2022.01.10
ABテストの際に実務で気をつけている尖った観点だけ集めてみた
こんにちは。次世代システム研究室のY. O.です。
今回は、ビジネス現場で非常に知名度が高いものの、正確な結果解析を行うためにはそれなりに技術が必要で注意する点も多い”ABテスト”について取り上げ、筆者が実務で直面している3つのシチュエーションを題材に、どのように考え、対処しているかを集めました。
なお、ABテストの基礎やABテストで用いられる統計の基礎については、「A/Bテスト実践ガイド 真のデータドリブンへ至る信用できる実験とは」[1] という書籍にまとめられており、そちらの購読がお勧めです。以下では基礎を飛ばして”尖った観点”だけ集めて議論をしますが、同書はこの尖った観点についてもトピックとして取り上げています。本記事はこれらの尖った観点をトピックとして引用しつつ、実務での観点や数値検証を交えて議論を進めてみようと思います。
目次
- 複数の直交したABテストを行う
- トリガー条件を用いて分析感度を向上させる
- 長期効果を測定する
複数の直交したABテストを行う
実務シチュエーション
「今回のユーザ登録画面に関するABテストでは、user_idの下一桁が、偶数のユーザをA、奇数のユーザをBとして実験を行いましょう!」
という会話はごく自然なように聞こえますが、、、ちょっと待ってください、翌週別のABテストを計画する場合、どのような会話が発生するでしょう?
「今回のマイページ情報に関するABテストでは、user_idの下一桁が、偶数のユーザをA、奇数のユーザをBとして実験を行いましょう!」
「実は先週ユーザ登録画面に関するABテストを行っていて、その際も偶数:A、奇数:Bとしたので、その実験方法だと今週のテストにはA→AというユーザかB→Bというユーザしかいないことになり、A→BやB→Aというケースにどのような結果となるのかをテストできません。。。」
「なるほど。。。では今週はuser_idの下一桁を4で割って余りが0,1をA、2,3をBとして、先週と今週のABテストが干渉しないようにしましょう!」
気をつけている観点
上記の最後の発言も一つの解決策と思いますが、この方法では実験がスケールアウトしないことは目に見えています。
そこで、下一桁や偶奇という概念に囚われず、完全ランダムにユーザをA群B群に分けるという方法を思いつくわけです。ただ、やたらめったらにランダムに分けていては後々の解析が捗りませんので、ABテストのランダム割付に関して気をつけるべきポイントをまとめてみます。
- ユーザは、実験ごとに固有のランダムシードで、A群B群に割り付けられる
- 用いたランダムシードには再現性がある
- プラットフォームを横断して割付ロジックに互換性がある
上記ポイントを考慮して実務で用いているコードを一部紹介すると、バックエンド:Python、解析環境:BigQueryという一般的なケースでは、以下のコードを用いることで上記ポイントを満たしつつ、スケールアウトが容易な形で、ユーザをランダム割付することができます
## Python
import hashlib
...
abtest_key = "220101_XXXXX"
def hash_sha1(user_id, key):
hash_id = int(hashlib.sha1((key + str(user_id)).encode('utf-8')).hexdigest()[:15], 16)
return hash_id
judge_key = hash_sha1(user_id, abtest_key) % 2 ## 0:Treat・1:Control
...
## BigQuery
CREATE TEMP FUNCTION ABTEST_KEY() AS ("220101_XXXXX");
WITH
...
users AS (
SELECT
user_id
,MOD(hash_id, 2) AS judge_key
FROM (
SELECT
user_id
,CAST('0x'||LEFT(
TO_HEX(SHA1(ABTEST_KEY() || CAST(user_id AS STRING)))
,15) AS INT64) AS hash_id
FROM `project.dataset.table`
)
),
...
トリガー条件を用いて分析感度を向上させる
実務シチュエーション
「ABテストをしたんですけれど、有意な実験結果を得ることができませんでした。。。そもそも実験の対象となっているアクションを起こしてくれるユーザが0.5%くらいしかいなくて。。。」
「そうですか。。。そもそもの数が少ないとなると優位に実験結果を得ることがそもそも難しそうですね。。。」
実務を考えてみると、そうかそれは仕方がないな、と思ってしまいそうです。ですが、勘の良いシニアデータサイエンティストはこんなアドバイスをしてくれました。
「その0.5%という数字ですが、もしかしてうちのサービスを利用したことがある、延べ100万ユーザを対象に算出していませんか?」
「あ、そうです」
「今回ABテストを行った機能は、過去に有料オプションを利用したことがあるユーザのみに表示している機能なので、テスト開始時点でその該当となっているユーザのみに絞り込んで結果を出してみてはどうですか?」
気をつけている観点
なるほど、上記で言っていることは正しそうですが、この絞り込みにはどれほど効果があるのでしょうか?以下では、この絞り込み(= トリガー条件)と、分析感度の関係について調査を行なってみます。
想定するケースとしては、「全対象ユーザn = 1,000,000に対し、アクションを起こしたユーザ数a = 5,000の時、トリガー条件を利用してnを絞り込んでABテストの解析を行う」というもの取り扱ってみます。徐々にnを絞り込んでいった際に、分析感度(= Δμ ÷ μ = 最小の効果量 ÷ 機能利用の期待値)がどのようになるかプロットしてみましょう。
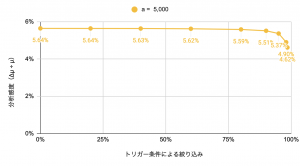
この際、縦軸の分析感度には有意水準(α):0.05、検出力(1 − β):0.80を用いており、A群B群のサンプル数をそれぞれn_A、n_Bとしたときの検出感度は次のように計算できます [2]。
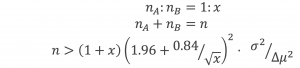
特に、今回のように注目する確率変数がベルヌーイ分布であるときは、次のように式変形をすることができます。
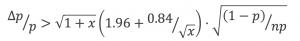
さて、上記グラフからどのようなことが言えるでしょうか。
- トリガー条件による絞り込みをすることにより、分析感度が上がる(小さい効果を測定できるようになる)
- 分析感度は上がるのだが、その上がり幅は、40%のサンプルを除外したとしても、5.64% → 5.63%と小さい(90%でも5.51%)
シニアデータサイエンティストのアドバイスは確かに正しいのですが、このケースにおいては、工数をかけてトリガー条件を解析に取り込む旨味がそこまでなさそうです。。。
では、このセクションの最後に、aとしていくつかのケースを考えてみましょう。以下はそのグラフと簡単な考察です。
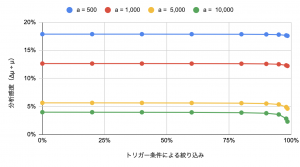
- aが小さい場合はそもそもの分析感度が低い(実験期間を継続してサンプルを集めよう)
- aが大きい場合にはトリガー条件による絞り込みの効果が大きく現れる
- トリガー条件による絞り込みを90%ほど行ったとしても、分析感度の上昇は依然小さいものである
長期効果を測定する
実務シチュエーション
「今回のキャンペーン施策で行ったABテストでは、1日目〜7日目においては有意な売上増加を確認することができましたが、2週間目に突入するとA群B群の間に優位な差を観測することができませんでした。。。」
「ですが、今回のキャンペーン施策はユーザに本機能を理解してもらう効果を狙っているので、より長期的な観点では効果が出てくるのではないでしょうか?」
「・・・」
気をつけている観点
これまたあるあるシチュエーションです。確かに正しい観点ですし、興味が湧く解析トピックなのですが、実務で取り組もうとすると非常に難しい課題の一つです。現に、冒頭で紹介した書籍でも、長期効果について”長期的な効果の測定は困難である”・”いまだに研究の活発な分野”と紹介されています。
ですが、難しい難しいと言っていても何も前進はありませんので、実務でデータサイエンティストとしてどのような解析・判断を行うことができるのかについて考察してみます。
短期効果の測定がもつ弱点
そもそも、なぜ短期効果を知るだけでは不十分なのでしょうか?主な観点として以下の2つがあると考えています。
- 効果を過大もしくは逆向きに評価してしまう
- 効果を過小に評価してしまう
効果を過大もしくは逆向きに評価してしまう:
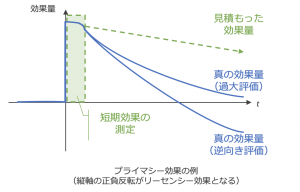
上図では、一般にプライマシー効果・リーセンシー効果と呼ばれる、「効果を過大もしくは逆向きに評価してしまう」ケースにおける効果量の時間推移をグラフで表現しました。
プライマシー効果の代表例としては、本質的な機能改善を伴わないワンショットのキャンペーン施策などが挙げられます。
一方、リーセンシー効果の代表例としては、UI変更といった、初期はユーザが困惑するものの、ユーザの学習が進むと、効果が同水準に戻ったり効果の向きが逆になったりというものが挙げられます。
図内で表現されているように、この状況下で短期効果のみを測定対象としてしまうと、効果量が過大もしくは逆向きとなってしまうことが問題になります。
効果を過小に評価してしまう:
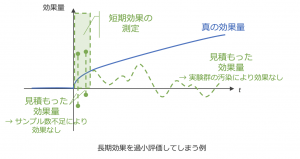
短期効果が不十分であるもう一つの観点が、効果の過小評価です。これが引き起こされてしまう原因には上図で表現した、短期でのサンプル数不足・時間経過による実験群の汚染、の2つがあると考えています。
長期効果の測定を成功させるには
では、長期効果を考える際にどのような点に気を付けると良いのでしょうか?
- 短期効果の測定結果を活用する
- 本施策の長期効果が本当に測定対象とすべき効果量なのかを再考する
- 長期効果のシグナルとなる短期指標で代替する
- 分析感度を高める
- 効果を検出しやすい指標(= 施策に対してより直接的な指標)で測定を代替する
- 他のどの施策にも汚染されない実験群を長期にわたり確保する
まずは長期効果が本当に測定対象とすべき効果量なのかを再考してみます。上記の課題評価・逆向き評価ですが、仮に短期評価の期間を少しだけ延長して、効果量の収束が確認できたとしたら、どうでしょうか。長期の効果量は無視しても問題なく、さらに見積もった効果量も真の効果量と判断しても良いのではないでしょうか。また、期間を先延ばした際に効果量が収束しなくても、効果量の減少を確認することができたとします。測定している指標について、短期の変動と長期の変動の関係を事前に把握しているなら、短期の測定結果を長期のシグナルとして利用することができると考えられます。
そして、過小評価を防ぐためには、短期で効果を測定できるよう、より感度の高い指標へと変更したり、長期にわたって実験用のユーザを確保したりという方法が考えられます。
特に後者については、運用面・収益面などで大きなコストがかかるため、そもそも測定対象の施策が長期効果を引き起こす原因となるのかを論理的に考え、測定対象とすべきかを再考すべきです。
最後に
ABテストの尖った観点を3つご紹介しました。これらの考えをもとに、今後も実務でのABテストを素早く・正しく行なっていきたいと思います。
前回のブログではFirebase A/B Testingを紹介し、実務でフル活用には少し物足りない、と結論付けてしまいましたが [2]、こういった汎用的なABテストのツールにはどんどん進化をしていただいて(もちろん今回の”尖った観点”にも対応していただいて)、ABテストを素早く・正しく行なっていくだけではデータサイエンティストが価値を出せない世の中になっていくことを願っております。
次世代システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧からご応募をお願いします。
一緒に勉強しながら楽しく働きたい方のご応募をお待ちしております。
参考資料
[1] https://www.kadokawa.co.jp/product/302101000901/
[2] https://www.wiley.com/en-us/Statistical+Rules+of+Thumb%2C+2nd+Edition-p-9780470144480
[3] https://recruit.gmo.jp/engineer/jisedai/blog/business_firebase_abtesting_personalization/
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD