2017.12.05
Druid を軽く試してみた話
こんにちは。次世代システム研究室で Hadoop 周辺をよく触っている T.O. です。
Hadoop 周辺をよく触っているので、最近 Hadoop 周辺を触ってきて得た話などを書いていきます。
今回は Druid を軽く試してみた話です。なお、今回は HDP 2.6.1 に含まれる Druid を試しており、これのバージョンは 0.9.2 となっているため、引用するドキュメントは 0.9.2 のものを用いています。
Druid とは何か
Druid は下記のような特徴を持ったデータストアです。
- オープンソースである
- 列指向である
- 分散処理できる
- OLAP 向けである
- 時系列のデータを保持することが前提
あくまで OLAP 向けなので、トランザクションをさばきまくる、というような使い道にはなりません。また、時系列でデータを保持することが前提となるので、そうではないデータも扱えないものと思った方が良さそうです。そのため、アクセスログやイベントログと言ったようなログの類を分析する際に用いるのが主たる用途と言えそうです。
Druid に取り込むデータの構造
Druid が扱うデータはその中身を下記の3種類に分けて扱います。
- タイムスタンプ
- ディメンション
- メトリック
すでに書いているとおり、 Druid では時系列でデータを保持することが前提となっているので、まずタイムスタンプが必須となります。
ディメンションは言うなれば集計する際の group by のキーにするような項目です。これはつまり文字通りメトリックをつくる際の次元になるわけです。
メトリックはディメンションで集計された数値です。
Druid における取り込みでは、値は集計されたものとなるので、どういう集計をするかを定義することになります。
このあとの取り込み処理の例の中でも出てきますが、メトリックは metricsSpec として定義します。
この定義において、例えば type が count ならばレコード数、 longSum なら fieldName で指定された列の値の合計を取る、というようになっています。
詳細は Druid | Aggregations にまとまっています。
さらに、データを取り込む際に、どのぐらいの粒度にするかという設定を与えられます。
queryGranularity という項目がそれですが、これを NONE にすると、元の粒度のままになりますが、例えばこれを DAY にすると、日毎に集計されたデータというのが、取り込んだデータの最小の粒度になります。
下のスクリーンショットは queryGranularity をそれぞれ NONE 、 DAY として取り込み、それらに対して Superset から Time Granularity の指定を 5 minutes に、つまり、5分ごとの推移を見るべく折れ線グラフにした場合の結果です。
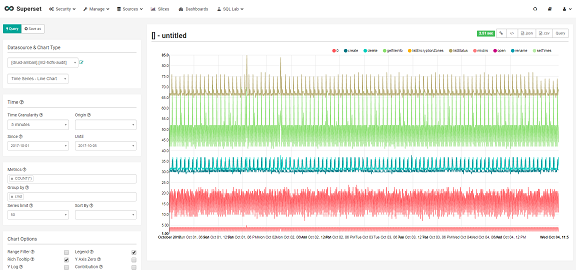
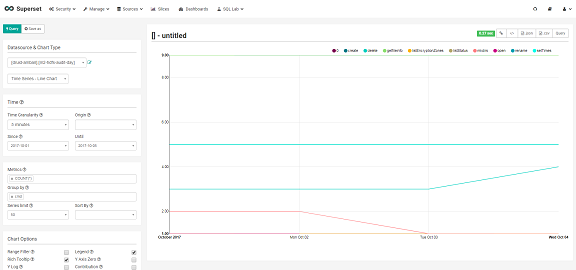
このように、 NONE (上)の方はしっかりと5分単位のデータになっている一方、 DAY (下)の方は5分単位というクエリの指定にも関わらず、日毎にまとめられた値しか取り出せません。
柔軟性を考えれば queryGranularity を NONE にして取り込むべき、という話にはなりますが、データの分析や可視化においては、しばしば、粗い粒度でも十分、ということもあります。そういう場合はどういう粒度で見られれば良いのかが明確であれば、それに合わせて取り込んでしまった方が保存するデータサイズも小さくなります。
下記は、 Druid へ取り込んだデータのディレクトリの hdfs dfs -du の結果ですが、 “m2-hdfs-audit” は queryGranularity を NONE にして取り込んだもので、 “m2-hdfs-audit-day” は “DAY” にして取り込んだものです。この例では約70倍の差があります。
12.7 M /user/druid/data/m2-hdfs-audit 182.3 K /user/druid/data/m2-hdfs-audit-day
粒度については Druid | Aggregation Granularity に詳しく書かれています。
Druid を構成するコンポーネント
Druid は複数のコンポーネントで構成されています。それらのコンポーネントがどのような構成になっているのか、については、 “druid component broker” などで画像検索すると図がいろいろ出てくるので、それで大まかな理解はできますが、ここでも簡単に触れておきます。
Druid のコンポーネントは大きく2つのまとまりにわけて捉えることができます。
ひとつは、データを Druid に取り込むためのコンポーネント群、そしてもうひとつは Druid に取り込んだデータに対して問い合わせるためのコンポーネント群です。
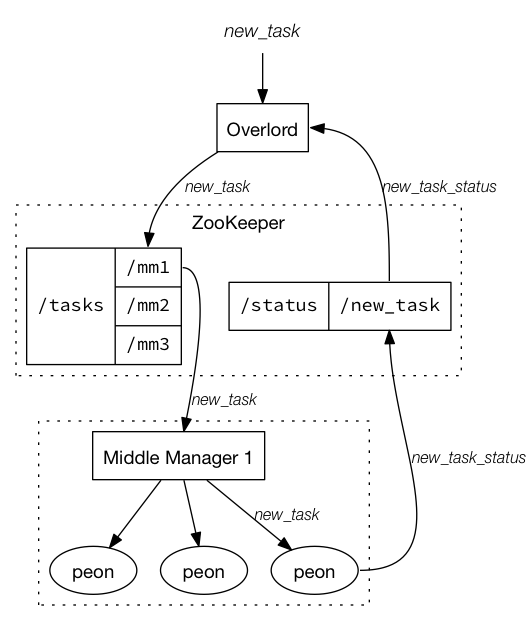
前者はまとめて Indexing Service と呼ばれており、それは Overlord, Middle Manager, Peon で構成されていて、下の図( Druid | Indexing Service から引用)のようになっています。
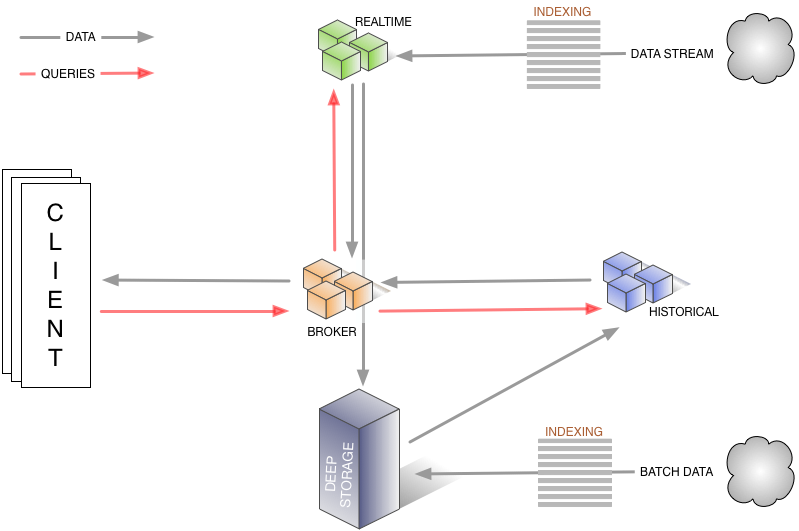
後者は Broker, Coordinator, Historical Node で構成されていて、こちらは下の図( Druid | Overview から引用)のようになっています。
なお、データのストリーミングでの取り込みに際しては、 Real-time Node と呼ばれるコンポーネントを使うような記述もありますが、ざっと読む限り、現在においては、 Tranquility Server を使うよう推奨されている雰囲気があります。この Tranquility Server は Indexing Service の Overlord の前段に置かれるもののようです。
それぞれのコンポーネントの役割も少し書いておきましょう。
Indexing Service
Overlord
Overlord はインデクシング(実質的にはデータの取り込みと言って良い)のリクエストを受け付けるサービスです。
あとでデータの取り込みの実例を出しますが、そこでも登場しています。
Middle Manager
Middle Manager は Overlord 経由で渡ってきた処理をさばく際の仲介になるサービスで、おおむね YARN の NodeManager と似たような役割と言えるものではないかと思います。
Node Manager が Container を起動するように、 Middle Manager は Peon を起動します。
Peon
Peon は、 YARN の世界の話で言えば、 Container にあたるものと思えば良いような、実際の処理を担うプロセスです。
ひとつの Peon は 1 つのタスクを実行するだけで、生存期間もそのタスクを実行している間だけ、となるようです。
・・・恐らくきっとここは高速化を考え出す頃には、動きっぱなしの Peon が出てくるのではないかと思ったりするところですが…。
問い合わせ側
Historical Node
Druid に取り込んだデータというのは、セグメントと呼ぶ塊に分けて保存されてますが、そのセグメントに対する操作を担うのが Historical Node のようです。
分散して配置することができるので、保持するセグメントが増えてきたらこの Historical Node も増やしていくことになるのでしょう。
Broker
Broker は、クライアントやアプリケーションからクエリを受け付け、受け付けたクエリをそのクエリの対象となるセグメントを持つ Historical Node に投げる役割を担っています。
Coordinator
セグメントは直接的には Historical Node が管理しているわけですが、その管理について管理するのが Cooordinator の役割のようです。
つまり、 Coordinator が Historical Node に対して新しいセグメントのロードや古いセグメントの削除、それと負荷分散のためのセグメントの移動を指示しているわけです。
Druid のために動かす必要がある外部のコンポーネント
Druid はいくつかの Druid 外のコンポーネントにも依存しています。
まず Druid は ZooKeeper を多用しており、特にデータに対する問い合わせをするコンポーネントたちは、基本的に直接コンポーネント間で通信するのではなく、 ZooKeeper を介してやりとりするような感じになっているようです。
また、セグメントのメタデータを格納するためになんらかの RDB にも依存しています。デフォルトでは組み込みで Apache Derby を使いますが、 MySQL か PostgreSQL を使うことも出来ます。 Ambari からのセットアップでも、 Derby, MySQL, PostgreSQL のいずれかを選択するようになっています。
ところで、取り込んだデータ = セグメントはどこで永続化しているのでしょうか。これの保存先が Druid において “Deep Storage” と呼ばれているもので、実体としては、ローカルのストレージか、 HDFS か AWS S3 を選べます。
ローカルのストレージでは耐障害性だけでなく拡張性も低いので、プロダクション環境で使う場合は、 HDFS か AWS S3 を選ぶべきでしょう。
今回は、 HDFS がもともとある環境なので、 Deep Storage には HDFS を使っています。
Druid へのデータの取り込み
Druid へのデータの取り込みは、バッチ処理でもストリーミング処理でも可能です。
バッチ処理で取り込む
Druid へのデータの取り込みは、下の例のように、いわゆる REST API でやります。そして、これが Druid にとってのネイティブなやり方のようです。
curl -X 'POST' -H 'Content-Type:application/json' -d @m2-hdfs-audit-indexing.json overlord_host:8090/druid/indexer/v1/task
この例での overlord_host:8090 というのは、前述の Indexing Service を構成している Overlord というコンポーネントのホスト・ポートで、ここの /druid/indexer/v1/task に m2-hdfs-audit-indexing.json というファイルをリクエストボディとして POST しているわけですが、その m2-hdfs-audit-indexing.json の中身は以下のようになっています。
{
"type" : "index_hadoop",
"spec" : {
"ioConfig" : {
"type" : "hadoop",
"inputSpec" : {
"type" : "static",
"paths" : "hdfs://hdfsns/user/hdfs/m2-hdfs-audit/hdfs-audit.log.2017-*"
}
},
"dataSchema" : {
"dataSource" : "m2-hdfs-audit",
"granularitySpec" : {
"type" : "uniform",
"segmentGranularity" : "day",
"queryGranularity" : "none",
"intervals" : [ "2017-08-20/2017-11-09" ]
},
"parser" : {
"type" : "hadoopyString",
"parseSpec" : {
"format" : "javascript",
"dimensionsSpec" : {
"dimensions": [
"loglevel",
"allowed",
"ugi",
"auth",
"ip",
"cmd"
]
},
"timestampSpec" : {
"format" : "yyyy-MM-dd HH:mm:ss,SSS",
"column" : "timestamp"
},
"function" : "function (str) { var parts = str.split(/[\\s\\t]+/); return { timestamp: parts[0] + \" \" + parts[1], loglevel: parts[2], allowed: parts[4].substring(8), ugi: parts[5].substring(4), auth: parts[6].substring(6, parts[6].length - 1), ip: parts[7].substring(4), cmd: parts[8].substring(4), src: parts[9].substring(4), dst: parts[10].substring(4), perm: parts[11].substring(5), proto: parts[12].substring(6), callerContext: (typeof parts[13] === \"undefined\") ? \"\" : parts[13].substring(14) };}"
}
},
"metricsSpec" : [
{
"name" : "count",
"type" : "count"
}
]
},
"tuningConfig" : {
"type" : "hadoop",
"partitionsSpec" : {
"type" : "hashed",
"targetPartitionSize" : 5000000
},
"jobProperties" : {
"mapreduce.map.java.opts":"-Duser.timezone=UTC -Dfile.encoding=UTF-8",
"mapreduce.reduce.java.opts":"-Duser.timezone=UTC -Dfile.encoding=UTF-8"
}
}
}
}
この内容の詳細については、 Druid | Batch Data Ingestion を読むとして、主要な設定については下記のような感じです。
| JSON Path | 説明 |
|---|---|
| $.type | 処理の種類。ここでは、 Hadoop (実際には Hadoop MapReduce )を使ってインデクシングする index_hadoop になっている。 |
| $.spec.ioConfig | 取り込むデータの情報。この例では、 HDFS 上のファイルを指定している。 |
| $.spec.dataSchema.dataSource | source と言っているが Druid 側の取り込み先の名前。 |
| $.spec.dataSchema.granularitySpec | 取り込む際の粒度の指定。詳細は後述。 |
| $.spec.dataSchema.parser | 取り込むデータにかける parser の設定。この例では JavaScript のコードで parse しているが、取り込むデータがシンプルな CSV, TSV, JSON の場合はシンプルに指定できる。 |
| $.spec.dataSchema.metricsSpec | 取り込みにより生成するメトリクスの指定。この例では単にレコード数のカウントのみを指定している。 |
| $.spec.tuningConfig | 文字通りチューニングであるが、実行環境のタイムゾーンが UTC でない場合は、ここで明示してやる必要があるようだ。 |
なお、今回の例では、 HDFS の監査ログを処理の対象としています。
ストリーミング処理で取り込む
ストリーミング処理での取り込みも可能です。ただし、最近の巷のストリーム処理エンジンが持っている exactly once はサポートしておらず、あくまでベストエフォートでの処理になるようです。
コンポーネントの解説でも触れましたが、ストリーミング処理で取り込むには、 Real-time Node を使う方法と、 Tranquility Server と Indexing Service を使う方法がありますが、前者は、ドキュメントを読む限りあまり勧められていないような印象があります。
ストリーミングで処理による取り込みについては公式ドキュメントは下記で言及されていますが、今回は試しておりません…。
Druid からのデータの読み出し
データの読み出しも、 REST API を叩くのが Druid にとってのネイティブなやり方です。従って、下記のように curl などの HTTP クライアントを使ってアクセスすることになります。
curl -X POST '<queryable_host>:<port>/druid/v2/?pretty' -H 'Content-Type:application/json' -d @<query_json_file>
詳細は Druid | Querying に書かれています。
ところで、リクエストボディに JSON ファイルを指定しているわけですが、取り込みぐらいならともかく、クエリを投げるために JSON を書きたいか、という話になります。私は書きたくありません。
幸いなことに今回利用している HDP 2.6.1 の Druid では、そのセットアップの際に、 Apache Superset もインストールされ、これが Druid へのインターフェイスも持っているので、基本的にはこれを使えば良いと思います。データの粒度の話で貼り付けたスクリーンショットはまさにその Superset によるものです。
また、様々なプログラミング言語向けのライブラリも存在しているので、コードから Druid にアクセスしたい場合は、それらを使えば良いでしょう。それらは Druid | Community and Third Party Software で確認できます。
恐らくこれらのライブラリも内部で上記の REST API にアクセスしていることだろうと思いますが、お使いのプログラミング言語向けのライブラリがあるならば、敢えて REST API を叩かずにライブラリを使ってみるのがお手軽なのだろうと思います。
この中には、 SQL でアクセスするためのライブラリの話も載っていますが、まだこれから、という感じのようです。
さらに、 Hive 経由でアクセスするという方法も一応あって、 Hive – Druid Integration に書かれているとおりに試すことはできました。
まとめ
Druid は用途が限定的ながらも、その用途 = OLAP においては、ふつうの RDB を使うよりもより時間的にも空間的にもより効率的に使うことができそうです。分散処理も可能なので、より規模の大きなデータに対応できることも魅力だろうと思います。
さらに Superset に Druid のためのビューが統合されているため、定型的な集計そしてその高速な可視化を提供したい、というような場合は、 Druid と Superset の組み合わせでお手軽に実現できるのも強みのひとつと言えるかもしれません。
また、 HDP を使っている場合は、 Ambari を使って、 Superset も含めてセットアップすることもでき、試しに導入するにしてもハードルは低い点も優れています。
最後に
次世代システム研究室では、グループ全体のインテグレーションを支援してくれるアーキテクトを募集しています。
インフラ設計・構築経験者の方、次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、
ぜひ 募集職種一覧 からご応募をお願いします。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD

