2018.07.09
スペックの違うサーバーで Hadoop クラスタを組むヘテロ構成を試す
こんにちは。次世代システム研究室のデータベース と Hadoop を担当している M.K. です。
今回も前回に引き続き Hadoop ネタです。
Hadoop クラスタ構築では、後でサーバーを増強するときにスペックが前より良くなっていたり、台数が増えてきたので数を減らすために1台あたりのスペックを良くしたりと、最初のサーバーより高スペックのサーバーを追加するケースってあると思います。
そこで、スペックが違うサーバーで Hadoop クラスタを組むヘテロ構成のときにやるべき設定を検証してみました。
今回の検証内容
前回のブログで構築した環境をそのまま利用して、以下のことを行いました。
- 最初の構築時より高スペックのサーバーを Hadoop クラスタに追加
- YARN の Configuration Group を設定
- YARN Queue の作成と Node Labels の設定
- YARN Queue と Node Labels を指定してジョブを試してみる
最初の構築時より高スペックのサーバーを Hadoop クラスタに追加
まず、前回より高スペックな GMO アプリクラウドのサーバーを2台準備します。
そしてそのサーバーを Hadoop クラスタに追加ホストとして登録し、必要な Hadoop のサービスを展開します。
サーバースペック
- 最初の構築時のスペック
- OS : CentOS 7
- 仮想 CPU : 4
- メモリ容量 : 16GB
- ディスク容量 : 320GB
- 追加するサーバーのスペック
- OS : CentOS 7
- 仮想 CPU : 10
- メモリ容量 : 60GB
- ディスク容量 : 800GB
hosts ファイルの設定
/etc/hosts ファイルを使って Hadoop クラスタを構築しているので、追加するサーバーだけでなく、すべてのサーバーで hosts ファイルを以下のように編集します。
今回追加するのは、tst-hdp-s4 と tst-hdp-s5 のスレーブノード2台です。
xx.xx.xx.99 tst-hdp-am.tst.hdptest.com tst-hdp-am xx.xx.xx.51 tst-hdp-m1.tst.hdptest.com tst-hdp-m1 xx.xx.xx.52 tst-hdp-m2.tst.hdptest.com tst-hdp-m2 xx.xx.xx.53 tst-hdp-m3.tst.hdptest.com tst-hdp-m3 xx.xx.xx.61 tst-hdp-s1.tst.hdptest.com tst-hdp-s1 xx.xx.xx.62 tst-hdp-s2.tst.hdptest.com tst-hdp-s2 xx.xx.xx.63 tst-hdp-s3.tst.hdptest.com tst-hdp-s3 xx.xx.xx.64 tst-hdp-s4.tst.hdptest.com tst-hdp-s4 xx.xx.xx.65 tst-hdp-s5.tst.hdptest.com tst-hdp-s5 xx.xx.xx.10 tst-pxc1 xx.xx.xx.20 tst-pxc2 xx.xx.xx.30 tst-pxc3
追加サーバーのセットアップ
前回のブログの手順と同じように、ホスト名の設定、ntpサーバー構築、パスワードなし SSH 認証、必要なパッケージのインストール、OS周りのセットアップを行います。
JDK の配布
Ambari を構築した tst-hdp-am サーバーにログインし、/usr/jdk64 を追加サーバーにコピーします。
cd /usr scp -pr jdk64 tst-hdp-s4:/usr/ scp -pr jdk64 tst-hdp-s5:/usr/
Ambari 管理画面からホスト追加
Ambari 管理画面にブラウザでログインして操作します。
必要に応じて tst-hdp-am ホスト の 8080 ポートを SSH トンネリングするなどしてください。
初期状態のままにしているので admin / admin でログインします。
各種の Hadoop サービスはひとまず Clients だけ展開します。
画面「Hosts」メニューから、「Actions」プルダウン > 「+Add New Hosts」を選択します。
ホスト追加のウィザードが出てくるので以下のように進めてください。
- Add Host Wizard
- Install Options
- Target Hosts ⇒追加ホストをFQDNで書く
- Host Registration Information
- Provide Your SSH Private Key to automatically register hosts ⇒これをチェックして、tst-hdp-am:/root/.ssh/id_rsa の内容を貼り付ける
- Confirm Hosts ⇒確認
- Assign Slaves and Clients ⇒追加ホストごとにここでは Clients だけ選択
- Configurations ⇒ここでは Configuration Group に Default を選択
- Install, Start and Test ⇒確認
- Summary ⇒確認
YARN の Configuration Group を設定
追加した高スペックのサーバーのリソースをきちんと利用するには、そのための YARN 設定をしないといけません。
既存の設定から何も変えないと、前のスペックにあわせた設定を引き継ぐだけなので、せっかくのリソースが無駄になってしまいます。
具体的には YARN 設定を切り分ける Configuration Group を設定します。
Configuration Group の作成とホスト登録
Ambari 管理画面の左にあるサイドメニューから、「YARN」リンク > 「Configs」タブ > 「Manage Config Groups」リンクを選択します。
ウィザードが出てきたら、以下のように進めてください。
- 左のテキストエリア下にある「+」ボタンを押して、新しい Configuration Group を作る ⇒「High-spec-201806」という設定名にします
- 新しく作った「High-spec-201806」を選択、右のテキストエリア下にある「+」ボタンを押して、登録したいホストにチェック
- 右下にある「Save」ボタンを押す
追加したホストに 必要な Hadoop サービスを展開
今回追加したいのはスレーブノードなので、以下の4つのコンポーネントを展開します。
- DataNode
- HST Agent
- Metrics Monitor
- NodeManager
HST Agent と Metrics Monitor はホスト追加時にインストール済みなので、実質追加するのは DataNode と NodeManager になります。
- DataNode を追加
- Ambari 管理画面の一番上にある「Hosts」メニューから追加ホスト (tst-hdp-s4, s5) のチェックボックスをチェック、「Actions」プルダウン > Selected Hosts > DataNodes > Add を選択、OKボタンを押す
- HDFS サービスを Restart all します
- NodeManager を追加
- Ambari 管理画面の一番上にある「Hosts」メニューから追加ホスト (tst-hdp-s4, s5) のチェックボックスをチェック、「Actions」プルダウン > Selected Hosts > NodeManagers > Add を選択、OKボタンを押す
- YARNをRestart all
新しく作った Configuration Group の YARN パラメータを設定
今回は高スペックにしたサーバーにあわせて、以下のパラメータを変更します。
- yarn.nodemanager.resource.memory-mb = 46080 ⇒このパラメータには今回物理メモリの 75% を当ててみました
- yarn.nodemanager.resource.cpu-vcores = 8 ⇒このパラメータには CPU 数の 3/4 を当ててみました (7.5 になるので四捨五入)
- YARN サービスで Restart Affected します
Ambari 管理画面の左にあるサイドメニューから、「YARN」リンク > 「Configs」タブ > Group のプルダウンで「High-spec-201806」を選択します。
yarn.nodemanager.resource.memory-mb に関しては、「Settings」タブで、Memory > Node にある Memory allocated for all YARN containers on a node のスライドバーで設定してください。
yarn.nodemanager.resource.cpu-vcores に関しては、「Settings」タブで、CPU > Node にある Number of virtual cores のスライドバーで設定してください。
Configuration Group を作ると、運用が非常に大変になるのかなと思っていましたが、実際は変更したパラメータだけ Default グループのパラメータに上書きされて他はすべて引き継ぐため、運用がそんなに大変になることはなさそうです。
YARN Queue の作成と Node Labels の設定
YARN Queue を新しく作成し、YARN Node Labels を設定して、既存サーバーと高スペックサーバーでリソースが使い分けられるようにします。
Queue の新規作成と Node Labels の有効化
Ambari 管理画面の左にあるサイドメニューから、「YARN」リンク > 「Configs」タブ > Default グループを選択します。
「Settings」タブで、YARN Features にある Node Labels と Pre-emption のスライドバーを Enable にします。
次に、管理画面の一番上にある表マークメニューのプルダウンで「YARN Queue Manager」を選択します。
画面の一番左上にある「+ Add Queue」ボタンを押し、今回は「batch-analitics」という名前のキューを追加します。
画面左上にある「Actions」プルダウンから「Save Only」を押したあと、YARN サービスで Restart Affected してください。
Ambari 管理画面から Node Labels を有効にすると、HDFS に /system/yarn というディレクトリをどうやら自動で作るみたいです。
[yarn@tst-hdp-m1 ~]$ hdfs dfs -ls /system Found 1 items drwx------ - yarn hadoop 0 2018-06-01 15:48 /system/yarn
キュー設計
今回検証目的として、図のような方針を立てました。敢えて少し複雑にしています。
default キューにはラベルなしのリソース 50%、normal-spec ラベルのリソース 50%を当てました。
一方、新たに追加した batch-analitics キューにはラベルなしのリソース 50%、normal-spec ラベルのリソース 50%、そして high-spec-201806 ラベルのリソース 100%を当てました。
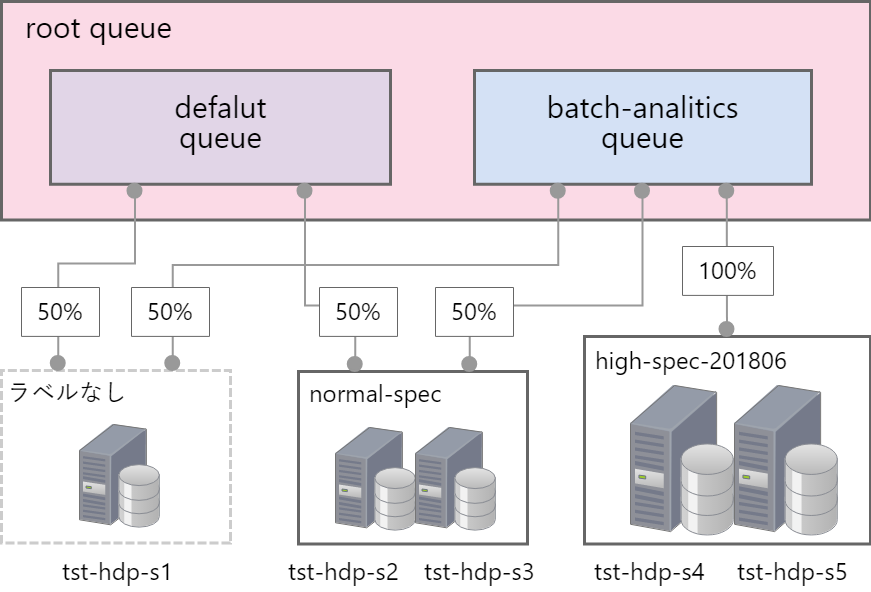
対象ホストごとに Node Labels を登録
Node Labels の登録は、管理画面ではなくコマンドで行います。
今回は tst-hdp-m1 サーバーで実施します。
キュー設計にしたがって以下のようにコマンドを実行してください。tst-hdp-s1 だけラベルなしとしました。
yarn rmadmin -addToClusterNodeLabels "normal-spec(exclusive=false),high-spec-201806(exclusive=true)" yarn rmadmin -replaceLabelsOnNode "tst-hdp-s2.tst.hdptest.com=normal-spec tst-hdp-s3.tst.hdptest.com=normal-spec kat-hdp-s4.tst.hdptest.com=high-spec-201806 tst-hdp-s5.tst.hdptest.com=high-spec-201806"
exclusive = true | false は、ラベルを割り当てたリソースを占有させるか共有可能とするかのパラメータです。
normal-spec は default キューと batch-analitics キューの両方を使うので false 、high-spec-201806 は batch-analitics キュー専用にするので true にします。
こちらの Hortonworks のドキュメントを参考にしてみてください。
YARN Queue と Node Labels のリソース配分設定
管理画面の一番上にある表マークメニューのプルダウンで「YARN Queue Manager」を選択します。
画面左上にある batch-analitics キューを選択、右画面に表示される Capacity の Enable Node Labels をチェック、スライドバーを図のように設定してください。
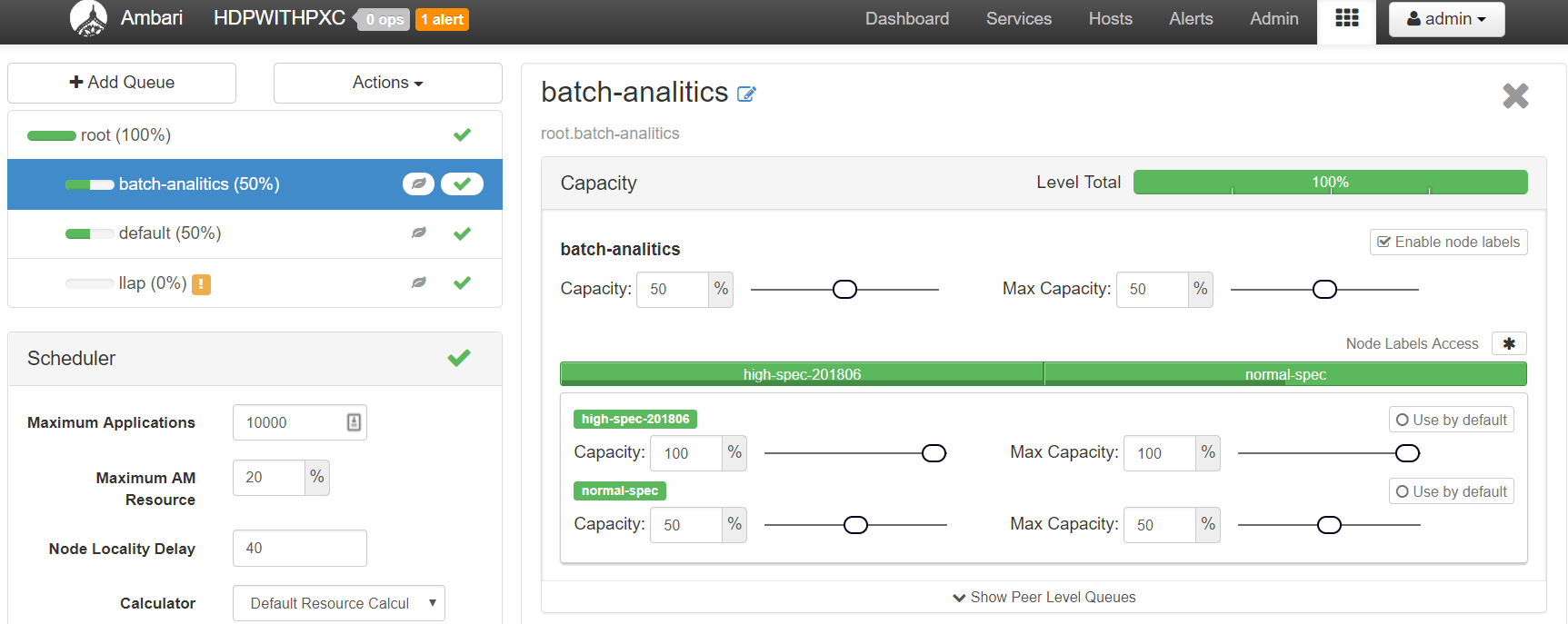
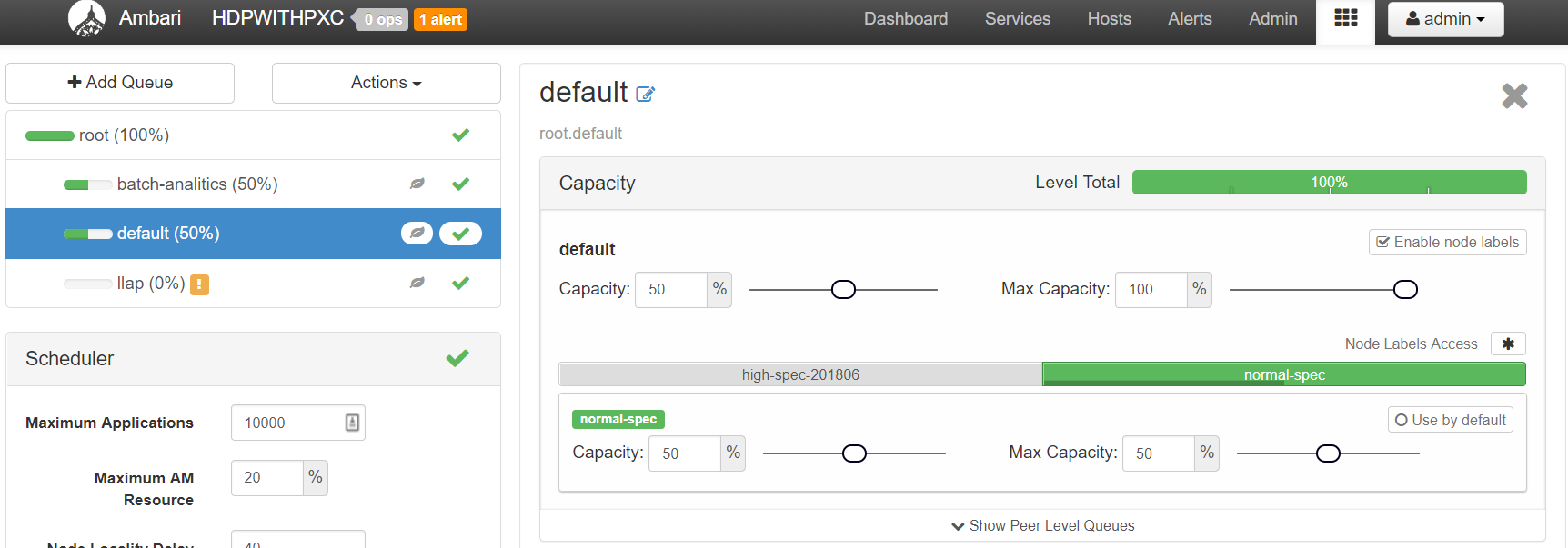
続いて、画面左上にある default キューを選択、batch-analitics キューと同じく、図のように設定してください。
YARN Queue と Node Labels を指定してジョブを試してみる
今回の設定がきちんと動くか、こちらの Hortonworks コミュニティの記事を参考に、簡単に動作検証してみます。
今回は tst-hdp-m1 サーバーで hdfs ユーザーで実施します。
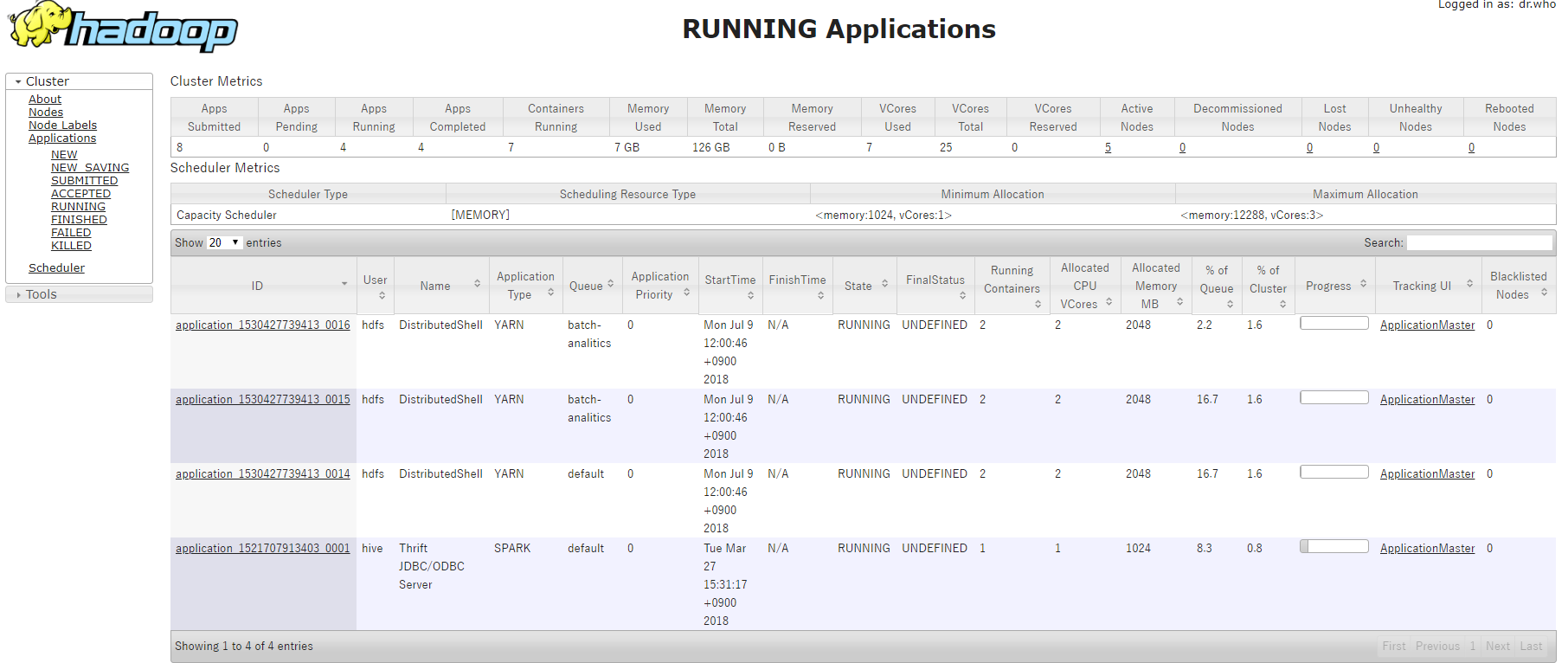
単なる sleep コマンドを敢えて YARN Queue と Node Labels を指定して実行するコマンドを3つ同時に実行します。
- batch-analitics キューと high-spec-201806 ラベルを指定して実行
hadoop jar \ /usr/hdp/current/hadoop-yarn-client/hadoop-yarn-applications-distributedshell.jar \ -shell_command "sleep 100" \ -jar /usr/hdp/current/hadoop-yarn-client/hadoop-yarn-applications-distributedshell.jar \ -queue batch-analitics \ -node_label_expression high-spec-201806 \
- batch-analitics キューと normal-spec ラベルを指定して実行
hadoop jar \ /usr/hdp/current/hadoop-yarn-client/hadoop-yarn-applications-distributedshell.jar \ -shell_command "sleep 100" \ -jar /usr/hdp/current/hadoop-yarn-client/hadoop-yarn-applications-distributedshell.jar \ -queue batch-analitics \ -node_label_expression normal-spec \
- default キューと normal-spec ラベルを指定して実行
hadoop jar \ /usr/hdp/current/hadoop-yarn-client/hadoop-yarn-applications-distributedshell.jar \ -shell_command "sleep 100" \ -jar /usr/hdp/current/hadoop-yarn-client/hadoop-yarn-applications-distributedshell.jar -queue default \ -node_label_expression normal-spec \
結果、以下の図のように設定したキューを指定して動作できていることが確認できました。
まとめ
今回試してわかったことは、YARN の Configuration Group、Queue、Node Labels をうまく使って、Apache Ranger などの権限管理と組み合わせれば、割と容易に一つの大きな Hadoop クラスタをたくさんのコンテナのように分けて運用できそうということです。
思っていたよりは複雑ということはないので、みなさんもぜひ試してみてください。
最後に
次世代システム研究室では、データ分析エンジニアやアーキテクトを募集しています。ビッグデータの解析業務など次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。
皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD

