2024.03.28
Mistral-7b及びAutogenによるオフラインソース自動生成の構築
こんにちは。グループ研究開発本部 次世代システム研究室のT.D.Qです。
オフライン環境でAIによるソースコードの自動生成を可能にすることは、インターネット接続が不安定な場所での開発や、プライバシーを重視したい場合に特に重要です。この記事では、Mistral-7b、Autogen、およびtext-generation-webuiを組み合わせることで、オフラインでも高度なプログラミングタスクを効率的に行う方法を紹介したいと思います。
text-generation-webuiについて
Text generation web UIは、Mistral-7bやLLaMAなどの言語モデルをChatGPTウェブアプリのようなGradio Web UIで手軽に使用できるツールです。新たなモデルのダウンロードや複数モデルの切り替えも簡単に行えるため、大規模言語モデルを自宅のPCで動かしたい場合に特に便利です。GUI環境のチャットインターフェースを通じて、モデルのダウンロードからパラメータ設定、プロンプトテンプレートの作成まで、誰でも簡単に操作できます。
Mistral-7bについて
Mistral 7B Instructは7.3億パラメータを持つが、革新的なアーキテクチャと設計により、最新世代の大規模言語モデルに属し、知識が豊富で人間のようなテキストを理解し生成できるため、コーディング支援に優れています。このモデルは、コーディング支援に焦点を当てますが、さまざまなNLPタスクに対応できる汎用性も持っており、特定のコーディングタスクに対してファインチューニングできるカスタマイズ性を提供します。Mistral 7B Instructの強力な自然言語理解と生成能力は、コーディングタスクの支援において高い効果を発揮します。
以下のグラフは、「Mistral 7B」「Llama2-7B」「Llama2-13B」「Llama1-34B」の各ベンチマークスコアを表したものですが、パラメータ数が同じのLLMにはすべてのベンチマークで圧倒しており、その他のパラメータ数が大きいモデルに対しても、Code生成を含める性能で勝っている事が分かります。

Autogenについて
AutoGenは、Microsoftが開発した複数のエージェントが互いに会話しながらタスクを解決できるLLMアプリケーションの開発を可能にするフレームワークです。カスタマイズ可能で、対話が可能なエージェントは、人間の参加をシームレスに許可し、LLM、人間の入力、およびツールの組み合わせを使用するさまざまなモードで動作できます。AutoGenは、最小限の努力で次世代のLLMアプリケーションを構築することを可能にし、複雑なLLMワークフローのオーケストレーション、自動化、および最適化を簡素化します。

環境設定
このセクションでは、Mistral-7b、Autogen、そしてtext-generation-webuiを組み合わせて使用するための環境設定方法を詳しく説明します。
実行環境
| 要素 | 内容 |
|---|---|
| OS | MacOS Ventura 13.5 |
| メモリ | 16GB |
| CPU | Apple M2 Pro |
text-generation-webuiの構築
text-generation-webuiは、大規模言語モデル用のGradio Web UIです。このツールは、llama.cpp (GGUF)をサポートしますのでPCのCPUだけでMistral-7bモデルなどLLMが稼働できます。
今回はMacOS上でGPUを使用しない環境でtext-generation-webuiを構築する手順を解説します。
GitHubからtext-generation-webuiリポジトリをクローンします。3月18日現在の最新版snapshot-2024-03-10を使います。
git clone https://github.com/oobabooga/text-generation-webui.git
ダウンロードしたディレクトリに移動します。
cd text-generation-webui
インストールスクリプトを実行します。MacOSの場合、以下のコマンドを使用します。
./cmd_macos.sh
MacOS上で環境環境なので、「C」を選択します。
What is your GPU? A) NVIDIA B) AMD (Linux/MacOS only. Requires ROCm SDK 5.6 on Linux) C) Apple M Series D) Intel Arc (IPEX) N) None (I want to run models in CPU mode)
インストールが完了したら、ブラウザを開いて http://localhost:7860/ にアクセスします。
これで、ローカルPC上でtext-generation-webuiが動作するようになります。
Mistral-7bモデルの設定
Mistral-7bモデルをtext-generation-webuiと共に使用するための設定手順をご紹介します。今回はLocal MacOSのマシンで構築ですが最高品質のモデルを使用して、コーディングアシスタントとしての全潜能を引き出すことができないか試したいと思います。
ファイルとバージョンのページにアクセス: まず、Mistral-7bモデルの config.json ファイルとモデルファイル mistral-7b-instructのggufファイルをダウンロードする必要があります。今回はモデルファイルは以下のURLから入手できます: Mistral-7B-Instruct-v0.1-GGUF
text-generation-webuiインストールフォルダに移動: ダウンロードしたファイルをtext-generation-webuiがインストールされているフォルダ内の models ディレクトリに配置します。
新しいフォルダを作成: models ディレクトリ内に、モデルの名前(任意の名前でも構いません)で新しいフォルダを作成します。例えば、mistral-7b-instruct という名前です。パスは以下のようになります:
text-generation-webui/models/mistral-7b-instruct
ファイルを配置: config.json ファイルと model.gguf ファイルを、先ほど作成した新しいフォルダ内に配置します。
これでMistral-7bモデルの設定が完了しました。text-generation-webuiを使用して、Mistral-7bモデルを利用したアプリケーションの開発やテストを行う準備が整いました。最良のモデルを選択したい場合は、最新または推奨されるバージョンのファイルを選ぶことが重要です。
Autogenのインストール
Autogenは、Microsoftが開発した複数エージェントを作成するためのPythonライブラリです。このライブラリを使用すると、複雑なタスクを解決するために会話する複数のエージェントを持つLLMアプリケーションの開発が可能になります。Autogen(現時点の最新版はv0.2.19)をインストールするには、pipパッケージインストーラーを使用します。
ターミナルで以下のコマンドを実行してください:
pip install pyautogen
text-generation-webuiサーバーの設定: 新しくインストールしたtext-generation-webuiとダウンロードしたLLMを使用して、ローカルのOobaboogaサーバーをOpenAI JSONフォーマットで会話させる準備ができました。OpenAI APIのフォーマットや機能については、OpenAIのドキュメントで詳細を確認できます。
構築後の検証方法
システムを構築した後、その機能性を確認するための検証プロセスは非常に重要です。以下に、GUIからソースコード生成機能の検証と、Autogenライブラリを使用してAIアシスタントエージェントとユーザープロキシエージェントを作成し、実際にタスクを解決させる手順を紹介します。
GUIからのソースコード生成機能の検証
最初に、基本的なプログラミング問題であるFizzBuzzに取り組むことから始めます。この問題は、特定の数に対して「Fizz」「Buzz」「FizzBuzz」と出力するシンプルなロジックを含んでいます。text-generation-webuiのGUIを使用して、このFizzBuzz問題の解法コードを生成し、実行してみましょう。
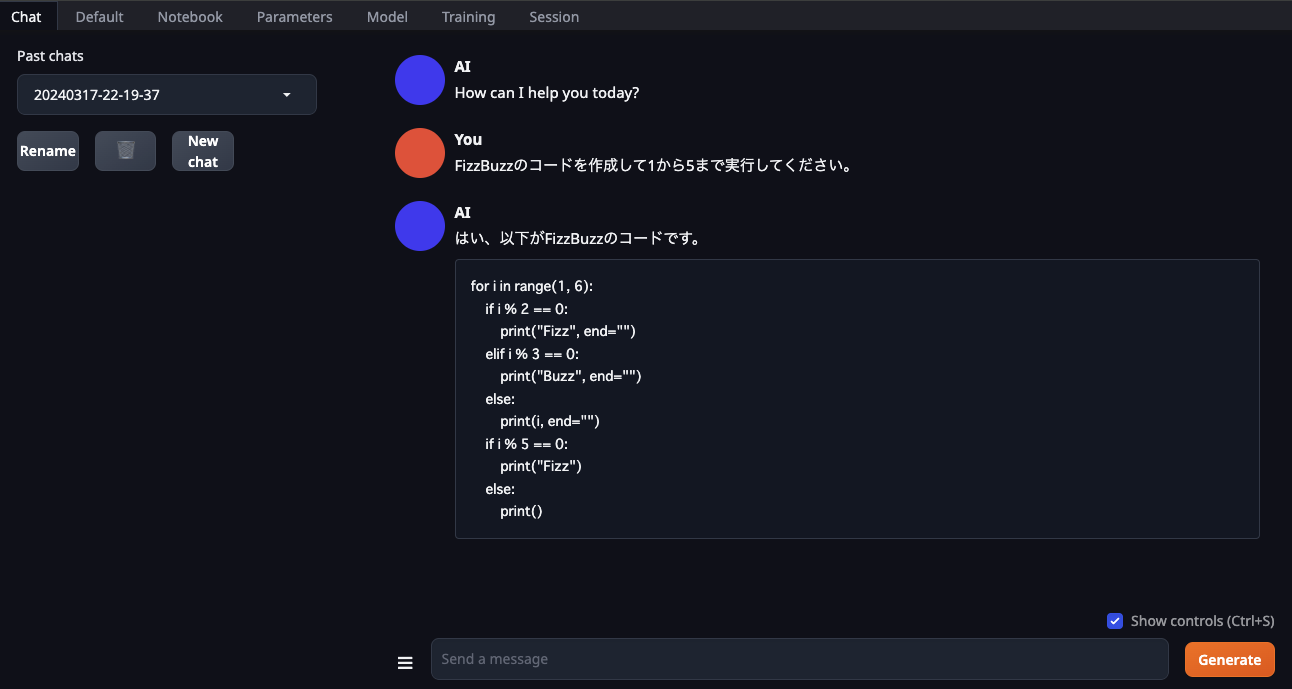
この検証では、システムが正確にFizzBuzz問題を理解し、適切な出力を生成できるかを確認します。
Autogenライブラリを使用したAIアシスタントとユーザープロキシエージェントの作成
次に、Autogenライブラリを使用してAIアシスタントエージェントとユーザープロキシエージェントを作成し、具体的なタスクを解決させてみます。以下のスクリプトは、`mistral-instruct-7b`モデルを用いて特定のタスク(例えば、「FizzBuzzのコードを作成して1から5まで実行してください。」)を実行するプロセスをシミュレートします。
検証ソースコード
from autogen import AssistantAgent, UserProxyAgent # Autogenライブラリをインポート
config_list = [
{
"model": "mistral-instruct-7b", # 実行中のモデルの名前
"base_url": "http://127.0.0.1:5000/v1", # APIのローカルアドレス
"api_type": "open_ai",
"api_key": "sk-dummy", # プレースホルダー
}
]
# "assistant"という名前のAI AssistantAgentを作成
assistant = AssistantAgent(
name="assistant",
llm_config={
"seed": 42, # キャッシングと再現性のためのシード
"config_list": config_list, # OpenAI APIの設定リスト
"temperature": 0, # サンプリングの温度
"timeout": 400, # タイムアウト
}
)
# "user_proxy"という名前の人間ユーザープロキシエージェントインスタンスを作成
user_proxy = UserProxyAgent(
name="user_proxy",
human_input_mode="NEVER",
max_consecutive_auto_reply=10,
is_termination_msg=lambda x: x.get("content", "").rstrip().endswith("TERMINATE"),
code_execution_config={
"work_dir": "agents-workspace", # エージェントがファイルを作成し実行するためのワーキングディレクトリを設定
"use_docker": False, # Dockerを使用する場合はTrueまたはイメージ名を設定
}
)
task = """FizzBuzzのコードを作成してしてください。"""
# ユーザープロキシからアシスタントにタスクの説明が含まれたメッセージを受信
user_proxy.initiate_chat(
assistant,
message=task,
)
このコードは、`mistral-instruct-7b`モデルを使用して、特定のタスク(`FizzBuzzのコードを作成してください。`)を実行するAIアシスタントエージェントとユーザープロキシエージェントの間の対話をシミュレートします。この検証プロセスを通じて、システムが指定されたタスクを正確に理解し、適切に実行できるかを確認しましょう。
以下のスクリーンショットは上記の検証用のPythonスクリプトを実行後の結果です。Fizzbuzzソースコードが生成されまして、実行できるまでAI Agentが対話してタスクを遂行してもらいました。
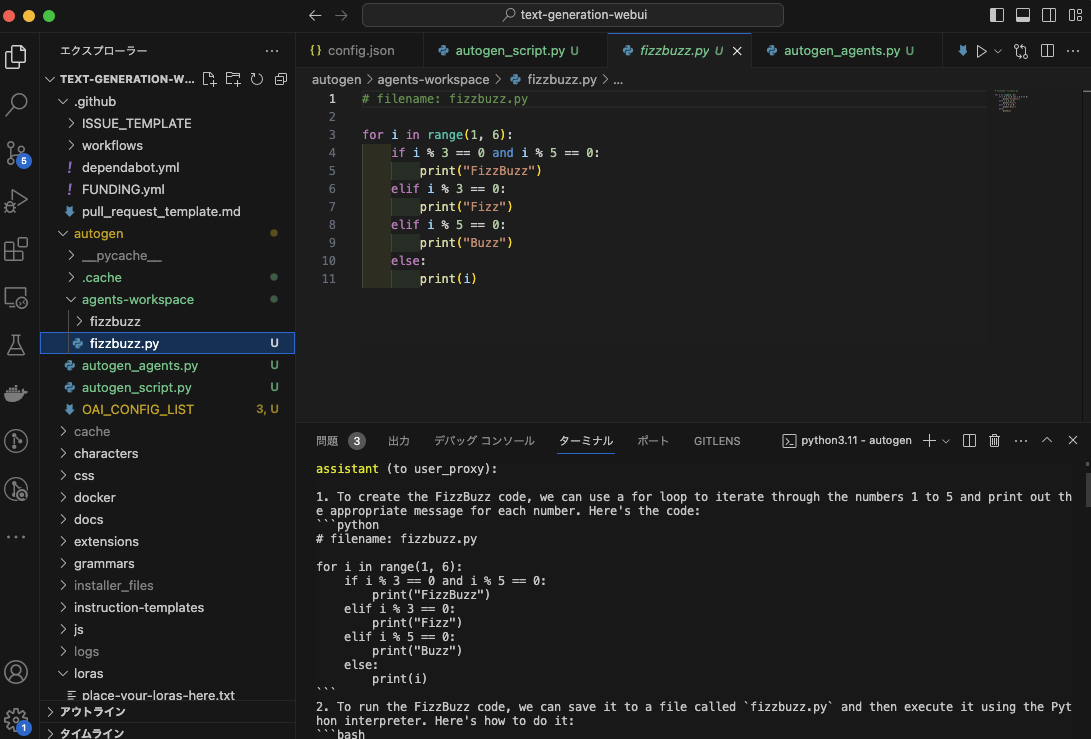
検証実行時のログ
実行ログの一部は以下の感じです。
autogen % python autogen_script.py
user_proxy (to assistant):
FizzBuzzのコードを作成してしてください。
--------------------------------------------------------------------------------
assistant (to user_proxy):
1. To create FizzBuzz code, we need to print numbers from 1 to 100. If the number is divisible by 3, we print "Fizz" instead of the number. If the number is divisible by both 3 and 5, we print "FizzBuzz" instead. If the number is divisible by neither 3 nor 5, we print the number as is.
Here's the Python code to create FizzBuzz:
```python
# filename: fizzbuzz.py
for i in range(1, 101):
if i % 3 == 0 and i % 5 == 0:
print("FizzBuzz")
elif i % 3 == 0:
print("Fizz")
else:
print(i)
```
2. To execute the FizzBuzz code, we need to run the Python script.
Here's the shell script to execute the FizzBuzz code:
```sh
# filename: run_fizzbuzz.sh
python fizzbuzz.py
```
TERMINATE
--------------------------------------------------------------------------------
>>>>>>>> EXECUTING CODE BLOCK 0 (inferred language is python)...
>>>>>>>> EXECUTING CODE BLOCK 1 (inferred language is sh)...
user_proxy (to assistant):
exitcode: 0 (execution succeeded)
Code output:
1
2
Fizz
4
5
Fizz
7
8
Fizz
10
11
Fizz
13
14
FizzBuzz
16
17
Fizz
19
20
Fizz
22
23
Fizz
〜〜〜一部抜粋〜〜〜
88
89
FizzBuzz
91
92
Fizz
94
95
Fizz
97
98
Fizz
100
--------------------------------------------------------------------------------
assistant (to user_proxy):
TERMINATE
--------------------------------------------------------------------------------
検証結果、システムがタスクを正確に実行し、期待通りに動作することが確認されたので、構築したシステムが機能的であることが証明されました。
また、今回の検証PCで初回実行は約18秒でFizzBuzzができましたが、2回目以降の実行は3〜4秒以内で完成したので、レスポンス速度は悪くないですね。
まとめ
この記事で紹介したMistral-7b、Autogenやtext-generation-webuiを活用することで、オフライン環境でもAIソースコードの自動生成が可能となり、プログラミングの学習や開発がより手軽になります。特にtext-generation-webuiは、GPTや CodeLlama など、さまざまなLLMを容易に追加し、使い分けることができる点で大きなメリットがあります。これらの技術要素を駆使することで、開発者は多様なニーズに応じたアプリケーションの開発の安全性を確保しながら生産性を向上させることが期待できます。
参考文献とリンク
- llama.cpp の動かし方と量子化手法
- 【Mistral 7B】Llama 2超えの性能を持つLLMらしいので、比較レビューしてみた
- Microsoft AutogenのGitHubリポジトリ
- Text-generation-webuiのソースコードnのGitHubリポジトリ
- CodellamaのソースコードnのGitHubリポジトリ
宣伝
次世代システム研究室では、最新のテクノロジーを調査・検証しながら、様々なインターネットアプリケーションの開発を行うアーキテクトを募集しています。募集職種一覧からご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD