2022.04.06
知識グラフ上での推論のためのモデルQuery2Boxを試す
こんにちは。次世代システム研究室のS.S.です。
今回は知識グラフ上での推論手法の一つであるQuery2Boxについて紹介したいと思います。
(記事中の図はwikidataの図およびQuery2Box論文からの引用です。)
知識グラフとは
知識グラフとは人や組織、場所などの名前がついたエンティティどうしの関係性をグラフの形でエンコードしたものです。
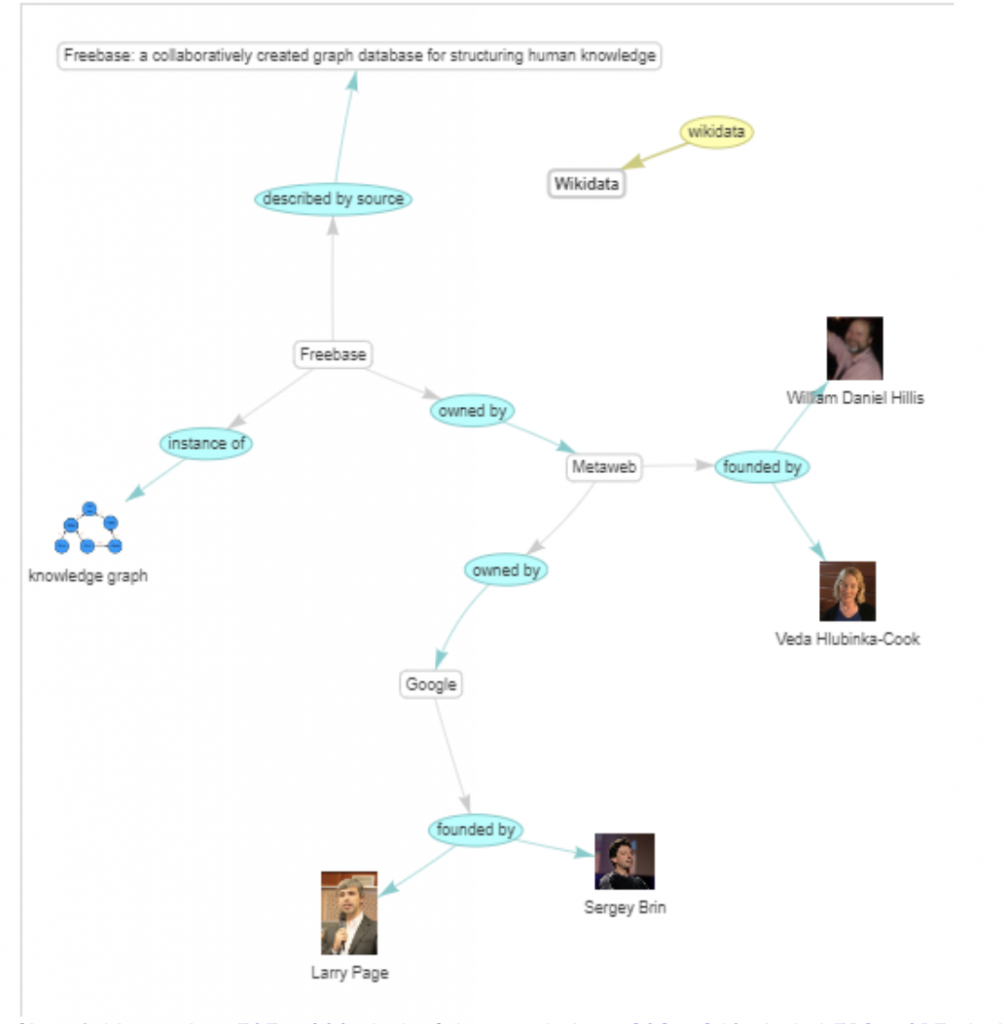
wikimediaより引用
Query2Boxからの例を引用すると、このグラフをたどっていくことによって例えばチューリング賞をとったカナダ在住の人は誰かといったクエリに対して、Turing Award -(win)-> Hinton, Canada -(citizen)-> HintonからHintonが答えの一つであることがわかります。
単純な関係性であればグラフから視覚で情報を読み取ることができますが、グラフを何ステップかたどるようなさらに複雑なクエリもQuery2Boxでは扱うことができます。
チューリング賞をとったカナダ在住の人が卒業した大学はどこかというクエリでは、条件を満たす人の部分を存在量化をつかって書くことで、何ステップかたどる関係性を表現します。
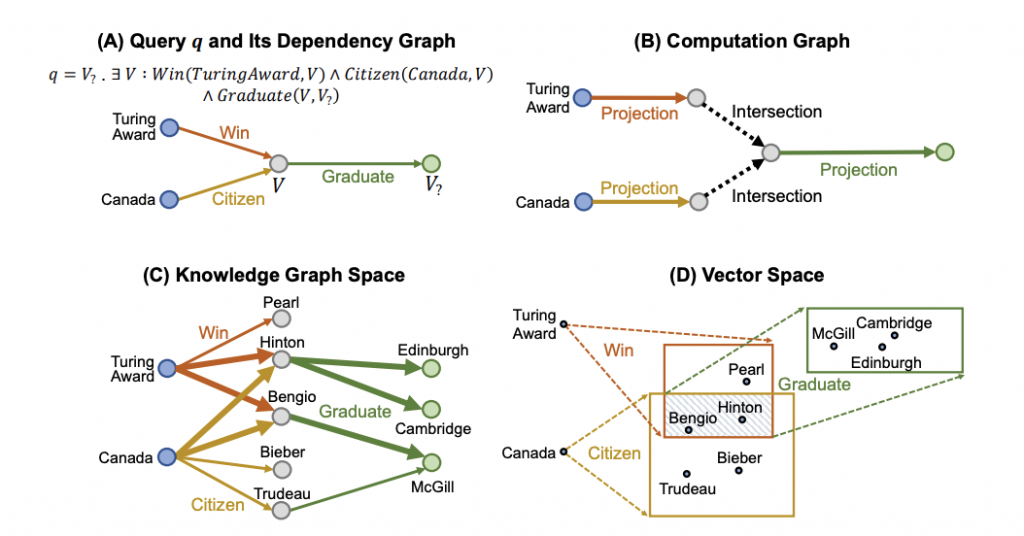
Query2Box論文より引用
さらに実際のknowledge graphではrelationの一部が欠けていることもよくあり、例えばBengioはカナダ在住という情報がグラフに入っていないとすると、グラフを愚直にたどっただけでは上記のクエリに答えられないということになります。
しかしHintonやBengioの他のノードとのつながり方は似ているので、二つは似ているノードかもしれないと読み取れるかもしれません。
Query2Boxではentity, relationやクエリを低次元のembedding spaceに埋め込み、NNでknowledge graph上の欠けている関係を補いながらクエリに対する答えを見つけます。
Query2Boxで表現できるクエリ
Query2BoxではクエリをProjection, Intersection, Unionの3つの基本操作に分解し、Boxによる表現でこの3つの操作を実現します。
単一のentityはsizeが0のboxとみなすことができ、そこからスタートして箱を広げたり縮めたりする3つの操作を組み合わせてクエリを表現します。
Projection
Projectionでは与えられたentityから特定のrelationを介してたどりつけるノードの集合をBoxを使って表現します。
boxは中心と幅を持ち、以下のrのような表現を使います。
![]()
input box pを受け取ってrelation rでprojectionをすると結果のboxは次のように定義します。
![]()
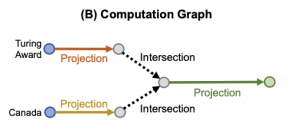
図の例だとチューリング賞をとったのは誰かもしくはカナダ在住は誰かというのはProjectionのクエリとなります。
図中の二つのProjectionの共通部分をとる操作が次に紹介するIntersectionのクエリです。
Intersection
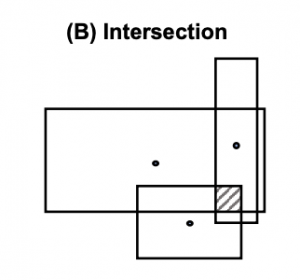
Query2Box論文より引用
共通部分の中心は入力のboxの中心に近くなるようにself-attentionを使って計算します。
共通部分は元の集合よりも小さくなるはずなので、boxの幅の計算方法も必ず縮むようにしつつ、どのくらい縮めるかをサブのネットワークで決めます。
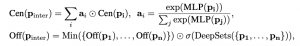
Query2Box論文より引用
Union
Unionでは入力の複数のboxの和を得る操作となります。
トレーニングのloss
各クエリをboxを使って表現することができたので、positive exampleは箱に近づけ、negative exampleは箱から遠ざけるようなlossを設定します。
そのために知識グラフからクエリにマッチするentityをサンプルしてトレーニングに使います。
実装上の工夫として箱の内側にあるか外側にあるかでpenaltyをどのくらい強くするかを変えています。
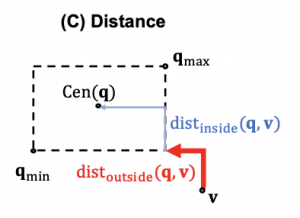
Query2Box論文より引用
Unionについては上記でクエリをどう計算にマッピングするかを説明していませんでしたが、論理式の外側に括り出すような操作つまりDisjunctive Normal Form(DNF)への書き換えをあらかじめやっておくことで、トレーニングや推論のときの計算が単純になります。
実装をいじってみる
ここで紹介したQuery2Boxの実装はgithubにて公開されています。
https://github.com/snap-stanford/KGReasoning
ここからは実際の実装を触ってみることにします。
データとしてはFreebaseのデータを元に作られた、FB15k-237の加工済みデータを含むデータセットをダウンロードして、以下の手順でトレーニングを行います。
注意点としては計算が重いのでGPUを使わないとトレーニングが永遠に終わりません。
幸いにも手元の環境で試した限りではColabのGPUインスタンスにちょうど収まるデータサイズなので気になる方は試してみてください。
git clone https://github.com/snap-stanford/KGReasoning.git cd /content/drive/MyDrive/kg_test/KGReasoning mkdir data wget http://snap.stanford.edu/betae/KG_data.zip unzip KG_data.zip cd .. CUDA_VISIBLE_DEVICES=0 python main.py --cuda --do_train --do_valid --do_test \ --data_path data/FB15k-237-betae -n 128 -b 512 -d 400 -g 24 \ -lr 0.0001 --max_steps 450001 --cpu_num 1 --geo box --valid_steps 15000 \ -boxm "(none,0.02)" --print_on_screen --tasks "1p.2p.3p.2i.3i.ip.pi.2u.up" --save_checkpoint_steps 1000 --test_batch_size 16
GPUを使ってもやはりトレーニングは長いので、簡単なクエリがある程度当たるようになる15000 stepでトレーニングを打ち切り、出力結果を見てみます。
データセットに含まれるクエリは上記のProjection, Intersection, Unionの組み合わせで表現されており、全部で9パターンあります。
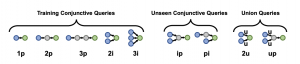
Query2Box論文より引用
トレーニングに使うクエリは図の左半分に相当する、3 stepまでのprojectionもしくは3個までのintersectionという比較的シンプルなクエリだけを使います。
Query2Boxでうまくいくとどのようなことができるのか感覚をつかむために図の2p, 2iで正解したクエリの例を見てみることにします。
2pクエリの例
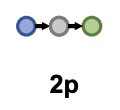
2pのクエリでは与えられたentityから二つの指定されたrelationをたどって到達できるentityは何かというクエリになります。
抽出したクエリではヨーロッパでのオスマン戦争に関わった国の首都はどこかというクエリです。
Query2Boxで抽出した答えはランク順に以下のようになっています。
この中で実際の答えはBudapestが該当します。
|
ans_label |
ans_description |
|
Wallachia |
historical and geographical region of Romania |
|
Ottoman wars in Europe |
war |
|
Constantinople |
capital city of the Eastern Roman or Byzantine… |
|
Budapest |
capital city of Hungary |
|
Madrid |
capital city of Spain |
|
Paris |
capital city of France |
|
Frankfurt |
city in Hesse, Germany |
|
Bratislava |
capital city of Slovakia |
|
Bohemia |
Historical land in the Czech Republic |
|
Holy Roman Empire |
varying complex of lands that existed from 962… |
2iクエリの例
2iのクエリでは二つの与えられたentityから指定のrelationをたどって到達できる共通のentityは何かというクエリです。
抽出したクエリは紅の豚とThe Gooniesの共通ジャンルは何かというものです。
いろいろと映画のジャンルが並んでいますが、正解はadventure filmとなります。
|
ans_label |
ans_description |
|
comedy film |
genre of film in which the main emphasis is on… |
|
romance film |
film genre |
|
drama film |
film genre |
|
black comedy |
comic work that employs black humor or gallows… |
|
action film |
film genre |
|
fantasy |
genre of fiction |
|
science fiction |
genre of fiction |
|
adventure film |
film genre |
|
crime fiction |
genre of fiction focusing on crime |
|
animation |
process of creating animated films |
ここまでの例をみると、明示的に絞って情報を与えなくともクエリに関係のあるentity(首都や映画ジャンルの一覧)をリストアップすることはできていますが、実際の並び順を見てみるとクエリの正確な内容までうまく考慮できているかどうかは少し微妙なラインというようにみえます。
今回手元で試した時はトレーニングのステップ数をかなり短めに設定しているので、実際に元論文と同じ設定でトレーニングをするとよりそれっぽい候補が上位に出てくると思われます。
補足
FB15k-237に含まれるentityはFreeBaseのID形式で入っており、ぱっと見何のentityかわかりませんので、以下から各IDがどのentityに対応するかの情報を持ってきて上記の抽出例で使いました。
FB15k-237のディレクトリの下にjsonが置いてあります。
https://github.com/villmow/datasets_knowledge_embedding
参考文献・引用元
https://arxiv.org/abs/2002.05969
https://commons.wikimedia.org/wiki/File:Knowledge_graph_wikidata.png
まとめ
Knowledge Graph上での推論を行うアーキテクチャとしてQuery2Boxを取り上げました。
さらに著者が公開している実装をもとに得られた実際の出力例をいくつか見てみました。
論文の実験結果と合わせてみると、シンプルなクエリの正答率は高めですが、複雑なクエリの出力結果をdown-streamのタスクで使うにはもう一工夫くらい必要なそうな結果となりました。
最後に
次世代システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。興味を持って頂ける方がいらっしゃいましたら、ぜひ募集職種一覧からご応募をお願いします。皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD



{kind=link}