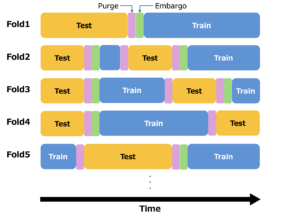
2025.04.08
AIエージェントで金融取引予測モデルを作ってみた
こんにちは、グループ研究開発本部・AI研究開発室のY. O.です。どうやら、2025年はAIエージェント元年らしいです。“自律的に(柔軟に)、環境とコミュニケーションして、タスクをこなしてくれるAI”として、旅行計画や企業分析など、さまざまな活用例が報告されています。
筆者は、AIエージェントに期待が集まる理由は以下2点だと考えています。
1. 複数タスクにまたがる人間の仕事を代替できる
→ 柔軟な自動化
2. LLMは人間の頭脳を超える(と多くが予想している)
→ イノベーション・超人間
以下では、そんな「AIエージェント」を利用して、金融取引戦略の立案(複数タスクを含んだビジネス的取り組み)を自動化する試みを紹介します。そして、人間の取引戦略を超えられるのか、を検証していきます。

TL;DR
- AIエージェントによる機械学習コードの自動生成ができた
- 日本株売買予測で一定の予測能力を確認した
はじめに
エージェントの歴史
AIエージェント!がバズワード的に広がっていますが、エージェント自体は古くから広い学問領域で研究の対象となってきました。

人間タスクをどれだけ代替できるかの指標
LLMの性能評価をする指標として様々なベンチマークが提唱されています。一方、今回の検証で行う(複数タスクにまたがる人間の仕事を代替できるのか)ような、より実世界での能力を測る指標を提唱している論文も発表されています。
図は、縦軸が「人間が実施したときのタスクの時間」、横軸が「LLMリリース年度」、となっていて、タスクを50%で完遂できるときにプロットがされる方針になっています。
この論文では、タスク完遂時間が7ヶ月で2倍になる、という結果を示していますので、人間の1日8時間労働は、2027年中頃に50%のsuccess rateで完遂できることになります。
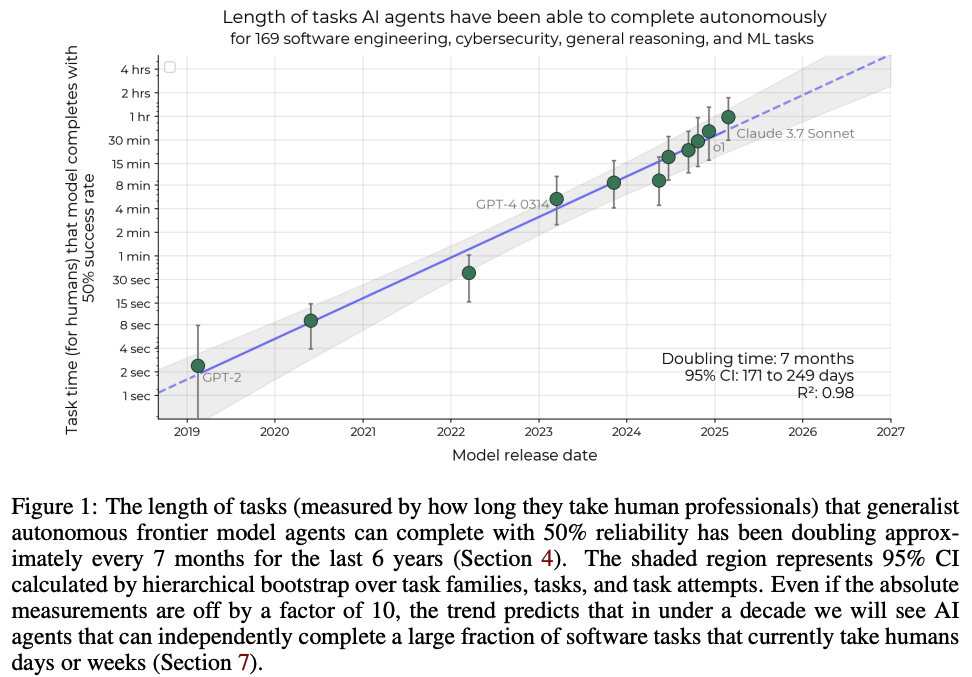
論文で述べられている結果自体も示唆深いものですが、実世界でどれだけ使えるのかが意識されたLLM評価も今後は主流になっていくと改めて認識できました。
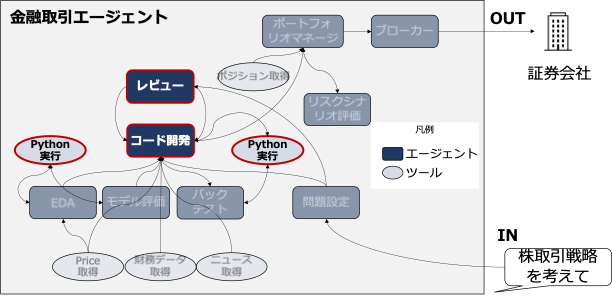
本研究の全体像
コード開発エージェントとレビューエージェントの役割分担
本研究では特に「コード開発エージェント」と「レビューエージェント」という2つの役割を設けました。
- コード開発エージェント
- クオンツ/データサイエンティストのイメージ
- 問題設定やデータ格納場所が与えられ、Pythonコードを作成する
- 実行結果やレビューコメントをもとにコードを改善する
- レビューエージェント
- チーフクオンツ/チーフデータサイエンティストのイメージ
- 問題設定/実行結果/開発コード与えられ、レビューコメントを生成する
この2者のやり取りを何度もイテレーションすることで、最終的に取引戦略のコアとなるPythonコードを完成させることを狙っています。
今回は実装しませんでしたが、将来的には「ポートフォリオを管理して売買判断を下すエージェント」「証券会社のAPIに注文を出すエージェント」などへの拡張が構想できます。
金融ドメイン知識の取り込み方
LLMは公開データセットからの学習を行っています。一方で、今回検証したい予測性能は、まだ公開されていないアルファを源泉としています。エージェントにこの知識を与えるためには、プロンプトとして関連情報を追加する、あらかじめ金融向けに特化したデータセットを扱えるようにする、などの必要があります。
本研究では原稿用紙15枚分ほどの金融データセットに対する分析方針や、機械学習プロジェクトにおけるノウハウと注意点をまとめ、システムプロンプトとしてエージェントに与えることにしました。これにより、一定のレベルで「金融知識をもった」AIエージェントがコードを書いてくれることを期待しています。このアイデアは、研究初期の結果として全く見当外れのコードを生成したことへの対応策として着想しました。結果的に、コード開発・レビューの両エージェントから、ノウハウに基づいていると明らかに見て取れる出力を観測できるようになりました。
エラー処理・デバッグプロセスの技術的課題
コード生成においては、当然エラーが出ることがあります。理想的には「エージェントが自律的にデバッグしてくれる」状態ですが、現状はなかなか難しく、以下のような問題に直面しました。(研究障壁の大部分がこのエラーとの戦いでした)
- 生成されるコードがそもそも構文エラーになっている
- ログをきちんと出力してくれず、どこでエラーが起きたか分かりづらい
- 機械学習モデルの評価方法が不適切で、結果の数値があてにならない
こうした課題については暫定的に回避することとして(人間がデバッグする・強制終了させるルールを入れる・etc.)、コード開発エージェントとレビューエージェントが相互作用し、「より良い」コードを徐々に完成させる経過を確認することにしています。
実験結果・考察
問題設定
実験では、日本株の株価データを使い、以下のような流れで株価予測モデルを作成してみました。
- 2018〜2022年の株価データを学習用データとして用意
- コード開発エージェントがPythonコードを自動生成
- レビューエージェントが合格を出すまでコードを改善
- 2023,2024年をテスト期間に設定
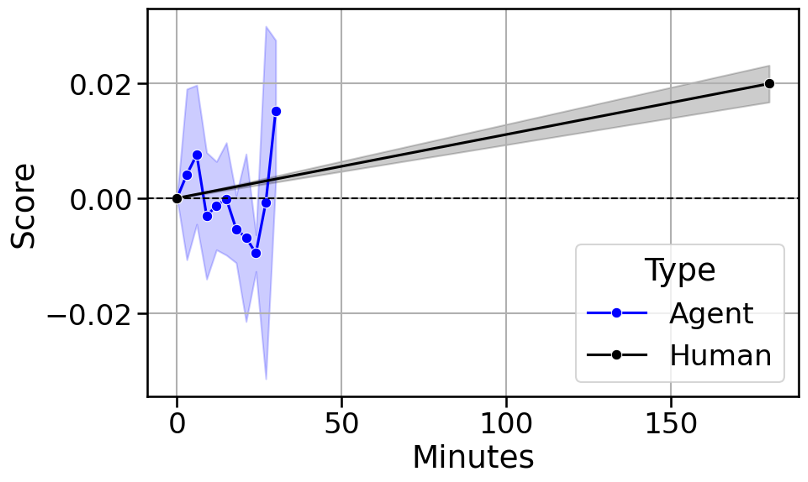
人間の仕事を代替できたのか
以下で予測精度について述べますが、少なくとも、一定レベルの精度を示すコードを、人間がイチから書くのに比べて時間が削減されるメリットを確認できました。
人間の戦略を超えられたのか
まだまだですが、予測力0という話ではありませんでした。また、生成されたコードを筆者が確認しましたが、今後の検討対象とできそうな内容も含まれていました。
まとめ・展望
以下2点が今回の研究のまとめです。
- AIエージェントによる機械学習コードの自動生成ができた
- 日本株売買予測で一定の予測能力を確認
今後の展望として以下を考えています。
- 「EDAエージェント」のコンセプトを導入することにより、金融データセットを取り扱う際の具体的な注意点をデータから抽出することができるのではないか(今回の検証では、金融データセットに対する時間普遍な専門知識を与えたが、データに基づいてモデリング戦略を変えることも精度向上に寄与するはずである)
- LLMの思考能力が向上することにより、生成されるコードの予測性能が向上するはずである
- 複数のコード開発エージェントを作成することで、マルチストラテジーな構成にすることができ、この構成は金融データセットの持つ低SN比な特性と良い相性なはずである
今回の研究を通して、ディープラーニング!AI!が銀の弾丸と思われていた2010年後半〜に似ていなぁ、と感じました。便利なライブラリ・データ解析基盤・計算力は2020年にはほとんど揃っていたましたが、データサイエンティストには、データクレンジング・データ収集・目的関数設定…、といった仕事がたくさんありました。AIエージェントの技術でもそれは繰り返される、つまり、人間がお世話をしてあげる部分が仕事として残っていくのではないか、と考えます。
さいごに
グループ研究開発本部 AI研究開発室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務などAI研究開発室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ募集職種一覧からご応募をお願いします。皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD