2022.07.07
モバイル端末における機械学習実装(1) – モバイル特有の考慮点と利用ライブラリについて –
次世代システム研究室のT.Sです。機械学習が一般化していく現代において、これを実行するアーキも大きく変わってきています。これまで中央サーバにデータを集め、そこで学習・解析を行ってきたという方法から、モバイル端末などのエッジ側で学習を行い、これを各端末・個人においてカスタマイズする、もしくはエッジ側で学習したパラメータだけを中央サーバに集め新しいモデルを作るなどエッジ側で学習までしてしまうというアーキテクチャがポツポツと出てきています。
そこで今回(&次回以降も含め)は端末における学習アーキの実装の一例をご紹介できればと思っています。
まず今回はその前段として、なぜモバイル端末側で機械学習を行うのか、そしてそれはサーバ側と違ってどのような点をまず考慮する必要があるのかなどの前段の部分の説明をしようかと思います
やりたいこと
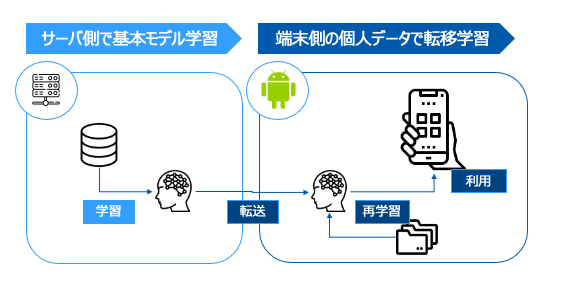
冒頭に記載したように今回やりたいことは「端末側でデータを学習->モデル利用する」という仕組みになります。モデル自体はひとまずサーバ側で共通モデルを構築し、これを端末側に配布。その後端末側で転移学習を実施・チューニングした上で、これを利用という形になります。簡単に図に合わすと以下のようなイメージになります。また端末側ははandroid(Pixel6)を利用する前提でおります。
なぜ端末側で学習したいのか
さて実際の技術要素のお話をする前に、なぜ端末側で学習したいのかという背景をお話したいと思います。
ユーザごとにデータ分布が異なるため
通常中央サーバで学習した場合、全ユーザで共通する一つのモデルが作成され、これを全体に適用していくというのがほとんどかと思います。基本的にこれで多くの場合問題はないのですが、各ユーザに最適になっているものになっているかというと必ずしもそうではないことは想像に難くないかと思います。
レコメンドのパーソナライゼーションのような文脈で語られることも多いですが、個人におけるデータ分布というのは基本非i.i.d.であり、個人ごとに同じ確率分布から生成されたものでないという特性があるからです。
federated learningのフレームワークの一つであるtensorflow federatedにその状態を表す関数があるので、こちらで簡単に見てみましょう。
ちなみにですがGoogle colabでfederated learningを実行する際、pip installをする必要があるのですが、その際以下のようにversionを指定しないと落ちてしまうのでお気をつけください。どうやらpythonのVersionが若干古いことが原因のようです。
!pip install --quiet --upgrade tensorflow_federated==0.20.0
tensorflow federated には単純なデータロードではなく、各端末の状況を再現した上でデータセットをロードするtff.simulation.datasetsという関数が存在します。こちらを利用すると端末毎にシュミレートしたデータセットが取得できます。今回はmnistデータなので若干直感的ではないですが、まあ個人の各数字の特性ということで理解いただければと…
train, test = tff.simulation.datasets.emnist.load_data()
これをUser毎のどういったデータ分布になるか見てましょう。tensorflow federatedではcreate_tf_dataset_for_clientを利用してUser毎のシュミレーションデータから取得できます。
for i in range(10):
client_dataset = train.create_tf_dataset_for_client(train.client_ids[i])
plot_data = collections.defaultdict(list)
for example in client_dataset:
label = example['label'].numpy()
plot_data[label].append(label)
plt.subplot(2, 5, i+1)
plt.title(f'User{i}')
for j in range(10):
plt.hist(plot_data[j],bins=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
結果としてユーザそれぞれで分布がことなることがわかります。まあこれが即非i.i.d.であることの証明にはならないのではありますが、それでユーザによって全く違うデータ分布が得られる以上、個人の特性によって新たに生み出せれるデータパターンに適用していかないと「最適である」とは言えなそうですね。
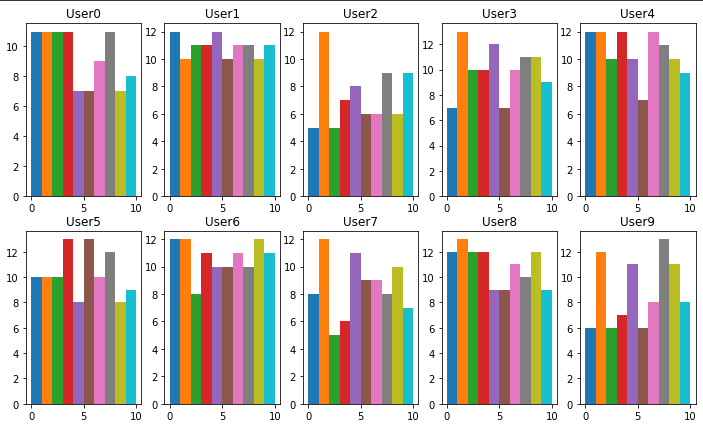
またデータの内容を見ると直感的にわかる部分もあります。mnistであるため手書きの数字データにはなるのですが、個人によって文字のクセが違うというのは想像しやすいのかなと感じます。実際にユーザ1-5に振り分けられたデータを見てみると大きく違いますね。もし学習したデータにないような文字の癖があるとするならばこれを即座に学習すべきでしょう。

個人情報保護観点
広告識別子(AAID/IDFA)のオプトイン方式導入やiOSのプライベートリレー導入など個人情報の取り扱いは一層厳しくなっていっています。次期VersionでのAndroid13ではPhotoへのアクセス範囲の変更(メディア権限の細分化)なども実施され、今後もその取扱が難しくなっていことは間違いないかと思われます。
そういった環境の中、個人情報に関するデータを収集できたとしても、これを中央サーバに集めることは望ましくなく、端末側で学習せざる得なく、そのため上記のようなアーキが必要になってくると考えています。
データ量の爆発的増加
各種センサーデータの発達等によって取得できるデータ量は大きく増えています。また画像、音声、動画といった非構造データを取り扱うのが当たり前になってきました。
このようなデータを全てサーバに集めることは通信容量やこれにかかる料金、また電池消費などの観点で現実的ではなく、端末側で学習したパラメータのみを転送せざるを得なくなってくるかと考えます
その他にもPixel搭載のTensorチップなどによる処理性能向上などで端末側学習が用意になるなどの理由もあり、Needs/Seedsの双方で上記アーキが必要且つ現実的になっているかと考えています。
モバイル端末での学習で難しい点
上記でモバイル端末における学習の必要性はおわかりいただけたかと思います。じゃあ端末上で今まで通り学習してみよう!…………というわけにはなかなか行きません。モバイル端末(ここではスマートフォンを前提)においては、特有の問題点がありこれがアーキ構築を一層難しくしています。
電池やネットワーク状態の変化
モデル学習のためにはまずベースモデルを外部からダウンロードした上で、処理量の多い学習プロセスを実行する必要があります。通常サーバでこれを実施する場合、常に電源が供給されかつネットワークにはつながっているのでここを意識する必要はありません。
しかしモバイル端末は違います。地下に入ったり、自宅の電波環境が悪いなどいつ電波が途切れるかわかりません。また大量のデータ通信は通信制限につながりUXに大きな悪影響を与えるため気軽には実施できません。
また電池残量が少ない場合に実行してしまうと途中で電池切れしてしまう可能性もありますし、何より電池を大量に消費してしまうアプリケーションというのはやはりUXが悪く、最悪アンインストールに直結してしまいます。
そのためandroidでスケジュールタスクを実行する際にはConstraintsを設定して、UXを阻害しない範囲で実行するよう設計・実装することができます.以下はそのサンプルコードとなります。
val constraints = Constraints.Builder()
// WiFiに接続した場合のみ
.setRequiredNetworkType(NetworkType.UNMETERED)
// Storage容量が十分にある場合のみ
.setRequiresStorageNotLow(true)
// 充電中のみ
.setRequiresCharging(true)
// アイドル状態のときのみ
.setRequiresDeviceIdle(true)
// 電池容量が充分な場合のみ
.setRequiresBatteryNotLow(true)
.build()
// 1時間毎に定期実行
val request = PeriodicWorkRequestBuilder<HogeWorker>(1, TimeUnit.HOURS)
.setConstraints(constraints)
.setInputData(data.build())
.build()
WorkManager.getInstance(context).enqueueUniquePeriodicWork(
"hoge",
ExistingPeriodicWorkPolicy.REPLACE,
request
)
従来のスケジュールタスクでも考慮が必要ですが、処理量が圧倒的に大きいモデル学習においてはさらにここを綿密に考える必要があります。少なくても従来どおりの考えではUXを大きく損ねてしまう可能性が非常に高くなります。
長時間タスクの取り扱い
モデル学習は処理量が多いため、デバイス端末上も一定の時間が必要となります。
しかしデバイス端末上では先程言及したUXへの影響を鑑み、そもそも長時間タスクがあまり推奨されていません。先程コードの例を上げたWorkManagerについても、ワーカーが停止する条件として以下の4つが挙げられています。
4つ目がまさにそれで10分以上経過した場合、スケジュールタスクはキャンセルされてしまう可能性があります。ちなみに3つ目は先程設定したConstraintsにまつわる条件で、たとえ実行中でもconstraintsに抵触した場合実行中タスクがキャンセルとなってしまうことを指しています。どちらも従来のモデル学習では考慮しない点ですよね。
- ワーカーをキャンセルするよう明示的に要求した(WorkManager.cancelWorkById(UUID) を呼び出したなど)。
- 一意処理の場合に、ExistingWorkPolicy が REPLACE に設定された新しい WorkRequest を明示的にキューに登録した。古い WorkRequest は直ちにキャンセル済みと判断されます。
- 処理の制約が満たされなくなった。
- システムがアプリに対し、なんらかの理由で処理を停止するよう指示した。これは、実行期限の 10 分を超えた場合に行われることがあります。処理が後で再試行されるようにスケジュール設定されます。
ただ一応こちらについてはWorkManager 2.3.0-alpha02から解決策が用意はされております。(もし途中でキャンセルしたい場合はcreateCancelPendingIntentがalpha03から導入されており、こちらで制御する)
class DownloadWorker(context: Context, parameters: WorkerParameters) :
CoroutineWorker(context, parameters) {
....
override suspend fun doWork(): Result {
....
setForeground(createForegroundInfo(progress))
....
}
private fun createForegroundInfo(progress: String): ForegroundInfo {
// 処理を記載
....
}
}
というわけでこちらは解決済みではありますがUXへの影響が大きいので、どの単位でどうやって実行するかは独自設計が必要そうです
モデル学習の実行単位
こちらは上記の制限等に関わる話ではあるのですが、サーバでのようにモデル学習が一括で実施できるという保証がまったくないため、これを考慮する必要があります。簡単に考えただでも以下のような理由・原因により、モデル学習を一定以上小さく分断して実施する必要が出てきます。
- 大量処理を一括で行うと処理が重くなる/li>
- 大量処理を一括で行うと電池残量が急激に減ってしまう
- 外部データのダウンロードが大量で、少量ずつしか実行できない
- 電源接続されている場合のみ動作したいが、途中で電源から外される
- WiFi接続されている場合のみ動作したいが、途中で電源から外される
- ユーザ行動によって個人別データが少量しか貯まらない
上はあくまで例でありますが、モバイル端末特有の制約があることがわかるかと思います。
このようなアーキテクチャを取る場合、federated learningのようにパラメータをどうやって同期とるのか?といった難しい問題にも目が行きますが、そもそも最低限のUI/UXを満たすためだけでも考えなければいけないことが多いことがわかります。
ひとまず解決しないと行けない課題としては「UI/UXに影響が及ばないようモデル学習をどのタイミング/粒度で実施するか」「そして粒度を小さくした場合にモデル学習はうまく進むのか」があるのかなと考えています。
android端末で利用できる機械学習ライブラリ
上記でモバイル端末上でのモデル学習の必要性とそれにまつわる難しさの一端をご理解いただけたかと思います。さてここからはandroid上で利用できる機械学習ライブラリをご紹介していきましょう。そしてそれらのライブラリが先述した課題点を解決するかも合わせてみていければと思います。
Firebase MLKit
Firebase MLKitは、mBaaSであるFirebaseで取り扱えるML関連機能になります。基本機能としてはPretrainedされたMLモデルをAPIベースで利用できるというものなのですが、カスタムモデルを利用するための機能も存在しております。
主な機能は以下の4つとなります。モデルを利用するという観点ではモバイル端末の特性を考慮した上で、簡単に利用できるものになっているかと感じます。
- Tensorflow Liteを利用したモデルの格納、配布
- 端末上でモデルを実行するためのML Kit SDKの提供
- リモートが利用できない場合に自動でローカルモデルにフォールバック
- 新しいモデルバージョンの自動更新(WiFi接続、充電、アイドルなどの条件設定あり)
例えばモデルをダウンロードして実行するのも以下のようなコードで可能であり、非常にシンプルに記載できますね
val remoteModel = FirebaseCustomRemoteModel.Builder("your_model").build()
val conditions = FirebaseModelDownloadConditions.Builder()
.requireWifi()
.build()
FirebaseModelManager.getInstance().download(remoteModel, conditions)
.addOnCompleteListener { model: CustomModel? ->
val modelFile = model?.file
if (modelFile != null) {
Timber.tag("model").d("Load Done")
interpreter = Interpreter(modelFile)
}
....
interpreter?.run(input, modelOutput)
}
ただFirebase MLKit自体は配布/推論用のSDKになっており学習に関しては別途自作する必要があります。
しかしホストされるのがTensorflow Liteという一般的なものであるため学習自体はTensorflow側で実行可能となっています. androidではJava(kotlin)で実装するため、Tensorflowをそのまま扱えばよいというお話ですね。
float[] losses = new float[NUM_EPOCHS];
for (int epoch = 0; epoch < NUM_EPOCHS; ++epoch) {
for (int batchIdx = 0; batchIdx < NUM_BATCHES; ++batchIdx) {
Map<String, Object> inputs = new HashMap<>();
inputs.put("x", trainImageBatches.get(batchIdx));
inputs.put("y", trainLabelBatches.get(batchIdx));
Map<String, Object> outputs = new HashMap<>();
FloatBuffer loss = FloatBuffer.allocate(1);
outputs.put("loss", loss);
interpreter.runSignature(inputs, outputs, "train");
// Record the last loss.
if (batchIdx == NUM_BATCHES - 1) losses[epoch] = loss.get(0);
}
// Print the loss output for every 10 epochs.
if ((epoch + 1) % 10 == 0) {
System.out.println(
"Finished " + (epoch + 1) + " epochs, current loss: " + loss.get(0));
}
}
(https://www.tensorflow.org/lite/examples/on_device_training/overview?hl=ja より抜粋)
結論として、「配布・推論は十分な機能を保有」「学習はTensorflowを直接利用することで可能」「パラメータ収集などサーバ側に返す仕組みはない」という内容になるかと思います。
TensorFlow Lite Model Maker
Firebase MLKitは学習機能が弱いというお話をしましたが、これをサポートすることはできないのでしょうか?
この便利ツールとしてTensorFlow Lite Model Maker なるものが存在しています。例えば以下のようなコードで転移学習が実施できます。
data = DataLoader.from_folder('flower_photos/')
train_data, test_data = data.split(0.9)
model = image_classifier.create(train_data)
ただこちらのツール、(そもそもPythonであるためandroid上で扱いにくいという話もありますが)タスクが以下に限定されており、利用ケースが制限されてしまいます。
またデバイス端末特有の問題を解決するものではなく、あくまでMLに不慣れでTensorflow/Kearasの理解がいらない便利ツールという立ち位置ですので今回の目的にはあまり合致しないであろうという結論にいたりました。
- Image Classification/li>
- Object Detection
- Text Classification
- BERT Question Answer
- Audio Classification
- Recommendation
- Searcher
https://www.tensorflow.org/lite/models/modify/model_maker?hl=en より
結果Tensorflow Liteを使う場合には、Firebase MLKitを推論/配布で利用し、学習ではTensorflow自体を使うという方法がまずはわかりやすいのかなという結論にいたりました。
TensorFlow Federated
これまではFirebase ML Kitを元にお話をしていましたが、TensorflowにはTensorflow Federatedという別のデバイス端末上で実行するためのフレームワークがあります。
これはいわゆるフェデレーションラーニング用のライブラリであり、学習はもちろんパラメータをサーバ側に転送してモデルを更新するというところまでサポートすることを目指したライブラリになります。
パラメータの更新ではFederated Avarageというアルゴリズムを利用しており、個別に学習したパラメータを連合学習するために以下のような関数もあったりします。
iterative_process = tff.learning.build_federated_averaging_process(
model_fn,
client_optimizer_fn=lambda: tf.keras.optimizers.SGD(learning_rate=0.02),
server_optimizer_fn=lambda: tf.keras.optimizers.SGD(learning_rate=1.0))
まさにモバイル端末を含めた連合学習のフレームワークを実現するためのものであり、もし実装できるのであればこれがBestであるように思えます。が、ドキュメントを読んでいくと気になる一文があり,まだ実際に使える実装にはなっていないようです(使いたかったのでちょっと残念。。。)
It is a goal of TFF to define computations in a way that they could be executed in real federated learning settings, but currently only local execution simulation runtime is implemented.
結論として現時点で使えるアプリケーションを組みのであればまずTensorflow Lite+Firebase ML Kit で行くのが現実的なようですね。
今後検証すること
今回のブログではモバイル端末上で機械学習を実装するにあたって特有の注意点と、それを踏まえた上でどのようなライブラリ構成が候補にあるかの例を提示しました。次回以降はこれを踏まえた上で、実際にAndroid上で機械学習を実行するアプリケーションを作成し、書道として以下の点を検証していこうと考えています。
- android上でデータを収集・学習・推論をする際の実装方法
- 学習実行した際に実行時間や電池消費量がどの程度変化するかの遷移
- 学習頻度によってUIや電池残量にどの程度影響があるか
- 途中切断などが発生した場合のフォールバックなど異常発生時の挙動検証
次世代システム研究室では、ビッグデータ解析プラットフォームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧からご応募をお願いします。
一緒に勉強しながら楽しく働きたい方のご応募をお待ちしております。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD