2019.04.07
Hive3とLLAPとDruidを試す ~HDP3.0.1.0~(後編:クエリ検証編)
こんにちは。次世代システム研究室のデータベース と Hadoop を担当している M.K. です。 前回のブログでは構築がメインでしたが、今回の後編はHive3+LLAP+Druidのクエリ検証について書きたいと思います。
目次(後編:クエリ検証編)
- データ準備(テーブル&マテリアライズドビュー作成とデータロード)
- クエリ実行時間を比較検証(Hive+LLAP+Druid or ORC)
- マテリアライズドビューの更新の検証
- まとめ
1. データ準備(テーブル&マテリアライズドビュー作成とデータロード)
利用したデータ
今回もずっと検証で使い続けているお馴染みのこのサンプルデータを利用しました。サンプルデータのうち、以下の2つを利用しました。大きいのはpage_viewsで、documents_metaはマスタデータのようでとても小さいです。
- page_views.csv
- documents_meta.csv
page_viewsについてはDruidで大事になるタイムスタンプのデータが特殊な状態になっているため、今回の検証では事前に加工しました。
Druidのテーブルはタイムスタンプのカラムが一つしか持てないことと、今のところHiveから使うには秒単位まででミリ秒やマイクロ秒には対応していないため、page_viewsのタイムスタンプを秒までに変換、なるべく同じ秒で重複がないようにしています。
苦労したところ①
重複がないように加工したこともあり加工後のpage_viewsはだいぶコンパクトになりましたが、元は巨大なテーブルで、前回のブログで行ったLLAPの設定ではメモリ割り当てが足りずに失敗を繰り返したため、結局LLAPを一回無効にして処理を行いました。
加工は段階を分けて行いましたが、最終的には以下のテーブルに格納しています。元のタイムスタンプのカラムは残したまま、新たに秒までに変換したpv_secondと、程よくパーティショニングするようにパーティションキーのpv_date、pv_hourを追加しています。
CREATE TABLE page_views_unique_p_date_hour_insertonly( uuid string, document_id int, pv_timestamp bigint, pv_second timestamp, platform tinyint, geo_location string, traffic_source tinyint) PARTITIONED BY ( pv_date date, pv_hour tinyint) STORED AS ORC TBLPROPERTIES ( 'transactional'='true', 'transactional_properties'='insert_only');
Hive3からは外部テーブル以外はトランザクション対応がデフォルトで前提になっています。今回の検証ではトランザクション対応はしなくて良かったのですが、LLAPは外部テーブルは対象外というのと、テーブル単位でトランザクションがうまく無効にできなかったため、トランザクションの設定をあえて「insert_only」にしてみました。
マテリアライズドビュー作成
Hive+LLAP+Druidを試すにあたり、実際に運用することを考えると、HiveとDruidを別々にETL処理でデータを格納するよりも、HiveテーブルからDruidのマテリアライズドビューを作るほうがより良いので、クエリ検証のためにマテリアライズドビューを作成しました。
マテリアライズドビューを作るときにテーブル結合まで行っておけばクエリ実行時間を減らことができるので、page_viewsとdocuments_metasを結合しています。基本的にはCREATE … AS SELECT …の構文で行います。
Druidのマテリアライズドビュー
CREATE MATERIALIZED VIEW mvdruid_page_views_documents_meta STORED BY 'org.apache.hadoop.hive.druid.DruidStorageHandler' TBLPROPERTIES( 'druid.segment.granularity'='HOUR', 'druid.query.granularity'='SECOND', 'druid.datasource'='mvdruid_page_views_documents_meta') AS SELECT pv.pv_second AS `__time`, CAST(pv.pv_date AS string) AS pv_date, pv.pv_hour, pv.uuid, pv.document_id, dm.source_id, dm.publisher_id, pv.platform, pv.geo_location, pv.traffic_source FROM page_views_unique_p_date_hour_insertonly pv LEFT JOIN documents_meta dm ON pv.document_id = dm.document_id;
ポイントは「__time」(アンダーバー二つ)カラムとTBLPROPERTIES句です。
「__time」カラムがDruidのテーブルで一つだけ持てるタイムスタンプのカラムなので、pv_secondカラムを割り当てて、date型のpv_dateはstring型に変えます。
それからTBLPROPERTIES句には少なくとも3つの大事な設定があります。Druidのタイムスタンプデータのgranularity(=粒度)については、こちらのHortonworksのドキュメントに詳しく書いてあります。
- druid.segment.granularity:物理的なパーティションなので、今回の検証は日時(pv_date+pv_hour)の粒度になるようにHOURを指定
- druid.query.granularity:上記セグメントにどう格納するかで、タイムスタンプを秒までにしたので、SECONDを指定
- druid.datasource:Druid上のテーブル名にあたるので、ユニークな名前であれば何でも良いですが、マテリアライズドビューと同じ名前を指定
ORCフォーマットのマテリアライズドビュー
CREATE MATERIALIZED VIEW mvorc_page_views_documents_meta STORED AS ORC AS SELECT pv.pv_second, pv.pv_date, pv.pv_hour, pv.uuid, pv.document_id, dm.source_id, dm.publisher_id, pv.platform, pv.geo_location, pv.traffic_source FROM page_views_unique_p_date_hour_insertonly pv LEFT JOIN documents_meta dm ON pv.document_id = dm.document_id;
ORCのマテリアライズドビューの作成はもっとシンプルです。「__time」カラムにする必要がないのでpv_secondはpv_secondのまま、データ型もすべてそのままとしました。
比較のための結合テーブル(ORC)
CREATE TABLE page_views_documents_meta STORED AS ORC AS SELECT pv.pv_second, pv.pv_date, pv.pv_hour, pv.uuid, pv.document_id, dm.source_id, dm.publisher_id, pv.platform, pv.geo_location, pv.traffic_source FROM page_views_unique_p_date_hour_insertonly pv LEFT JOIN documents_meta dm ON pv.document_id = dm.document_id;
マテリアライズドビューとテーブルで差があるかも見たかったので、結合したORCテーブルも作りました。
それぞれのマテリアライズドビューまたはテーブルのサイズ
- page_views_unique_p_date_hour_insertonly → 2598048件、46.9MB
- mvdruid_page_views_documents_meta → 2598048件、81.0MB
- Druidのデータの実体であるindexファイルはHDFSの以下の場所にあるので、その合計サイズを集計。Druidのindexファイルはzip圧縮でした。
- /apps/druid/warehouse/mvdruid_page_views_documents_meta
- Druidのデータの実体であるindexファイルはHDFSの以下の場所にあるので、その合計サイズを集計。Druidのindexファイルはzip圧縮でした。
- mvorc_page_views_documents_meta → 2598048件、44.8MB
- page_views_documents_meta → 2598048件、45.4MB
苦労したところ②
Druidのマテリアライズドビューの作成がうまくいかず、処理は成功するのに件数が入らない事象に悩まされました・・。
hive.
当初は実はもっと大きなデータでDruidのマテリアライズドビューを作ろうとしていたんですが、メモリ不足でHive+LLAP(正確にはHiveServer2 InteractiveとLLAPデーモン)がよく落ちました。このときHive側でクエリキャンセルを繰り返したんですが、どうもそれでおかしくなっていたようなので、Druidに関連するクエリをキャンセルするときはDruidのサービス再起動もやっておくことをお薦めします。
Druidに何が起きているかは、DruidのCoordinatorを立ち上げているノードでcoordinator.logを見てください。ここで削除したはずのマテリアライズドビューへの処理に関するログが出続けていて、おかしいと思って再起動したら直りました。
2. クエリ実行時間を比較検証(Hive+LLAP+Druid or ORC)
LLAPの設定見直し
HiveからDruidを使う場合は、HDPの初期設定ではLLAPの利用が前提になっており、HiveServer2ではなくHiveServer2 Interactiveに接続して使うようになっています。
上述しましたが、前回のブログのLLAPの設定ではメモリ割り当てが抑えめで、全体のリソースに対して半分以下のため、クエリ検証にあたり以下のように設定を見直しました。Ambariの管理画面から以下のように変更し、それぞれのサービスでRestart Affectedします。
YARN > CONFIGS > SETTINGS > Memory >> Node Memory allocated for all YARN containers on a node: 28672(MB) YARN > CONFIGS > SETTINGS > CPU >> Node Number of virtual cores: 5 Hive > CONFIGS > SETTINGS > Optimization >> Memory Data per Reducer: 256MB Tez > CONFIGS > General tez.grouping.min-size: 536870912(Bytes) tez.grouping.max-size: 2147483648(Bytes) Hive > CONFIGS > ADVANCED >> Advanced hive-interactive-env HiveServer Interactive Heap Size: 5958 #HiveServer2 Heap Sizeと同じに変更 Hive > CONFIGS > SETTINGS > Interactive Query Memory per Daemon (=LLAP daemon size): 26624MB In-Memory Cache per Daemon (=Cache size): 4096MB Hive > CONFIGS > ADVANCED > Advanced hive-interactive-env LLAP Daemon Container Max Headroom: 2048(MB) LLAP Daemon Heap Size (MB): 20480 Number of Node(s) for running Hive LLAP daemon: 4
実運用ではしないと思いますが、今回は検証なので5台あるスレーブノードのうち4台をLLAPに割り当てて1台あたりのリソースも使い切るような設定に変更しました。
あと直接LLAP関連ではないですが、MapとReduceタスクのメモリもより今回の検証にあうように、tez.grouping.min-size、tez.grouping.max-size、Data per Reducer (hive.exec.reducers.bytes.per.reducer)の値も調整しました。
LLAPの設定見直しの根拠
スレーブノード1台のマシンスペックはCPU: 6vCPU / メモリ: 30GBで、これが前提になります。
前回のブログと同じようにLLAP周りの設定値を計算します。より詳細に知りたい方は、HortonworksのLLAP sizing and setupとHive LLAP deep diveのドキュメントを読むことをお薦めします。
LLAPデーモンのサイズ
LLAP daemon = (NM_memory – 2GB * ceiling((N_Tez_AMs + 1)/N_LLAP_nodes))
・N_LLAP_nodes = 全ノードにおけるLLAPが使うノード数 → 5台中4台をLLAP専用にするため4に変更
・N_Tez_AMs = query coordinators (Tez AMs)の数 → ここは変えずに2のまま
・NM_memory = 1台のNode Managerのメモリ (yarn.nodemanager.resource.memory-mb) → 少し控えめに26GBにしていましたがもっと利用するため28GBに変更
それぞれ当てはめて計算するとLLAPデーモンは、28GB – 2GB * ceiling(3/4) = 26GBです。
LLAPキューのサイズ
LLAP queue size = (2GB * N_TEZ_AMs) + (1GB [slider AM]) + (daemon_size * N_LLAP_nodes)
さきほど設定した値をそれぞれ当てはめるとLLAPキューのサイズは、(2GB * 2) + 1GB + (28GB * 4) = 4GB + 1GB + 104GB = 109GBになりました。
全体のYARNキューリソースはNode Managerのメモリ28GB×5台の140GBで、109GBはそのおよそ78%なので、LLAPキューの割り当てを80%に変更します。
LLAPデーモンのヒープサイズ
LLAP Daemon Heap Size = n_executors * memory_per_executor
・n_executors = LLAPデーモンが立ち上げるexecutors数 → 1ノードあたりでYARNに割り当てるリソースを4から5に増やしたので5に変更
・memory_per_executor → ここは変えずに4GBのまま
計算しなおすとLLAPデーモンのヒープサイズは、5 * 4GB = 20GBです。
LLAPデーモンのキャッシュサイズ
Cache size = LLAP daemon size – LLAP Daemon Heap Size – headroom
・headroom (LLAP Daemon Container Max Headroom) → 0.06 * LLAP Daemon Heap Size = 1.2GB ≒ 2GB (2Gの倍数に切り上げ:LLAP Daemon Container Max Headroomを2GBに)
計算しなおすとLLAPデーモンのキャッシュサイズは、26GB – 20GB – 2GB = 4GBです。
クエリ検証
①簡単なクエリの比較
特定の条件におけるpv_secondまたは「__time」カラムの最新のタイプスタンプ値を取得するクエリを比較検証しました(3回実行)。
/* ORCテーブル */ select max(pv_second) from page_views_unique_p_date_hour_insertonly where geo_location like 'US>NY%' and traffic_source = 3; /* Druidのマテリアライズドビュー */ select max(`__time`) from mvdruid_page_views_documents_meta where geo_location like 'US>NY%' and traffic_source = 3;
ORCテーブルへのクエリ結果
- 1回目:39.63秒 → 1回目はだいぶ遅い
- 2回目:0.391秒 → 2回目からクエリキャッシュが効いている
- 3回目:0.387秒
1回目がだいぶ遅いのはデータをLLAPのキャッシュに乗せているオーバーヘッドの時間なんでしょうか。2回目以降はexplainコマンドで実行計画を取るとクエリキャッシュが効いていることがわかります。
1回目:
----------------------------------------------------------------------------------------------
VERTICES MODE STATUS TOTAL COMPLETED RUNNING PENDING FAILED KILLED
----------------------------------------------------------------------------------------------
Map 1 .......... llap SUCCEEDED 4 4 0 0 0 0
Reducer 2 ...... llap SUCCEEDED 1 1 0 0 0 0
----------------------------------------------------------------------------------------------
2回目以降の実行計画:
+----------------------------------------+
| Explain |
+----------------------------------------+
| Stage-0 |
| Fetch Operator |
| Cached Query Result:true,limit:-1 |
| |
+----------------------------------------+
Druidのマテリアライズドビューへのクエリ結果
- 1回目:16.52秒
- 2回目:6.36秒
- 3回目:2.75秒 → 3回目以降は大体同じ実行時間
マテリアライズドビューに対してはクエリキャッシュが効かない模様。でもやるたびに速くなっているため、DruidのデータをLLAPのキャッシュに段階的に乗せているのだろうか。
----------------------------------------------------------------------------------------------
VERTICES MODE STATUS TOTAL COMPLETED RUNNING PENDING FAILED KILLED
----------------------------------------------------------------------------------------------
Map 1 .......... llap SUCCEEDED 361 361 0 0 0 0
Reducer 2 ...... llap SUCCEEDED 1 1 0 0 0 0
----------------------------------------------------------------------------------------------
データが小さい割にMapタスクが361個も作られており、どうもdruid.segment.granularityに指定したHOURの数だけMapタスクができているようにみえます。
②簡単なクエリの検証 其の二
pv_secondまたは「__time」カラムの一致検索のクエリを比較検証しました(3回実行)。
/* Druidのマテリアライズドビュー */
select uuid, pv_hour, `__time` from mvdruid_page_views_documents_meta where `__time` = '2016-06-20 01:14:36'
/* ORCのマテリアライズドビュー */
select uuid, pv_hour, pv_second from mvorc_page_views_documents_meta where pv_second = 1466385276;
/* ORCの結合テーブル */
select uuid, pv_hour, pv_second from page_views_documents_meta where pv_second = 1466385276;
/* ORCのオリジナルテーブル */
select uuid, pv_hour, pv_second from page_views_unique_p_date_hour_insertonly where pv_date = '2016-06-20' and pv_hour = 1 and pv_second = 1466385276;
--補足: unix_timestamp('2016-06-20 01:14:36.0') = 1466385276
Druidのマテリアライズドビューへのクエリ結果
- 1回目:0.353秒
- 2回目:0.417秒
- 3回目:0.298秒
ORCのマテリアライズドビューへのクエリ結果
- 1回目:2.89秒
- 2回目:2.874秒
- 3回目:2.882秒
ORCの結合テーブルへのクエリ結果
- 1回目:4.033秒
- 2回目:4.052秒
- 3回目:4.125秒
ORCのオリジナルテーブルへのクエリ結果
- 1回目:0.568秒
- 2回目:0.528秒
- 3回目:0.477秒
一見、Druidへの一致検索が速い感じも受けますが、ORCのマテリアライズドビューとORCの結合テーブルはパーティショニングをしていないので、パーティショニングしたORCのオリジナルテーブルへの一致検索とあまり変わらない結果になりました。
パーティショニングしていないORCのテーブルとマテリアライズドビューを比べると、なぜかマテリアライズドビューへのクエリの方が若干速かったです。
③少し複雑なクエリの検証
条件を増やしてGROUP BYしたクエリを比較検証しました(3回実行)。
/* Druidのマテリアライズドビュー */
SELECT count(*) FROM (
SELECT publisher_id, pv_hour, count(*)
FROM mvdruid_page_views_documents_meta
WHERE
platform = 2 AND
geo_location like 'US>NY%' AND
traffic_source = 3 AND
`__time` >= '2016-06-15 00:00:00' AND `__time` < '2016-06-26 00:00:00' AND
source_id >= 10000 AND source_id < 12000
GROUP BY publisher_id, pv_hour
ORDER BY publisher_id, pv_hour
) t;
/* ORCのマテリアライズドビュー */
SELECT count(*) FROM (
SELECT publisher_id, pv_hour, count(*)
FROM mvorc_page_views_documents_meta
WHERE
platform = 2 AND
geo_location like 'US>NY%' AND
traffic_source = 3 AND
pv_second >= '2016-06-15 00:00:00' AND pv_second < '2016-06-26 00:00:00' AND
source_id >= 10000 AND source_id < 12000
GROUP BY publisher_id, pv_hour
ORDER BY publisher_id, pv_hour
) t;
/* ORCの結合テーブル */
SELECT count(*) FROM (
SELECT publisher_id, pv_hour, count(*)
FROM page_views_documents_meta
WHERE
platform = 2 AND
geo_location like 'US>NY%' AND
traffic_source = 3 AND
pv_second >= '2016-06-15 00:00:00' AND pv_second < '2016-06-26 00:00:00' AND
source_id >= 10000 AND source_id < 12000
GROUP BY publisher_id, pv_hour
ORDER BY publisher_id, pv_hour
) t;
/* 2テーブルの結合 */
SELECT count(*) FROM (
SELECT dm.publisher_id, pv_hour, count(*)
FROM page_views_unique_p_date_hour_insertonly pv
LEFT JOIN documents_meta dm ON pv.document_id = dm.document_id
WHERE
pv.platform = 2 AND
pv.geo_location like 'US>NY%' AND
pv.traffic_source = 3 AND
pv.pv_second >= '2016-06-15 00:00:00' AND pv.pv_second < '2016-06-26 00:00:00' AND
dm.source_id >= 10000 AND dm.source_id < 12000
GROUP BY dm.publisher_id, pv.pv_hour
ORDER BY dm.publisher_id, pv.pv_hour
) t;
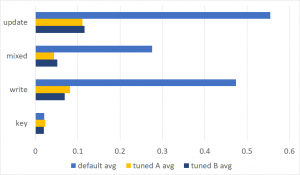
Druidのマテリアライズドビューへのクエリ結果
- 1回目:1.79秒
- 2回目:1.27秒
- 3回目:2.96秒
----------------------------------------------------------------------------------------------
VERTICES MODE STATUS TOTAL COMPLETED RUNNING PENDING FAILED KILLED
----------------------------------------------------------------------------------------------
Map 1 .......... llap SUCCEEDED 1 1 0 0 0 0
Reducer 2 ...... llap SUCCEEDED 1 1 0 0 0 0
----------------------------------------------------------------------------------------------
ORCのマテリアライズドビューへのクエリ結果
- 1回目:0.62秒
- 2回目:0.97秒
- 3回目:0.26秒
----------------------------------------------------------------------------------------------
VERTICES MODE STATUS TOTAL COMPLETED RUNNING PENDING FAILED KILLED
----------------------------------------------------------------------------------------------
Map 1 .......... llap SUCCEEDED 4 4 0 0 0 0
Reducer 2 ...... llap SUCCEEDED 19 19 0 0 0 0
Reducer 3 ...... llap SUCCEEDED 1 1 0 0 0 0
----------------------------------------------------------------------------------------------
ORCの結合テーブルへのクエリ結果
- 1回目:1.04秒
- 2回目:0.157秒 → 2回目からクエリキャッシュが効いている
- 3回目:0.19秒
1回目:
----------------------------------------------------------------------------------------------
VERTICES MODE STATUS TOTAL COMPLETED RUNNING PENDING FAILED KILLED
----------------------------------------------------------------------------------------------
Map 1 .......... llap SUCCEEDED 4 4 0 0 0 0
Reducer 2 ...... llap SUCCEEDED 19 19 0 0 0 0
Reducer 3 ...... llap SUCCEEDED 1 1 0 0 0 0
----------------------------------------------------------------------------------------------
2回目以降の実行計画:
+----------------------------------------+
| Explain |
+----------------------------------------+
| Stage-0 |
| Fetch Operator |
| Cached Query Result:true,limit:-1 |
| |
+----------------------------------------+
2テーブルの結合クエリ結果
- 1回目:20.19秒
- 2回目:0.405秒 → 2回目からクエリキャッシュが効いている
- 3回目:0.406秒
1回目:
----------------------------------------------------------------------------------------------
VERTICES MODE STATUS TOTAL COMPLETED RUNNING PENDING FAILED KILLED
----------------------------------------------------------------------------------------------
Map 1 .......... llap SUCCEEDED 4 4 0 0 0 0
Map 2 .......... llap SUCCEEDED 3 3 0 0 0 0
Reducer 3 ...... llap SUCCEEDED 19 19 0 0 0 0
Reducer 4 ...... llap SUCCEEDED 1 1 0 0 0 0
----------------------------------------------------------------------------------------------
2回目以降の実行計画:
+----------------------------------------+
| Explain |
+----------------------------------------+
| Stage-0 |
| Fetch Operator |
| Cached Query Result:true,limit:-1 |
| |
+----------------------------------------+
Druidのマテリアライズドビューへは一つずつしかMapタスクとReduceタスクが動いてなくて、ORCのマテリアライズドビューへは4個と19個動いているために速く終わっている印象。マテリアライズドビューではなくテーブルの場合は2回目からクエリキャッシュが効くので、事前にマテリアライズドビューや結合テーブルを用意しなくてもクエリキャッシュが効く前提で事足りるケースもありそうです。
今回くらいのデータサイズ(約260万件・45MB)であればクエリキャッシュが効かなくても、Hive+LLAPでは1秒未満というレスポンスも出せることがわかりました。
3. マテリアライズドビューの更新の検証
手動でマテリアライズドビューを更新
クエリ検証のついでにマテリアライズドビューの更新も検証してみます。HDP3ではマテリアライズドビューの更新は手動で行うのがデフォルトです。自動更新するやり方もあるようですが、今回はまず手動更新が簡単にできるかを試しました。
マテリアライズドビューの元のテーブルの一つにデータを追加
INSERT INTO page_views_unique_p_date_hour_insertonly PARTITION(pv_date='2019-03-03', pv_hour=10) SELECT ...;
マテリアライズドビューの元になっているpage_views_unique_p_date_hour_insertonlyに新しいダミーのパーティション(2019-03-03日 10時)のデータを適当に作ってINSERT、2598048 → 2603546件のレコードにします。
マテリアライズドビューをALTER文で手動更新
/* Druidのマテリアライズドビューを更新 */ ALTER MATERIALIZED VIEW mvdruid_page_views_documents_meta REBUILD; /* ORCのマテリアライズドビューを更新 */ ALTER MATERIALIZED VIEW mvorc_page_views_documents_meta REBUILD;
Druidのマテリアライズドビュー
- 実行時間:191.06秒
----------------------------------------------------------------------------------------------
VERTICES MODE STATUS TOTAL COMPLETED RUNNING PENDING FAILED KILLED
----------------------------------------------------------------------------------------------
Map 3 .......... llap SUCCEEDED 3 3 0 0 0 0
Map 1 .......... llap SUCCEEDED 4 4 0 0 0 0
Reducer 2 ...... llap SUCCEEDED 19 19 0 0 0 1
----------------------------------------------------------------------------------------------
ORCのマテリアライズドビュー
- 実行時間:15.56秒
----------------------------------------------------------------------------------------------
VERTICES MODE STATUS TOTAL COMPLETED RUNNING PENDING FAILED KILLED
----------------------------------------------------------------------------------------------
Map 2 .......... llap SUCCEEDED 3 3 0 0 0 0
Map 1 .......... llap SUCCEEDED 4 4 0 0 0 0
----------------------------------------------------------------------------------------------
手動更新した結果、マテリアライズドビューのレコード件数は2603546件、最新のpv_dateは2019-03-03となり、正しく更新されていることがわかりました。
クエリの中身を意識せずにALTER MATERIALIZED VIEW … REBUILDコマンドだけ打てば良いのでかなり便利です。
4. まとめ
結論
HiveからDruidを使うメリットはあまり感じられず、それほど大きなデータにならなければORCフォーマットのマテリアライズドビューを作りHive+LLAPから利用するのが思ったより良い感じ、という結果に。
集計結果をテーブルに格納してBIツールで見る、といった用途にHive+LLAP+ORCマテリアライズドビューを使うのはぴったり合いそうです。
ただ、Druidの構成や設定をチューニングしてHiveを挟まないでDruidだけで使うと良かったり、LLAPでメモリをたくさん割り当てるくらいならPresto(もしくは前に検証したPreso on YARN)の方が使い勝手が良いというケースはありそうなので、このあたりはワークロードによって見極める必要がありそうです。
LLAPについて思ったこと
LLAPの利用はLLAPデーモンが常駐することになるため、LLAPの恩恵を得ようとするとメモリをたくさん割り当てる必要があります。かなりメモリを積んだマシンを用意する必要があるのと、メモリ周りの設定が難しくなるため(たくさん影響するパラメータがあります)、デフォルトでLLAP利用になっていますが、きちんと使うにはハードルがかなり高いです。
メモリをHiveだけに使わせるわけにはいかない場合、日中はアドホックな分析などでLLAPを活用、夜間はLLAPデーモンを落としてLLAPキューをSpark処理バッチに回す、みたいな運用もありかも知れないと思いました。
課題
今回はそこまで大きなデータを用意できなかったのですが、巨大なデータをたくさん分析したりバッチ処理する環境で、LLAPやマテリアライズドビューをどう設計して実際に運用レベルまで使っていくかはやはり大きなポイントです。
参考
以前他のメンバーがDruidについてブログ「Druid を軽く試してみた話」を書いていますので、良かったらこちらも参考にしてください。
最後に
次世代システム研究室では、データ分析エンジニアやアーキテクトを募集しています。ビッグデータの解析業務など次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。
皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD