2021.01.06
Google Edge TPUとTensorFlow Lite(基礎篇)
こんにちは。次世代システム研究室のY.R.です。外国人です。近来Google Edge TPUとTensorFlow Liteを勉強しているところですが、こちらで習ったとこを皆さんと共有致します。宜しくお願い致します。
はじめに
エッジコンピューティング
エッジコンピューティングとは、利用者や端末と物理的に近い場所に処理装置(エッジプラットフォーム)を分散配置して、ネットワークの端点でデータ処理を行う技術の総称。多くのデバイスが接続されるIoT時代となり提唱されるようになった[1]。Google GCP[2]とAmazon AWS[3]も相関の開発を促進している。
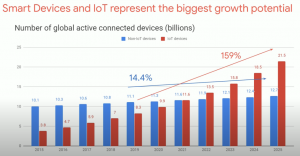
図[1]
更に、この図で示された通り将来の数年間でスマートデバイスはすごく増加すると見通す。エッジAIは注目される領域になると信じる。これから、重要なハードウェアとソフトウェアをそれぞれに紹介する。
Cloud TPUとは

図[2] Google TPU v2
Google TPUで以下のような特徴を持っている
- 巨大なオンチップRAMを備えている。メモリのアクセス時間を減らす。
- 8ビット 定量化(8 bit quantitation)。32ビットのfloating-point計算を入れ替わって8ビットのinteger 計算を採用される。ある程度の精度を犠牲したが、効率をよく改善した。
- Systolic arrayというアーキテクチャを使用する。Systolic array自体新しい技術でない。「積和演算」などの特定の操作用に配線されている。ディープラーニングによく適用できる。
- 良い冷却システムがある。リソースコストを節約できる。
現在普通のユーザはGCPを通してTPU [5]を利用できる。Cloud TPU Pod[6]というプラットホームを利用してもスーパーコンピュータのように動ける。
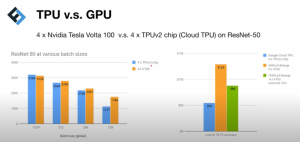
図[3]TPU vs GPU
Edge TPUとは
2019年でエッジAI に向かって、Google Coralチーム[7]はEdge TPUをリリースした。

図[4]Edge TPU 商品

図[5]
詳細的に説明したら、Edge TPUのデバイスとTensorFlow lite緊密的に繋がる。
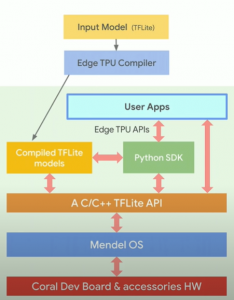
図[6]

図[7]
TensorFlow Lite
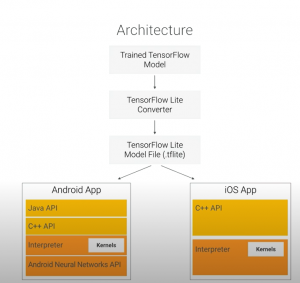
図[8]

図[9]
Edge TPUに向けて、トレーニングのTensorFlowモデル導入フローは以下のようになる。
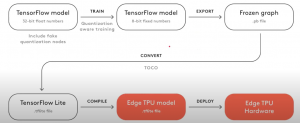
図[10]
図[11]
Google Edge TPUとTensorFlow Liteの検証
これから簡単的な検証を皆さんに共有致します。

図[12] Coral USB Accelerator
ノートPC OS: mac 10.14
Coral USB accelerator
問題点
最初、検証はCoral AIの正式な教程[9]に参考してやってみましたが、エラーに出会った。
RuntimeError: Internal: Unsupported data type: 0Node number 1 (EdgeTpuDelegateForCustomOp) failed to prepare.
対策
相関の議論[10]を参考して、最新のEdge TPU runtime(このブログを書く時点でedgetpu_runtime_20201204.zip)とTensorFlow lite libraryの互換性において問題点がると考える。議論[11]で一つ古いバージョンのEdge TPU runtime (edgetpu_runtime_20200331.zip)を発見しました。古いバージョンのEdge TPU runtimeを利用して動けるようになる!
結果
CPUバージョンとEdge TPUバージョンのMobileNet画像分類モデルの比較は以下のようになる。
CPU バージョン
python3 classify_image.py \ > --model models/mobilenet_v2_1.0_224_inat_bird_quant.tflite \ > --labels models/inat_bird_labels.txt \ > --input images/parrot.jpg
----INFERENCE TIME---- Note: The first inference on Edge TPU is slow because it includes loading the model into Edge TPU memory. 40.3ms 37.2ms 36.5ms 36.4ms 36.5ms
Edge TPUバージョン
python3 classify_image.py \ > --model models/mobilenet_v2_1.0_224_inat_bird_quant_edgetpu.tflite \ > --labels models/inat_bird_labels.txt \ > --input images/parrot.jpg
----INFERENCE TIME---- Note: The first inference on Edge TPU is slow because it includes loading the model into Edge TPU memory. 15.5ms 3.4ms 3.4ms 3.1ms 3.1ms -------RESULTS-------- Ara macao (Scarlet Macaw): 0.77734
判断結果は同じくレベルになったが、Edge TPUは10倍以上速くなる。
更に、正式な教程で紹介された通り、最大動作周波数(maximum operating frequency)を起動したら、Coral USB acceleratorは顯著に熱くなった。
感想と次の探索
TPUに感想
CPUとGPUと違ってTPUはAI特にディープラーニングのために設計された。巨大オンチップ RAM を備えているし、Systolic arrayのようなアーキテクチャも使用された。
しかし、GoogleによりTensorFlowしか支えられないし、Google GCPしかCloud TPUを使用できない。それに対して、ディープラーニングでPyTorchは人気があるし、PyTorch/XLA が出ている[12]。将来、筆者もPyTorch/XLAを 試してみたい。
次の探索
今のところ、TensorFlow LiteとEdge TPUの探索はまだ早い段階になります。これから、両方に深く研究したいと思う。
モデルについて、Mask R-CNN[13]系列の物体検知モデルとMobileBERT[14]という自然言語処理用の機械学習モデルに高い興味が持っている。
TensorFlow Liteのカーネルに深く理解して、性能をよく発揮させることに頑張る。
終わり
次世システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧からご応募をお願いします。 一緒に勉強しながら楽しく働きたい方のご応募をお待ちしております。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD





