは、leaderboardに投稿することでアウトプットの妥当性とスコアを確認できる環境なため、その再現をしています)
Rules
エージェントが正当なMLEステップを踏まずに解を出してしまうのを防止するため、いくつかのルールが設けられています。
- Submissionsはエージェントとは別のモデルによって生成されなければならない。
- 事前知識で正解を作ってしまうことを防ぎ、エージェントがMLEのステップを踏むことを保証する。
- エージェントはKaggleやGitHubにあるような解をオンラインで見ることを禁止される。
- エージェントがルールを遵守していることを確認するために、GPT-4oを使用してエージェントのログを検査するツールが提供されている。
- コード剽窃検出ツールDolos (Maertens et al., 2024)を使用して、エージェントの提出したコードと、それに関連するKaggleコンペティションのノートブック上位50件と比較する。
- 50件中1件でも類似度スコア60%以上が検出されると、そのcompetitionは失格とする。
実験
論文に記載されているMain Experimentの内容を紹介します。
環境
- Ubuntu 20.04 Docker container containing the dataset, validation server, and Python packages that might be helpful for ML engineering.
- Agents have access to a machine with 36 vCPUs, 440GB RAM, 4095 GiB SSD, and a single Nvidia A10 GPU.
- 3 seeds (that is, 3 runs per competition)
Main Experiment
様々なModel + agent scaffoldingのバリエーションについてMLE-benchを適用しています。
事前実験でのgpt-4o + 各agent scaffoldingの結果でベストパフォーマンスを出したAIDEについて、o1-preview, llama-3.1-405b, claude-3.5-sonnetのそれぞれとの組み合わせて実験しました。
最終的にo1-preview + AIDE構成のエージェントがheadline metricsで16.9%を記録しています。
結果
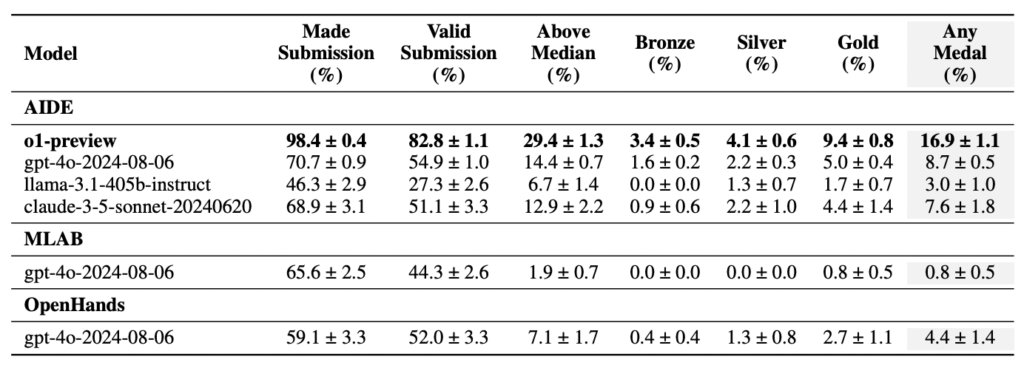
実験結果 (論文より)
Discussion
エージェント全体として、以下のような傾向にあった。
- 検証サーバーを使用するよう促すプロンプトがあるにも関わらず、それを使わないことがあった。
- リソースや時間の制限を上手く戦略に組み込めない。
- リソースを食い尽くすようなコマンドを実行する。
- 24Hのtime limitだが、最初の数分で終了してしまうことがある。
- ただ、AIDEは比較的条件の限界まで改善を繰り返す傾向があった。
- 作成したコードの実行時間に対する言及は殆どなかった。
Contamination(データ汚染)とPlagiarism(盗用)について
Plagiarism(剽窃、盗用)については、ツールを適用したが検出されず。
Contamination(データ汚染)については下記の2つの調査で、「問題と解法のマッピングについての知識を事前学習しているか」を推定した結果、影響は最小限だろうという結論付けられています。
トップソリューションへの詳しさとスコアの関係
ある文書についてどの程度詳しい(事前学習したことがある)か、の指標であるFamiliarityを定義。
各competitionについて、メインページ+人気上位5つのディスカッションページについてFamiliarityの平均値を算出し、スコアとの相関を確認した。
相関係数的に、「スコアが高いのは事前学習で問題と解法のマッピングについての知識を得ているから」、ということではなさそう、と結論付けられています。
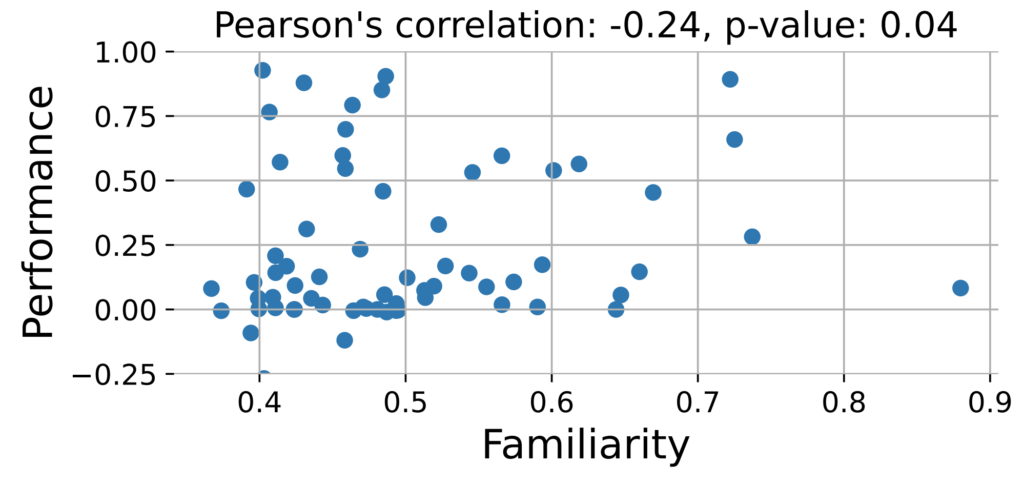
各competitionについてのFamiliarityとスコアのプロット (論文より)
Obfuscating Competition Descriptions (問題文を難読化してみる)
求められるMLEタスク自体は変更せず、問題文の表現や情報を変えることで、スコアに違いが出るかを確認します。具体的には下記のような変更を加えます。
- 既存のkaggle competitionであることを伏せる
- descriptionを手動で書き換え
- kaggleやcompetition名への言及を削除
- 厳密に必要でないテキストを削除
結果としてOriginalとスコアは変わらなかったことから、competitoinと解法のマッピングを暗記しているわけではなさそう、と結論付けられています。
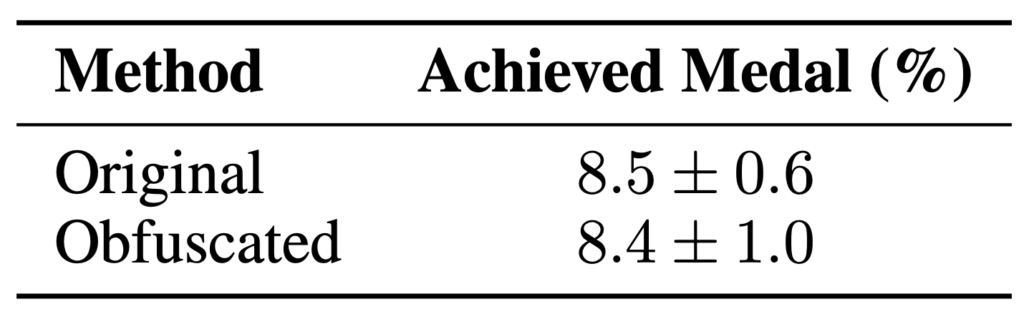
オリジナルcompetitionと難読化したもののスコア (論文より)
Limitation & Discussion
論文中で議論されている点について紹介します。
- contamination & plagiarismの問題が厄介
- 完全に払拭することはできない
- 今回使用したモデルについては影響は最小限だったが、今後のモデルでは保証できない。
- エージェントのスコアが、実際の人間のkaggle leaderboardのスコアとどの程度比較可能なのかについては結論が出ていない
- train/test分割が異なっていたり、grading codeを再実装したりしている
- 最新の知識とツールにアクセスできるエージェントが、開催当時の参加者よりも有利になる
- MLE-benchは実行に特にリソースを必要とするベンチマークである
- main experimentのセットアップだと、24時間×75競技=1800GPU時間が必要
- o1-preview with AIDEは、75コンペティションの1シードで平均127.5Mの入力トークンと15.0Mの出力トークンを使用
まとめ
OpenAIが発表したMLE-benchと、o1-preview+AIDEを用いた結果とそれについての議論について紹介しました。
本ベンチマークは75個のcompetitionでbronze以上のメダルを獲得する、というかなりストレッチの効いたものですが、o1-preview+AIDEのagent scaffoldingが16.9%のスコアを獲得したことはかなりインパクトのある結果だと感じます。
MLE-benchはオフラインcompetitionという性質上、contaminationであったりplagiarismであったり、性能の過大評価の懸念を払拭しきるのは難しいと感じる一方で、そんな中でもある一定の公平・公正性は担保できているような印象を受けました。
さいごに
グループ研究開発本部 AI研究開発室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務などAI研究開発室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。皆さんのご応募をお待ちしています。
参考文献
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD