2022.01.11
GKE及びGCSを用いてSpark on K8s, Delta Lakeデータ解析基盤を構築してみた
こんにちは。次世代システム研究室のT.D.Qです。
ビッグデータ分析は、データドリブン経営を実現するうえで欠かせない要素であり、市場ニーズの変化が著しい近年では特に需要を増しています。Google Cloudにはビッグデータ向けのDataProcサービスがありまして、GCP上にHadoopやSparkを使った大規模データを取り扱うための環境構築をより簡単に行うために作られました。ですが、場合によってはこのサービスの料金が大量発生してしまうので、Dataproc及びDataproc Metastoreを使わずにGCP上にデータ解析基盤を作れるか今回の記事で検証したいと思います。
今回やりたいこと
- GKE上にApache Sparkクラスターを構築したい
- GCS上にDelta Lakeを構築できるようにしたい
- Delta lakeのHiveメタストアを構築して使いたい
- 構築したSparkクラスターにてDelta Lakeから抽出・永続化できるようにしたい
GKE上にK8sクラスター作成
GKEの概要
Google Kubernetes Engine (GKE)は、 Google Cloud (GCP)上で提供されている Kubernetes のマネージドサービスです。マスターノードは GKE が管理を行うため、ユーザー側は管理の必要がありません。
GKEはコンソールを利用してクラスターを容易に構築でき、負荷に応じたノードの自動スケーリングも可能となっています。また、 Google Cloud (GCP)のサービスアカウントや IAM を連携して権限を制御するなど、セキュリティを強化するための機能も多く実装されています。
次の図は、GKE 内のゾーンクラスタのアーキテクチャの概要を示しています。

GKEについて詳しく知りらい方はこちらのページをご参照ください。
GKE上にK8sクラスター作成
GKE上にK8sクラスターを作成するため、Googleは複数の方法をサポートしています。google-cloud-sdkを利用するTerraformやGcloudコンソール、GKEのWEB画面で作成できます。主なステップは以下の4ステップですね。
- Google Cloudで使うGoogleアカウントのセットアップ
- Kubernetes Engine APIを有効化する
- Gcloudコマンドのインストールとkubectlのインストール
- Google Container Engine上にKubernetesのクラスタを構築
K8sクラスター作成手順はインターネットで公開しているブログは結構あるので今回の記事は詳細な説明を割愛します。
自前のMetaStoreを構築
データレイクでオープンソース テクノロジーを使用している場合、信頼できるメタストアとしてビッグデータの処理用に Hive メタストアをすでに利用したことがあるかもしれません。Hive メタストアは、オープンソースのデータシステムがデータ構造を共有するために使用するメカニズムとして標準化されています。次の図は、Hive メタストアを中心にすでに構築されているエコシステムの一部を示しています。
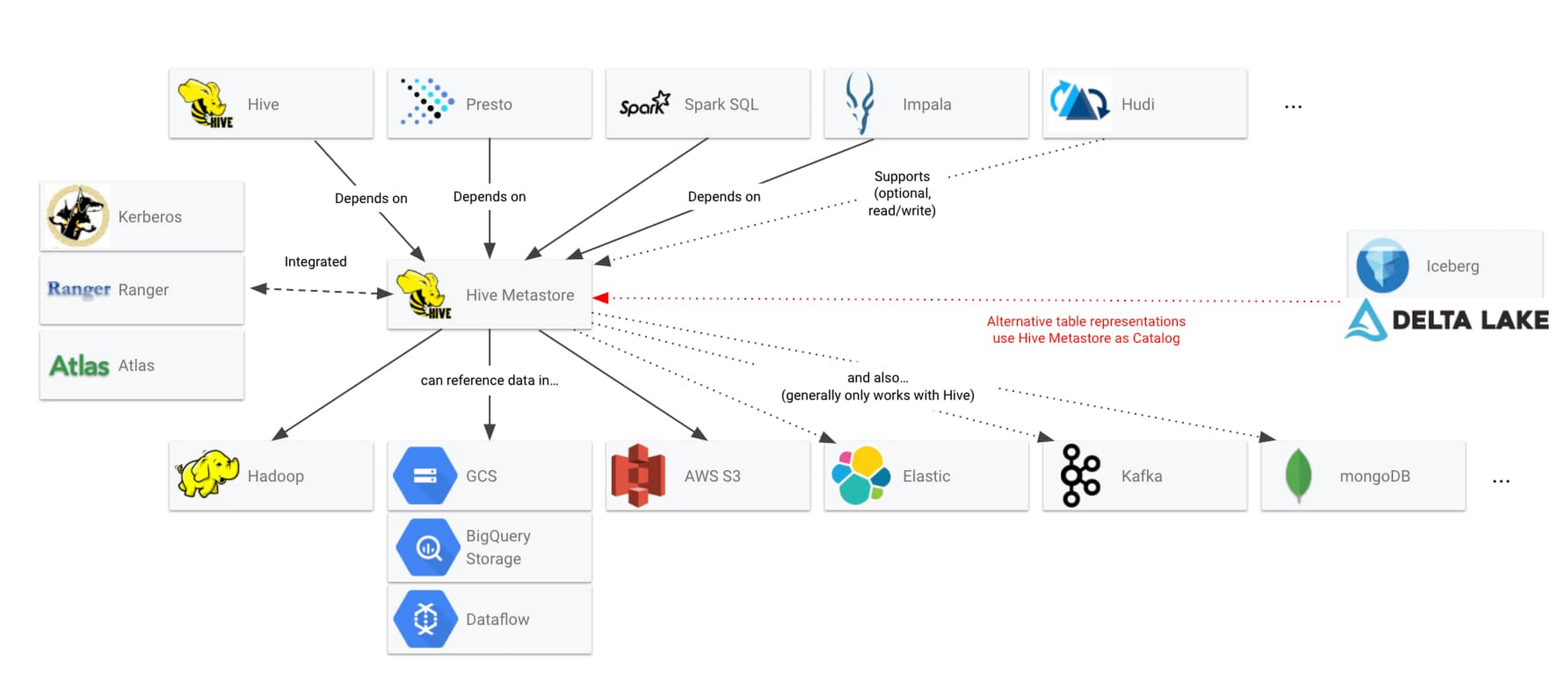
特にSparkはテーブルをHiveと連携してデータ基盤のメタデータを管理することで色々便利ですので今回はMySQLでHive Metastoreを構築したいと思います。
Secret及びConfigMapを作成
以下の感じでMySQLのSecret情報及び設定情報を定義しておきます。
ファイル名はmetastore_configmap_secret.ymlとします。
---
apiVersion: v1
kind: Secret
metadata:
name: mysql-secret
data:
MYSQL_ROOT_PASSWORD: 0YXb3JlX3Jxxxxx
MYSQL_DATABASE: bW0YXN0b3JlX2Rhxxxxx
MYSQL_USER: 0YN0b3JlX3VzZIxxxxxx
MYSQL_PASSWORD: bYXN0b3Jl3xxxxx
---
apiVersion: v1
kind: ConfigMap
metadata:
name: mysql-config-file
data:
custom.cnf: |
[mysqld]
default_authentication_plugin=mysql_native_password
character-set-server=utf8mb4
[client]
default-character-set=utf8mb4
※Secretの値にはbase64エンコードされた値を入れておく必要があります。
echo -n "<TEXT>" | openssl enc -e -base64
MySQLの設定に必要なConfigMapとSecretをapplyしておきます。
kubectl apply -f metastore_configmap_secret.yml
MetaStore用のServiceを作成
ファイル名はmetastore_service.ymlとしましょう。
---
apiVersion: v1
kind: Service
metadata:
name: mysql
spec:
ports:
- port: 3306
selector:
app: mysql
clusterIP: None
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: mysql
spec:
selector:
matchLabels:
app: mysql
replicas: 1
serviceName: mysql
template:
metadata:
labels:
app: mysql
spec:
containers:
- image: mysql:8.0.15
name: mysql
ports:
- containerPort: 3306
name: mysql
envFrom:
- configMapRef:
name: mysql-config-file
- secretRef:
name: mysql-secret
volumeMounts:
- name: mysql-persistent-storage
mountPath: /var/lib/mysql
subPath: mysql
- name: mysql-config-volume
mountPath: /etc/mysql/conf.d/custom.cnf
subPath: custom.cnf
volumes:
- name: mysql-config-volume
configMap:
name: mysql-config-file
volumeClaimTemplates:
- metadata:
name: mysql-persistent-storage
spec:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 1Gi
kubectl apply -f metastore_service.yml
Metastoreの動作確認
MySQLのMetastoreのPodにSSHしてMetastoreが稼働しているか確認したいと思います。
tranduc_quy@cloudshell:~/metastore (evident-time-3366xx)$ kubectl exec -it mysql-0 -- /bin/bash root@mysql-0:/# mysql -u metastore_username -p Enter password: Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 14 Server version: 8.0.15 MySQL Community Server - GPL Copyright (c) 2000, 2019, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | metastore_database | +--------------------+ 2 rows in set (0.00 sec) mysql> use metastore_database; Database changed mysql> show tables; Empty set (0.00 sec)
問題なく動いていますね。
Hive Metastoreのテーブルを作成
テーブルが作成されてないのでHive Metastoreのテーブルを作成しましょう。Spark3.1.2はHive2.3.7を使っているので、Hive2.3.7のMetastore SQLを使った方が良さそうですね。
以下のコマンドでHive Metastoreのテーブルを作成しましょう。
mysql -u metastore_user -p metastore_database < hive-schema-2.3.0.mysql.sql mysql -u metastore_user -p metastore_database < hive-txn-schema-2.3.0.mysql.sql mysql> use metastore_database; Reading table information for completion of table and column names You can turn off this feature to get a quicker startup with -A Database changed mysql> show tables; +------------------------------+ | Tables_in_metastore_database | +------------------------------+ | AUX_TABLE | | BUCKETING_COLS | | CDS | | COLUMNS_V2 | | COMPACTION_QUEUE | | COMPLETED_COMPACTIONS | | COMPLETED_TXN_COMPONENTS | | DATABASE_PARAMS | | DBS | | DB_PRIVS | | DELEGATION_TOKENS | | FUNCS | | FUNC_RU | | GLOBAL_PRIVS | | HIVE_LOCKS | | IDXS | | INDEX_PARAMS | | KEY_CONSTRAINTS | | MASTER_KEYS | | NEXT_COMPACTION_QUEUE_ID | | NEXT_LOCK_ID | | NEXT_TXN_ID | | NOTIFICATION_LOG | | NOTIFICATION_SEQUENCE | | NUCLEUS_TABLES | | PARTITIONS | | PARTITION_EVENTS | | PARTITION_KEYS | | PARTITION_KEY_VALS | | PARTITION_PARAMS | | PART_COL_PRIVS | | PART_COL_STATS | | PART_PRIVS | | ROLES | | ROLE_MAP | | SDS | | SD_PARAMS | | SEQUENCE_TABLE | | SERDES | | SERDE_PARAMS | | SKEWED_COL_NAMES | | SKEWED_COL_VALUE_LOC_MAP | | SKEWED_STRING_LIST | | SKEWED_STRING_LIST_VALUES | | SKEWED_VALUES | | SORT_COLS | | TABLE_PARAMS | | TAB_COL_STATS | | TBLS | | TBL_COL_PRIVS | | TBL_PRIVS | | TXNS | | TXN_COMPONENTS | | TYPES | | TYPE_FIELDS | | VERSION | | WRITE_SET | +------------------------------+ 57 rows in set (0.00 sec)
ここでHive Metastoreを構築できました。
データ分析基盤のDockerfileを実装
Apache Sparkのインストール
今回はSparkの最新版(3.1.2)を使いたいのでこのバージョンでDocker Imageをビルドします。
もちろん他のSparkバージョンを使いたいときはそのバージョンを指定してDocker Imageをビルドできますが、今回はDelta Lakeのデータレイクを構築していくのでDelta LakeがサポートするSparkバージョンを考慮する必要がある。現時点はSparkの最新バージョンが3.2.0ですが、Delta Lakeの最新バージョンはこのSparkバージョンをまだサポートしていないので、3.1.2にしました。
# Spark dependencies
# Default values can be overridden at build time
# (ARGS are in lower case to distinguish them from ENV)
ARG spark_version="3.1.2"
ARG hadoop_version="3.2"
ARG spark_checksum="2385CB772F21B014CE2ABD6B8F5E815721580D6E8BC42A26D70BBCDDA8D303D886A6F12B36D40F6971B5547B70FAE62B5A96146F0421CB93D4E51491308EF5D5"
ARG openjdk_version="11"
ENV APACHE_SPARK_VERSION="${spark_version}" \
HADOOP_VERSION="${hadoop_version}"
RUN apt-get update --yes && \
apt-get install --yes --no-install-recommends curl \
"openjdk-${openjdk_version}-jre-headless" \
ca-certificates-java && \
apt-get clean && rm -rf /var/lib/apt/lists/*
# Spark installation
WORKDIR /tmp
RUN wget -q "https://archive.apache.org/dist/spark/spark-${APACHE_SPARK_VERSION}/spark-${APACHE_SPARK_VERSION}-bin-hadoop${HADOOP_VERSION}.tgz" && \
echo "${spark_checksum} *spark-${APACHE_SPARK_VERSION}-bin-hadoop${HADOOP_VERSION}.tgz" | sha512sum -c - && \
tar xzf "spark-${APACHE_SPARK_VERSION}-bin-hadoop${HADOOP_VERSION}.tgz" -C /usr/local --owner root --group root --no-same-owner && \
rm "spark-${APACHE_SPARK_VERSION}-bin-hadoop${HADOOP_VERSION}.tgz"
WORKDIR /usr/local
# Configure Spark
ENV SPARK_HOME=/usr/local/spark
ENV SPARK_OPTS="--driver-java-options=-Xms1024M --driver-java-options=-Xmx4096M --driver-java-options=-Dlog4j.logLevel=info" \
PATH="${PATH}:${SPARK_HOME}/bin"
RUN ln -s "spark-${APACHE_SPARK_VERSION}-bin-hadoop${HADOOP_VERSION}" spark && \
# Add a link in the before_notebook hook in order to source automatically PYTHONPATH
mkdir -p /usr/local/bin/before-notebook.d && \
ln -s "${SPARK_HOME}/sbin/spark-config.sh" /usr/local/bin/before-notebook.d/spark-config.sh
# Fix Spark installation for Java 11 and Apache Arrow library
# see: https://github.com/apache/spark/pull/27356, https://spark.apache.org/docs/latest/#downloading
RUN cp -p "${SPARK_HOME}/conf/spark-defaults.conf.template" "${SPARK_HOME}/conf/spark-defaults.conf" && \
echo 'spark.driver.extraJavaOptions -Dio.netty.tryReflectionSetAccessible=true' >> "${SPARK_HOME}/conf/spark-defaults.conf" && \
echo 'spark.executor.extraJavaOptions -Dio.netty.tryReflectionSetAccessible=true' >> "${SPARK_HOME}/conf/spark-defaults.conf"
Delta lakeの構築
Delta lakeのライブラリを用意する必要がありますので以下のコマンドでDocker Imageにインストールしておきます。
# Download libraries for Delta lake and Hive metastore
WORKDIR /opt/spark/jars
RUN wget https://repo1.maven.org/maven2/com/google/guava/guava/30.1-jre/guava-30.1-jre.jar && \
wget https://repo1.maven.org/maven2/com/google/guava/failureaccess/1.0.1/failureaccess-1.0.1.jar && \
wget https://dev.mysql.com/get/Downloads/Connector-J/mysql-connector-java-8.0.27.tar.gz && \
tar xzvf mysql-connector-java-8.0.27.tar.gz && mv mysql-connector-java-8.0.27/mysql-connector-java-8.0.27.jar ./mysql-connector-java-8.0.27.jar && \
rm -rf mysql-connector-java-8.0.27.tar.gz && rm -rf mysql-connector-java-8.0.27
RUN chmod +x /opt/spark/jars/mysql-connector-java-8.0.27.jar && \
chmod +x /opt/spark/jars/failureaccess-1.0.1.jar && \
chmod +x /opt/spark/jars/guava-30.1-jre.jar
# Install delta lake spark libraries
RUN pip install delta-spark pandas pyarrow
注意点としては、PySparkが使うguavaライブラリとGCS connectorが使うguavaのバージョンが違うため、SparkからGCSにうまく接続できません。
この問題を解決するため、以下の感じでGuavaのバージョンを統一します。
# Fix Guava version issue
RUN mv /opt/conda/lib/python3.9/site-packages/pyspark/jars/guava-14.0.1.jar /opt/conda/lib/python3.9/site-packages/pyspark/jars/guava-14.0.1.jar.bak && \
rm $SPARK_HOME/jars/guava-14.0.1.jar && \
cp /opt/spark/jars/guava-30.1-jre.jar /opt/conda/lib/python3.9/site-packages/pyspark/jars/ && \
cp /opt/spark/jars/*.jar $SPARK_HOME/jars/
Metastoreに接続するための準備
構築したMySQL Serviceのアドレスを指定し、接続するためのアカウント情報を設定する必要があります。また、GCSにデータ永続化するため、hive.metastore.warehouse.dirがGCSに作成するBucket名を指定します。
ファイル名はhive-site.xmlなので以下の内容で実装します。
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://xx.xx.xx.xx:3306/metastore_database</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>metastore_username</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>xxxxxxx</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>gs://forex_data_xxxx/delta_lake/warehouse</value>
<description>location of default database for the warehouse</description>
</property>
</configuration>
このhive-site.xmlファイルをSPARK_HOME直下のconfにコピーしましょう。
COPY ./hive-site.xml /usr/local/spark/conf/hive-site.xml ENV HIVE_CONF_DIR=/usr/local/spark/conf
MetastoreはMySQLで構築したのでMySQLのJDBCを用意する必要がありますので、
上のステップにmysql-connector-java-8.0.27.jarをImageにダウンロードしておきました。
Dockerfileの最終ソースコード
# Copyright (c) Jupyter Development Team.
# Distributed under the terms of the Modified BSD License.
ARG OWNER=jupyter
ARG BASE_CONTAINER=$OWNER/base-notebook
FROM $BASE_CONTAINER
# Fix DL4006
SHELL ["/bin/bash", "-o", "pipefail", "-c"]
USER root
# Spark dependencies
# Default values can be overridden at build time
# (ARGS are in lower case to distinguish them from ENV)
ARG spark_version="3.1.2"
ARG hadoop_version="3.2"
ARG spark_checksum="2385CB772F21B014CE2ABD6B8F5E815721580D6E8BC42A26D70BBCDDA8D303D886A6F12B36D40F6971B5547B70FAE62B5A96146F0421CB93D4E51491308EF5D5"
ARG openjdk_version="11"
ENV APACHE_SPARK_VERSION="${spark_version}" \
HADOOP_VERSION="${hadoop_version}"
ENV JUPYTER_ENABLE_LAB=yes
RUN apt-get update --yes && \
apt-get install --yes --no-install-recommends curl \
"openjdk-${openjdk_version}-jre-headless" \
ca-certificates-java && \
apt-get clean && rm -rf /var/lib/apt/lists/*
# Spark installation
WORKDIR /tmp
RUN wget -q "https://archive.apache.org/dist/spark/spark-${APACHE_SPARK_VERSION}/spark-${APACHE_SPARK_VERSION}-bin-hadoop${HADOOP_VERSION}.tgz" && \
echo "${spark_checksum} *spark-${APACHE_SPARK_VERSION}-bin-hadoop${HADOOP_VERSION}.tgz" | sha512sum -c - && \
tar xzf "spark-${APACHE_SPARK_VERSION}-bin-hadoop${HADOOP_VERSION}.tgz" -C /usr/local --owner root --group root --no-same-owner && \
rm "spark-${APACHE_SPARK_VERSION}-bin-hadoop${HADOOP_VERSION}.tgz"
WORKDIR /usr/local
# Configure Spark
ENV SPARK_HOME=/usr/local/spark
ENV SPARK_OPTS="--driver-java-options=-Xms1024M --driver-java-options=-Xmx4096M --driver-java-options=-Dlog4j.logLevel=info" \
PATH="${PATH}:${SPARK_HOME}/bin"
RUN ln -s "spark-${APACHE_SPARK_VERSION}-bin-hadoop${HADOOP_VERSION}" spark && \
# Add a link in the before_notebook hook in order to source automatically PYTHONPATH
mkdir -p /usr/local/bin/before-notebook.d && \
ln -s "${SPARK_HOME}/sbin/spark-config.sh" /usr/local/bin/before-notebook.d/spark-config.sh
# Fix Spark installation for Java 11 and Apache Arrow library
# see: https://github.com/apache/spark/pull/27356, https://spark.apache.org/docs/latest/#downloading
RUN cp -p "${SPARK_HOME}/conf/spark-defaults.conf.template" "${SPARK_HOME}/conf/spark-defaults.conf" && \
echo 'spark.driver.extraJavaOptions -Dio.netty.tryReflectionSetAccessible=true' >> "${SPARK_HOME}/conf/spark-defaults.conf" && \
echo 'spark.executor.extraJavaOptions -Dio.netty.tryReflectionSetAccessible=true' >> "${SPARK_HOME}/conf/spark-defaults.conf"
COPY ./hive-site.xml /usr/local/spark/conf/hive-site.xml
ENV HIVE_CONF_DIR=/usr/local/spark/conf
# Download libraries for Delta lake and Hive metastore
WORKDIR /opt/spark/jars
RUN wget https://repo1.maven.org/maven2/com/google/guava/guava/30.1-jre/guava-30.1-jre.jar && \
wget https://repo1.maven.org/maven2/com/google/guava/failureaccess/1.0.1/failureaccess-1.0.1.jar && \
wget https://dev.mysql.com/get/Downloads/Connector-J/mysql-connector-java-8.0.27.tar.gz && \
tar xzvf mysql-connector-java-8.0.27.tar.gz && mv mysql-connector-java-8.0.27/mysql-connector-java-8.0.27.jar ./mysql-connector-java-8.0.27.jar && \
rm -rf mysql-connector-java-8.0.27.tar.gz && rm -rf mysql-connector-java-8.0.27
RUN chmod +x /opt/spark/jars/mysql-connector-java-8.0.27.jar && \
chmod +x /opt/spark/jars/failureaccess-1.0.1.jar && \
chmod +x /opt/spark/jars/guava-30.1-jre.jar
# Install delta lake spark libraries
RUN pip install delta-spark pandas pyarrow
# Fix Guava version issue
RUN mv /opt/conda/lib/python3.9/site-packages/pyspark/jars/guava-14.0.1.jar /opt/conda/lib/python3.9/site-packages/pyspark/jars/guava-14.0.1.jar.bak && \
rm $SPARK_HOME/jars/guava-14.0.1.jar && \
cp /opt/spark/jars/guava-30.1-jre.jar /opt/conda/lib/python3.9/site-packages/pyspark/jars/ && \
cp /opt/spark/jars/*.jar $SPARK_HOME/jars/
USER ${NB_UID}
RUN mkdir -p ${HOME}/.ivy2/jars
WORKDIR ${HOME}/.ivy2/jars
RUN wget https://repo1.maven.org/maven2/io/delta/delta-core_2.12/1.1.0/delta-core_2.12-1.1.0.jar && \
wget https://repo1.maven.org/maven2/org/antlr/antlr4-runtime/4.8/antlr4-runtime-4.8.jar && \
wget https://repo1.maven.org/maven2/org/codehaus/jackson/jackson-core-asl/1.9.13/jackson-core-asl-1.9.13.jar
RUN chmod +x ${HOME}/.ivy2/jars/delta-core_2.12-1.1.0.jar && \
chmod +x ${HOME}/.ivy2/jars/antlr4-runtime-4.8.jar && \
chmod +x ${HOME}/.ivy2/jars/jackson-core-asl-1.9.13.jar
WORKDIR "${HOME}"
Docker Imageのビルド及びRepositoryにPush
Docker Imageをビルドする
$ docker build -t gcr.io/evident-time-3366xx/pyspark-jupyterlab:latest . Successfully built 9f2a3284fc38 Successfully tagged gcr.io/evident-time-3366xx/pyspark-jupyterlab:latest $ docker images REPOSITORY TAG IMAGE ID CREATED SIZE gcr.io/evident-time-3366xx/pyspark-jupyterlab latest 9f2a3284fc38 7 seconds ago 1.76GB
Docker ImageをGoogle Container RegistryにPush
tranduc_quy@cloudshell:~/metastore (evident-time-3366xx)$ docker push gcr.io/evident-time-3366xx/pyspark-jupyterlab:latest The push refers to repository [gcr.io/evident-time-3366xx/pyspark-jupyterlab] latest: digest: sha256:7c4f0d7109e268a547d0690901e345977fc5e456f40e6e0ac5d461872b598f84 size: 5137
GCS上にデータ永続化の準備
Google Cloud Storage(以降GCS)とはGoogle Cloud Platform(GCP)が提供しているオンラインストレージサービスです。
GCSを利用する為には用語の理解をする必要があります。
- バケット
- データを格納するコンテナ
- 地理的なロケーションや、ストレージクラスの設定が可能
- オブジェクト
- GCSに保存する個々のデータ
- ストレージクラスの設定が可能

GCS上にBucketの作成
Google Storage Serviceの管理画面でデータレイクの永続化先を作成します。名前はforex_data_20211229とします。
tranduc_quy@cloudshell:~ (evident-time-3366xx)$ gsutil ls gs://forex_data_20211229/
IAM管理でサービスアカウント作成
Docker container内に実行するPySparkプログラムからGCS上に構築したDelta Lakeに接続するため、サービスアカウントが必要です。サービス アカウントは、ユーザーではなく、Compute Engine 仮想マシン(VM)インスタンスなどのアプリケーションやコンピューティング ワークロードで使用される特別なアカウントです。アプリケーションはサービス アカウントを使用して、承認された API 呼び出しを行います。このサービスアカウントがGCPのIAM管理サービスで作成できますので、GCPが公開している手順を従って作成しました。
K8sクラスターにデータ解析基盤を展開する
データ解析基盤のサービスを作成
基本的には前回のブログに使ったYMLファイル内容と同じですが、GCPの秘密情報の管理はConfigMapとSecretを使うように変更しました。
apiVersion: v1
kind: ServiceAccount
metadata:
name: jupyter
labels:
release: jupyter
secrets:
- name: gcp-service-account
- name: gcs-access-key
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: jupyter
labels:
release: jupyter
namespace: spark
rules:
- apiGroups:
- ""
resources:
- pods
verbs:
- create
- get
- delete
- list
- watch
- apiGroups:
- ""
resources:
- services
verbs:
- get
- create
- apiGroups:
- ""
resources:
- pods/log
verbs:
- get
- list
- apiGroups:
- ""
resources:
- pods/exec
verbs:
- create
- get
- apiGroups:
- ""
resources:
- configmaps
verbs:
- get
- create
- list
- watch
- delete
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: jupyter
labels:
release: jupyter
namespace: spark
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: jupyter
subjects:
- kind: ServiceAccount
name: jupyter
namespace: spark
- kind: User
name: [email protected]
namespace: spark
- kind: User
name: [email protected]
namespace: spark
---
apiVersion: v1
kind: Service
metadata:
name: jupyter
labels:
release: jupyter
spec:
type: ClusterIP
selector:
release: jupyter
ports:
- name: http
port: 8888
protocol: TCP
- name: blockmanager
port: 7777
protocol: TCP
- name: driver
port: 2222
protocol: TCP
---
apiVersion: v1
kind: Service
metadata:
name: jupyter-headless
labels:
release: jupyter
spec:
type: ClusterIP
clusterIP: None
publishNotReadyAddresses: false
selector:
release: jupyter
ports:
- name: http
port: 8888
protocol: TCP
- name: blockmanager
port: 7777
protocol: TCP
- name: driver
port: 2222
protocol: TCP
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: jupyter
labels:
release: jupyter
spec:
replicas: 1
updateStrategy:
type: RollingUpdate
serviceName: jupyter-headless
podManagementPolicy: Parallel
volumeClaimTemplates:
- metadata:
name: notebook-data
labels:
release: jupyter
spec:
accessModes:
- ReadWriteOnce
volumeMode: Filesystem
resources:
requests:
storage: 100Mi
selector:
matchLabels:
release: jupyter
template:
metadata:
labels:
release: jupyter
spec:
restartPolicy: Always
ImagePullPollicy: Always
terminationGracePeriodSeconds: 30
serviceAccountName: jupyter
dnsConfig:
options:
- name: ndots
value: "1"
containers:
- name: jupyter
image: "gcr.io/evident-time-3366xx/pyspark-jupyterlab:latest"
imagePullPolicy: IfNotPresent
ports:
- name: http
containerPort: 8888
protocol: TCP
- name: blockmanager
containerPort: 7777
protocol: TCP
- name: driver
containerPort: 2222
protocol: TCP
volumeMounts:
- name: notebook-data
mountPath: /home/spark/notebook
- name: gcp-service-account
mountPath: /usr/local/spark/conf/evident-time-3366xx-xxx.json
subPath: evident-time-3366xx-xxx.json
env:
- name: GOOGLE_APPLICATION_CREDENTIALS
value: /usr/local/spark/conf/evident-time-3366xx-xxx.json
resources:
limits:
cpu: 400m
memory: 1Gi
requests:
cpu: 200m
memory: 0.5Gi
volumes:
- name: gcp-service-account
configMap:
name: gcp-service-account
- name: google-cloud-key
secret:
secretName: gcs-access-key
クラスターにServiceを適用する
YMLファイルを準備できましたので、K8sクラスターにSparkクラスターを展開しましょう。
tranduc_quy@cloudshell:~/metastore (evident-time-3366xx)$ kubectl create namespace spark namespace/spark created tranduc_quy@cloudshell:~/metastore (evident-time-3366xx)$ kubectl apply -f data-platform-config.yml serviceaccount/jupyter created role.rbac.authorization.k8s.io/jupyter created rolebinding.rbac.authorization.k8s.io/jupyter created service/jupyter created service/jupyter-headless created statefulset.apps/jupyter created tranduc_quy@cloudshell:~/metastore (evident-time-3366xx)$
想定の通り、各サービスが立ち上がりました。
tranduc_quy@cloudshell:~/metastore (evident-time-3366xx)$ kubectl get services NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE jupyter ClusterIP 10.xx.xx.xx <none> 8888/TCP,7777/TCP,2222/TCP 3m44s jupyter-headless ClusterIP None <none> 8888/TCP,7777/TCP,2222/TCP 3m43s kubernetes ClusterIP 10.xx.xx.xx <none> 443/TCP 45h mysql ClusterIP None <none> 3306/TCP 43h
動作確認
GKE上に稼働するContainerからGCSにアクセスできるか
GKE上に構築したpySpark on K8sクラスターがGCSにアクセスできるか検証したいと思います。
検証するため、GCSに検証用のCSVファイルを準備しておきます。このCSVファイルはHISTDATAサイトが公開している為替レートデータファイルです。
tranduc_quy@cloudshell:~ (evident-time-3366xx)$ gsutil cat gs://forex_data_20211229/DAT_ASCII_USDJPY_T_202109.csv | head 20210901 000000866,110.177000,110.181000,0 20210901 000001581,110.177000,110.181000,0 20210901 000003278,110.178000,110.182000,0 20210901 000003429,110.179000,110.182000,0 20210901 000006023,110.179000,110.184000,0 20210901 000006125,110.180000,110.183000,0 20210901 000008995,110.179000,110.183000,0 20210901 000018162,110.178000,110.182000,0 20210901 000034261,110.178000,110.182000,0 20210901 000035889,110.177000,110.181000,0 tranduc_quy@cloudshell:~ (evident-time-3366xx)$
SparkOperatorを導入してSpark-summitコマンドを実行してPySparkの実行は可能になると思いますが、
今回は簡単に検証するため、まずはContainer内にログインしてGCS接続及びDelta Lake対応するpySparkを起動するため以下のコマンドを実行します。
kubectl exec -it jupyter-0 -- /bin/bash pyspark \ --packages com.google.cloud.bigdataoss:gcs-connector:hadoop3-2.2.4,io.delta:delta-core_2.12:1.0.0 \ --conf "spark.sql.extensions=io.delta.sql.DeltaSparkSessionExtension" \ --conf "spark.sql.catalog.spark_catalog=org.apache.spark.sql.delta.catalog.DeltaCatalog" \ --conf "spark.hadoop.fs.AbstractFileSystem.gs.impl=com.google.cloud.hadoop.fs.gcs.GoogleHadoopFS" \ --conf "spark.hadoop.fs.gs.project.id=evident-time-3366xx" \ --conf "spark.hadoop.google.cloud.auth.service.account.enable=true" \ --conf "spark.hadoop.google.cloud.auth.service.account.json.keyfile=/usr/local/spark/conf/evident-time-3366xx-xxxx.json" \ --conf "spark.sql.catalogImplementation=hive"
無事にPySpark Shellを起動されました。
$ pyspark \
> --packages com.google.cloud.bigdataoss:gcs-connector:hadoop3-2.2.4,io.delta:delta-core_2.12:1.0.0 \
> --conf "spark.sql.extensions=io.delta.sql.DeltaSparkSessionExtension" \
> --conf "spark.sql.catalog.spark_catalog=org.apache.spark.sql.delta.catalog.DeltaCatalog" \
> --conf "spark.hadoop.fs.AbstractFileSystem.gs.impl=com.google.cloud.hadoop.fs.gcs.GoogleHadoopFS" \
> --conf "spark.hadoop.fs.gs.project.id=evident-time-3366xx" \
> --conf "spark.hadoop.google.cloud.auth.service.account.enable=true" \
> --conf "spark.hadoop.google.cloud.auth.service.account.json.keyfile=/usr/local/spark/conf/evident-time-3366xx-xxxx.json" \
> --conf "spark.sql.catalogImplementation=hive"
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 3.1.2
/_/
Using Python version 3.9.7 (default, Sep 29 2021 19:20:46)
Spark context Web UI available at http://jupyter-0.jupyter-headless.default.svc.cluster.local:4040
Spark context available as 'sc' (master = local[*], app id = local-1641711782546).
SparkSession available as 'spark'.
次に、以下のコマンドでSpark Sessionを生成します。Delta Lake及びGCSに接続することを明言する必要があるので以下の感じでSparkSessionのConfigを設定しておきます。
from pyspark import SparkContext
from pyspark.sql import Column, DataFrame, SparkSession, SQLContext, functions
from pyspark.sql.functions import *
from pyspark.sql.types import *
from py4j.java_collections import MapConverter
from delta.tables import *
spark = SparkSession \
.builder \
.appName("test-gcs-deltalake") \
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") \
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog") \
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") \
.config("fs.gs.impl", "com.google.cloud.hadoop.fs.gcs.GoogleHadoopFileSystem") \
.config("spark.hadoop.fs.AbstractFileSystem.gs.impl", "com.google.cloud.hadoop.fs.gcs.GoogleHadoopFS") \
.enableHiveSupport() \
.getOrCreate()
次に、GCSに格納したCSVファイルをちゃんと読み込めるか確認しましょう。
df = spark.read.format("csv"). \
schema(read_schema). \
load("gs://forex_data_20211229/DAT_ASCII_USDJPY_T_202109.csv")
df.show()
データフレームにCSVデータが格納されているのでContainer内のPySparkからGCSにアクセスできることを確認しました!
>>> df = spark.read.format("csv"). \
... schema(read_schema). \
... load("gs://forex_data_20211229/DAT_ASCII_USDJPY_T_202109.csv")
>>>
>>> df.show()
+------------------+-------+-------+------+
| tick_timestamp| bid| ask|volume|
+------------------+-------+-------+------+
|20210901 000000866|110.177|110.181| 0|
|20210901 000001581|110.177|110.181| 0|
|20210901 000003278|110.178|110.182| 0|
|20210901 000003429|110.179|110.182| 0|
|20210901 000006023|110.179|110.184| 0|
|20210901 000006125| 110.18|110.183| 0|
|20210901 000008995|110.179|110.183| 0|
|20210901 000018162|110.178|110.182| 0|
|20210901 000034261|110.178|110.182| 0|
|20210901 000035889|110.177|110.181| 0|
|20210901 000045068|110.176|110.178| 0|
|20210901 000045169|110.173|110.177| 0|
|20210901 000045663|110.172|110.178| 0|
|20210901 000054698|110.175|110.177| 0|
|20210901 000054749|110.175|110.179| 0|
|20210901 000102208|110.175|110.177| 0|
|20210901 000102360|110.172|110.177| 0|
|20210901 000102461|110.172|110.176| 0|
|20210901 000102564|110.169|110.176| 0|
|20210901 000104822|110.171|110.175| 0|
+------------------+-------+-------+------+
only showing top 20 rows
SparkがMetastoreでDelta Lakeのメタデータが連携できるか確認する
以下のコマンドでMetastoreにスキーマがあるか確認しましょう。
database_name = "gold_forex"
spark.catalog.listDatabases()
spark.sql(f"CREATE DATABASE IF NOT EXISTS {database_name}")
spark.catalog.listDatabases()
実行結果は以下の感じですので、構築したHive Metastoreに接続できていると思います。
>>> database_name = "gold_forex"
>>> spark.catalog.listDatabases()
[Database(name='default', description='Default Hive database', locationUri='file:/apps/delta_lake/warehouse')]
>>> spark.sql(f"CREATE DATABASE IF NOT EXISTS {database_name}")
DataFrame[]
>>> spark.catalog.listDatabases()
[Database(name='default', description='Default Hive database', locationUri='file:/apps/delta_lake/warehouse'),
Database(name='gold_forex', description='', locationUri='gs://forex_data_20211229/delta_lake/warehouse/gold_forex.db')]
>>> spark.sql(f"USE {database_name}")
DataFrame[]
GCSにgold_forex.dbがあるか確認したいと思います。
tranduc_quy@cloudshell:~ (evident-time-3366xx)$ gsutil ls gs://forex_data_20211229/delta_lake/warehouse/ gs://forex_data_20211229/delta_lake/warehouse/ gs://forex_data_20211229/delta_lake/warehouse/gold_forex.db/
GCS上のDelta Lakeにデータを永続化できるか確認する
以下のコマンドで上記に作ったデータフレームから新しいカラムを計算したり、カラム名変更したり、データ型をキャストしたりしてからDelta Lakeに永続化したいと思います。
>>> commodity = "USDJPY"
>>> # volumeカラムは使わないのでforex_pairに変更。
>>> df = df.withColumn("volume", lit(commodity)).withColumnRenamed("volume", "forex_pair")
>>> # 検索時間を短縮する目的でレート日付でテーブルのPartitionを作るため、quote_dateカラムを作成する。
>>> df = df.withColumn("business_date", df.tick_timestamp[0:8])
>>> df = df.withColumn("business_date", df.business_date.cast(IntegerType()))
>>> # Midプライスを計算する
>>> df = df.withColumn("mid", (df.bid + df.ask)/2)
>>> df = df.withColumn("mid", df.mid.cast(FloatType()))
>>>
>>> df.show()
+------------------+-------+-------+----------+-------------+----------+
| tick_timestamp| bid| ask|forex_pair|business_date| mid|
+------------------+-------+-------+----------+-------------+----------+
|20210901 000000866|110.177|110.181| USDJPY| 20210901| 110.179|
|20210901 000001581|110.177|110.181| USDJPY| 20210901| 110.179|
|20210901 000003278|110.178|110.182| USDJPY| 20210901| 110.18|
|20210901 000003429|110.179|110.182| USDJPY| 20210901| 110.1805|
|20210901 000006023|110.179|110.184| USDJPY| 20210901| 110.1815|
|20210901 000006125| 110.18|110.183| USDJPY| 20210901| 110.1815|
|20210901 000008995|110.179|110.183| USDJPY| 20210901| 110.181|
|20210901 000018162|110.178|110.182| USDJPY| 20210901| 110.18|
|20210901 000034261|110.178|110.182| USDJPY| 20210901| 110.18|
|20210901 000035889|110.177|110.181| USDJPY| 20210901| 110.179|
|20210901 000045068|110.176|110.178| USDJPY| 20210901| 110.177|
|20210901 000045169|110.173|110.177| USDJPY| 20210901| 110.175|
|20210901 000045663|110.172|110.178| USDJPY| 20210901| 110.175|
|20210901 000054698|110.175|110.177| USDJPY| 20210901| 110.176|
|20210901 000054749|110.175|110.179| USDJPY| 20210901| 110.177|
|20210901 000102208|110.175|110.177| USDJPY| 20210901| 110.176|
|20210901 000102360|110.172|110.177| USDJPY| 20210901| 110.1745|
|20210901 000102461|110.172|110.176| USDJPY| 20210901|110.173996|
|20210901 000102564|110.169|110.176| USDJPY| 20210901| 110.1725|
|20210901 000104822|110.171|110.175| USDJPY| 20210901|110.173004|
+------------------+-------+-------+----------+-------------+----------+
only showing top 20 rows
>>> table_name = "commodity_rates"
>>> table_location = f"gs://forex_data_20211229/delta_lake/warehouse/{database_name}.db/{table_name}"
>>> checkpoint_location = table_location + "/_checkpoints/streaming_ckp"
>>> partitions = ["business_date", "forex_pair"]
>>> df.write \
... .format("delta") \
... .partitionBy(partitions) \
... .option("mergeSchema", "true") \
... .option("overwriteSchema", "true") \
... .option("checkpointLocation", checkpoint_location) \
... .mode('overwrite') \
... .saveAsTable(table_name)
無事に永続化できたようですので、gsutilコマンドでGCS上のデータレイクを確認しましょう。
tranduc_quy@cloudshell:~ (evident-time-3366xx)$ gsutil ls gs://forex_data_20211229/delta_lake/warehouse/gold_forex.db/commodity_rates/ gs://forex_data_20211229/delta_lake/warehouse/gold_forex.db/commodity_rates/_delta_log/ gs://forex_data_20211229/delta_lake/warehouse/gold_forex.db/commodity_rates/business_date=20210901/ gs://forex_data_20211229/delta_lake/warehouse/gold_forex.db/commodity_rates/business_date=20210902/ gs://forex_data_20211229/delta_lake/warehouse/gold_forex.db/commodity_rates/business_date=20210903/ gs://forex_data_20211229/delta_lake/warehouse/gold_forex.db/commodity_rates/business_date=20210905/ gs://forex_data_20211229/delta_lake/warehouse/gold_forex.db/commodity_rates/business_date=20210906/ gs://forex_data_20211229/delta_lake/warehouse/gold_forex.db/commodity_rates/business_date=20210907/ gs://forex_data_20211229/delta_lake/warehouse/gold_forex.db/commodity_rates/business_date=20210908/ gs://forex_data_20211229/delta_lake/warehouse/gold_forex.db/commodity_rates/business_date=20210909/ gs://forex_data_20211229/delta_lake/warehouse/gold_forex.db/commodity_rates/business_date=20210910/ tranduc_quy@cloudshell:~ (evident-time-3366xx)$ gsutil ls gs://forex_data_20211229/delta_lake/warehouse/gold_forex.db/commodity_rates/business_date=20210901/ gs://forex_data_20211229/delta_lake/warehouse/gold_forex.db/commodity_rates/business_date=20210901/forex_pair=USDJPY/ tranduc_quy@cloudshell:~ (evident-time-3366xx)$ gsutil ls gs://forex_data_20211229/delta_lake/warehouse/gold_forex.db/commodity_rates/business_date=20210901/forex_pair=USDJPY/ gs://forex_data_20211229/delta_lake/warehouse/gold_forex.db/commodity_rates/business_date=20210901/forex_pair=USDJPY/part-00000-240228c7-2b28-444a-990b-0c69cb06de23.c000.snappy.parquet
問題なくGCS上のDelta Lakeにデータを格納されました。良さそうですね。
まとめ
長くなりましたが、今回はDataProcなどを使わずにGCP上にデータ解析基盤を構築してみました。GKE上にpySpark on K8sクラスターを構築する前に自社のConoha VPS上に同様のK8sクラスターを構築したが、その時はVPSの初期化設定やセキュリティ周りの設定は自分で対応する必要がありました。GCP上にクラスター構築はこの作業が発生しないので大分楽になると感じました。Docker Imageは自分でビルドして使うのでSparkバージョンを変更することが可能ですが、データ基盤のStorageレイヤーがGCSを使いまして、さらにGCS上にデータレイクレイヤーはDelta Lakeを構築したので、Sparkバージョンの選択時にDelta Lakeが対応しているバージョンかどうかを考慮したほうが良さそうですね。検証の最初の段階にGCSにうまく接続できなくて色々調査してみたら各製品のJarバージョンが違うので上手く連携できないということもわかりましたので、やはり自分で環境構築にこれらの問題が発生しやすいかと感じました。
最後、データレイクのMetastoreはMySQLで構築して使いました。使い勝手は良さそうですが、Metastoreのバージョンやテーブル設計に色々な細かい問題があったので調査時間が発生しました。最近、GoogleはDataProcやHive Metastoreといったビックデータ解析向けのサービスを公開しているので、自分で構築しなくても良いですが、コスト削減などで自分で構築して運用するケースもありますね。
最後に
次世代システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。
皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD