2021.07.07
BigQuery解説 ~データ登録方法いろいろ~
次世代システム研究室の Y.I です。 Google Cloud Platform (GCP) の B「BigQueryにデータを登録する方法」についてまとめます。GCPで一番知名度のあるサービスはBigQueryなのではないでしょうか。まずはBigQueryにデータを登録しないと集計や分析やMachine Learningを行うことができません。今回は以下のデータ登録方法をご紹介します。
BigQueryデータ登録方法
まとめ
今回のまとめです。
- GCPから多様な手順が提供されている
- GCP以外の環境からデータ登録するのは Embulk がおすすめ
Google Console
GCP の Cloud Console で BigQuery の操作をブラウザから行えます。 SQLを使ってデータを登録したり、csvなどのデータファイルを取り込んでテーブルを作ることができます。
Consoleテーブル作成画面
– Console上でテーブル名、カラム定義やパーティション定義を指定できます。
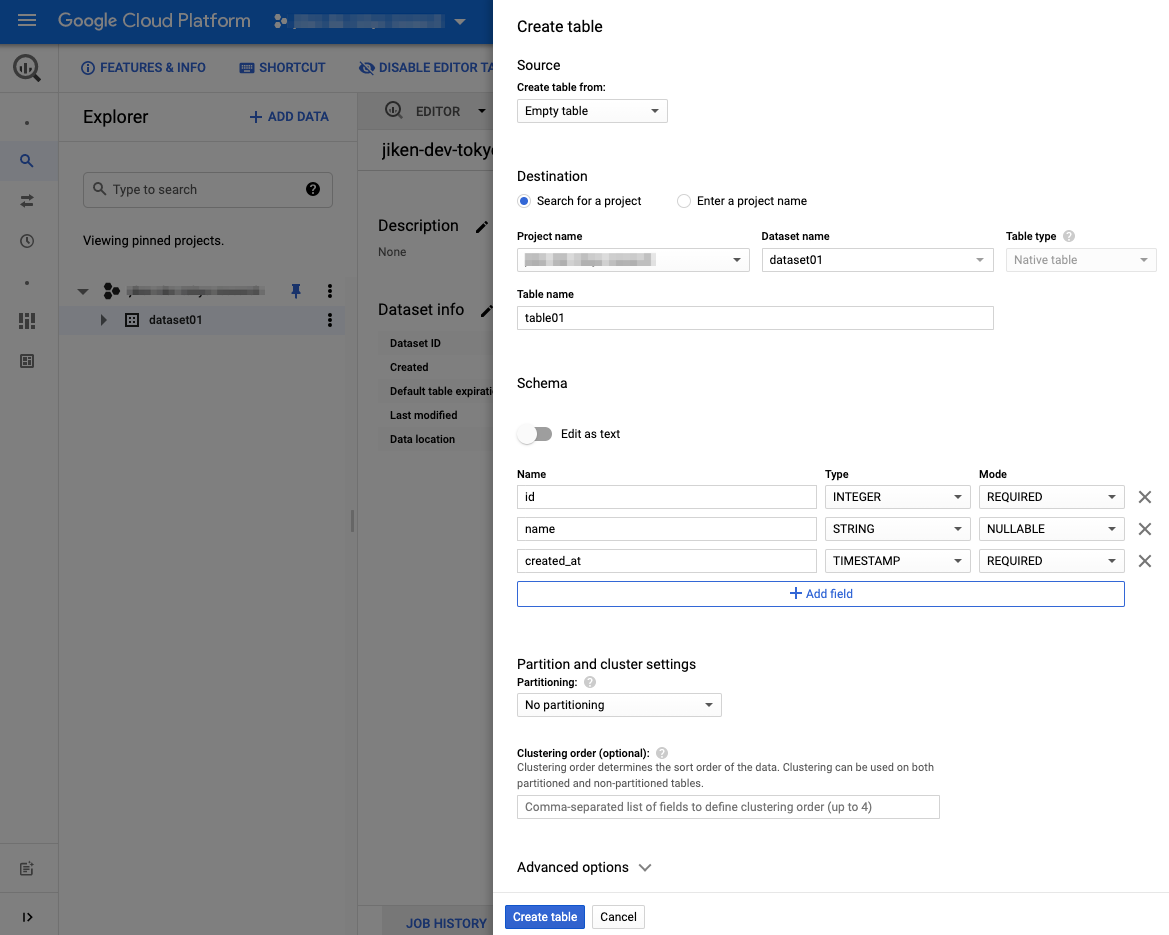
BigQuery Table作成
Console SQLの実行画面
ブラウザ上のConsole画面にてINSERTやSELECTなどSQLを実行することができます。
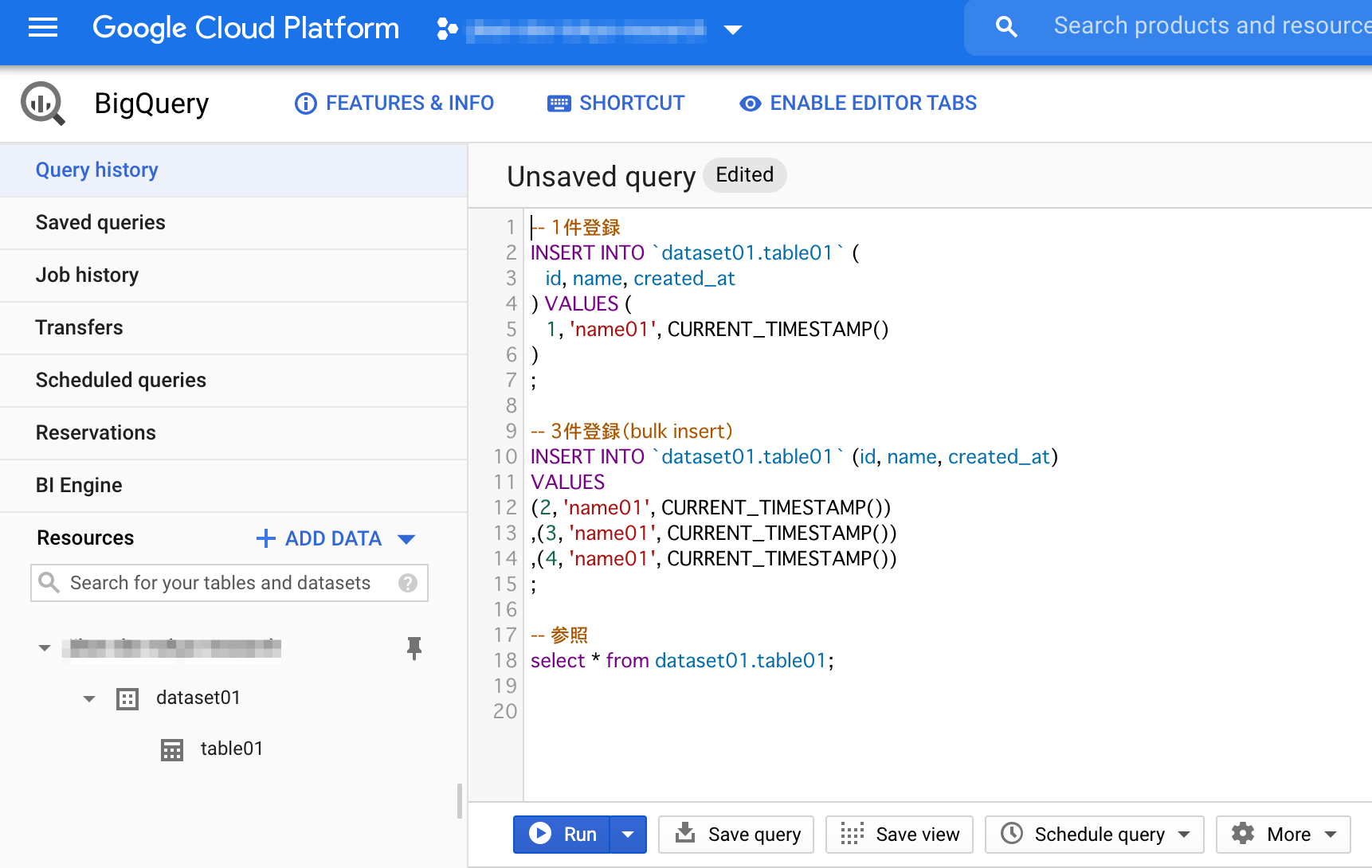
BigQuery Cloud Console SQLエディター
bq コマンド
Google Cloud SDK をインストールすると BigQuery をコマンドラインで操作できる bq コマンドラインツールが使えるようになります。 bqコマンドは SQLによる参照やデータ登録 や csvなどのデータファイルの一括登録 や テーブル作成やテーブル定義参照 など多様なことを実行可能です。
bqコマンドinsert例
- 登録(insert) bq query --nouse_legacy_sql 'insert into dataset01.table01 values (5, "name05", "2021-07-06 08:00:00")'
bqコマンドselect例
- 参照(select/query) bq query --nouse_legacy_sql 'select * from dataset01.table01' Waiting on bqjob_r6dc81f832b179ff5_0000017a7ae33c8a_1 ... (0s) Current status: DONE +----+--------+---------------------+ | id | name | created_at | +----+--------+---------------------+ | 1 | name01 | 2021-07-06 07:14:56 | | 5 | name05 | 2021-07-06 08:00:00 | | 4 | name01 | 2021-07-06 07:19:10 | | 2 | name01 | 2021-07-06 07:19:10 | | 3 | name01 | 2021-07-06 07:19:10 | +----+--------+---------------------+
Google Dataflow
GCP で提供されるマネージドの ETL サービス。 Apache Beamを元に構築されています。利用はテンプレートが用意されて簡単にデータの加工や取り込みが実行できます。Google Console上でプログラミングなしに指定可能です。
テンプレートを利用したDataflow job作成画面
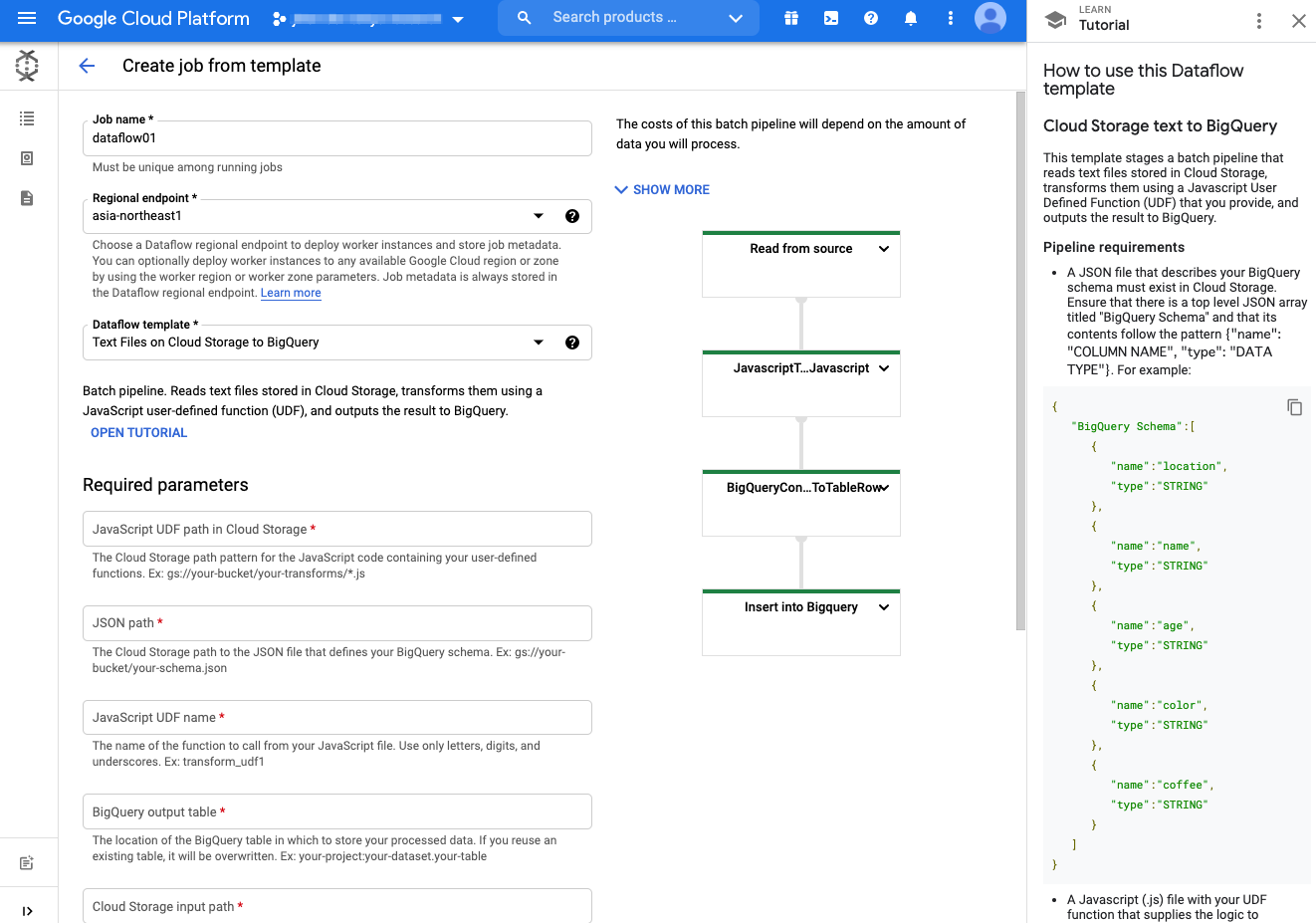
Cloud Dataflow
BigQuery向けのDataflowテンプレート一覧
2021/7現在、Streaming処理やBatch処理向けに以下のテンプレートが用意されています。
- Stream Cloud Datastream to BigQuery Data Masking/Tokenization from Cloud Storage to BigQuery (using Cloud DLP) Hive to BigQuery Kafka to BigQuery Pub/Sub Avro to BigQuery Pub/Sub Subscription to BigQuery Pub/Sub Topic to BigQuery Text Files on Cloud Storage to BigQuery - Batch BigQuery export to Parquet(via Storage API) BigQuery to TFRecords Jdbc to BigQuery Synchronizing CDC data to BigQuery Text Files on Cloud Storage to BigQuery
Google Functions
イベント起動やHTTPアクセスによりサーバーレスで簡単なPythonやJavaなどのプログラムを実行できます。例えばGCS(Google Cloud Storage)にファイルが作成されたら指定の Functions を実行することができるため、ログやデータファイルをGCSにアップロードすることで自動でBigQueryに登録することが可能です。
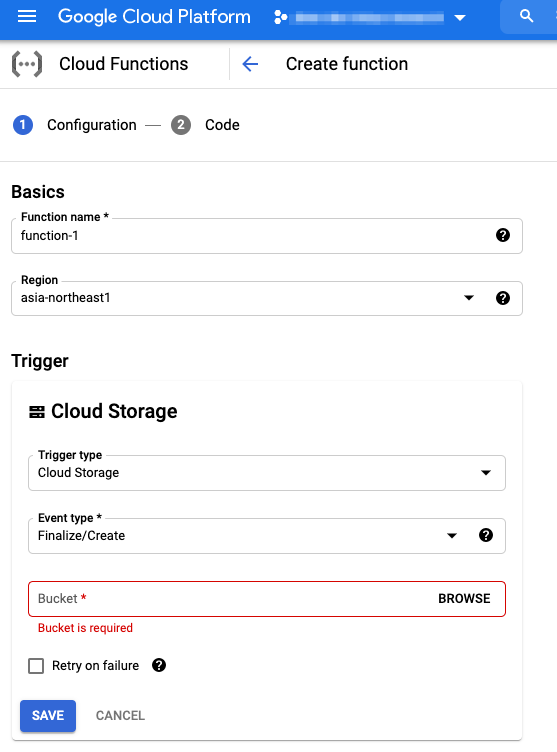
Cloud Functions job設定
Embulk
バッチ処理でデータの参照および登録を行えます。プラグイン形式により多数の参照元/先のデータストアに対応しています。 MySQLなどのRDBMS、RedisなどのKVS、Hadoop HDFSやGCS/S3上のファイルを始め他にも多数対応しています。 今回は担当プロダクトでも使用しているMySQLからBigQueryに登録する方法を紹介します。
embulk手順まとめ
- インストール
- プラグインのインストール (embulk gem xxx)
- schemaファイルの作成 (schema.jsonファイルの作成)
- configの作成 (embulk guess/configファイル作成)
- dry-run (embulk preview)
- 実行 (embulk run)
インストール
curl --create-dirs -o ~/.embulk/bin/embulk -L "https://dl.embulk.org/embulk-latest.jar" chmod +x ~/.embulk/bin/embulk echo 'export PATH="$HOME/.embulk/bin:$PATH"' >> ~/.bashrc source ~/.bashrc
プラグインのインストール
必要なプラグインをインストールします。今回はinputに 「embulk-input-mysql」, outputに 「embulk-output-bigquery」 をインストールします。
embulk gem install embulk-input-mysql embulk gem install embulk-output-bigquery
schemaファイルの作成
BigQueryのテーブル定義をjsonファイルとして用意します。bigqueryプラグインがこの定義を参照します。
[
{
"description": "ID",
"mode": "REQUIRED",
"name": "id",
"type": "INTEGER"
},
{
"description": "名前",
"mode": "NULLABLE",
"name": "name",
"type": "STRING"
},
{
"description": "登録日時",
"mode": "REQUIRED",
"name": "created_at",
"type": "TIMESTAMP"
}
]
configの作成
ymlファイルにてデータの取り込み元(参照元)と登録先(出力先)を設定します。今回はMySQLからselectした結果をBigqueryに登録します。
# in mysqlの参照クエリーを指定
# out bigqueryのschema.jsonやテーブル名などを指定
in:
{% include 'mysql' %}
query: |
SELECT
id
from_name AS name
CAST(DATE_FORMAT(NOW(), "%Y-%m-%d %H:%i:%s +09:00") AS DATETIME) AS created_at
FROM
from_table
WHERE
begin_date <= NOW()
AND NOW() < end_date
out:
type: bigquery
mode: append
auth_method: json_key
json_keyfile: /path/to/key.json
project: {ここにGCP projectidを指定}
dataset: dataset01
table: table01
schema_file: /path/to/schema.json
source_format: CSV
dry-run
リハーサル実行します。設定が正しいか確認できます。
embulk preview /path/to/xxx.yml.liquid
実行
実行は run で行います。設定を記入したymlファイルパスを指定して実行します。
embulk run /path/to/xxx.yml.liquid
参考リンク
BigQuery公式ページ (https://cloud.google.com/bigquery)
Embulk公式ページ ( https://www.embulk.org)
embulk-output-bigeuryプラグイン (https://github.com/embulk/embulk-output-bigquery)
embulk-input-mysql (https://github.com/embulk/embulk-input-jdbc/tree/master/embulk-input-mysql)
最後に
BigQueryにデータを登録する方法は多数ありますが、GCP上のサービスからBigQueryに登録するならばCloud Dataflowでテンプレートを利用するのが簡単でオススメです。GCP以外のサーバーやサービスからからBigQueryに登録するならば多様なデータストアに対応しているEmbulkがオススメです。実際に担当PJで使用していますが問題なく動作しています。
次世代システム研究室では、グループ全体のインテグレーションを支援してくれるアーキテクトを募集しています。アプリケーション開発の方、次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ募集職種一覧からご応募をお願いします。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD