2025.07.01
Cloud SQL autovacuumとHOT対応
こんにちは。次世代システム研究室のM.Mです。
担当しているWEBアプリでCloud SQL(PostgreSQL 13)を利用しているのですが、サービス成長に伴い負荷が高くなってきたため、何か対策できないかとpostgres.logを見ていました。
結果、以下のことが分かりました。
- 更新処理が多く、チェックポイントが頻発している
- autovacuum処理に数時間かかっているものが存在している
そして以下の対応を進めることにしました。
■ 更新処理が多く、チェックポイントが頻発している
チェックポイントが頻発している問題については、max_wal_sizeの見直しも考えられます。
ただ、アクセスが集中する時間帯のみで、常に発生しているわけではありませんでした。
そのため、まず、利用していない無駄なインデックスがないか、SQLの見直しで改善できないかを調査しました。
■ autovacuum処理に数時間かかっているものが存在している
データ削除運用を行い、autovacuumの頻度の見直しを行うことにしました。
今回は、その際に実施した内容と結果を紹介します。
(いくつか対応したテーブルはありますが、そのうちの1つ、テーブル名・カラム名は適当に変更して紹介しています。)
1. 現状のautovacuumの状況確認
以下の図のように、Google Cloudコンソールのロギングにあるログ エクスプローラーを利用して確認します。
すると以下の図のように約3日ごとにautovacuumが動いていることが分かりました。

以下はvacuumの実行結果となります。

571.25秒、約10分時間がかかっている状況でした。
また、78187361 remainとありますが、データ削除運用していなかったので増え続けている状況でした。pagesに関しても同様、増え続けている状況でした。
autovacuumの状況は把握できたので、続いて、データ削除運用を進めるため、不要なデータの条件を調べていきます。
ついでに無駄なインデックスがないか、実行しているSQLも調べます。
2. スキーマ定義とSQLの確認
※ 実際のテーブル定義とは違い、テーブル名はuser_test、カラム名も適当に変更しています
■ スキーマ定義
Table "public.user_test"
Column | Type |
--------------------+-----------------------------+
id | integer |
user_id | integer |
test_id | integer |
daily_test | integer[] |
first_got_test_at | timestamp with time zone |
last_got_test_at | timestamp with time zone |
index | integer |
completed_at | timestamp with time zone |
created_at | timestamp without time zone |
updated_at | timestamp without time zone |
Indexes:
"user_test_pkey" PRIMARY KEY, btree (id)
"user_test_user_id_completed_at_idx" btree (user_id, completed_at)
"user_test_user_id_idx" btree (user_id)
"user_test_user_id_last_got_test_at_idx" btree (user_id, last_got_test_at)
SQLを確認するまでもなく、不要なインデックスがあることが分かりました。
“user_test_user_id_idx” btree (user_id)
は不要ですね。
勝手な想像ですが、user_test_user_id_idxを作ったが、実装している内にuser_idとcompleted_at、user_idとlast_got_test_atで抽出することが多く、後から、user_test_user_id_completed_at_idxやuser_test_user_id_last_got_test_at_idxの複合インデックスを作った。
ただuser_test_user_id_idxを削除せず放置したといったところでしょうか・・
続いて、WEBアプリで実行しているSQLの確認をします。
■ SQL確認
WEBアプリで実行しているSQLは以下の4つでした。
1. SELECT * FROM user_test WHERE user_id = ? AND completed_at IS NULL; 2. INSERT INTO user_test(user_id, test_id, ...) VALUES (?, ?, ...); 3. UPDATE user_test SET last_got_test_at = ?, completed_at = ?, updated_at = ? WHERE id = ?; 4. UPDATE user_test SET last_got_test_at = ?, updated_at = ? WHERE id = ?;
SELECTはuser_idとcompleted_atをWHERE句に指定している。
インデックスは“user_test_user_id_completed_at_idx” btree (user_id, completed_at)を利用する想定のようです。
UPDATEはidをWHERE句に指定している。
インデックスは“user_test_pkey” PRIMARY KEY, btree (id)を利用する想定のようです。
ただ、上記スキーマ定義にあったインデックス
“user_test_user_id_last_got_test_at_idx” btree (user_id, last_got_test_at)を使う想定のSQLが存在しませんでした。
これも勝手な想像ですが、はじめは以下のようなSQLを利用して、対象データの存在チェックをしていたのかも知れません。
SELECT * FROM user_test WHERE user_id = ? AND last_got_test_at > ?;
開発の傾向として、以下のようなことがあると感じました。
- 一度リリースした後に機能拡張などの開発があった場合、プログラムのソースコードやSQLは修正するけど、インデックスが不要になったかは見直さない。
- すでに稼働しているテーブルに対してのインデックス削除は、本当に削除して問題ないのか調査も必要であり、もし調査が漏れた状態でインデックスを削除するとフルスキャンになるリスクもあるので、そのままにしておきたい。
とはいえ、現状、更新処理が多く、チェックポイントが頻発しているということもあり、不要なインデックスを削除して少しでも改善したい。
今回は調査して利用していないと判断し、以下の2つのインデックスを削除することにしました。
- “user_test_user_id_idx” btree (user_id)
- “user_test_user_id_last_got_test_at_idx” btree (user_id, last_got_test_at)
また、UPDATE文を見ると、last_got_test_atの値を更新しています。
上記、last_got_test_atが含まれるインデックスを削除することでHOTが効くようになるかもしれません。
続いてHOTの状況を確認します。(HOTについてはこちら)
3. HOTの状況確認
HOTの効いた更新になっているかは以下のSQLで確認できます。
SELECT relname,
n_tup_upd,
n_tup_hot_upd,
round(100.0 * n_tup_hot_upd / NULLIF(n_tup_upd, 0), 2) AS hot_update_ratio
FROM pg_stat_user_tables
WHERE relname = 'user_test';
以下が確認した結果になります。
relname | n_tup_upd | n_tup_hot_upd | hot_update_ratio --------------+-----------+---------------+------------------ user_test | 29371516 | 0 | 0.00
n_tup_hot_updがHOTが効いた更新件数になります。値は0なのでまったく効いていないですね・・
では、インデックス削除を行います。
4. インデックス削除
以下のようにインデックスを削除します。
DROP INDEX CONCURRENTLY user_test_user_id_idx; DROP INDEX CONCURRENTLY user_test_user_id_last_got_test_at_idx;
注意点としてはサービス稼働中なので、テーブルロックがかからないようにCONCURRENTLYをつけるぐらいでしょうか。
担当しているプロジェクトでは、通常DBマイグレーション機能を使ってDDLを適用するのですが、CONCURRENTLYはトランザクション内では利用できず、DBマイグレーションツールを使うとトランザクションを開始したうえで処理が動くので、直接上記DDLを実行して適用しました。
その後に、必ず空振りしますが、DROP INDEX IF EXISTS user_test_user_id_idx;といった形でDBマイグレーションのファイルに反映させて、知らない間にインデックスが消えていたといったことにならないようにマイグレーションのファイルと整合性が合うようにしておきました。
5. HOTの状況確認(インデックス削除後)
relname | n_tup_upd | n_tup_hot_upd | hot_update_ratio --------------+-----------+---------------+------------------ user_test | 29419876 | 6619 | 0.02
おぉ!n_tup_hot_updの値が増えてきました!HOTが効くようになりました!
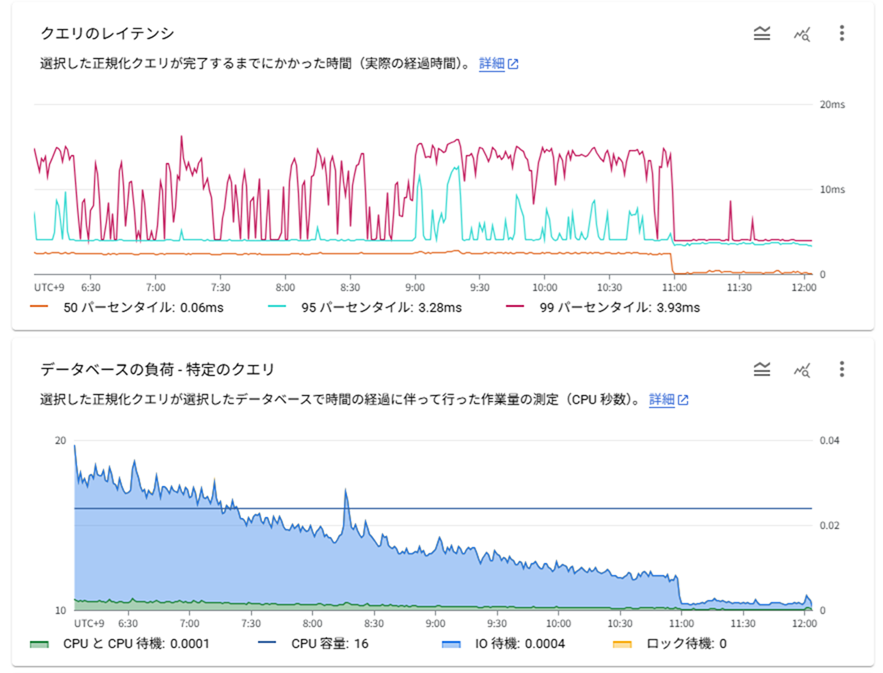
負荷が下がったことも確認できました。
話は少し逸れますが、他のテーブルでは、updated_atにインデックスをつけていることが多かったです。
WEBアプリとしてupdated_atをSQLのWHERE句に指定して利用していませんでしたが、更新SQLでは必ずupdated_atを更新するルールのため、HOTが効いていない状態でした。
その対応に少し悩みました。
WEBアプリとしてupdated_atのインデックスは利用していませんが、日次バッチのデータ抽出でupdated_atのインデックスを利用していました。
updated_atのインデックスを削除するとHOTが効くようになりますが、1日1回ではありますが、日次バッチで実行されるSQLがフルスキャンになり影響がでてしまいます。
今回は、事前にフルスキャンになった際の実行計画を確認して、許容範囲と判断したものは、updated_atのインデックスを削除することにしました。
削除できないとの判断に至ったとしても、日次バッチでupdated_atでの抽出期間が数日前以降のみであれば、部分インデックスに変えるとHOTの効果は得られなくても、WALサイズは抑えられるかもしれません。
HOTが利用されるようにSQLやインデックスを見直した結果、以下のように「更新処理が多く、チェックポイントが頻発している」というログの件数はかなり減らすことができました。
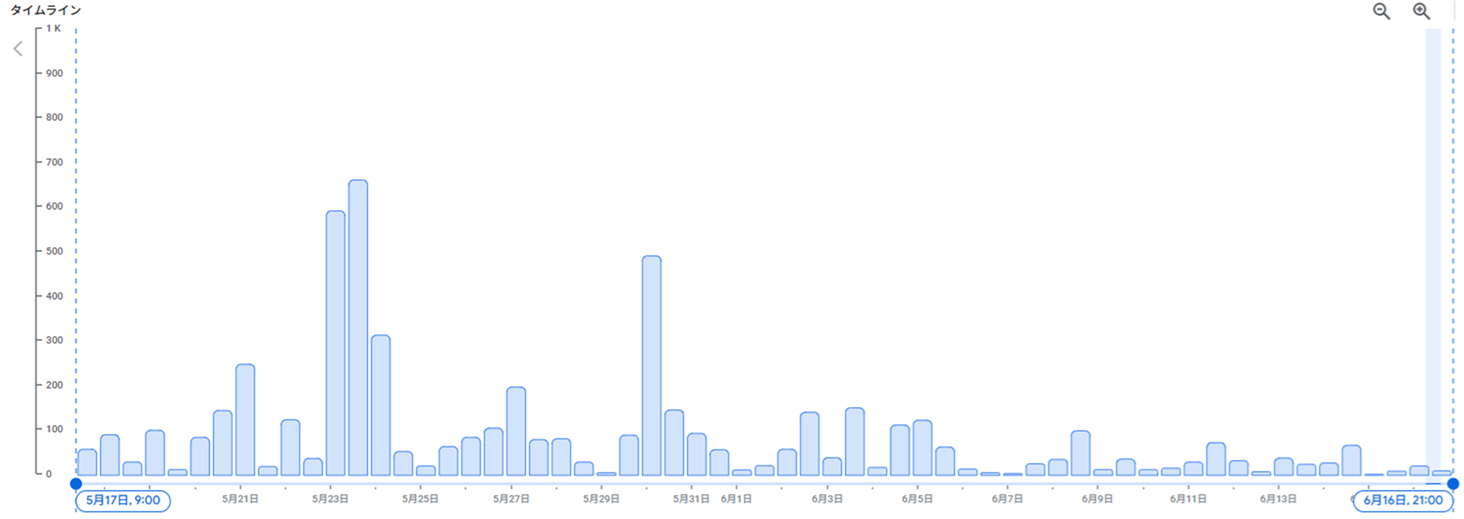
6. 不要データ削除運用開始
不要なデータは上記SQLを確認した際に、last_got_test_atが古くなっているデータはWEBアプリにて使われない不要な状態になっていると分かりました。
そのため、データ削除バッチを作成し、last_got_test_atがバッチ実行日の1週間前以前のデータを日次で削除していくことにしました。
ただ、すでに1週間前以前のデータが数千万レコード存在している状況だったので、数日分削除、手動VACUUMの繰り返しを数日間行った後に、日次データ削除バッチを動かしました。
データ削除運用をしておらず、後から大量に溜まった不要データを削除するのは本当にしんどいです。
(他のテーブルでは数億レコード溜まっているものもありました。)
不要なデータは大量に溜まる前に定期的に削除するような仕組みを入れて、autovacuumの設定を見直す。これは必須だなと反省です。
なお、手動VACUUMでは、以下のSQLを実行しつつ進めました。
■ vacuum状況確認
SELECT schemaname, relname, n_live_tup, n_dead_tup, last_vacuum, last_autovacuum, last_analyze, last_autoanalyze FROM pg_stat_all_tables where relname = 'user_test'; schemaname | relname | n_live_tup | n_dead_tup | last_vacuum | last_autovacuum | last_analyze | last_autoanalyze ------------+--------------+------------+------------+-------------+-------------------------------+--------------+------------------------------- public | user_test | 77154582 | 1551462 | | 2025-05-25 10:30:17.093634+00 | | 2025-05-11 22:48:02.975695+00
■ vacuum実行
VACUUM ANALYZE user_test;
■ vacuum状況確認
SELECT schemaname, relname, n_live_tup, n_dead_tup, last_vacuum, last_autovacuum, last_analyze, last_autoanalyze FROM pg_stat_all_tables where relname = 'user_test'; schemaname | relname | n_live_tup | n_dead_tup | last_vacuum | last_autovacuum | last_analyze | last_autoanalyze ------------+--------------+------------+------------+-------------------------------+-------------------------------+------------------------------+------------------------------- public | user_test | 77358211 | 518 | 2025-05-26 08:13:29.208491+00 | 2025-05-25 10:30:17.093634+00 | 2025-05-26 08:13:47.16041+00 | 2025-05-11 22:48:02.975695+00
分かりにくいですが、n_dead_tupが1551462から518に減りました。また、初めて手動でVACUUMを行ったので、last_vacuumがnullだったのが、2025-05-26 08:13:29.208491+00になりました。
7. 不要データ削除運用後のautovacuumの状況確認
データ削除されてデータ総数が減ったことにより、以下の図のように1日1回vacuumがされるようになりました。(データ削除運用前は3日に1回でした)
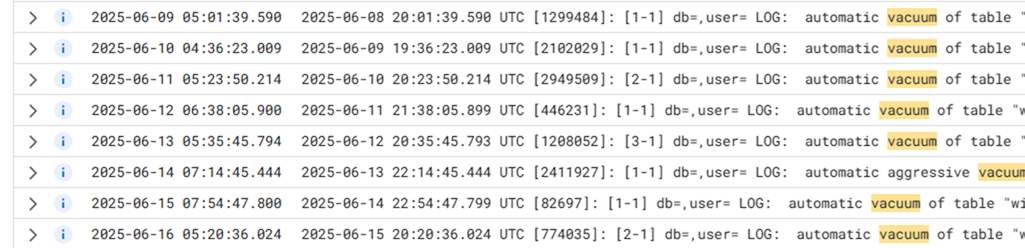
また不要データを日次で削除運用するようになり、以下の図のようにpages: 672 removedとなっており、不要になったページもしっかり削除されるようになりました。

ただ、どの程度の頻度が適切なのかをどのように決めればいいのか分からず、今後知見を増やしていきたいところではあります。
次に、autovacuumの間隔調整、fillfactorの設定でHOTをより効かせられるか確認していきたいと思います。
8. autovacuum間隔変更とHOT改善
以下のようにALTER TABLEにて設定変更を行いました。
autovacuum_vacuum_scale_factorのデフォルト値は0.2なので、0.1にすることで、1日1回vacuumが動いていたのが1日2回になる想定です。
ALTER TABLE user_test SET ( fillfactor = 90, autovacuum_vacuum_scale_factor = 0.1 );
実行してもテーブルロックがかかるような影響はないと理解はしていたのですが、稼働中テーブルに対するALTER TABLEはやはり怖いです。
今回は上記SQLを実施しても、テーブルロックがかかって処理が詰まるといった影響はなく、その実績を得られたのはよかったです。
設定されたかどうかは以下のSQLで確認できます。
select relname, reloptions from pg_class where reloptions is not null;
relname | reloptions
-------------+---------------------------------------------------
user_test | {fillfactor=90,autovacuum_vacuum_scale_factor=0.1}
■ autovacuumの間隔確認
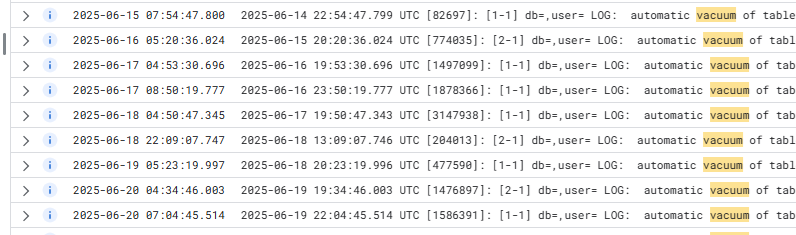
期待通り、おおよそ1日2回vacuumが実行されるようになりました。
■ fillfactor設定前のHOT割合グラフ
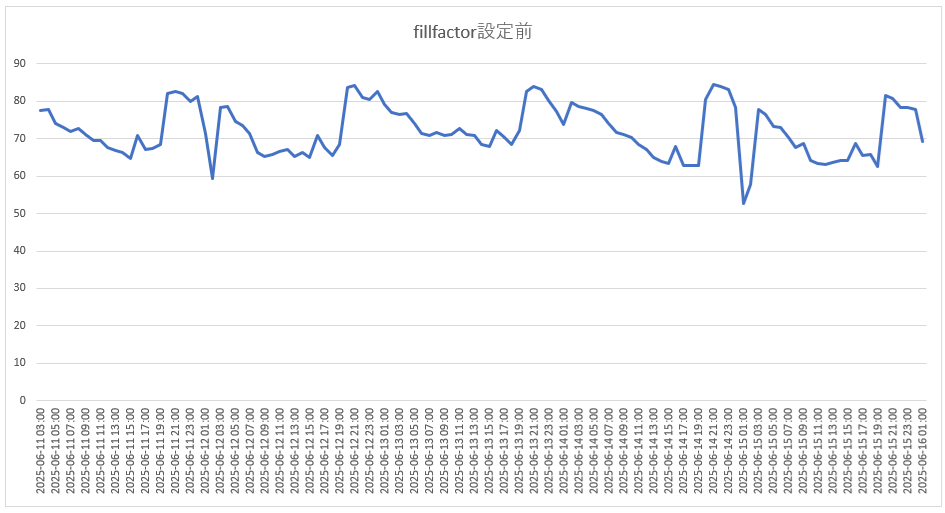
HOTが有効だった割合が60%-80%で、以下のfillfactor設定後のHOT割合グラフと比べると不安定な状態になっています。
■ fillfactor設定後のHOT割合グラフ
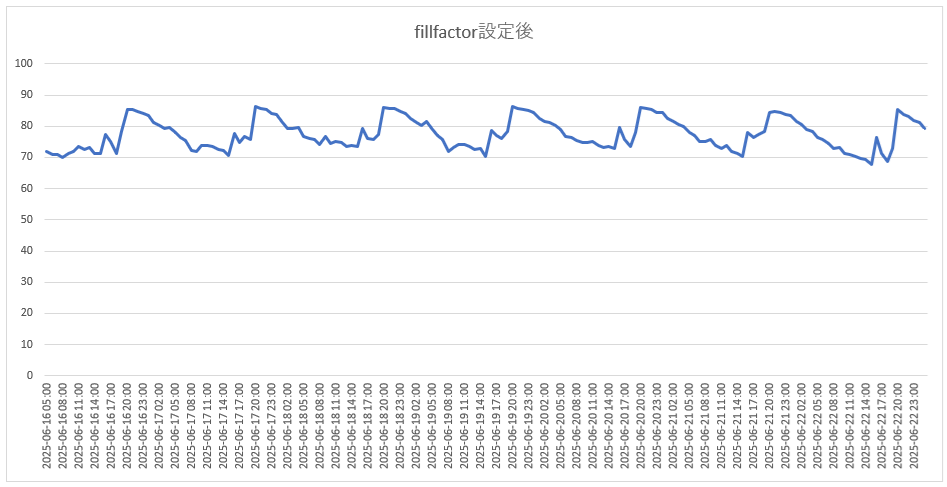
HOTが有効だった割合が、70%-90%で、傾向も安定している状態になっています。
データ削除運用やautovacuumの間隔見直しにて安定し、fillfactorの設定でHOTがより効率的に行われるようになった結果だと思われます。
9. まとめ
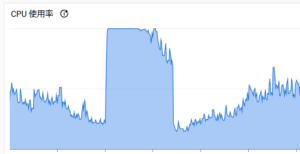
まだ対応中のものもありますが、不要なインデックス削除、HOT活用、データ削除運用とautovacuum調整にて以下の図のようにCloud SQLの負荷軽減を行うことができました。
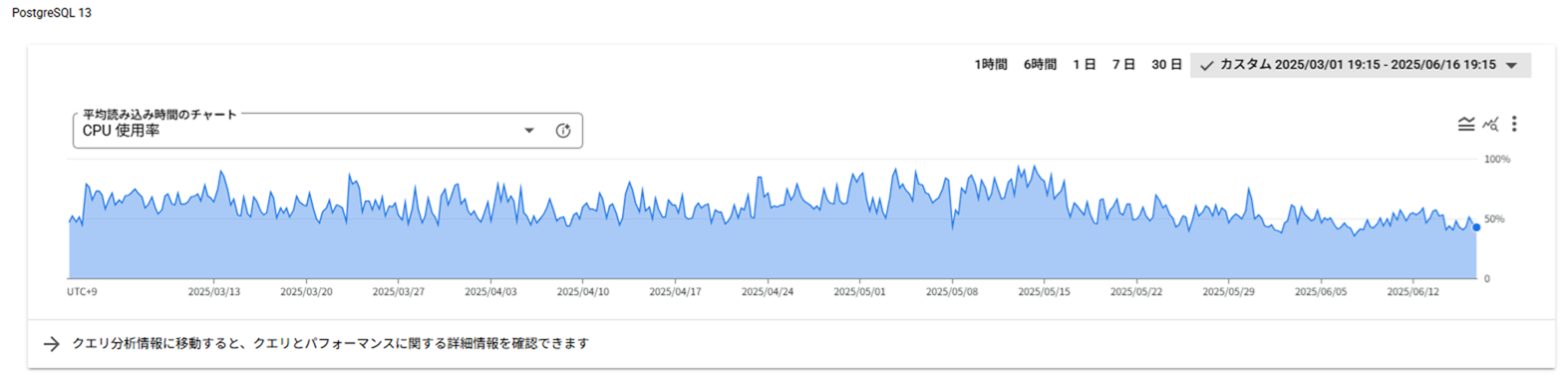
CPU使用率が50-80%でばらつきがある状態でしたが、50%-60%である程度、落ち着く状態になりました。
今回の対応で、以下の対応が重要なポイントとなると感じました。
- 不要なデータは大量に溜まる前に定期的に削除するような仕組みを入れて、autovacuumの設定を見直す
- 不要になったインデックスは放置せず、HOTを意識した更新SQLとする
ALTER TABLEによる設定変更でサービス影響がでない実績も得られたのもよかったです。
また、BigQueryでデータ分析をするため、updated_atを利用した日次データ抽出を行いBigQueryにデータ登録しているテーブルも多く、updated_atにインデックスが作られているケースが多かった。
そうするとHOTが効かなくなるため、WEBアプリで必要となるインデックス、日次データ抽出などで必要となるインデックスは分けて考えたいところです。
データ抽出などは負荷を気にせずサーバーレスエクスポートで実現できないか試してみましたが、サーバーレスエクスポートは別課金となるため、すでに大量のストレージを利用しているデータベースに対して日次運用としてサーバーレスエクスポートを利用するのは金銭的な課題が発生しそうでした。
(サーバーレスエクスポートの金額は、エクスポートされるデータ量に基づくものではなく、プライマリインスタンスのディスクサイズに基づいているので)
必要なテーブルだけレプリケーションするようなレプリカデータベースを構築したほうがいいのかも知れません。
引き続き検討していきたいと思います。
最後に、次世代システム研究室では、グループ全体のインテグレーションを支援してくれるアーキテクトを募集しています。アプリケーション開発の方、次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ募集職種一覧からご応募をお願いします。
皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD