2024.01.12
chatGPTの進化の歴史 - GPT-3からGPT-4 Advanced Data Analysisまで-
まとめ
- OpenAIのllmの変遷と進化のポイントを解説。
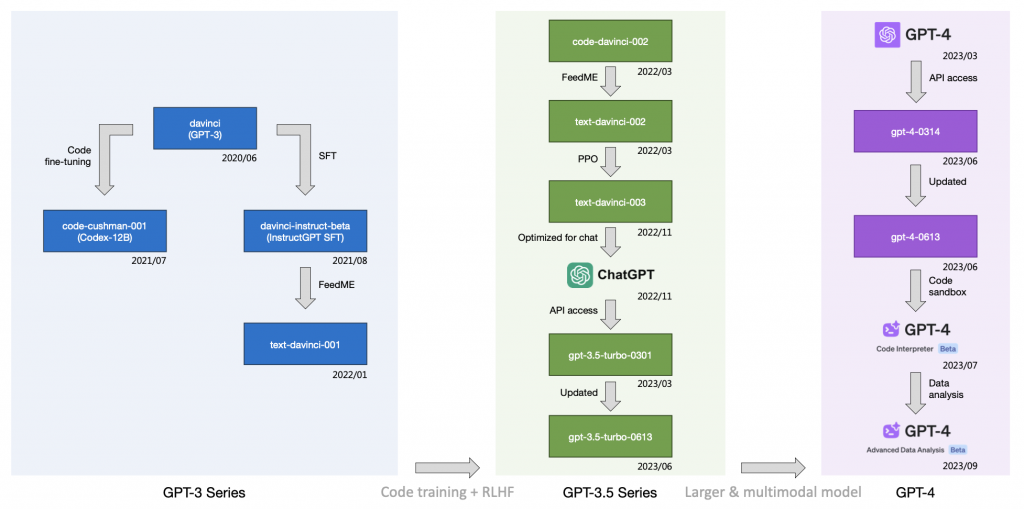
- 大きな区分(左から右の流れ)としては、GPT-3→GPT-3.5→GPT-4となっており、その度に全体的な指標が大きく向上している。
- GPT-3からGPT-3.5はコードデータの学習の影響が大きい
- GPT-3.5からGPT-4はモデルのパラメータ数の増加とマルチモーダル対応の影響が大きい。
- 小さな区分(上から下の流れ)としては後述する教師ありファインチューニング(SFT)や人間のフィードバックによる強化学習(RLHF)やCode Interpreterなどがある。
- SFTを行うことは、プラス効果があるがベースモデルの性能が向上する(下図で左から右へいく)ごとにその効果が逓減している。
- SFTやRLHFは、一発で正しいコードを書くことに大きく寄与している。
- 各種マイナーチェンジは、特定の性能指標向上に寄与している。
次世代研究室AI研のM.S.です。本日は、ByteDanceとイリノイ大学の共著である論文を紹介したいと思います。2023年12月19日にarXivに出稿されている論文で、大規模言語モデル間の比較の新しい指標と結果を提案し、その評価のソースコードをgithubに公開しています。
イントロダクション
問題提起
既存のリーダーボードなどで用いられる指標で各種のLLMを比較することには以下の問題点があります。
- 設定の一貫性の欠如
- モデルとベンチマークの網羅性の欠如
- モデルの感度への考察の欠如
設定の一貫性の欠如
プロンプトエンジニアリングなどを用いてインコンテクストラーニングを用いているかやその工夫をしているかについて、一貫性がない。
モデルとベンチマークの網羅性の欠如
OpenAIのモデルに縦断的な視点を導入することでモデルの進化の変遷をたどる。
モデルの頑健性への考察の欠如
既存の評価では、評価の設定やプロンプトの微妙な差異に対する性能の頑健性(注:原論文ではsensitivity(感度)ですが、文脈的に頑健性と訳しています。)が評価されていない。
既存の評価指標
- HELM
- Open LLM Leaderboard
- OpenCompass
- InstructEval
- AlpacaEval
- Chatbot Arena
- Chain-of-Thought Hub
これらの既存の評価指標に対して、よりよい評価指標を提案していきます。
それにしても、上記の7つの評価指標はすべて2023年に発表されたものであり、LLM界隈のスピード感には驚かされます、、。
方法
指標として、以下の7つの観点を挙げています。
- 知識(Knowledge)
- 推論(Reasoning)
- 理解(Comprehension)
- 数学(Math)
- コーディング(Coding)
- 多言語(Multilingual)
- 安全性(Safety)
それぞれ既存の研究から良さそうな評価方法をピックアップしているようです。
また評価方法は、最終出力の正誤を評価するブラックボックステストを行います。これによってホワイトボックステストでは必要となるdecoderのトークンの尤度などの内部処理を参照する必要が無くなるため、オープンソースでないllmの評価が可能となります。
実験
各種llmの評価結果をレーダーチャート図にしたのが以下となります。GPT-3とGPT-4ではGPT-4のほうが優れていることは言うまでも有りませんが、特筆すべきは、GPT-3.5-*のモデルが確実にその橋渡し的な性能となっていることです。(左図と中図)
このブログでは、GPT-3からGPT-4の変遷で何が評価指標を改善させ、何が評価指標を改善させなかったのかに焦点を当てて解説します。
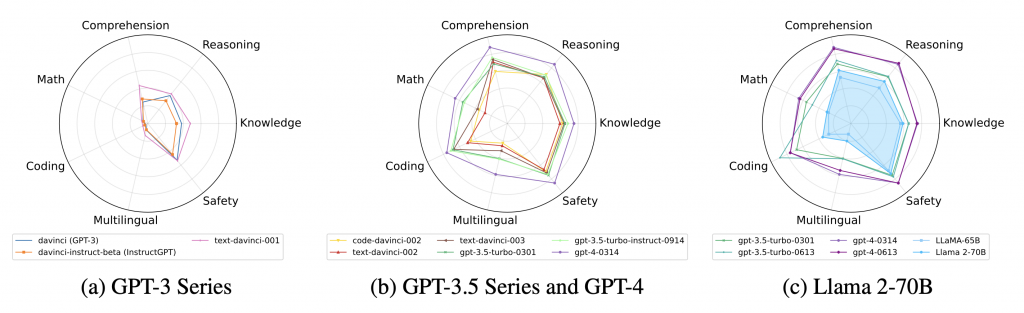
シーソー現象に関する考察
モデルのアップデート時にある指標は改善されるが、ある指標が(大きく)低下するシーソー現象が確認されています。例えば、gpt-3.5-turbo-0613はgpt-3.5-turbo-0301と比較してコーディングの指標が明確に改善されていますが、数学は大きく低下しています。
コードデータによる事前学習の影響
コードデータの学習はコーディング性能だけでなく、普遍的に性能を大きく向上させます。
GPT-3.5シリーズは、OpenAIがテキストデータだけでなくコードデータを追加で学習したcode-davinci-002によって始まったようです。そして、そのcode-davinci-002がコーディングだけでなく、普遍的に性能を向上させていることが分かります。
教師ありファインチューニング(SFT)の影響
人手で教師データを準備して、教師ありファインチューニング(SFT)を行うことは、効果があるがベースモデルの性能が向上するごとにその効果が逓減していきます。
これは、GPT-3のベースモデルdavinciにSFTを加えたtext-davinci-001は大幅に性能を向上させたのに対して、それよりも上位のGPT-3.5のベースモデルであるcode-davinci-002にSFTを加えたtext-davinci-002はほとんどの指標が改善されていません。
この傾向は他のオープンソースモデルでも確認されているようです。
ここから、SFTで必要となる人件費の費用対効果は、モデルが強力になっていくにつれ、逓減されていくといえるでしょう。
人間のフィードバックによる強化学習(RLHF)
RLHFは、主要な指標の性能向上に直接寄与していません。
SFTモデルtext-davinci-002の上に、RLHFを適用したモデルであるtext-davinci-003は、ベースモデルcode-davinci-002と同等程度の性能です。
コーディングへのSFTとRLHFの影響
それでは、SFTやRLHFが無意味かというとそうではなく、少ない試行回数で高い性能を出すことに大きく寄与します。
コーディングの性能について、LLMの温度パラメータなどを固定して、何回の試行回数で成功するか(pass@k)を測定したところ、SFTやRLHFを加えたモデルはそうでないモデルと比較して、pass@100の性能はわずかに低下しますが、pass@1の性能が大きく向上します。これは、1回でバグのないコードを書く能力が向上しているということを意味しています。
総じてSFTやRLHFは、特に計算資源の制約があり弱いベースモデルを使う必要がある場合は有効になるといえます。
ショット数の影響
インコンテキストラーニングのショット数は大きいほど性能が向上しますが、その効果はモデルの性能が向上するにつれて逓減していきます。
特にgpt-4-0314は1ショットと25ショットで性能指標がほとんど変化しません。これは、GPT-4のモデルはほとんどのタスクに対して1ショットの例がうまくいくことを示しています。
Chain-of-Thoughtの影響
Chain-of-Thought(CoT)とは、llmが複雑な問題を分割して逐次的に処理をしていくことですが、このChain-of-Thoughtは推論性能を大きく向上させます。
Webバージョンのアップデートの影響
OpenAIの、古いAPIモデル(例えばgpt-4-0613)は変更されていないモデルに固定されていますが、Webバージョンのモデルは常にアップデートされ続けており、その差が確認されています。特に最新のGPT-4 Advanced Data Analysis(旧Code Interpreter)がコーディングベンチマークのパフォーマンスを大幅に向上させています。
プロンプトへの頑健性の影響
プロンプトの僅かな差によってモデルの性能が大きく変化すると問題ですが、Llama 2-70Bなど一部のモデルでは、プロンプトへの頑健性が低いことが分かりました。
しかし、特にモデルの強さとプロンプトへの頑健性の間の相関は発見されなかったようです。
感想
OpenAIのモデルが縦断的にまとめられていて、とても理解しやすかったです。
SFTの効果やショット数の効果がモデルの性能向上とともに逓減していくことは、「人手による工夫はモデルの性能向上によって、だんだん通用しなくなっていく」という共通的なテーマがあると感じています。
領域は変わりますが、将棋AIでも類似の現象が起きており、一昔前は機械学習を用いたモデルであっても、定跡(人間が培ってきた基本)は別で学習する必要が有りましたが、近年ではそのような工夫をせずに単に自己強化学習のみでモデルを作成することが主流となっています。
人類の工夫を、計算資源の力が圧倒的に凌駕する時代は近いかもしれません。
参考文献
最後に
グループ研究開発本部 AI研究開発室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務などAI研究開発室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ募集要項一覧からご応募をお願いします。 一緒に勉強しながら楽しく働きたい方のご応募をお待ちしております。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD