2023.07.07
LLMの言語能力をPrivate Dataに活用するGroundingについて
こんにちは。S.Y.です。
最近の大規模言語モデル(LLM)の進化は目覚ましいですが、LLMを自分のビジネス領域で活用するには、そこで求められるタスクやドメイン固有のデータに対してLLMを特化させる必要があります。
例えばGPT-3/4に、直近の株の値動きの実用的なインサイトを尋ねても、当たり障りのない回答か、幻覚を起こした回答しか返してきません。LLMが金融のスペシャリストと呼ばれるためには、実データに基づき、ユーザーが望むような回答(有価証券報告書中で株の売り買いに影響しそうな項目をピックアップしてわかりやすくまとめる、など)を生成できなければいけません。
専門のLLMを作る一番シンプルな方法はscratchから学習させることですが、それにはドメインのデータを含む巨大な学習コーパスを用意する手間と、多くの計算コストがかかり、一般的には現実的な選択肢ではありません。
LLMを自分の分野に活用するより一般的な方法は、ある程度学習されたpre-trainedなモデルをベースに、いろいろ工夫を頑張ることです。
ここではLLMの活用を、「タスク特化」と「データ特化」に分け、それぞれどのような工夫があるかを解説します。
- LLMのタスク特化: Fine-Tuning
- LLMのデータ特化: Grounding
- Grounding実践: QAシステム
- まとめ
- おわりに
LLMのタスク特化: Fine-Tuning
ある程度の言語能力を備えたLLMを、感情分析のようなタスクに応用したり、特定の出力フォーマット(キャラクター口調など)に調整するには、Fine Tuningする工夫があります。
例えば感情分析タスクに応用したい場合、以下のようなフォーマットのデータをある程度の数用意してNext Token Predictionさせることで、promptの文章に対してpositiveかnegativeかを出力するようになります。
ここで、promptはLLMへの入力、completionは期待される出力です。
{"prompt":"Overjoyed with the new iPhone! ->", "completion":" positive"}
{"prompt":"@lakers disappoint for a third straight night https://t.co/38EFe43 ->", "completion":" negative"}
positiveかnegativeかの判別は、promptの文章の意味に基づいて行われていると考えられます。また、試しにラベルを反転させたり、言語的に意味のないラベル(“1”, “2”など)をつけてみても、LLMは正しく分類を行うことができます。(参考1)
LLMのFine Tuningにおいて、タスクを学習するのに必要となるパラメータ数は、元のパラメータ数より圧倒的に少ないことが知られています。
この性質を利用し、効率的にFine Tuningを行うために、LoRAやP-Tuning等の手法が提案されています。手元にGPU環境があれば、PEFTというPythonフレームワークを使って、公開されているpre-trainedのモデルに対して上記のFine Tuning手法を試すことができます。
また、OpenAIが公開しているFine Tuning APIを使って、GPTモデルのFine Tuningができます。こちらの学習はOpenAI側のプラットフォームで行われ、料金はFine Tuningの学習で消費したトークン数と、Tuningしたモデルを使用する際に消費したトークン数に対してそれぞれかかります。OpenAI Fine Tuning APIは何の手法を用いているのか公開されていなかったり、Tuningに関するパラメータを指定できなかったりと自由度は高くありませんが、とりあえず試してみる分にはお手軽で良いと思います。これで上手くいきそうだったら、本格的にGPU環境を整えていろんな手法やpre-trainedモデルで試してみる、という流れでしょうか。
LLMのデータ特化: Grounding
LLMは学習コーパスにないデータでも、プロンプトに含めてやることでそれに基づいて回答するIn-context Learningの能力があります。例えば、ある文書をプロンプトに含めて、「この文章を要約してください」というプロンプトを投げれば、それなりに要約してくれます。
ただ、殆どのLLMには入力できるプロンプト長に上限があります。また、長い文書をプロンプトに含めることは幻覚の確率を高めることが示唆されています。
Groundingは、エンべディングとベクトル検索を組み合わせ、質問に関係ある文書のみでIn-context Learningさせる工夫です。LLMの中間表現として得られるEmbedding Vectorは、意味が近い文章は、そのベクトル同士の距離が近くなるという性質が知られています。
コーパスの各文書をLLMを介してベクトル化しておき、入力文章のベクトルに近い文書を取得することで、In-context Learningを行います。
これを使って、あるサービスに特化したQAシステムや、巨大なドキュメントを要約するシステムなどが実現できます。
LangChainのフレームワークを使って、Groundingの工夫によってLLMを特定コーパスのデータに特化させる例を見ていきます。
Grounding実践: QAシステム
概要
あるドキュメントについてのQAシステムを考えます。
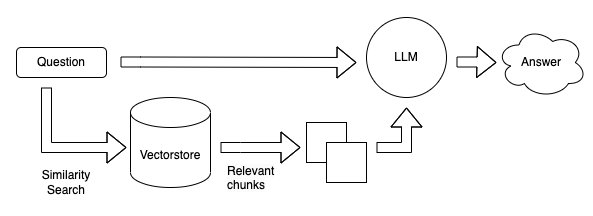
QAの流れは以下の通りです。
- (事前準備) 文書をチャンクに分割する。
- (事前準備) LLMのEmbedding Layerを通じて各チャンクのVectorを取得し、Vector Storeに格納する。
- システムに入力されたQuestionの文章から、LLMのEmbedding Layerを通じてQuestion Vectorを取得する。
- Question Vectorと各Chunk Vectorで類似度を計算し、関連度の高いチャンクを取得する。
- Questionの文章と取得したチャンクの文章の両方を用いたIn-context Learningで、LLMに回答を出力させる。
Langchainでの実装とともに、各ステップを見ていきます。今回は走れメロスに特化したQAシステムを作ります。
Embedding用のLLMモデルにはOpenAI API ada、In-Context Learning用のLLMモデルにはOpenAI davinci、vector storeにはchromaを使用します。
実装
ライブラリインポート
!pip install openai langchain chromadb tiktoken from langchain.document_loaders import TextLoader from langchain.indexes import VectorstoreIndexCreator from langchain.text_splitter import CharacterTextSplitter from langchain.vectorstores import Chroma from langchain.embeddings import OpenAIEmbeddings from langchain.prompts import PromptTemplate from langchain.chains.question_answering import load_qa_chain from langchain.llms import OpenAI
チャンク分割
ドキュメント読み込み、それをチャンクと呼ばれる単位に分割します。
loader = TextLoader('./melos_jp.txt')
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0, separator = "\n")
texts = text_splitter.split_documents(documents)
チャンクサイズやセパレータはパラメータです。今回は改行記号をセパレータとします。
最後に取得できるtextsが、チャンクのリストです。
Chunk Vector格納
embeddings = OpenAIEmbeddings() melos_docsearch = Chroma.from_documents(texts, embeddings)
OpenAIEmbedding()は、OpenAIが公開しているEmbeddingAPIを使用するwrapperです。
Chromaはchromadbに対して操作を行うクラスです。Chroma.from_documents()で、embeddingsを用いて変換されたtextsが格納されたchromadbのインスタンスを作成しています。
Question Vector取得 & 関連度の高いチャンク取得
queryと近いチャンクを取得します。
query = "Question?" docs = melos_docsearch.similarity_search(query)
上記の関数はquery vector取得と、それと近いchunk vectorの取得を一気にやっています。
In-context Learning
In-context Learningのテンプレートを用意します。
今回はmap_reduceという方法で回答を生成します。
map_redeceでは、question_promptとcombine_promptという2種類のpromptを用います。
まずmap処理においてquestion_promptを用いて、各チャンクについてそれぞれquestionと関係する部分を抽出し、その後reduce処理においてcombine_promptを用いてそれらをsummaryさせて最終的な回答とします。
map_reduce_question_prompt_template = """Use the following portion of a long document to see if any of the text is relevant to answer the question.
Return any relevant text translated into Japanese.
{context}
Question: {question}
Relevant text, if any, in Japanese:"""
MAP_REDUCE_QUESTION_PROMPT = PromptTemplate(
template=map_reduce_question_prompt_template, input_variables=["context", "question"]
)
map_reduce_combine_prompt_template = """Given the following extracted parts of a long document and a question, create a final answer Japanese.
If you don't know the answer, just say that you don't know. Don't try to make up an answer.
QUESTION: {question}
=========
{summaries}
=========
Answer in Japanese:"""
MAP_REDUCE_COMBINE_PROMPT = PromptTemplate(
template=map_reduce_combine_prompt_template, input_variables=["summaries", "question"]
)
OpenAI(temperature=0)はOpenAI APIのLLMを使用するwrapperで、このモデルにIn-context Learningによる回答生成をさせます。
map_reduce_chain = load_qa_chain(OpenAI(temperature=0), chain_type="map_reduce", return_map_steps=True, question_prompt=MAP_REDUCE_QUESTION_PROMPT, combine_prompt=MAP_REDUCE_COMBINE_PROMPT)
map_reduce_chain({"input_documents": docs, "question": query}, return_only_outputs=True)
結果
いくつか質問をしてみて、出力を見てみます。
intermediate_stepsには、各チャンクでquestionと関係ある部分が抽出されています。output_textは最終的な回答です。
質問1
メロスの親友の名前は?
答えは皆さんご存知、セリヌンティウスです。
回答1
{'intermediate_steps': ["Relevant Text: メロスはひょいと、からだを折り曲げ、飛鳥の如く身近かの一人に襲いかかり、その棍棒を奪い取って、「気の毒だが正義のためだ!」と猛然一撃、たちまち、三人を殴り倒し、残る者のひるむ隙すきに、さっさと走って峠を下った\n\nNo, this text does not answer the question of who Melos's friend is.",
'\nメロスは、百匹の大蛇のような浪を相手に必死の闘争を開始した。',
'\nセリヌンティウスは、友と友の間でメロスをひしと抱きしめた。',
'\nメロスには父も、母も無い。女房も無い。十六の、内気な妹と二人暮しだ。'],
'output_text': '\nメロスの親友はセリヌンティウスです。'}
質問に関係のないノイズなチャンクも含まれているようですが、最終的な回答は正しいです。
質問2
セリヌンティウスの弟子の名前は?
答えは皆さんご存知(?)、フィロストラトスです。
回答2
{'intermediate_steps': ['Answer: セリヌンティウスの弟子の名前はメロスである。',
'Relevant Text: 「セリヌンティウス。」メロスは眼に涙を浮べて言った。',
'\nSubject: その若い石工\nPredicate: フィロストラトスである',
'No relevant text.'],
'output_text': ' 知りません。'}
正解を含むチャンクも抽出できていますが、最終的には「知りません」と回答してしまいました。
恐らく、mapの段階で出てきた“No relevant text.”という文章に引っ張られているのでしょう。これは、question _promptの「Return any relevant text translated into Japanese.」の記述に由来するものだと考えられます。
試しに4つ目のチャンクを除いてin-context learningさせてみると、正しい回答を導くことができました。
{'intermediate_steps': ['Answer: セリヌンティウスの弟子の名前はメロスである。',
'Relevant Text: 「セリヌンティウス。」メロスは眼に涙を浮べて言った。',
'\nSubject: その若い石工\nPredicate: フィロストラトスである'],
'output_text': ' その若い石工はフィロストラトスである。'}
ただ、一つ目のチャンクから「セリヌンティウスの弟子の名前はメロスである。」との要約を作成しているので、使用する言語モデルによってはこちらを回答にしてしまう可能性があります。
質問3
メロスはなぜ王を殺そうとした?
文中に直接明記はされていませんが、望ましい回答としては「市を暴君の手から救う」といったところでしょうか。
回答3
{'intermediate_steps': ['\nAnswer: メロスは、邪智暴虐の王を除かなければならないと決意した。',
'\nメロスは、「市を暴君の手から救う」ために、王を殺そうとした。',
'\nメロスは、王が人を信ずることが出来ぬということに激怒し、王を殺そうとした。',
'\nメロスは、王を殺そうとしたのは、自分の国を救うためだった。'],
'output_text': ' メロスは、邪智暴虐の王を除くために、「市を暴君の手から救う」ために、王が人を信ずることが出来ぬということに激怒し、自分の国を救うために王を殺そうとした。'}
なんだか長ったらしい回答が返ってきました。「市を暴君から救う」というのは含まれていますが、結論からいうとこの回答はバツです。
そもそも日本語の文章としておかしいのもありますが、「自分の国を救うため」という幻覚が含まれています(それっぽいですが、文中でこのようなことは書かれていないので、これは幻覚です。)。map処理の時点で幻覚を起こしていて、これをreduce処理でそのまま使っています。
また、reduce処理がmap処理の結果をただ繋げているだけのような挙動になっていて、「ために」を繰り返すような日本語として適切でない文章となってしまいました。
質問4
メロスが殴った人は合計何人?
帰りの道中の3人の山賊 + 最後のセリヌンティウスで4人です。
複数のチャンクを参照しないと答えに辿り着けない質問ですが、果たしてどうでしょうか。
回答5
{'intermediate_steps': ['\n三人。',
'Relevant Text: メロスは、ざんぶと流れに飛び込み、百匹の大蛇のようにのた打ち荒れ狂う浪を相手に、必死の闘争を開始した。\n\nSubject: メロス\nPredicate: 百匹の大蛇のようにのた打ち荒れ狂う浪と闘争を開始した',
'\n答え:メロスはセリヌンティウスの頬を殴った。',
'\nメロスはセリヌンティウスと自分の頬を殴った。'],
'output_text': ' メロスはセリヌンティウスの頬を1人殴ったので、合計で1人です。'}
中間出力を見てみましょう。
1つ目は、メロスが3人の山賊を殴り倒した部分に由来しています。3人は正しいです。
2つ目は、殴る描写は関係なく、ノイズのチャンクです。
3つ目は、物語終盤でメロスがセリヌンティウスを殴る部分に由来しています。
4つ目は、セリヌンティウスがメロスを殴った後でメロスに対して殴り返せと言っている部分に由来していて、メロスが誰かを殴った描写はありません。「メロスはセリヌンティウスと自分の頬を殴った。」というのは幻覚です。
上記を合計すると、4~6人が回答になりそうですが、最終的な回答ではセリヌンティウスのみを殴ったので1人となっています。深掘りはしていませんが、各チャンクを参照しつつ、算術を行う必要があるので、難しかったようです。
LLMの処理能力の限界なのか、Chain-of-Thoughtのようなプロンプトの工夫で解決できるのかはわかりませんが、多くのチャンクを参照しつつ複雑な処理を行うのは一筋縄ではいかないようです。
考察
チャンクの分割の仕方にもよるのでしょうが、簡単かつ特定のチャンクが極端に関係しているような質問でないと正確に答えられない印象でした。
複数チャンクを参照してまとめたり、算術を含むような高度な処理は苦手なようです。
また、やはりLLMを通すとしばしば幻覚を起こしてしまうようで、回答の信頼性は低いです。
まとめ
LLMを自分の分野に活用するには、Fine-Tuningによるタスク特化とGroundingによるデータ特化の2パターンのアプローチがあることを説明しました。
Langchainのフレームワークを用いて、GroundingによるQAシステムを実践しました。そのままではだいぶ簡単な質問にしか正解できないようです。また、結構な頻度で幻覚が発生しました。より強いLLMを使ったりプロンプトを工夫したりして性能向上や幻覚抑制の期待がありますが、ただベクトル検索した結果をユーザーに返すだけでも大抵のユースケースには十分なのでは、という気もしました。
さいごに
グループ研究開発本部 AI研究開発室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務などAI研究開発室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。皆さんのご応募をお待ちしています。
参考文献
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD