2020.07.14
高速なKVS:Aerospikeの特徴、ユーザーケースを紹介します。
こんにちは。次世代システム研究室のB.Mです。外国人です。よろしくお願いします。
弊社では、MySQL, MariaDB, MongoDBなど、様々なデータベースを用途に応じて使い分けていますが、大規模な機能、高いパフォーマンスが要求されるデータの保管先としてAerospikeを導入していました。
先日、Aerospikeのsetに関するの管理問題が発生して、システムをメンテナンスをしました。
そこで今回は、Aerospikeの特徴や注意点、使用例などをご紹介したいと思います。
注意点:今回の話は無料版(Community Edition)しか発生しません。
問題点:管理しやすいため、Set名は日付に追加しています。例えば:Set名は”books_20200101″です。
でも、1つnamespaceに最大1023Setしかないです。もし一日1Set を追加した場合、3年くらい上限に達します。
それで、古くて、使わないデータセットを削除するのが必要になります。
ですが調査結果により、Setを動的に削除するのができなくなりました。
問題点と解決方法は後で具体的説明いたします。その前に、まずはAerospikeについて、特徴と優位性を紹介したいと思います。
1. Aerospikeの紹介
Aerospikeとは米Aerospike社によって開発・販売されているNoSQLデータベースのです。
まずは、NoSQL データベースについて説明したいと思います。
NoSQLデータベースとは
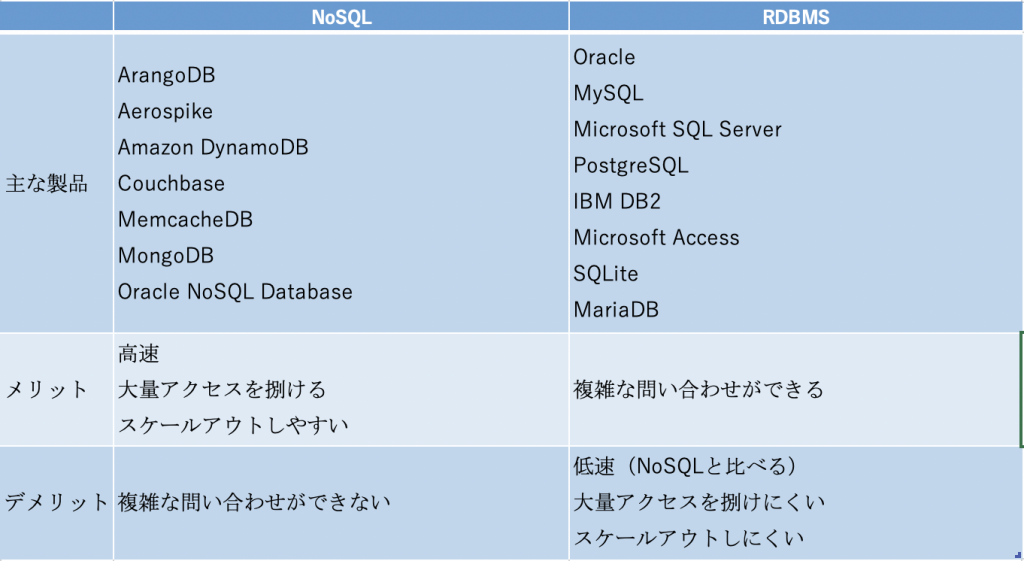
簡単に説明すると、RDBMS(リレーショナルデータベース管理システム)以外のデータベースのことです。
そのため、Not only SQL (NoSQL) と呼ばれています。
RDBMSは関係モデルの複雑で高度な問い合わせができますが、速度が遅いです。
NoSQLは関係モデルの複雑で高度な問い合わせができないが、速度が早いです。
各種類の代表、メリットとデメリット表は以下のようになります。
2. Aerospikeの特徴
Aerospikeは、C言語で書かれていてフラッシュ向けに最適化されたインメモリオープンソースのNoSQLデータベースです。
以前は商用のみでしたが、現在は、無料版も提供されています。
主な特徴として、次の点が挙げられます。
- 高速な分散KVS
- 基本的にデータはSSD、インデックスはメモリに持つ
- スケールアップ・スケールアウト両方に対応
- レプリケーションファクター(RF)・バックアップで可用性を確保可能
- GET/SETは驚異的な速度を発揮するが、KVSなのでSCANやQUERYは得意ではない
- オープンソースのCommunity Editionと有償のEnterprise Editionがある
2.1 ハイブリッドストレージ
Aerospikeは、次のタイプのメディアおよび組み合わせのいずれかにデータを保存できます。
- ダイナミックランダムアクセスメモリ(DRAM)
- 非揮発性メモリ拡張(NVMe)フラッシュまたはソリッドステートドライブ(SSD)
- 永続メモリ(PMEM)
- 従来のスピニングメディア
Aerospikeでのストレージはデータストレージ(Data Storage)とプライマリインデックスストレージ(Primary index storage)に分けています。上記のストレージタイプを使用して、以下の表でハイブリッドストレージオプション間の違いが比較できます。
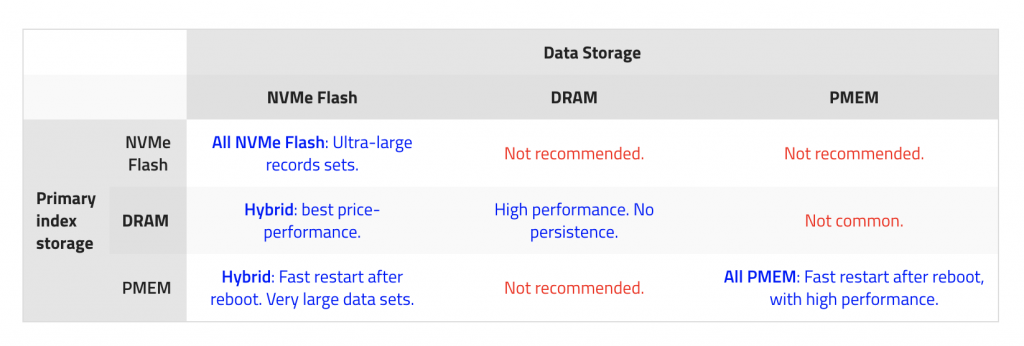
上記の表によりプライマリインデックスストレージはDRAM、データストレージはSSDなどのは最高のコストパフォーマンスです。
2.2 高速な分散KVS
Aerospikeの仕様のメリットは:
データを永続化(データストレージはSSDに保存します)
パフォーマンスが良い(プライマリインデックスストレージはRAMか高速メモリを使用します)
ある記事により、平均1ミリ秒以下のレイテンシで読込み/書込みが可能で、スループットは超高性能SSDを使用した場合では、なんと1サーバーで100万TPSにも達するようです。
TPS: (Transactions Per Second) トランザクション毎秒。
データはSSD保存が基本
AerospikeはSSDに最適化されたデータベースであり、基本的にはSSDにデータを保存します。
SSDの代わりにHDDを使うこともできますが、AerospikeのパフォーマンスはSSDの性能に大きく依存するので、あえてHDDにするメリットは殆どありません。
また、より速度が必要な場合は、AerospikeをRedisのようにPure In Memory(全部データはメモリに保存される)で動かすという事も実は可能です。 しかし、当然ながら永続性は失われますし、それをやるなら別にAerospikeじゃなくてもいいかな〜と自分は思っています。
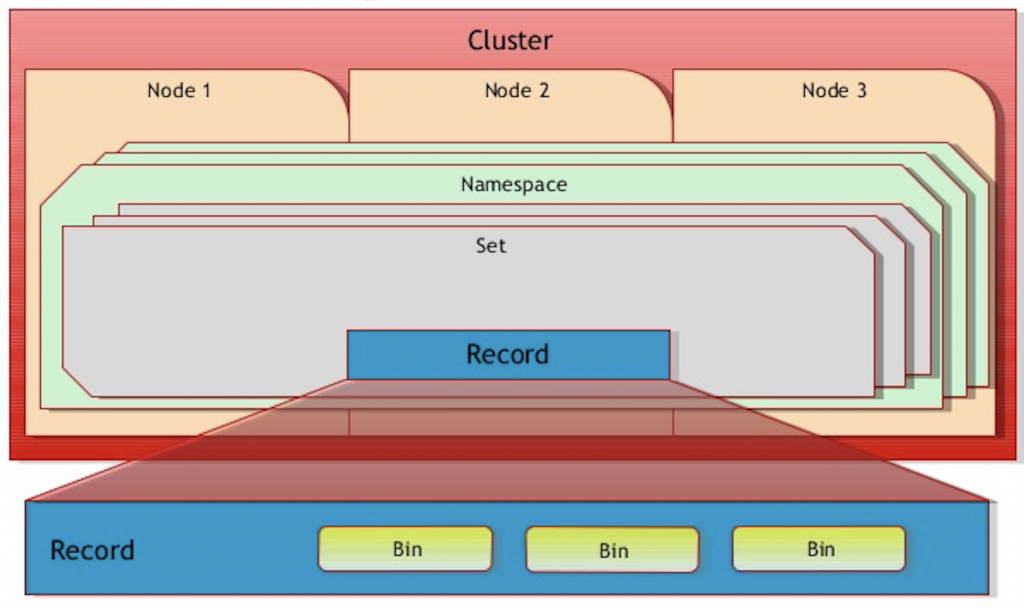
2.3 データ階層
AerospikeはNamespace, Set, Record, Binの階層構造になっています。 これはMySQLにおけるDatabase, Table, Row, Columnに似ています。
無料版は
Namespacesが最大2つをサポートされます。
Cluster Management (max Cluster size, data)が8 nodes, 5 TBまでサポートされます。
詳細はこちらに参考できます。
Cluster
- クラスターは複数ノードに分散されます。
- クラスターの管理は自動化されているため、手動での再調整や再構成は必要ありません。
- 1つ以上の名前空間が含まれます。
- 名前空間の追加/削除には、クラスター全体の再起動が必要ですので、稼働前に使用するNamespaceを全て作成しておくことをおすすめします。
Node
- 各ノードは同一であると想定されます。
- データ(および関連するトラフィック)はノード間で均等に分散されます。
- ノード間の大きな違いは問題を意味します。
- ノード容量は、ノード障害パターンを考慮に入れる必要があります。
Namespace
MySQLのDatabaseのようなものです。
- ストレージメディアに関連付けられている:
- ハイブリッド(インデックスにはRAM、データにはSSD)
- 永続性のみのRAM +ディスク
- RAMのみ
- それぞれを独自に構成できます:
- レプリケーションファクター(変更にはクラスター全体の再起動が必要です)
- RAMとディスクの構成
- ハイウォーターマークの設定
- デフォルトttl(自動的にデレットされてはならないデータがある場合は、これを「0」に設定する必要があります)
Set
MySQLのTableに似ています。
- RDBMSの「テーブル」と同様です。
- セットはオプションです。
- AerospikeはKVSなのでスキーマはありませんのおで、スキーマは事前に定義する必要はありません。
- レコードをリクエストするには、そのセットを知っている必要があります。
- スキャンはセット全体で実行できます
- SetはNamespace毎に1,023個まで作成することができます。
注意点:Set数が限定なので、 日毎にSetを作成していると、3年以内にSetが作成できないので注意しましょう。
Record / Bin
Recordはkey, expiration, generation, binsによって構成されています。
- RDBMSのRowと同様です。
- レコードのすべてのデータは同じノードに保存されます。
key
- ユニークなID。
- KVSって、Key Value Storeですから基本的にRecordはKeyを使用したらクセスできます。
expiration(TTL = Time to live)
- Recordの有効期限です。
- 有効期限を超過したRecordはAerospikeによって自動的に削除されます。
- 秒単位は秒です。
- 有効期限を設定したくない場合は”-1”です。
- デフォルトは0です。
generation
Recordを更新されると自動的にインクリメントされていく値です。
GenerationPolicyを使用することで、「generationがNより大きいRecordのみ」などの条件を設定することができます。
bins
Binとは名前と値の組の事で、Recordは必ずBinを1個以上持っています。
- 現在Binの値には:
- シンプル(整数、文字列、ブロブ[言語固有])
- 複雑(リスト、マップ)
- 大きなデータ型(Large Data Types)
- 単一のビンがクライアントによって更新される場合があります
- インクリメント
- 置換
- ユーザー定義関数(User Defined Function)
使用例
Aerospike では aql (Aerospike Query Language) と呼ばれる SQL に近いコマンドラインインターフェースがあります。 aql を使って CRUD処理などのデータ操作できます。以下はaqlを使用して、Recordを作成・取得する例です。
aql> SET OUTPUT JSON
aql> SET RECORD_PRINT_METADATA true
aql> SET RECORD_TTL 3600
aql> INSERT INTO test.books (PK, name, price) VALUES (4798139017, '楽しいRecord', 2020万円)
OK, 1 record affected.
aql> SELECT * FROM test.books WHERE PK = 4798139017
[
{
"edigest": "N/A",
"ttl": 3571,
"gen": 1,
"bins": {
"name": "楽しいRecord",
"price": 2020万円
}
}
]
例えば:データを変更する時、簡単に変更できます。
aql> INSERT INTO test.books (PK, name, price, created_at) VALUES ('key_001', 'Record_001', '10man', 20200606)
OK, 1 record affected.
aql> SELECT * FROM test.books WHERE PK = 'key_001'
[
{
"edigest": "N/A",
"ttl": 3589,
"gen": 3,
"bins": {
"name": "Record_001",
"price": "10man",
"created_at": 20200606
}
}
]
3. 問題解決
冒頭で記述しましたが、もしSet名に日付を付けていた場合、クエリ時のSet 名を変更することで、いつのデータかを変更することができます。
しかし、1つのNamespace のSet 数の上限は1023 です。そのため、もし一日1Set を追加した場合、3年後には1023 を超えてしまいます。もし、古いSet を削除したいなら、現在の仕様では、データを期限切れ設定にするかディスクがワイプされた後にコールドリスタートする方法しかありません。
もし、サービスが稼働していた場合、再起動したくありません。(無料版では再起動に30分かかります。ちなみに、有料版は10秒だそうです。)
Aerospikeはtruncate機能をサポートしていますが、truncateして、コールドリスタートしても、セットがまだ残ります(空セットです)。
それで、一番簡単な方法は:日付をキーに入れます。そうすると、Set名は’books_20200101’から’books’に統一して、PKは例えば’key_001’から’book_20200701_key_001’になります。PKでクエリするの際、PKに日付の情報と組み立てましたらデータを取得できます。
例えば:
aql> SET RECORD_TTL 3600
aql> INSERT INTO test.books (PK, name, price, created_at) VALUES ('book_20200701_key_001', 'Record_001', '10man', 20200606)
OK, 1 record affected.
aql> SELECT * FROM test.books WHERE PK = 'book_20200701_key_001'
[
{
"edigest": "N/A",
"ttl": 3600,
"gen": 1,
"bins": {
"name": "Record_001",
"price": "10man",
"created_at": 20200606
}
}
]
対応方法は簡単なんですが、アプリのAPIを修正すると有効期限を設定するのが必要ですので、ご注意ください。
参考リンク
- https://www.aerospike.com/docs/
- https://tech-blog.fancs.com/entry/aerospike-introduction
- https://qiita.com/d-tech/items/53e57c8cc425530d6e28
- https://www.slideshare.net/AerospikeDB/aerospike-key-value-store
最後に
Aerospikeを用いて、高速なKVSデータベースとユーザーケースを紹介しました。RDBMSとNoSQLのデータベースはメリットとデメリット両方がありますが、システムの要求に応じて使用した方が適切だと思います。Aerospikeは特に早いですから、その利点を使用してより良いアプリを開発できれば幸いです。
次世代システム研究室では、グループ全体のインテグレーションを支援してくれるアーキテクトを募集しています。インフラ設計、構築経験者の方、次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ募集職種一覧からご応募をお願いします。
皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD